计算机视觉项目实战(二)、局部特征匹配 Local Feature Matching
局部特征匹配 Local Feature Matching
- 项目要求
- 项目原理
-
- 局部特征
- 图像中的特征点
- Harris角点(Harris Corner Detector)
- NMS(非最大值抑制)
- SIFT(尺度不变特征变换)
- Soble算子
- 实验步骤
-
- (一) 读取图像,并对图像进行预处理
-
- 简介
- sepup_image()
- (二)使用Harris Corner Detector查找图像中的角点
-
- 简介
- get_interest_points()
- 输出
- (三)使用ANMS进行角点筛选以获得高分特征点
-
- 简介
- ANMS()
- 输出
- (四)构建SIFT功能描述符
-
- 简介
- get_features()
-
- 功能
- 参数
- 返回值
- 具体步骤
- 输出
- (五)特征匹配
-
- 简介
- match_features()
- 效果
- 实验结果
- 参考链接
- 项目源码下载链接
项目要求
- 实现兴趣点检测
- 实现类SIFT局部特征描述
- 实现简单匹配算法

项目原理
局部特征
全局特征(global features)指的是图像的方差、颜色直方图等等,描绘了图像的整体信息,但是无法分辨出图像中的前景和背景。
局部特征(loacl features)指的是一些局部才会出现的特征,而且该部分需要满足两个条件:1. 能够稳定出现; 2. 具有良好的可区分性。
当我们所关注的对象在图像中受到部分遮挡,全局特征可能会被破坏,但局部特征依然能够稳定存在,以代表这个物体。
图像中的特征点
一幅图像中总存在着其独特的像素点,这些点我们可以认为就是这幅图像的特征,成为特征点。计算机视觉领域中的很重要的图像特征匹配就是一特征点为基础而进行的,所以,如何定义和找出一幅图像中的特征点就非常重要。
在计算机视觉领域,兴趣点(也称关键点或特征点)的概念已经得到了广泛的应用, 包括目标识别、 图像配准、 视觉跟踪、 三维重建等。 这个概念的原理是, 从图像中选取某些特征点并对图像进行局部分析,而非观察整幅图像。 只要图像中有足够多可检测的兴趣点,并且这些兴趣点各不相同且特征稳定, 能被精确地定位,上述方法就十分有效。
好的特征应该有以下几个特点:
- 重复性:不同图像的相同区域应该能被重复检测到,而且不受旋转、模糊、光照等因素的影响。
- 可区分性:不同的检测子应可通过检测对应的描述子进行区分。
- 数量适宜:检测子的数量过多或者过少都会降低识别精度。
- 高定位:检测子的大小和位置均应固定。
- 有效性:具有较快的检测速度。
Harris角点(Harris Corner Detector)
角点的基本原理:人眼对角点的识别通常是在一个局部的小区域或小窗口完成的。如果在各个方向上移动这个特征的小窗口,窗口内区域的灰度发生了较大的变化,那么就认为在窗口内遇到了角点。如果这个特定的窗口在图像各个方向上移动时,窗口内图像的灰度没有发生变化,那么窗口内就不存在角点;如果窗口在某一个方向移动时,窗口内图像的灰度发生了较大的变化,而在另一些方向上没有发生变化,那么,窗口内的图像可能就是一条直线的线段。
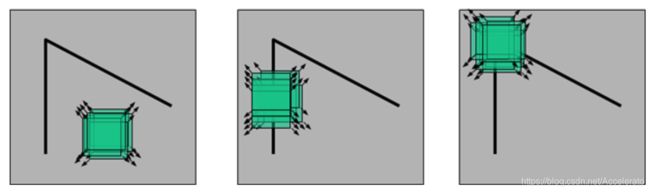
角点具有一些良好的特征:视角变化时也仍然可以很好的辨识;和周围点在任何方向上变化都很大。角点经常被检测在边缘的交界处、被遮挡的边缘、纹理性很强的部分。满足这些条件一般都是稳定的、重复性比较高的点,所以实际上他们是不是角点并不重要(因为我们的目标就是找一些稳定、重复性高的点以作为特征点)。

Harris Corner是最典型的角点检测子,具有的优点是平移不变、旋转不变,能克服一定光照变化。
NMS(非最大值抑制)
NMS(Non-Maximum Supression)非最大抑制,就是抑制除最大值(局部最优)外的其他元素。比如在下图中要确认人行道上的车辆,需要找到区域内识别概率最大的框,所以将右边0.9的框和左边0.8的框高亮,之后遍历其他边框,如果和高亮的框交并比大于0.5,则将框进行淡化(抑制)。

SIFT(尺度不变特征变换)
SIFT(Scale-Invariant Feature Transform)尺度不变特征变换,是计算机视觉领域对图像局部特征进行描述的常用方法,有以下四个关键步骤
1. 尺度空间极值检测(Scale-space extrema detection)
建立高斯差分金字塔,采用不同 σ \sigma σ(尺度)的高斯核对原图像进行卷积操作,得到一组不同层的图片,而不同组之间的图片通过降采样(隔点取点)得到。通过不断的变化高斯核和进行降采样,便可以得到高斯金字塔。再通过同一组不同两层之间的图片相减,就得到高斯差分金字塔(又叫尺度空间),如下图所示。
其中,
组数 O = [ l o g 2 ( m i n ( M , N ) ) ] − 3 O=[log_2(min(M,N))]-3 O=[log2(min(M,N))]−3,其中M和N是图片的长和宽。
层数 S = n + 3 S=n+3 S=n+3,其中n是希望提取从中特征的图片数目,因为做差分的过程中有一张图片无法使用,同时尺度空间上最上面一张和最下面一张图片无法求导,所以S-3=n。
σ \sigma σ取法请见参考资料中原论文,不在此赘述。
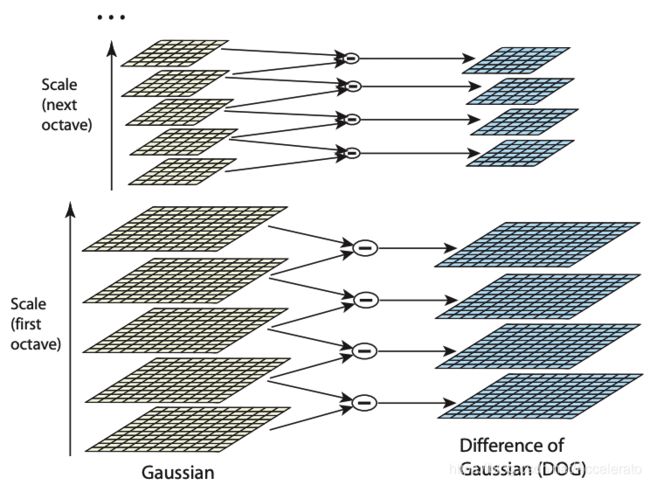
理解:因为SIFT要解决尺度不变性问题,它的理念是不仅在任何尺度下拍摄的物体都能检测到一致的关键点,而且每个被检测的特征点都对应一个尺度因子。 在高斯金字塔中,其实降采样就是模拟了近大远小的尺寸变化,高斯核进行卷积模拟的是近处清晰,远处模糊。(PS:值得注意的是,高斯核是唯一一个可以模拟近处清晰,远处模糊的线性核)
2. 关键点定位(Keypoint Localization)
关键点需要满足:包含很多信息,稳定不易变化。关键点通常是极值位置。
-> 1. 阈值化
a b s ( v a l ) > 0.5 ∗ T / n abs(val)>0.5*T/n abs(val)>0.5∗T/n,其中T=0.04,因为如果太小了可能是噪声,不进行保留。
-> 2. 在高斯差分金字塔中找极值
在考虑了尺度空间后,如果一个像素点的值比周围26个像素点都大(小),那么就认为这个点是一个极值。
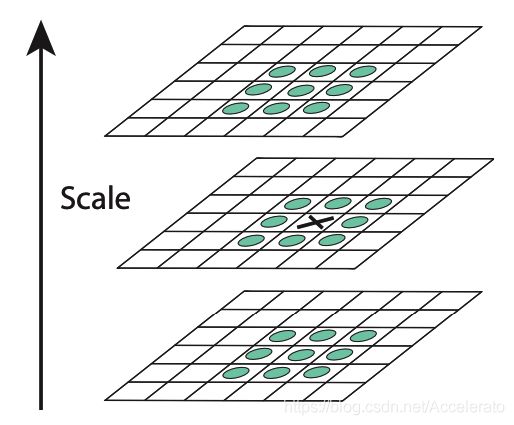
-> 3. 调整极值点的位置
因为像素空间和尺度空间均是离散的,所有需要找到亚像素位置的精确极值点,具体操作是在检测到的极值点处做三元二阶泰勒展开,再对函数进行求导并令导数为零。
-> 4. 舍去低对比度的点
若 ∣ f ( X ) < T / n ∣ |f(X)
-> 5. 边缘效应的去除
3. 方向赋值(Orientation assignment)
在最接近关键点尺度值 σ \sigma σ的高斯图像上,统计以特征点为圆心,以该特征点所在的高斯图像的尺度的1.5倍为半径的圆内所有像素的梯度方向以及其梯度幅值,并做 1.5 σ 1.5\sigma 1.5σ的高斯滤波。
4. 关键点描述(Keypoint descriptor)
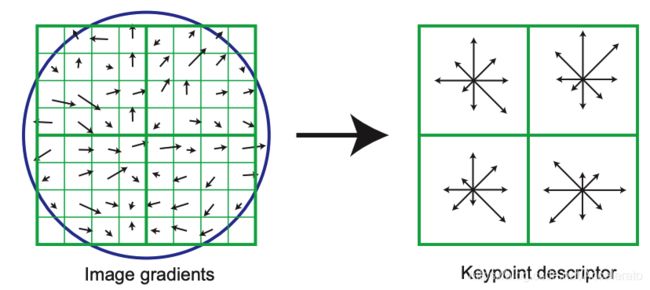
关键点的描述符是一个128维的向量,用k近临算法进行向量匹配两个图片当中所有关键点的描述符中距离最近的两个描述符,并进行连接。
在每一个子区域内统计八个方向上的梯度的经过高斯加权的长度,将每个子区域内的各个方向上的长度依次写出,便得到描述符。
Soble算子
索贝尔算子是计算机视觉领域的一种重要处理方法。主要用于获得数字图像的一阶梯度,常见的应用和物理意义是边缘检测。索贝尔算子是把图像中每个像素的上下左右四领域的灰度值加权差,在边缘处达到极值从而检测边缘。
Soble算子模版:
Gx:
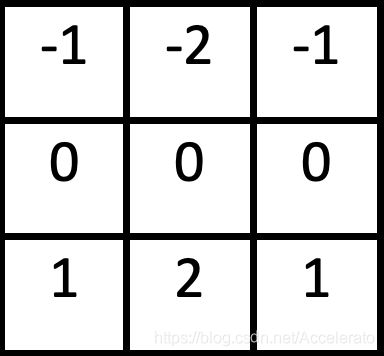
Gy:

实验步骤
(一) 读取图像,并对图像进行预处理
简介
读取图像,将图片的长和宽放缩为原来的1/2,再转化为灰度图。
sepup_image()
def setup_image(img_name):
image = load_image('../data/'+img_name+'/'+img_name+'.jpg')#载入图像
eval_file = '../data/'+img_name+'/'+img_name+'Eval.mat'#载入标准匹配矩阵
scale_factor = 0.5 #设置缩放系数
image = cv2.resize(image, (0, 0), fx=scale_factor, fy=scale_factor)#将图片进行缩放
image_bw = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) #进行灰度处理
return image_bw
(二)使用Harris Corner Detector查找图像中的角点
简介
首先需要对图片进行兴趣点检测,我使用Harris Corner Detector来检查图像中的角点,通过用矩阵的行列式减去矩阵的平方来确定特定像素得分,得分越高的像素越具有角的特征,具体评判标准由阈值人为设定。如果像素的角点得分高于阈值,便认为它是一个角点,否则就忽略它。带有角点标记的图像如下面两张图所示。可见,检测到大量的角点,且角点在图像上的分布不均匀。为了保证角点分布的均匀性,我采用了自适应的MNS来抑制多余的角点。
get_interest_points()
- 获得图片的尺寸(长和宽)
ImageRows = image.shape[0]
ImageColumns = image.shape[1]
- 利用Sobel算子进行边缘检测,第二个参数cv2.CV_64F表示64位浮点数即64float,第三和第四个参数分别是对X和Y方向的导数(即dx,dy),对于图像来说就是差分,这里1表示对X求偏导(差分),0表示不对Y求导(差分),第五个参数ksize是指核的大小。
imX = cv2.Sobel(image, cv2.CV_64F,1,0,ksize=5)
imY = cv2.Sobel(image, cv2.CV_64F,0,1,ksize=5)
- 计算Harris矩阵分量(包括矩阵特征值和迹,以及角点相应函数R)
Ixx = (Xderivative)*(Xderivative)
Iyy = (Yderivative)*(Yderivative)
Ixy = (Xderivative)*(Yderivative)
for i in range(16, ImageRows - 16):
for j in range(16, ImageColumns - 16):
Ixx1 = Ixx[i-1:i+1, j-1:j+1]
Iyy1 = Iyy[i-1:i+1, j-1:j+1]
Ixy1 = Ixy[i-1:i+1, j-1:j+1]
Ixxsum = Ixx1.sum()
Iyysum = Iyy1.sum()
Ixysum = Ixy1.sum()
Determinant = Ixxsum*Iyysum - Ixysum**2 #计算矩阵的特征值
Trace = Ixxsum + Iyysum #计算矩阵的迹
R = Determinant - alpha*(Trace**2) #角点相应函数R
#判断每个像素相应函数是否大于阈值R,如果大于阈值则合格。
if R > threshold:
XCorners.append(j)
YCorners.append(i)
RValues.append(R)
XCorners = np.asarray(XCorners)
YCorners = np.asarray(YCorners)
RValues = np.asarray(RValues)
- 使用非最大抑制算法(ANMS)进行角点过滤,返回满足条件的角点坐标和得分。ANMS函数在下面给出。
NewCorners = ANMS(XCorners, YCorners, RValues, 3025)
NewCorners = np.asarray(NewCorners)
x = NewCorners[:,0]
y = NewCorners[:,1]
scales = NewCorners[:,2]
return x,y, scales
输出
下图为Harris Corner Detector对NotreDame图像的角点检测结果。
(三)使用ANMS进行角点筛选以获得高分特征点
简介
使用Harris Corner Detector生成的角点不是均匀分布的。在许多情况下角点可能集中在图像的特定区域,从而导致准确性的下降。NMS算法通过在特征函数中寻找局部最大值并丢弃剩余的次大值(即图像中的临近角点)。通过使用该算法,可以提高特征匹配的准确性,但是传统的NMS具有某些局限性,例如图像中特征点在处理后可能会不均匀分布。为了避免这种情况,所以使用ANMS算法(自适应非最大值抑制),基本思想是仅保留r个像素附近最大的那些点。下面两张图显示了使用Harris角点检测器生成的特征点与抑制后剩余的特征点之间的比较。可见,图像中的特征点已从数7000个左右抑制到1500个,且均匀分布。
ANMS()
def ANMS (x , y, r, maximum):
i = 0
j = 0
NewList = []
while i < len(x):
minimum = 1000000000000
#获得一个harris角点的横纵坐标,称为基础点
X, Y = x[i], y[i]
while j < len(x):#遍历除该角点外每一个得分(R值)更高的角点,称为比较点,找到离基础点最近的一个比较点,记录下基础点的横纵坐标和与最近比较点之间的距离
CX, CY = x[j], y[j]
if (X != CX and Y != CY) and r[i] < r[j]:
distance = math.sqrt((CX - X)**2 + (CY - Y)**2)
if distance < minimum:
minimum = distance
j = j + 1
NewList.append([X, Y, minimum])
i = i + 1
j = 0
#根据距离大小对基础点进行排序,很显然,距离越小的点说明在该角点周围有更好的角点,所以可以适当舍弃。在舍弃一定数目的得分较小的角点后,就得到了非最大抑制后的harris角点坐标。
NewList.sort(key = lambda t: t[2])
NewList = NewList[len(NewList)-maximum:len(NewList)]
return NewList
输出
下图显示了NotreDame图像使用ANMS进行角点筛选后的特征点。

(四)构建SIFT功能描述符
简介
为每个特征点创建的特征向量,用于将第一幅图像的关键点与第二幅图像的关键点进行匹配。为此,计算第一图像中每个关键点的每个特征向量到第二图像中每个特征向量的距离。然后对距离进行排序,并获取和比较两个最小距离。为了使关键点与第二个图像中的另一个关键点精确匹配,计算并检查两个最小距离的比率是否大于指定的阈值,之后将其视为关键点。
get_features()
功能
获得给定兴趣点集的一组特征描述符。
参数
image:灰度图
x:兴趣点的x坐标(np array)
y:兴趣点的y坐标(np array)
feature_width:局部特征宽度(以像素为单位)
返回值
fv:规范化特征向量
具体步骤
- 初始化高斯滤波器,使用高斯模糊降低图像中的噪点,并获得图像的尺寸。
filter1 = cv2.getGaussianKernel(ksize=4,sigma=10)
filter1 = np.dot(filter1, filter1.T)
image = cv2.filter2D(image, -1, filter1)
ImageRows = image.shape[0]
ImageColumns = image.shape[1]
xlen = len(x)
ylen = len(y)
FeatureVectorIn = np.ones((xlen,128))
NormalizedFeature = np.zeros((ylen,128))
- 遍历Harris算法得到的每一个角点坐标,提取以该角点坐标为中心的16x16像素的一个局部图像,对于每一个局部图像,拆分成16个4x4像素的窗口,计算窗口内每个像素的大小和方向。
for i in range(xlen):
temp1 = int(x[i])
temp2 = int(y[i])
Window = image[temp2-8:temp2 + 8, temp1-8:temp1 + 8]
WindowRows = Window.shape[0]
WindowColumns = Window.shape[1]
for p in range(4):
for q in range(4):
WindowCut = Window[p*4:p*4 +4,q*4: q*4+4]
NewWindowCut = cv2.copyMakeBorder(WindowCut, 1, 1, 1, 1, cv2.BORDER_REFLECT)
Magnitude = np.zeros((4,4))
Orientation = np.zeros((4,4))
for r in range(WindowCut.shape[0]):
for s in range(WindowCut.shape[1]):
Magnitude[r,s] = math.sqrt((NewWindowCut[r+1,s] - NewWindowCut[r-1,s])**2 + (NewWindowCut[r,s+1] - NewWindowCut[r,s-1])**2)
Orientation[r,s] = np.arctan2((NewWindowCut[r+1,s] - NewWindowCut[r-1,s]),(NewWindowCut[r,s+1] - NewWindowCut[r,s-1]))
- 对于每一个窗口,以方向为横坐标建立直方图(共8个方向),窗口内所有像素在方向上的加权和为直方的幅度值,这样就得到了每一个角点的局部图像中每个窗口表示大小和方向的特征向量。
Magnitude = Magnitude
OrientationNew = Orientation*(180/(math.pi))
hist, edges = np.histogram(OrientationNew, bins = 8, range = (-180,180), weights = Magnitude)
for t in range(8):
l = t+p*32+q*8
FeatureVectorIn[i,l] = hist[t]
- 正则化特征向量,并返回值。
for a in range(FeatureVectorIn.shape[0]):
sum1 = 0
for b in range(FeatureVectorIn.shape[1]):
sum1 = sum1 + (FeatureVectorIn[a][b])*(FeatureVectorIn[a][b])
sum1 = math.sqrt(sum1)
for c in range(FeatureVectorIn.shape[1]):
NormalizedFeature[a][c] = FeatureVectorIn[a][c]/sum1
fv = NormalizedFeature
return fv
输出
下图显示了NotreDame图像对中前100个关键点匹配项。
(五)特征匹配
简介
在得到两个图像的SIFT特征描述符和Harries算法得到的角点坐标后,即可通过计算特征向量之间的距离,进行图像的特征匹配。
match_features()
- 对于图片1的每一个SIFT特征描述符遍历图片2的每一个SIFT特征描述符,分别计算它们和图一特征向量之间的欧式距离。
for x in range(features1.shape[0]):
for y in range(features2.shape[0]):
ExtractedRow1 = features1[[x],:]
ExtractedRow2 = features2[[y],:]
SubtractedRow = ExtractedRow1 - ExtractedRow2
Square = SubtractedRow*SubtractedRow
Sum = Square.sum()
Sum = math.sqrt(Sum)
Distance[x,y] = Sum
- 按照距离大小对图片2的特征向量进行升序排序,取与图一特征向量距离最小的两个,若两者的距离只比小于阈值,则说明最佳的匹配效果较好,记录下图一和图二两个特征向量的坐标。若大于阈值则不操作。在对图一所有特征向量遍历完后,返回每一对需匹配的特征向量的坐标,和两者之间的距离。
IndexPosition = np.argsort(Distance[x,:])
d1 = IndexPosition[0]
d2 = IndexPosition[1]
Position1 = Distance[x,d1]
Position2 = Distance[x,d2]
ratio = Position1/Position2
if ratio<0.8:
Hitx.append(x)
Hity.append(d1)
Value.append(Position1)
Xposition = np.asarray(Hitx)
Yposition = np.asarray(Hity)
matches = np.stack((Xposition,Yposition), axis = -1)
confidences = np.asarray(Value)
return matches, confidences
效果
实验结果
load 标准配对数据文件和SIFT功能描述符的匹配结果进行比较,结果如下:
- NotreDame的配对准确率为79%,如下图所示
- MountRushmore的配对准确率为32%,如下图所示。
其他: - LaddObservatory
参考链接
Project 2: Local Feature Matching
CSCI 1430: Introduction to Computer Vision
特征检测和特征匹配方法
局部特征(1)——入门篇
Harris角点
C4W3L07 Nonmax Suppression
Distinctive Image Features from Scale-Invariant Keypoints-David G. Lowe
项目源码下载链接
局部特征匹配 Local Feature Matching