这2万字的前端基础知识查漏补缺,请你收藏好

一,JS基础
1.如何在es5环境下实现let
对于这个问题,我们可以直接查看babel转换前后的结果,看一下在循环中通过let定义的变量是如何解决变量提升的问题
- 源码
//源码
for(let i=0; i<10; i++){
console.log(i)
}
console.log(i)
babel转码
for(var _i = 0; _i < 10; _i++){
console.log(_i)
}
console.log(i)
babel在let定义的变量前加了道下划线,避免在块级作用域外访问到该变量,除了对变量名的转换,我们也可以通过自执行函数来模拟块级作用域。
(function(){
for(var i = 0; i < 5; i ++){
console.log(i) // 0 1 2 3 4
}
})();
console.log(i) // Uncaught ReferenceError: i is not defined
2、如何在ES5环境下实现const
实现const的关键在于Object.defineProperty()这个API,这个API用于在一个对象上增加或修改属性。通过配置属性描述符,可以精确地控制属性行为。Object.defineProperty() 接收三个参数:
Object.defineProperty(obj, prop, desc)
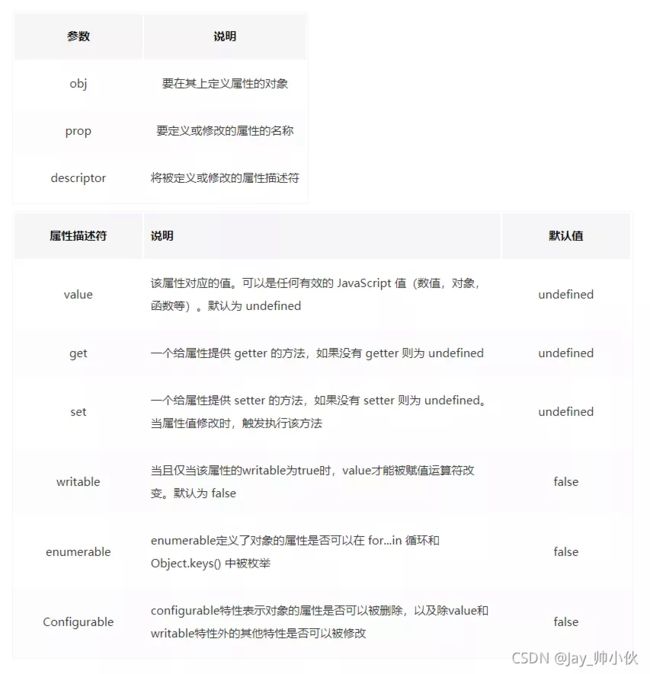
- 对于const不可修改的特性,我们通过设置writable属性来实现
function _const(key, value) {
const desc = {
value,
writable: false
}
Object.defineProperty(window, key, desc)
}
_const('obj', {
a: 1}) //定义obj
obj.b = 2 //可以正常给obj的属性赋值
obj = {
} //抛出错误,提示对象read-only
参考资料:如何在 ES5 环境下实现一个const ?
手写call()
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数
语法:function.call(thisArg, arg1, arg2, …)
call()的原理比较简单,由于函数的this指向它的直接调用者,我们变更调用者即完成this指向的变更:
//变更函数调用者示例
function foo() {
console.log(this.name)
}
// 测试
const obj = {
name: '写代码像蔡徐抻'
}
obj.foo = foo // 变更foo的调用者
obj.foo() // '写代码像蔡徐抻'
- 基于以上原理, 我们两句代码就能实现call()
Function.prototype.myCall = function(thisArg, ...args) {
thisArg.fn = this // this指向调用call的对象,即我们要改变this指向的函数
return thisArg.fn(...args) // 执行函数并return其执行结果
}
但是我们有一些细节需要处理:
Function.prototype.myCall = function(thisArg, ...args) {
const fn = Symbol('fn') // 声明一个独有的Symbol属性, 防止fn覆盖已有属性
thisArg = thisArg || window // 若没有传入this, 默认绑定window对象
thisArg[fn] = this // this指向调用call的对象,即我们要改变this指向的函数
const result = thisArg[fn](...args) // 执行当前函数
delete thisArg[fn] // 删除我们声明的fn属性
return result // 返回函数执行结果
}
//测试
foo.myCall(obj) // 输出'写代码像蔡徐抻'
4. 手写apply()
apply() 方法调用一个具有给定this值的函数,以及作为一个数组(或类似数组对象)提供的参数。
apply()和call()类似,区别在于call()接收参数列表,而apply()接收一个参数数组,所以我们在call()的实现上简单改一下入参形式即可
Function.prototype.myApply = function(thisArg, args) {
const fn = Symbol('fn') // 声明一个独有的Symbol属性, 防止fn覆盖已有属性
thisArg = thisArg || window // 若没有传入this, 默认绑定window对象
thisArg[fn] = this // this指向调用call的对象,即我们要改变this指向的函数
const result = thisArg[fn](...args) // 执行当前函数
delete thisArg[fn] // 删除我们声明的fn属性
return result // 返回函数执行结果
}
//测试
foo.myApply(obj, []) // 输出'写代码像蔡徐抻'
5、手写bind()
bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。
语法: function.bind(thisArg, arg1, arg2, …)
从用法上看,似乎给call/apply包一层function就实现了bind():
Function.prototype.myBind = function(thisArg, ...args) {
return () => {
this.apply(thisArg, args)
}
}
但我们忽略了三点:
- bind()除了this还接收其他参数,bind()返回的函数也接收参数,这两部分的参数都要传给返回的函数
- new的优先级:如果bind绑定后的函数被new了,那么此时this指向就发生改变。此时的this就是当前函数的实例
- 没有保留原函数在原型链上的属性和方法
Function.prototype.myBind = function (thisArg, ...args) {
var self = this
// new优先级
var fbound = function () {
self.apply(this instanceof self ? this : thisArg, args.concat(Array.prototype.slice.call(arguments)))
}
// 继承原型上的属性和方法
fbound.prototype = Object.create(self.prototype);
return fbound;
}
//测试
const obj = {
name: '写代码像蔡徐抻' }
function foo() {
console.log(this.name)
console.log(arguments)
}
foo.myBind(obj, 'a', 'b', 'c')() //输出写代码像蔡徐抻 ['a', 'b', 'c']
6、手写一个防抖函数
防抖和节流的概念都比较简单,所以我们就不在“防抖节流是什么”这个问题上浪费过多篇幅了,简单点一下:
防抖,即短时间内大量触发同一事件,只会执行一次函数,实现原理为设置一个定时器,约定在xx毫秒后再触发事件处理,每次触发事件都会重新设置计时器,直到xx毫秒内无第二次操作,防抖常用于搜索框/滚动条的监听事件处理,如果不做防抖,每输入一个字/滚动屏幕,都会触发事件处理,造成性能浪费。
function debounce(func, wait) {
let timeout = null
return function() {
let context = this
let args = arguments
if (timeout) clearTimeout(timeout)
timeout = setTimeout(() => {
func.apply(context, args)
}, wait)
}
}
7、手写一个节流函数
防抖是延迟执行,而节流是间隔执行,函数节流即每隔一段时间就执行一次,实现原理为设置一个定时器,约定xx毫秒后执行事件,如果时间到了,那么执行函数并重置定时器,和防抖的区别在于,防抖每次触发事件都重置定时器,而节流在定时器到时间后再清空定时器
方式一 延时器
function throttle(func, wait) {
let timeout = null
return function() {
let context = this
let args = arguments
if (!timeout) {
timeout = setTimeout(() => {
timeout = null
func.apply(context, args)
}, wait)
}
}
}
实现方式2:使用两个时间戳prev旧时间戳和now新时间戳,每次触发事件都判断二者的时间差,如果到达规定时间,执行函数并重置旧时间戳
function throttle(func, wait) {
var prev = 0;
return function() {
let now = Date.now();
let context = this;
let args = arguments;
if (now - prev > wait) {
func.apply(context, args);
prev = now;
}
}
}
数组扁平化
对于[1, [1,2], [1,2,3]]这样多层嵌套的数组,我们如何将其扁平化为[1, 1, 2, 1, 2, 3]这样的一维数组呢:
- 1.ES6的flat()
const arr = [1, [1,2], [1,2,3]]
arr.flat(Infinity) // [1, 1, 2, 1, 2, 3]
- 2.序列化后正则
const arr = [1, [1,2], [1,2,3]]
const str = `[${
JSON.stringify(arr).replace(/(\[|\])/g, '')}]`
JSON.parse(str) // [1, 1, 2, 1, 2, 3]
- 3.递归
对于树状结构的数据,最直接的处理方式就是递归
const arr = [1, [1,2], [1,2,3]]
function flat(arr) {
let result = []
for (const item of arr) {
item instanceof Array ? result = result.concat(flat(item)) : result.push(item)
}
return result
}
flat(arr) // [1, 1, 2, 1, 2, 3]
- 4.reduce()递归
const arr = [1, [1,2], [1,2,3]]
function flat(arr) {
return arr.reduce((prev, cur) => {
return prev.concat(cur instanceof Array ? flat(cur) : cur)
}, [])
}
flat(arr) // [1, 1, 2, 1, 2, 3]
- 5.迭代+展开运算符
let arr = [1, [1,2], [1,2,3]]
while (arr.some(Array.isArray)) {
arr = [].concat(...arr);
}
console.log(arr) // [1, 1, 2, 1, 2, 3]
9. 手写一个Promise
异步编程二三事 | Promise/async/Generator实现原理解析 | 9k字
二、JS面向对象
在JS中一切皆对象,但JS并不是一种真正的面向对象(OOP)的语言,因为它缺少类(class)的概念。虽然ES6引入了class和extends,使我们能够轻易地实现类和继承。但JS并不存在真实的类,JS的类是通过函数以及原型链机制模拟的,本小节的就来探究如何在ES5环境下利用函数和原型链实现JS面向对象的特性。
在开始之前,我们先回顾一下原型链的知识,后续new和继承等实现都是基于原型链机制。很多介绍原型链的资料都能写上洋洋洒洒几千字,但我觉得读者们不需要把原型链想太复杂,容易把自己绕进去,其实在我看来,原型链的核心只需要记住三点:
- 每个对象都有__proto__属性,该属性指向其原型对象,在调用实例的方法和属性时,如果在实例对象上找不到,就会往原型对象上找
- 构造函数的prototype属性也指向实例的原型对象
- 原型对象的constructor属性指向构造函数
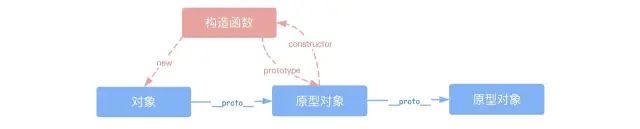
1、模拟实现new
首先我们要知道new做了什么
- 创建一个新对象,并继承其构造函数的prototype,这一步是为了继承构造函数原型上的属性和方法
- 执行构造函数,方法内的this被指定为该新实例,这一步是为了执行构造函数内的赋值操作
- 返回新实例(规范规定,如果构造方法返回了一个对象,那么返回该对象,否则返回第一步创建的新对象)
// new是关键字,这里我们用函数来模拟,new Foo(args) <=> myNew(Foo, args)
function myNew(foo, ...args) {
// 创建新对象,并继承构造方法的prototype属性, 这一步是为了把obj挂原型链上, 相当于obj.__proto__ = Foo.prototype
let obj = Object.create(foo.prototype)
// 执行构造方法, 并为其绑定新this, 这一步是为了让构造方法能进行this.name = name之类的操作, args是构造方法的入参, 因为这里用myNew模拟, 所以入参从myNew传入
let result = foo.apply(obj, args)
// 如果构造方法已经return了一个对象, 那么就返回该对象, 一般情况下,构造方法不会返回新实例,但使用者可以选择返回新实例来覆盖new创建的对象 否则返回myNew创建的新对象
return typeof result === 'object' && result !== null ? result : obj
}
function Foo(name) {
this.name = name
}
const newObj = myNew(Foo, 'zhangsan')
console.log(newObj) // Foo {name: "zhangsan"}
console.log(newObj instanceof Foo) // true
2、ES5如何实现继承
说到继承,最容易想到的是ES6的extends,当然如果只回答这个肯定不合格,我们要从函数和原型链的角度上实现继承,下面我们一步步地、递进地实现一个合格的继承
- 1). 原型链继承
原型链继承的原理很简单,直接让子类的原型对象指向父类实例,当子类实例找不到对应的属性和方法时,就会往它的原型对象,也就是父类实例上找,从而实现对父类的属性和方法的继承
// 父类
function Parent() {
this.name = '写代码像蔡徐抻'
}
// 父类的原型方法
Parent.prototype.getName = function() {
return this.name
}
// 子类
function Child() {
}
// 让子类的原型对象指向父类实例, 这样一来在Child实例中找不到的属性和方法就会到原型对象(父类实例)上寻找
Child.prototype = new Parent()
Child.prototype.constructor = Child // 根据原型链的规则,顺便绑定一下constructor, 这一步不影响继承, 只是在用到constructor时会需要
// 然后Child实例就能访问到父类及其原型上的name属性和getName()方法
const child = new Child()
child.name // '写代码像蔡徐抻'
child.getName() // '写代码像蔡徐抻'
原型继承的缺点:
- 由于所有Child实例原型都指向同一个Parent实例, 因此对某个Child实例的父类引用类型变量修改会影响所有的Child实例
- 在创建子类实例时无法向父类构造传参, 即没有实现super()的功能
// 示例:
function Parent() {
this.name = ['写代码像蔡徐抻']
}
Parent.prototype.getName = function() {
return this.name
}
function Child() {
}
Child.prototype = new Parent()
Child.prototype.constructor = Child
// 测试
const child1 = new Child()
const child2 = new Child()
child1.name[0] = 'foo'
console.log(child1.name) // ['foo']
console.log(child2.name) // ['foo'] (预期是['写代码像蔡徐抻'], 对child1.name的修改引起了所有child实例的变化
- 2)、 构造函数继承
构造函数继承,即在子类的构造函数中执行父类的构造函数,并为其绑定子类的this,让父类的构造函数把成员属性和方法都挂到子类的this上去,这样既能避免实例之间共享一个原型实例,又能向父类构造方法传参
function Parent(name) {
this.name = [name]
}
Parent.prototype.getName = function() {
return this.name
}
function Child() {
Parent.call(this, 'zhangsan') // 执行父类构造方法并绑定子类的this, 使得父类中的属性能够赋到子类的this上
}
//测试
const child1 = new Child()
const child2 = new Child()
child1.name[0] = 'foo'
console.log(child1.name) // ['foo']
console.log(child2.name) // ['zhangsan']
child2.getName() // 报错,找不到getName(), 构造函数继承的方式继承不到父类原型上的属性和方法
构造函数继承的缺点:
继承不到父类原型上的属性和方法
- 3)、 组合式继承
既然原型链继承和构造函数继承各有互补的优缺点, 那么我们为什么不组合起来使用呢, 所以就有了综合二者的组合式继承
function Parent(name) {
this.name = [name]
}
Parent.prototype.getName = function() {
return this.name
}
function Child() {
// 构造函数继承
Parent.call(this, 'zhangsan')
}
//原型链继承
Child.prototype = new Parent()
Child.prototype.constructor = Child
//测试
const child1 = new Child()
const child2 = new Child()
child1.name[0] = 'foo'
console.log(child1.name) // ['foo']
console.log(child2.name) // ['zhangsan']
child2.getName() // ['zhangsan']
组合式继承的缺点:
-
每次创建子类实例都执行了两次构造函数(Parent.call()和new Parent()),虽然这并不影响对父类的继承,但子类创建实例时,原型中会存在两份相同的属性和方法,这并不优雅
-
4)、寄生式组合继承
为了解决构造函数被执行两次的问题, 我们将指向父类实例改为指向父类原型, 减去一次构造函数的执行
function Parent(name) {
this.name = [name]
}
Parent.prototype.getName = function() {
return this.name
}
function Child() {
// 构造函数继承
Parent.call(this, 'zhangsan')
}
//原型链继承
// Child.prototype = new Parent()
Child.prototype = Parent.prototype //将`指向父类实例`改为`指向父类原型`
Child.prototype.constructor = Child
//测试
const child1 = new Child()
const child2 = new Child()
child1.name[0] = 'foo'
console.log(child1.name) // ['foo']
console.log(child2.name) // ['zhangsan']
child2.getName() // ['zhangsan']
但这种方式存在一个问题,由于子类原型和父类原型指向同一个对象,我们对子类原型的操作会影响到父类原型,例如给Child.prototype增加一个getName()方法,那么会导致Parent.prototype也增加或被覆盖一个getName()方法,为了解决这个问题,我们给Parent.prototype做一个浅拷贝
function Parent(name) {
this.name = [name]
}
Parent.prototype.getName = function() {
return this.name
}
function Child() {
// 构造函数继承
Parent.call(this, 'zhangsan')
}
//原型链继承
// Child.prototype = new Parent()
Child.prototype = Object.create(Parent.prototype) //将`指向父类实例`改为`指向父类原型`
Child.prototype.constructor = Child
//测试
const child = new Child()
const parent = new Parent()
child.getName() // ['zhangsan']
parent.getName() // 报错, 找不到getName()
到这里我们就完成了ES5环境下的继承的实现,这种继承方式称为寄生组合式继承,是目前最成熟的继承方式,babel对ES6继承的转化也是使用了寄生组合式继承
我们回顾一下实现过程:
一开始最容易想到的是原型链继承,通过把子类实例的原型指向父类实例来继承父类的属性和方法,但原型链继承的缺陷在于对子类实例继承的引用类型的修改会影响到所有的实例对象以及无法向父类的构造方法传参。
因此我们引入了构造函数继承, 通过在子类构造函数中调用父类构造函数并传入子类this来获取父类的属性和方法,但构造函数继承也存在缺陷,构造函数继承不能继承到父类原型链上的属性和方法。
所以我们综合了两种继承的优点,提出了组合式继承,但组合式继承也引入了新的问题,它每次创建子类实例都执行了两次父类构造方法,我们通过将子类原型指向父类实例改为子类原型指向父类原型的浅拷贝来解决这一问题,也就是最终实现 —— 寄生组合式继承。

三、V8引擎机制
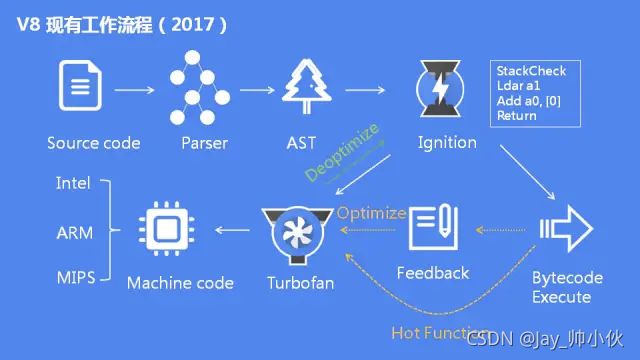
- 预解析:检查语法错误但不生成AST
- 生成AST:经过词法/语法分析,生成抽象语法树
- 生成字节码:基线编译器(Ignition)将AST转换成字节码
- 生成机器码:优化编译器(Turbofan)将字节码转换成优化过的机器码,此外在逐行执行字节码的过程中,如果一段代码经常被执行,那么V8会将这段代码直接转换成机器码保存起来,下一次执行就不必经过字节码,优化了执行速度
上面几点只是V8执行机制的极简总结,建议阅读参考资料:
2、介绍一下引用计数和标记清除
- 引用计数:给一个变量赋值引用类型,则该对象的引用次数+1,如果这个变量变成了其他值,那么该对象的引用次数-1,垃圾回收器会回收引用次数为0的对象。但是当对象循环引用时,会导致引用次数永远无法归零,造成内存无法释放。
- 标记清除:垃圾收集器先给内存中所有对象加上标记,然后从根节点开始遍历,去掉被引用的对象和运行环境中对象的标记,剩下的被标记的对象就是无法访问的等待回收的对象。
3、 V8如何进行垃圾回收
JS引擎中对变量的存储主要有两种位置,栈内存和堆内存,栈内存存储基本类型数据以及引用类型数据的内存地址,堆内存储存引用类型的数据

栈内存的回收:
- 栈内存调用栈上下文切换后就被回收,比较简单
V8的堆内存分为新生代内存和老生代内存,新生代内存是临时分配的内存,存在时间短,老生代内存存在时间长。

- 新生代内存回收机制:
新生代内存容量小,64位系统下仅有32M。新生代内存分为From、To两部分,进行垃圾回收时,先扫描From,将非存活对象回收,将存活对象顺序复制到To中,之后调换From/To,等待下一次回收 - 老生代内存回收机制
- 晋升:如果新生代的变量经过多次回收依然存在,那么就会被放入老生代内存中
- 标记清除:老生代内存会先遍历所有对象并打上标记,然后对正在使用或被强引用的对象取消标记,回收被标记的对象
- 整理内存碎片:把对象挪到内存的一端
参考资料:聊聊V8引擎的垃圾回收
4. JS相较于C++等语言为什么慢,V8做了哪些优化
1 JS的问题:
- 动态类型:导致每次存取属性/寻求方法时候,都需要先检查类型;此外动态类型也很难在编译阶段进行优化
- 属性存取:C++/Java等语言中方法、属性是存储在数组中的,仅需数组位移就可以获取,而JS存储在对象中,每次获取都要进行哈希查询
2 V8的优化:
- 优化JIT(即时编译):相较于C++/Java这类编译型语言,JS一边解释一边执行,效率低。V8对这个过程进行了优化:如果一段代码被执行多次,那么V8会把这段代码转化为机器码缓存下来,下次运行时直接使用机器码。
- 隐藏类:对于C++这类语言来说,仅需几个指令就能通过偏移量获取变量信息,而JS需要进行字符串匹配,效率低,V8借用了类和偏移位置的思想,将对象划分成不同的组,即隐藏类
- 内嵌缓存:即缓存对象查询的结果。常规查询过程是:获取隐藏类地址 -> 根据属性名查找偏移值 -> 计算该属性地址,内嵌缓存就是对这一过程结果的缓存
- 垃圾回收管理:上文已介绍

参考资料:为什么V8引擎这么快?
浏览器渲染机制
-
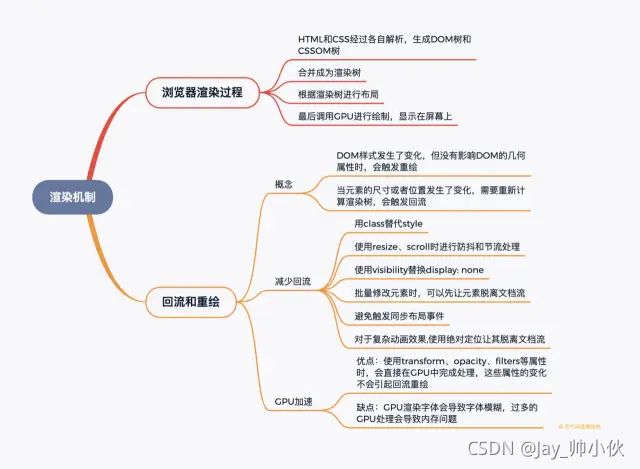
- 浏览器的渲染过程是怎样的。

大体流程如下:
1 HTML和CSS经过各自解析,生成DOM树和CSSOM树
2 合并成为渲染树
3 根据渲染树进行布局
4 最后调用GPU进行绘制,显示在屏幕上
- 浏览器的渲染过程是怎样的。
2、 如何根据浏览器渲染机制加快首屏速度
- 优化文件大小:HTML和CSS的加载和解析都会阻塞渲染树的生成,从而影响首屏展示速度,因此我们可以通过优化文件大小、减少CSS文件层级的方法来加快首屏速度
- 避免资源下载阻塞文档解析:浏览器解析到
3、什么是回流(重排),什么情况下会触发回流
- 当元素的尺寸或者位置发生了变化,就需要重新计算渲染树,这就是回流
- DOM元素的几何属性(width/height/padding/margin/border)发生变化时会触发回流
- DOM元素移动或增加会触发回流
- 读写offset/scroll/client等属性时会触发回流
- 调用window.getComputedStyle会触发回流
4、什么是重绘,什么情况下会触发重绘
DOM样式发生了变化,但没有影响DOM的几何属性时,会触发重绘,而不会触发回流。重绘由于DOM位置信息不需要更新,省去了布局过程,因而性能上优于回流
5、 什么是GPU加速,如何使用GPU加速,GPU加速的缺点
- 优点:使用transform、opacity、filters等属性时,会直接在GPU中完成处理,这些属性的变化不会引起回流重绘
- 缺点:GPU渲染字体会导致字体模糊,过多的GPU处理会导致内存问题
6、 如何减少回流
- 使用class替代style,减少style的使用
- 使用resize、scroll时进行防抖和节流处理,这两者会直接导致回流
- 使用visibility替换display: none,因为前者只会引起重绘,后者会引发回流
- 批量修改元素时,可以先让元素脱离文档流,等修改完毕后,再放入文档流
- 避免触发同步布局事件,我们在获取offsetWidth这类属性的值时,可以使用变量将查询结果存起来,避免多次查询,每次对offset/scroll/client等属性进行查询时都会触发回流
- 对于复杂动画效果,使用绝对定位让其脱离文档流,复杂的动画效果会频繁地触发回流重绘,我们可以将动画元素设置绝对定位从而脱离文档流避免反复回流重绘。
参考资料:必须明白的浏览器渲染机制
四、浏览器缓存策略
1、介绍一下浏览器缓存位置和优先级
1 Service Worker
2 Memory Cache(内存缓存)
3 Disk Cache(硬盘缓存)
4 Push Cache(推送缓存)
5 以上缓存都没命中就会进行网络请求
2、 说说不同缓存间的差别
- Service Worker
和Web Worker类似,是独立的线程,我们可以在这个线程中缓存文件,在主线程需要的时候读取这里的文件,Service Worker使我们可以自由选择缓存哪些文件以及文件的匹配、读取规则,并且缓存是持续性的 - Memory Cache
即内存缓存,内存缓存不是持续性的,缓存会随着进程释放而释放 - Disk Cache
即硬盘缓存,相较于内存缓存,硬盘缓存的持续性和容量更优,它会根据HTTP header的字段判断哪些资源需要缓存 - Push Cache
即推送缓存,是HTTP/2的内容,目前应用较少
强缓存(不要向服务器询问的缓存)
设置Expires
即过期时间,例如「Expires: Thu, 26 Dec 2019 10:30:42 GMT」表示缓存会在这个时间后失效,这个过期日期是绝对日期,如果修改了本地日期,或者本地日期与服务器日期不一致,那么将导致缓存过期时间错误。
设置Cache-Control
HTTP/1.1新增字段,Cache-Control可以通过max-age字段来设置过期时间,例如「Cache-Control:max-age=3600」除此之外Cache-Control还能设置private/no-cache等多种字段
协商缓存(需要向服务器询问缓存是否已经过期)
Last-Modified
即最后修改时间,浏览器第一次请求资源时,服务器会在响应头上加上Last-Modified ,当浏览器再次请求该资源时,浏览器会在请求头中带上If-Modified-Since 字段,字段的值就是之前服务器返回的最后修改时间,服务器对比这两个时间,若相同则返回304,否则返回新资源,并更新Last-Modified
ETag
HTTP/1.1新增字段,表示文件唯一标识,只要文件内容改动,ETag就会重新计算。缓存流程和 Last-Modified 一样:服务器发送 ETag 字段 -> 浏览器再次请求时发送 If-None-Match -> 如果ETag值不匹配,说明文件已经改变,返回新资源并更新ETag,若匹配则返回304
两者对比
- ETag 比 Last-Modified 更准确:如果我们打开文件但并没有修改,Last-Modified 也会改变,并且 Last-Modified 的单位时间为一秒,如果一秒内修改完了文件,那么还是会命中缓存
- 如果什么缓存策略都没有设置,那么浏览器会取响应头中的 Date 减去 Last-Modified 值的 10% 作为缓存时间

参考资料:浏览器缓存机制剖析
五、网络相关
1、讲讲网络OSI七层模型,TCP/IP和HTTP分别位于哪一层


2、 常见HTTP状态码有哪些
- 2xx 开头(请求成功)
200 OK:客户端发送给服务器的请求被正常处理并返回 - 3xx 开头(重定向)
301 Moved Permanently:永久重定向,请求的网页已永久移动到新位置。服务器返回此响应时,会自动将请求者转到新位置
302 Moved Permanently:临时重定向,请求的网页已临时移动到新位置。服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求
304 Not Modified:未修改,自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。 - 4xx 开头(客户端错误)
400 Bad Request:错误请求,服务器不理解请求的语法,常见于客户端传参错误
401 Unauthorized:未授权,表示发送的请求需要有通过 HTTP 认证的认证信息,常见于客户端未登录
403 Forbidden:禁止,服务器拒绝请求,常见于客户端权限不足
404 Not Found:未找到,服务器找不到对应资源 - 5xx 开头(服务端错误)
500 Inter Server Error:服务器内部错误,服务器遇到错误,无法完成请求
501 Not Implemented:尚未实施,服务器不具备完成请求的功能
502 Bad Gateway:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 service unavailable:服务不可用,服务器目前无法使用(处于超载或停机维护状态)。通常是暂时状态。
3、GET请求和POST请求有何区别
标准答案:
GET请求参数放在URL上,POST请求参数放在请求体里
GET请求参数长度有限制,POST请求参数长度可以非常大
POST请求相较于GET请求安全一点点,因为GET请求的参数在URL上,且有历史记录
GET请求能缓存,POST不能
更进一步:
其实HTTP协议并没有要求GET/POST请求参数必须放在URL上或请求体里,也没有规定GET请求的长度,目前对URL的长度限制,是各家浏览器设置的限制。GET和POST的根本区别在于:GET请求是幂等性的,而POST请求不是
幂等性,指的是对某一资源进行一次或多次请求都具有相同的副作用。例如搜索就是一个幂等的操作,而删除、新增则不是一个幂等操作。
由于GET请求是幂等的,在网络不好的环境中,GET请求可能会重复尝试,造成重复操作数据的风险,因此,GET请求用于无副作用的操作(如搜索),新增/删除等操作适合用POST
4、HTTP的请求报文由哪几部分组成
一个HTTP请求报文由请求行(request line)、请求头(header)、空行和请求数据4个部分组成

响应报文和请求报文结构类似,不再赘述
5、HTTP常见请求/响应头及其含义
- 通用头(请求头和响应头都有的首部)

- 请求头

- 响应头

实体头(针对请求报文和响应报文的实体部分使用首部)

HTTP首部当然不止这么几个,但为了避免写太多大家记不住(主要是别的我也没去看),这里只介绍了一些常用的,详细的可以看MDN的文档。
6、HTTP/1.0和HTTP/1.1有什么区别
- 长连接: HTTP/1.1支持长连接和请求的流水线,在一个TCP连接上可以传送多个HTTP请求,避免了因为多次建立TCP连接的时间消耗和延时
- 缓存处理: HTTP/1.1引入Entity tag,If-Unmodified-Since, If-Match, If-None-Match等新的请求头来控制缓存,详见浏览器缓存小节
- 带宽优化及网络连接的使用: HTTP1.1则在请求头引入了range头域,支持断点续传功能
- Host头处理: 在HTTP/1.0中认为每台服务器都有唯一的IP地址,但随着虚拟主机技术的发展,多个主机共享一个IP地址愈发普遍,HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会400错误
7、 介绍一下HTTP/2.0新特性
- 多路复用: 即多个请求都通过一个TCP连接并发地完成
- 服务端推送: 服务端能够主动把资源推送给客户端
- 新的二进制格式: HTTP/2采用二进制格式传输数据,相比于HTTP/1.1的文本格式,二进制格式具有更好的解析性和拓展性
- header压缩: HTTP/2压缩消息头,减少了传输数据的大小。