Tensorflow serving -- 部署和并发测试记录
参考链接 – 1 – Keras Tensorflow serving踩坑记录
参考链接 – 2 – Keras Tensorflow serving踩坑记录
参考链接 – 3 – Keras
参考链接-4 来自github部署项目
-
需要什么:Docker,Tensorflow-serving, keras
-
关键是什么:Tensorflow的版本,网络问题(前者保证了模型的正常运行)(后者保证数据的传输)。tensorflow serving,这篇文章主要是基础,关于tensorflow serving的深入,就看另一篇吧
什么是Tensorflow serving
参考链接1
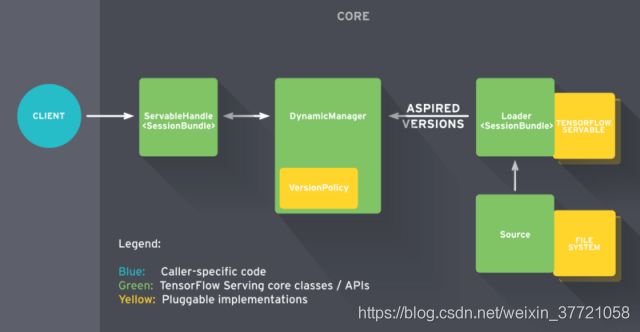
TensorFlow Serving 是一个用于机器学习模型 serving 的高性能开源库。它可以将训练好的机器学习模型部署到线上,使用 restful api或者grpc 作为接口接受外部调用,部署 TensorFlow Serving 后,你再也不需要为线上服务操心,只需要关心你的线下模型训练, 模型训练好打包成pd文件,传入tf-serving 中,调用即可。
总的来说,开箱即用吧,你不用去写什么web也不需要去写什么如何多模型的切换或者什么的,只要将你的模型转化为pb,然后给他,他就帮你部署。然后你去访问他,给他一张图片,他就给你个结果。其实它本身就是写好了web之类的,他也会支持不同的接收方式。上面提到的这些你也可以自己写,自己去实现,关键就是你可以写的比他们好,那就行吧。
整个熟悉的过程会涉及到什么部分呢?
1.首先是对整个部署流程,操作的大致了解,每一步需要做什么,为什么需要做。
2.针对整个流程的部署,然后进行一些细节的更改,这里包括tensorflow serving的几个参数,还有就是热启动,还有就是热更新,还有就是用tensorflow tensorrt来让你的模型等。这些都会在部署流程中某个地方进行修改。
3.对了,使用Tensorflow serving来部署的话,一般都是部署服务器上的,也就是云端进行操作的。
第一步:格式转换 PB部署模型
部署tensorflow模型或者是keras的模型等,只要你想用tensorflow serving来部署的第一步是模型持久化,将模型结构和权重保存到一个.pb文件当中。
如果用tensorflow的话,就是将模型的ckpt文件转换成pb文件,然后用tensorflow serving部署就可以了
如果模型的输出还不是最终的结果,需要进行其它运算,请尽可能把后处理的操作都用tf或者keras的API写进计算图的节点里面,尽量使模型的预测结果就是最终的结果,否则需要在web的代码中对返回的结果进行其它处理。
这一步就是一个正常的模型保存的过程,生成的文件是pb格式的,部署使用的话,都会转化成这个格式,接下来我们可能也会用上tensorrt,然后转换的过程也是模型保存的过程,但是也是会变成pb格式。为了更加细化这个过程,给大家看看下面的连接,可以参考下为什么这么做。
谷歌推荐的保存模型的方式是保存模型为 PB 文件,它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型。
它的主要使用场景是实现创建模型与使用模型的解耦, 使得前向推导 inference的代码统一。
另外的好处是保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小,适合在手机端运行。
还有一个就是,真正离线测试使用的时候,pb格式的数据能够保证数据不会更新变动,就是不会进行反馈调节啦。
pb文件+ variable目录(.index文件+.data).PS:如果从pb文件中转出来的模型,variable文件夹中为空,因为pb文件里面的各项参数都是tf.constant,所以不会存储到variable里面。
如果是使用tensorflow的ckpt的话可以使用freeze - graph的操作,将其转化为pb格式。
具体参考这个东西:冻结在Tensorflow中的作用
pb模型的了解
参考连接1
pb模型了解下
debug:
1.转成tensorflow-serving的话,要么就是tensorflow转tensorflow-serving,或者就是keras转tensorflow-serving,我这里是后者,后者的话,两者的区别主要是代码的区别,但是主要的input ,output ,signature这些区别不大。最终就会是生成一系列的文件。
2.模型训练的版本与tensorflow serving之间并不搭配导致的问题:
3.生成的模型可以使用http发送也可以使用grpc进行通信。
第二步:部署Docker
Docker容器的基本上搭建一个容器,让你在里面顺利的跑各种符合该容器环境的代码,之前在顺丰实习的时候,做法就是用了Docker 每个人每次用的时候创建容器拉取对应环境的镜像,然后直接在里面进行各种运行就好了。如果要进行部署的话这样是很快的,因为环境已经早就明确和布置好了。这里的话,我们主要就是使用了docker来部署tensorflowserving的环境,然后将你的模型放到docker中,这个容器就成为一个服务器,对外接收信息,处理,并给出处理结果。
TensorFlow Serving(官网)能够很简单的把你的模型挂在服务器后台,然后你只需要写一个客户端把请求发过去,它就会把运算后的结果返回给你。而TensorFlow Serving的最佳使用方式就是使用一个已经编译好TensorFlow Serving功能的docker,你所要做的只是简单的运行这个docker即可。
这一步比较emmm,麻烦点,因为docker 安装我就找了些不同的链接
1.安装docker
2.安装nvidia-docker
上面两者参考这个链接 ~~~
反正我成功了的链接
docker-compose 安装
docker-compose 安装官方链接
安装成功后,就可以先拉取合适你的镜像,这里的镜像就是你容器需要的环境,用镜像生成容器,然后挂上模型所在的路径,然后tensorflow-serving。这句话基本上就保证你的docker容器成为一个合格的服务器等待你的用户来用啦啦啦~~~ 具体参考链接
3.使用镜像前先拉取合适你使用的tensorflow-serving的镜像,根据的你的cuda情况选择就好了,我这里是1.10.1
docker pull tensorflow/serving:1.10.1-devel-gpu
关于挂载生成容器,有两种具体看我的参考链接,我是用的第二种啦,第二种就是用的devel的docker,这种的话不是一键生成的,但是会让你更加熟悉docker的运行机制。
第一步是:用上我刚刚的镜像,生成容器,同时呢挂载上我的模型所在的路径。这样我就可以在这个容器中做我想做的啦~
sudo nvidia-docker run -it --rm --name test_model --shm-size 16G -v 模型所在的路径:/docker的路径 镜像的名称,刚刚拉的不会忘记了吧? bash
sudo nvidia-docker run -it --rm --name test_model --shm-size 16G -v /mnt/ailab_data:/wsw tensorflow/serving:1.10.1-devel-gpu bash
由于接下来我们需要使用8500的端口,所以这里我们将端口映射到机器的8500端口,这样接下来就可以使用了。
sudo nvidia-docker run -it --rm --name test_model --shm-size 16G -p 8500:8500 -v /mnt/ailab_data:/wsw tensorflow/serving:1.10.1-devel-gpu bash
第二步:在容器中开启你的tensorflow-serving :这一部分需要设置一些不同的参数,不同的设置,会影响到你模型的并发性能,所以我们需进一步的调试。
tensorflow_model_server --port=8500 --model_name="随便你取" --model_base_path="/wsw/17_bk/wsw/bcs_project/code/BCS-keras/bcs_application/test_model"#docker下的路径
开始跑起来了

更加具体的部署流程:
-1.输入图片
-2.post发送 (自己写)
(客户端)
-3.web处理 (用前端框架写接收,然后通过grpc或者http转发给我们的tensorflow serving)所以我们这里为什么要写一个web,是为了预处理图像,如果将预处理图像加入到模型中,那么就可以直接发送图片,处理返回结果。
(web端)
-4.tensorflow serving处理
-结果返回给web
-5.web返回结果给用户
(tensorflow端)
第三步:写一个客户端吧
TensorFlow Serving启动后,我们需要用一个客户端来发送预测请求,跟以往请求不同的是,TensorFlow Serving使用的是gRPC协议,我们的客户端需要安装使用gRPC的API,以特定的方式进行请求以及接收结果。
第四步:图像预处理的问题 (前端框架,并发测试的位置在这里)
超好的参考链接
现实情况是你不可能要求每一个用户都要写一大堆预处理和后处理代码,用户只需使用简单POST一个请求,然后接收最终结果即可。因此,这些预处理和后处理代码必须由一个“中间人”来处理,这个“中间人”就是Web服务。
所以我先写web 到 Tensorflow serving:也就是第四步,可以测试你的tensorflow serving有没有问题,也可以完成预处理的部分。
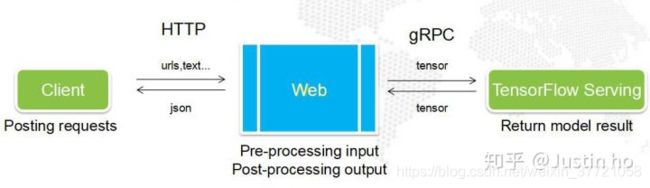
写web的话有:django、flask和tornado的部署。
对比链接1
参考链接2
debug过程:
http与https的问题
网络问题
简单来说docker 与tensorflow serving的网络关系是本机IP,端口ip,docker端口,tensorflow端口,后两者是一样的,所以创建docker的时候你可以选择自己的ip,也可以通过创建后查找他的ip,还有就是端口放开,然后通过这个端口访问这个程序基本上就没问题了。
预处理的过程:
预处理的过程
并发测哪里
并发目前来说都是测试在web端到tf端,所以我们需要更多的关注这一块,来解决这个问题。