决策树算法原理及实现
决策树:决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy(熵) = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法得出熵,这一度量是基于信息学理论中熵的概念。决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。决策树是一种十分常用的分类方法,是一种监督学习。
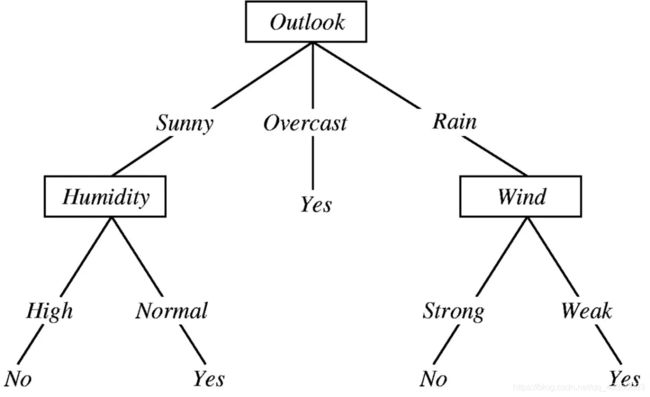
1、决策树的构造
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上那个特征在划分数据分类时起决定性的作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就会被划分为几个数据子集。这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则已正确划分数据类型,如过不同,则需重复划分数据子集。划分数据子集的算法和原始数据相同,直到所有的节点都是同一类型为止。
2、信息增益
上面说到我们需要找到决定性的特征来划分出最好的结果,这也是决策树核心问题所在,那怎么确定这个最优特征呢?我们常用的方法就是用信息论中的信息增益来确定这个特征。
在划分数据集之前之后信息发生的变化叫做信息增益,知道如何计算信息增益,获得计算增益最高的特征就是最好的选择。
在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越有序,信息熵就越低,反之一个系统越混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
熵定义为信息的期望值,既然是要算期望,就得先知道信息的定义。如果待分类的事件可能划分在多个分类之中,则事件(Xi)的信息定义为:
info(xi) = -log2p(xi)
其中p(xi)是选择该类别的概率。
为了计算熵,需要计算出信息的期望,即:
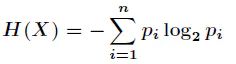
接下来以气象数据为例子,来说明决策树的构建过程:
在没有使用特征划分类别的情况下,有9个yes和5个no,当前的熵为:
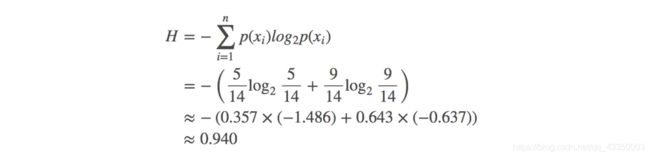
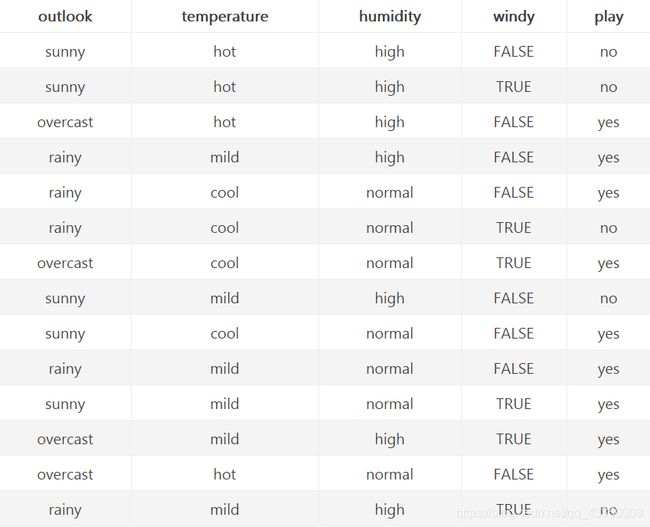
假设我们以 outlook 特征划分数据集,对该特征每项指标分别统计:在不同的取值下 play 和 no play 的次数:
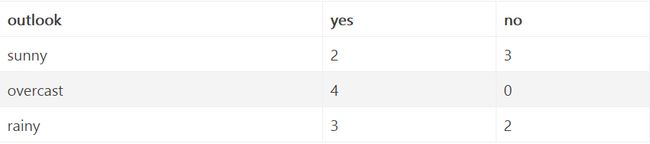
此时各分支的熵计算如下:

因此如果用特征outlook来划分数据集的话,总的熵为:
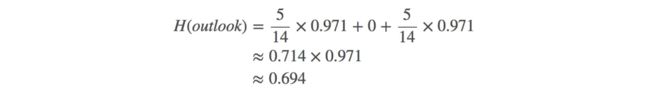
那么最终得到特征属性outlook带来的信息增益为:IG(outlook)=0.940−0.694=0.246,然后用同样的方法,可以分别求出temperature,humidity,windy的信息增益。IG(temperature)=0.029,IG(humidity)=0.152,IG(windy)=0.048。可以得出使用outlook特征所带来的信息增益最大,所以应该首先选择outlook来划分数据集。然后继续划分各个分支的数据集,知道每个分支下的所有实例都具有相同的分类。最终构造出决策树:
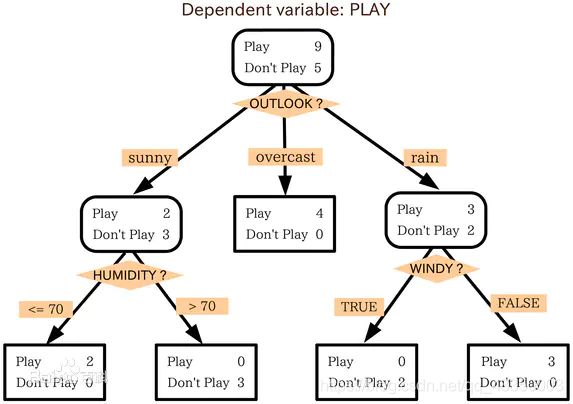
3、决策树代码实现
(1)计算香农熵
# 计算香农熵
def calShannonEntropy(dataSet):
numEntries = len(dataSet) # 数据总数
labelCounts = {
}
for featureVect in dataSet:
currentLabel = featureVect[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
probability = float(labelCounts[key]) / numEntries
shannonEnt -= probability * log(probability, 2)
return shannonEnt
(2)按照给定的特征划分数据集
# 划分数据集
def splitDataSet(dataSet, featureIndex, featureValue):
newDataSet = []
for featVec in dataSet:
if featVec[featureIndex] == featureValue:
reducedFeatVec = featVec[:featureIndex]
reducedFeatVec.extend(featVec[featureIndex+1:])
newDataSet.append(reducedFeatVec)
return newDataSet
(3)选择最佳特征值划分数据集
def chooseBestFeatureToSplit(dataSet):
numFeature = len(dataSet[0]) - 1
baseEntropy = calShannonEntropy(dataSet)
bestFeature = -1; bestInfoGain = 0
for i in range(numFeature):
featList = [entry[i] for entry in dataSet] # 取出每一种属性
uniqueValue = set(featList) # 得到该属性有哪些值(用集合的方法去掉重复值)
newEntropy = 0.0
for value in uniqueValue:
subDataSet = splitDataSet(dataSet, i, value)
probility = len(subDataSet) / float(len(dataSet))
newEntropy += probility * calShannonEntropy(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
(4)投票决定不确定结果
如果数据集已经处理了所有属性,但是类标签依然不是唯一的,通常我们才有多数表决的方法决定该叶子节点的分类。
# 找出票数最多的标签
def majorityVote(classList):
classCount = {
}
for vote in classList:
if vote not in classList.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reversed=True)
return sortedClassCount[0][0]
(5)创建决策树
def createTree(dataset, labels):
# 取出位于最后一列的类别标签
classList = [label[-1] for label in dataset]
if classList.count(classList[0]) == len(classList): # 类别完全相同时,停止划分
return classList[0] # 返回唯一特征值
if len(dataset[0]) == 1: # 已经遍历完所有特征,只剩最后一列类别标签
return majorityVote(classList) # 返回票数最多的类标签
# 开始划分
# 先选取最好的划分特征值
bestFeature = chooseBestFeatureToSplit(dataset)
bestFeatureLabel = labels[bestFeature]
# 初始化树
myTree = {
bestFeatureLabel: {
}}
subLabels = labels[:]
del subLabels[bestFeature]
# 递归构建决策树
featList = [entry[bestFeature] for entry in dataset]
uniqueValues = set(featList)
for value in uniqueValues:
myTree[bestFeatureLabel][value] = createTree(splitDataSet(dataset, bestFeature, value), subLabels)
return myTree
(6)使用决策树执行分类
# 使用决策树执行分类
def classify(inputTree, featLabels, testVec):
# 取出根节点,python2直接写成inputTree.keys()[0]
firstStr = list(inputTree.keys())[0]
# 找到根节点下面的分支(该分类特征的分支)
childDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
# 遍历分类特征的所有取值
for key in childDict.keys():
# 如果测试向量的该类值等于分类特征的第key个节点
if testVec[featIndex] == key:
# 判断该节点是否为字典类型
if type(childDict[key]).__name__ == 'dict':
# 是字典类型,继续遍历
classLabel = classify(childDict[key], featLabels, testVec)
else:
# 不是字典,返回最终结果
classLabel = childDict[key]
return classLabel
(7)存储决策树
构建决策树是非常耗时的任务,即使很小的数据集,也要花费几秒的时间来构建决策树,这样显然耗费计算时间。所以,我们可以将构建好的决策树保存在磁盘中,这样当我们需要的时候,再从磁盘中读取出来使用即可。为了解决这个问题,可以使用pickle序列化对象,任何对象都可以执行序列化操作,字典对象也不例外。