下列不是python数据类型的是_Python数据类型方法精心整理,不必死记硬背,看看源码一切都有了...
Python认为一切皆为对象;比如我们初始化一个list时:
li = list('abc')
实际上是实例化了内置模块builtins(python2中为__builtin__模块)中的list类;


classlist(object):def __init__(self, seq=()): #known special case of list.__init__
"""list() -> new empty list
list(iterable) -> new list initialized from iterable's items
# (copied from class doc)"""
pass
View Code
验证:
In [1]: li = list('abc')
In [2]: li.__class__Out[2]: list
In [3]: li.__class__.__name__Out[3]: 'list'
View Code
1. Python对象特性
python使用对象模型来存储数据。构造任何类型的值都是一个对象。所有python对象都拥有三个特性:身份、类型、值:
1)身份:每个对象都有一个唯一的身份标识自己,任何对象的身份可以使用内建函数 id() 来得到。
2)类型:对象的类型决定了该对象可以保存什么类型的值,可以进行什么样的操作,以及遵循什么样的规则。可以使用 type() 函数查看python对象的类型。type()返回的是对象而不是简单的字符串。
3)值:对象表示的数据。
python不需要事先声明对象类型,当python运行时,会根据“=“右侧的数据类型来确定变量类型;
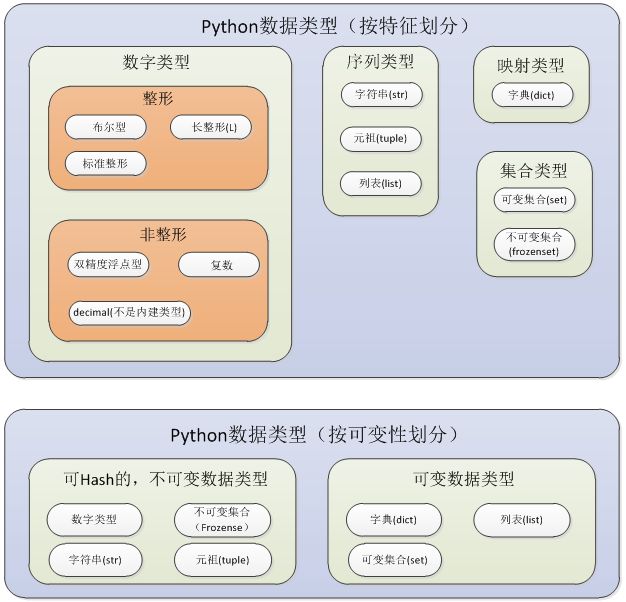
2.Python对象类型
(1)标准类型(基本数据类型)
a) .数字(分为几个字类型,其中三个是整型)
Integer 整型
Boolean 布尔型
Long integer 长整型
Floating point real number 浮点型
Complex number 复数型
b) String 字符串
c) List 列表
d) Tuple 元祖
e) Dictionary 字典
(2)其他内建类型
类型、Null对象(None)、文件、集合/固定集合、函数/方法、模块、类
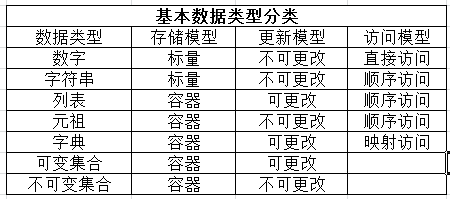
3. 基本对象类型分类
有3种不同的模型可以帮助我们对基本类型进行分类
1)存储类型

一个能保存单个字面对象的类型,称为原子或标量存储;可以容纳多个对象的类型,称为容器存储;并且所有的python容器对象都可以容纳不同类型的对象;
注意,python没有字符类型,所以虽然字符串你看上去像容器类型,实际是原子类型
2)更新模型(是否可变)

这里所说的是否可变,可更新是针对的对象的值而言的;是在对象身份不变的情况下(id不变),值是否可更新;
s = 'abc'
print('id of s:', id(s))
s= 'xyz'
print('id of s:', id(s))
View Code
结果:
id of s: 41643960id of s:46319184
上例中,很多人会说s是字符串,也可变啊,但是注意,这里s指向的对象发生了变化(id值发生了变化),所以这不是我们所说的可更新;让我们看一下list
li = ['a', 'b']print('li before update', li)print('id of li:', id(li))
li[0]= 'x'
print('li after update', li)print('id of li:', id(li))
View Code
结果:
li before update ['a', 'b']
id of li:48447304li after update ['x', 'b']
id of li:48447304
li的值发生了变化,但是li还是原来的对象(id值不变)
另外,对于元祖,元祖本身不可变,但是当元祖存在可变元素时,元祖的元素可变,比如
t = (1, ['a','b'])print('t before update', t)print('id of t:', id(t))
t[1][0] = 'x'
print('t after update', t)print('id of t:', id(t))
View Code
结果:
t before update (1, ['a', 'b'])
id of t:48328968t after update (1, ['x', 'b'])
id of t:48328968
注意:在使用for循环来遍历一个可更新对象过程中,增加删除可更新对象容器的大小会得到意想不到的结果(不期望的结果)甚至出现异常,其中对于字典,直接报错;
直接遍历列表:
1 lst = [1, 1, 0, 2, 0, 0, 8, 3, 0, 2, 5, 0, 2, 6]2
3 for item inlst:4 if item ==0:5 lst.remove(item)6 print(lst) #结果为 [1, 1, 2, 8, 3, 2, 5, 0, 2, 6]
View Code
遍历索引:
1 lst = [1, 1, 0, 2, 0, 0, 8, 3, 0, 2, 5, 0, 2, 6]2
3 for item inrange(len(lst)):4 if lst[item] ==0:5 dellst[item]6 print(lst) #结果为IndexError: list index out of range
View Code
字典:
1 dct = {'name':'winter'}2 for key indct:3 if key == 'name':4 di['gender'] = 'male'
5 print(dct) #结果报错RuntimeError: dictionary changed size during iteration
View Code
for循环来遍历可变对象时,遍历顺序在最初就确定了,而在遍历中如果增加删除了元素,更新会立即反映到迭代的条目上,会导致当前索引的变化,这样一是会导致漏删或多增加元素,二是会导致遍历超过链表的长度。那么有解决方案吗?
a) 通过创建一个新的可变对象实现,比如:
b) 通过while循环
1 #通过创建新的copy
2 for item inlst[:]:3 if item ==0:4 lst.remove(item)5 print(lst)6 #通过while循环
7 while 0 inlst:8 lst.remove(0)9 print (lst)
View Code
更多的内容,看我关于“迭代器”的博客
3)访问模型

序列是指容器内的元素按从0开始的索引顺序访问;
字典的元素是一个一个的键值对,类似于哈希表;通过获取键,对键执行一个哈希操作,根据计算的结果,选择在数据结构的某个地址中存储你的值。任何一个值的存储地址取决于它的键;所以字典是无序的,键必须是不可变类型(对于元祖,只能是元素不可变的元祖)
总结:
既然字符串,列表,元祖,字典都是对象,那么任何一种实例化的对象都会有相同的方法,下面让我们来依次来认识这些常见的数据类型:
4. 字符串
1)创建字符串
两种方式:
#直接创建字符串引用
s = 'winter'
#通过使用str()函数创建
s = str(123)
2)字符串方法
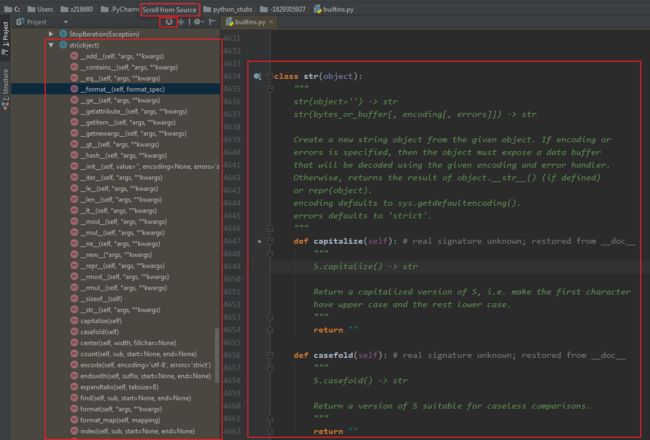
作为内建对象,字符串类的定义在内建模块builtins中,通过源码可以查看到所有字符串方法;如果你在用pycharm,那么更加方便,选中str类以后,点击按钮"Scroll from Source";就可以看到所有方法的列表;
针对每一种方法都有详细的方法文档;在这里吐血一一罗列出,有的注释部分很重要:
1 '''字符串方法'''
2
3 #index,字符串查找,返回第一个匹配到的索引值,没有就报错,可以提供开始,结束位置
4 s = 'xyzabc'
5 ret = s.index('za') #结果为2
6 ret = s.index('z',2) #结果为2
7 #rindex,反向查找,结果和index方法得到的结果一样
8 #find,也是字符串查找,与index不同的是找不到时,不会报错,而是返回-1,注意bool(-1)为True
9
10
11 #split,字符串分隔,如果不指定分割符,则默认采用任意形式的空白字符:空格,tab(\t),换行(\n),回车(\r)以及formfeed
12 res = 'a b c d\ne'.split() #结果res为['a', 'b', 'c', 'd', 'e']
13 res = 'a:b:c:d'.split(':') #结果为['a', 'b', 'c', 'd']
14 #rsplit,从字符串尾部开始分割,没有设置maxsplit参数时和split的结果一样
15 #splitlines用于将多行字符串,列表的每个元素为一行字符串,默认不带换行符
16
17
18 #partition,类似于s.split(sep, 1),只是输出是一个包括了sep的元祖,且没有默认分隔符sep
19 res = 'a:b:c:d'.partition(':') #结果为('a', ':', 'b:c:d')
20 #rpartition,从字符串末尾开始执行partition方法
21 res = 'a:b:c:d'.rpartition(':') #结果为('a:b:c', ':', 'd')
22
23
24 #strip,去掉字符串两端的字符,如果没指定字符,则默认去掉任意形式的空白字符:空格,tab(\t),换行(\n),回车(\r)以及formfeed
25 res = 'abcd'.strip('a') #结果res为'bcd'
26 res = 'abcd \n'.strip() #结果res为'abcd',可以通过len(res)验证
27 #rstrip,去掉右端的字符
28 #lstrip,去掉左端的字符
29
30
31 #join,字符串拼接
32 #format,字符串格式化
33 #解决万恶的‘+’号,每次'+'操作都会创建一个新的对象,就需要在内存空间开辟一块新的区域来存储;所以大量使用'+'会浪费内存空间
34 #解决方法1,使用join
35 #join,字符串拼接
36 li = ['a', 'b']37 res = ':'.join(li) #使用字符串来拼接一个可迭代对象的所有元素,结果res为'a:b'
38 #解决方法2,使用format,有两种方式:
39 #方式1,其中{0}可以简写为{}:
40 res = 'my name is {0}, my age is {1}'.format('winter',30) #{0},{1}为实参的索引
41 #方式2:
42 res = 'my name is {name}, my age is {age}'.format(name='winter', age=30)43 #或者直接下面这样
44 userInfo = {'name':'winter','age':30}45 res = 'my name is {name}, my age is {age}'.format(**userInfo)46 #或者用format_map(python3.x新增)
47 userInfo = {'name':'winter','age':30}48 res = 'my name is {name}, my age is {age}'.format_map(userInfo)49 #解决方法3,除了format以外,还可以使用占位符%,看上去没那么高级,同样有两种方式
50 #方式1
51 res = 'my name is %s, my age is %s'%('winter',30)52 #方式2
53 userInfo = {'name':'winter','age':30}54 res = 'my name is %(name)s, my age is %(age)s'%userInfo55 #结果为'my name is winter, my age is 30'
56
57 #replace,字符串替换,因为字符串为不可变数据类型,所以原字符串不会改变,改变的字符串以返回值形式返回
58 s = '123xyz'
59 ret = s.replace('1','a') #结果s不变,ret为'a23xyz'
60 ret = s.replace('12', 'ab') #结果为'ab3xyz'
61
62
63 #maketrans和translate,一对好基友;用于字符串替换和删除,很好用,python2.x与python3.x语法不同
64 #maketrans用于创建翻译表,translate用于翻译表
65 s = 'abccba'
66 trans_table = str.maketrans('ab','12','c')67 res = s.translate(trans_table) #结果为'1221',注意与replace的区别
68
69
70 s.count(strings) #count,统计字符串中字符的数目
71
72
73 s.encode() #以某种编码格式编码,比如utf-8
74
75
76 #大小写切换类方法
77 s = 'aBcD'
78 res = s.capitalize() #首字母大写,结果res为'Abc'
79 res = s.lower() #所有字母小写,结果res为'abcd',注意仅对ASCII编码的字母有效
80 res = s.casefold() #所有字母小写,结果res为'abcd',注意对unicode编码的字母有效
81 res = s.upper() #所有字母大写,结果res为'ABCD'
82 res = s.swapcase() #字符串中大小写互换,结果res为'AbCd'
83 s = 'aB cD,ef'
84 res = s.title() #每个单词首字母大写,结果res为'Ab Cd,Ef',其判断“单词”的依据则是基于空格和标点
85
86
87 #字符串判断类方法,以下方法除了isspace()以外,对于空字符串都返回False
88 s.isalpha() #判断字符串是否全为字母,等价于^[a-zA-Z]+$
89 s.islower() #判断字符串中字母部分是否全为小写字母,可以有其他字符,但是至少要有一个小写字母,等价于[a-z]+
90 s.isupper() #判断字符串中字母部分是否全为小写字母,可以有其他字符,但是至少要有一个小写字母,等价于[A-Z]+
91 s.istitle() #判断字符串首字母是否全为大写,可以有其他字符
92 s.isnumeric() #判断字符串是否全为数字(包括unicode数字,罗马数字,汉字数字)
93 s.isdigit() #也是判断字符串是否全为数字(包括unicode数字,罗马数字)
94 s.isdecimal() #判断字符串是否全为十进制数字(包括unicode数字)
95 s.isalnum() #判断字符串是否为数字与字母的组合,等价于^[0-9a-zA-Z]+$
96 s.isidentifier() #判断标识符是否合法
97 s.isspace() #判断是否为任意形式的空白字符:空格,tab(\t),换行(\n),回车(\r)以及formfeed
98 s.isprintable() #判断字符串是否可打印
99 s.startswith(strings) #判断字符串是否以某个字符串开头
100 s.endswith(stings) #判断字符串是否以某个字符串结尾
101
102
103 #center,ljust,rjust,zfill字符串排版,填充
104 s = '123'
105 res = s.center(50,'-') #center是字符串居中,结果为-----------------------123------------------------
106 #ljust为居左,rjust为居右,zfill使用0来左填充
107
108
109 s.expandtabs() #expandtables,用于将字符串中的tab字符转换为空格,如果没有指定tabsize,默认为8个
View Code
5. 列表
1)创建列表
三种方式:
a = ['a','b','c'] #直接创建
b = list('abc') #通过创建list实例创建,结果为['a','b','c']
c = [x for x in range(4)] #列表推导式,结果为[1,2,3,4]
注意,第二种方法,我们来看一下它的构造函数:
def __init__(self, seq=()): #known special case of list.__init__
"""list() -> new empty list
list(iterable) -> new list initialized from iterable's items
# (copied from class doc)"""
pass
View Code
接收的参数是一个可迭代对象,即拥有__iter__方法的对象,元祖,集合和字典的构造函数的参数都是可迭代对象;
第三种方法称为列表推导式,语法为
[expr for iter_var in iterable] #迭代iterable里所有内容,每一次迭代,都把iterable里相应内容放到iter_var中,再在表达式中应用该iter_var的内容,最后用表达式的计算值生成一个列表。
扩展形式
[expr for iter_var in iterable if cond_expr] #加入了判断语句
2)列表方法
与查看字符串方法类似,可以通过源码查看,这里也一一罗列出:
1 #增,append,insert,extend
2 #追加append
3 li = ['a','b','c']4 li.append('d') #结果li = ['a','b','c','d'],list是可变类型,所以li元素的增加删除会影响源列表
5 #插入insert
6 li = ['a','b','c']7 li.insert(1,'d') #结果li = ['a','d','b','c']
8 #extend,将一个可迭代对象增加追加到列表里
9 li = ['a','b','c']10 li.extend(['x','y']) #结果li = ['a','b','c','x','y']
11 li.extend(('m','n')) #结果li = ['a', 'b', 'c', 'x', 'y', 'm', 'n']
12
13
14 #删,remove,pop,clear
15 #remove,删除第一个与参数值相等的元素,删除不存在的元素报ValueError
16 li = ['a','b','c','a']17 li.remove('a') #结果li = ['b', 'c', 'a']
18 #pop,参数为索引值,弹出对应索引值的元素,返回值为弹出的元素,默认为弹出最后一个元素,索引不存在报IndexError
19 li = ['a','b','c','a']20 res = li.pop(1) #结果res = ‘b',li = ['a', 'c', 'a']
21 #clear,清空列表,但是列表对象依然存在,没有被回收
22 li = ['a','b','c','a']23 li.clear() #结果li = []
24
25
26 #查,count,index
27 #count,统计列表内元素个数
28 li = ['a','b','c','a']29 res = li.count('a') #结果res = 2
30 #index,查找元素对应的索引值,不存在报ValueError
31 li = ['a', 'b', 'c', 'a']32 res = li.index('a') #结果res = 0
33
34
35 #reverse,反转
36 li = ['a','b','c']37 li.reverse() #结果li = ['c','b','a']
38
39
40 #sort,根据key排序,默认从小到大,同样可以实现反转
41 li = ['c','b','a']42 li.reverse() #结果li = ['a', 'b', 'c']
43 li = [[4,5,6], [7,2,5], [6,1,8]]44 li.sort(key=lambda x:x[1]) #结果li = [[6, 1, 8], [7, 2, 5], [4, 5, 6]],根据li元素的第二个值进行排序
45
46
47 #copy,浅复制,注意与赋值和深复制的区别
48 li = [[1,2,3], 'a']49 li_new =li.copy()50 li_new[0][0] = 4 #li_new = [[4, 2, 3], 'a'],但是li也发生了变化li = [[4, 2, 3], 'a']
51 li_new[1] = 'b' #li_new = [[1, 2, 3], 'b'],但是li不变,[[1, 2, 3], 'a']
View Code
6. 元祖
1)创建元祖
两种方式:
t = (1,2,3) #直接创建
t = tuple([1,2,3]) #通过tuple函数创建,参数为可迭代对象,结果为(1,2,3)
2)元祖方法
和字符串,一样,通过源码查看,这里一一列出:
#count,统计元祖内元素个数
t = (1,2,3,1)
res= t.count(1) #结果res = 2
#index,查找元素对应的索引值,不存在报ValueError
t = (1,2,3,1)
res= t.index(1) #结果res = 0
View Code
元祖的方法很少,而且元祖对象是不可变的,元组不可变的好处。保证数据的安全,比如我们传数据到一个不熟悉的方法或者数据接口, 确保方法或者接口不会改变我们的数据从而导致程序问题。
注意,因为()处理用于定义元祖,还可以作为分组操作符,比如if ( a> b) and (a < c)中的(),且python遇到()包裹的单一元素,首先会认为()是分组操作符,而不是元组的分界符,所以一般我们对于元组,会在)之前再加入一个,
a = (1,2,3,)
3) 列表vs元组
使用不可变类型变量的情况:如果你在维护一些敏感数据,并且需要把这些数据传递给一个不了解的函数(或一个根本不是你写的API),作为一个只负责一个软件某一部分的工程师,如果你希望你的数据不要被调用的函数篡改,考虑使用不可变类型的变量;
需要可变类型参数的情况:管理动态数据集合时,你需要先创建,然后渐渐地不定期地添加,或者有时需要移除一些单个的元素,这时必须使用可变类型对象;将可变类型变量作为参数传入函数,在函数内可以对参数进行修改,可变类型变量也会相应修改;
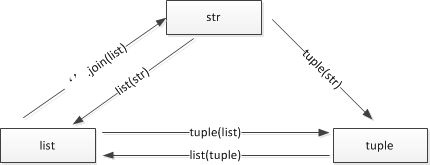
7. 序列共有特性
字符串,列表,元祖统称序列,是可以顺序访问的;他们的关系和共有特性如下:
1)相互转换
2)序列操作符

a)根据索引取值,可以正向索引,也可以反向索引

li = [1,2,3,4]
res= li[0] #结果为1
res = li[-1] #结果为4
li[1] = ['a'] #结果li = [1,'a',3,4]
View Code
b)切片
seq[ind1:ind2:step],原则是顾头不顾尾
li = [1,2,3,4]
res= li[:] #结果为[1, 2, 3, 4]
res = li[1:] #结果为[2,3,4]
res = li[:-2] #结果为[1,2]
res = li[1:3] #结果为[2,3]
res = li[::2] #取索引值为偶数的元素[1,3],对应的li[1::2]为取索引值为基数的元素
res = li[::-1] #步进为-1,结果为[4, 3, 2, 1]
res = li[-1:-3:-1] #结果为[4,3]
res = li[3:1:-1] #结果为[4,3]
res = li[1:1] #结果为[]
li[1:2] = ['a','b'] #结果li = [1, 'a', 'b', 3, 4]
li[1:1] = [9] #结果li = [1, 9, 'a', 'b', 3, 4],相当于插入
View Code
注意序列不能读写不存在的索引值,但是切片可以
li = [1,2,3]
li[9] #报IndexError
li[1:9] #结果为[2,3]
li[8:9] = [9] #结果为[1,2,3,9]
View Code
c)重复操作符*
[1]*3 #结果为[1,1,1]
[1,2,3]*3 #结果为[1, 2, 3, 1, 2, 3, 1, 2, 3]
View Code
d)连接操作符+
[1,2,3]+[4,5,6] 结果为 [1, 2, 3, 4, 5, 6]
View Code
e)成员关系操作符in, no in
li = [1,2,3]1 in li #结果为True
4 not in li #结果为True
View Code
f)删除序列对象,元素关键字del
l = [1,2,3]del l[0] #结果l为[2,3]
del l #结果访问l后,报NameError
View Code
3)可操作内建函数
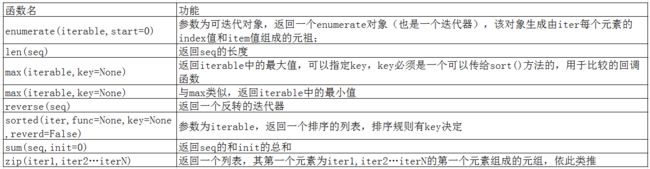
1 #enumerate,枚举
2 li = ['a','b','c']3 for item inenumerate(li):4 print(item)5 '''
6 结果为:7 (0, 'a')8 (1, 'b')9 (2, 'c')10 '''
11 for item in enumerate(li,5):12 print(item)13 '''
14 结果为:15 (5, 'a')16 (6, 'b')17 (7, 'c')18 '''
19
20
21 #len
22 len([1,2,3]) #结果为3
23 len([[1,2],[3,4]]) #结果为2
24
25
26 #max, min
27 max([1,2,3]) #结果为3
28 min([1,2,3]) #结果为1
29
30
31 #sorted,注意与list.sort()方法的区别
32 li = [[1,4],[2,3],[3,2]]33 res = sorted(li, key=lambda x:x[1]) #结果res为[[3, 2], [2, 3], [1, 4]]
34
35
36 #zip,和倒置有点像
37 l1 = [1,2,3]38 l2 = [1,2,3]39 for item inzip(l1,l2):40 print(item)41 '''
42 结果为:43 (1, 1)44 (2, 2)45 (3, 3)46 '''
47 l1 = [1,2,3]48 l2 = [1,2]49 for item inzip(l1,l2):50 print(item)51 '''
52 结果为:53 (1, 1)54 (2, 2)55 '''
View Code
8. 字典
字典是Python语言中唯一的映射类型。映射对象类型里哈希值(键,key)和指向的对象(值,value)是一对多的关系;
特性:
a)字典是无序的可变的容器类型
b)字典的键是唯一的,且必须是不可变类型,如果是元组,要求元组的元素也不可变(因为值的内存地址与键的哈希值有关)
1)创建字典
1 #直接创建
2 d ={3 'name':'winter',4 'age':18,5 'hobbies':['basketball','football']6 }7
8 #通过dict函数创建,参数为可迭代对象,字典或列表组成的任意形式;[(),()]或((),())或([],[])或[[],[]]或使用dict(zip())
9 d = dict([('name', 'winter'),10 ('age',18),11 ('hobbies',['basketball','football'])]) #结果为{'age': 18, 'hobbies': ['basketball', 'football'], 'name': 'winter'}
12
13 #通过字典推导式
14 d = {x:y for x, y in zip(['name','age','hobbies'],['winter',18,['basketball','football']])} #结果为{'age': 18, 'hobbies': ['basketball', 'football'], 'name': 'winter'}
15 d = {x:y for x, y in zip(['name','age','hobbies'],['winter',18,['basketball','football']]) if x=='name'}#结果为{'name': 'winter'}
16
17 #通过字典方法fromkeys()创建一个含有默认值的字典,fromkeys方法是dict类的静态方法
18 d = dict.fromkeys(['name','gender'], 'unknown') #结果{'gender': 'unknown', 'name': 'unknown'}
View Code
2)字典方法
1 #增
2 d ={3 'name':'winter',4 'age':18,5 'hobbies':['basketball','football']6 }7 #update,类似于list.extend(),将键值对参数加到字典中,对于已存在的更新
8 d.update({'gender':'male'}) #结果为:{'age': 18, 'gender': 'male', 'hobbies': ['basketball', 'football'], 'name': 'winter'}
9
10
11 #删
12 d ={13 'name':'winter',14 'age':18,15 'hobbies':['basketball','football']16 }17 #popitem,随机删除一组键值对,并返回该组键值对
18 res = d.popitem() #结果为res = ('hobbies', ['basketball', 'football']), d为{'age': 18, 'name': 'winter'}
19 #pop,删除指定键的键值对,返回对应的值
20 res = d.pop('name') #结果为res = 'winter', d为{'age': 18}
21 #clear,清空字典,字典对象还在,没有被回收
22 d.clear() #结果d为{}
23 #del关键字,可以用于删除字典对象和元素
24 d ={25 'name':'winter',26 'age':18,27 'hobbies':['basketball','football']28 }29 del d['hobbies'] #结果为 {'age': 18, 'name': 'winter'}
30 del d #结果访问d,报NameError
31
32
33 #查
34 d ={35 'name':'winter',36 'age':18,37 'hobbies':['basketball','football']38 }39 #get,根据键取对应的值,没有对应的键,就返回第二个参数,默认为None
40 res = d.get('name', 'not found') #res = ’winter'
41 res = d.get('gender', 'not found') #res = 'not found'
42 #setdefault,根据键取对应的值,如果不存在对应的键,就增加键,值为第二个参数,默认为None
43 res = d.setdefault('name','winter') #res = ’winter'
44 res = d.setdefault('gender','male') #res = 'male',d变为{'age': 18, 'gender': 'male', 'hobbies': ['basketball', 'football'], 'name': 'winter'}
45 #keys,获得所有的键
46 res = d.keys() #res = dict_keys(['name', 'age', 'hobbies', 'gender'])
47 #values,获得所有的值
48 res = d.values() #res = dict_values(['winter', 18, ['basketball', 'football'], 'male'])
49 #items,获得所有的键值对
50 res = d.items() #res = dict_items([('name', 'winter'), ('age', 18), ('hobbies', ['basketball', 'football']), ('gender', 'male')])
51
52
53 #copy方法, 和list.copy一样,是浅复制
View Code
3)字典元素的访问
1 dic = {'name':'winter', 'age':18}2 '''
3 下面3中方式的结果都为4 name winter5 age 186 '''
7 #方式1
8 for item indic:9 print(item, dic[item])10 #方式2
11 for item indic.keys():12 print(item, dic[item])13 #方式3
14 for k,v indic.items():15 print(k, v)
View Code
推荐方式1),采用了迭代器来访问;
4)字典vs列表
a) 字典:
查找和插入的速度极快,不会随着key的数目的增加而增加(直接查找hash后得到的内存地址);
需要占用大量的内存,内存浪费多(大量的hash值,占用内存你空间)
key不可变
默认无序
b) 列表:
查找和插入的时间随着元素的增加而增加
占用空间小,浪费内存很少
通过下标查询
有序
9. 集合
这是高一数学的内容了
集合对象是一组无序排列的值,分为可变集合(set)和不可变集合(frozenset);可变集合不可hash;不可变集合可以hash,即可以作为字典的键;
特性:
a) 无序性,无法通过索引访问
b) 互异性,元素不可重复,即有去重的功能
1) 创建集合
1 #直接创建可变集合
2 s1 = {1,2,3,3} #结果,python3.x为{1,2,3},python2.x为set([1, 2, 3]),因为集合不允许有重复元素,所以只有一个3元素
3 #通过函数创建
4 s2 = set([1,2,3,4]) #创建可变集合{1, 2, 3, 4}
5 s3 = frozenset([1,2,3,3]) #创建不可变集合,结果为frozenset({1, 2, 3})
View Code
2) 集合方法和操作符
这里直接用一张表:
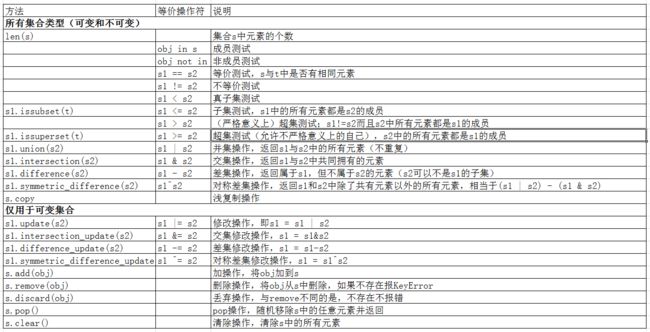
这里只列出可变集合的方法示例,因为不可变集合的方法可变集合都有
a) 单个集合的操作
1 #集合
2
3 #直接创建可变集合
4 s1 = {1,2,3,3} #结果,python3.x为{1,2,3},python2.x为set([1, 2, 3]),因为集合不允许有重复元素,所以只有一个3元素
5 #通过函数创建
6 s2 = set([1,2,3,4]) #创建可变集合{1, 2, 3, 4}
7 s3 = frozenset([1,2,3,3]) #创建不可变集合,结果为frozenset({1, 2, 3})
8
9
10 s1 = {1,2,3}11
12 #增
13 s1.add('456') #结果s1 = {1, 2, 3, '456'}
14 s1.update('789') #结果s1 = {1, 2, 3, '7', '8', '9', '456'}
15
16 #删
17 res = s1.pop() #结果res = 1,s1 = {2, 3, '7', '8', '9', '456'}
18 s1.remove(3) #结果s1 = {2, '7', '8', '9', '456'}
19 s1.discard(4) #结果s1 = {2, '7', '8', '9', '456'},同时不报Error
20 s1.clear() #结果s1 = set()
21
22 #浅复制
23 s1 = {1,2,3}24 s2 = s1.copy() #结果s2 = {1,2,3}
View Code
b) 集合之间的操作,集合的主要功能
1 s0 = {1,2}2 s1 = {1,2,3,4}3 s2 = {3,4,5,6}4
5 #子集,超级判断
6 res = s0.issubset(s1) #结果res = True
7 res = s1.issubset(s2) #结果res = False
8 res = s1.issuperset(s0) #结果res = True
9 res = s0 <= s1 #结果res = True
10
11 #并集
12 res = s1.union(s2) #结果res = {1, 2, 3, 4, 5, 6}
13 res = s1 | s2 #结果res = {1, 2, 3, 4, 5, 6}
14
15 #交集
16 res = s1.intersection(s2) #结果为{3, 4}
17 res = s1 & s2 #结果为{3, 4}
18
19 #差集
20 res = s2.difference(s1) #结果res = {5, 6}
21 res = s2 - s1 #结果res = {5, 6}
22 res = s1.difference(s2) #结果res = {1, 2}
23
24 #对称差集
25 res = s2.symmetric_difference(s1) #结果为{1, 2, 5, 6}
26 res = s2 ^ s1 #结果为{1, 2, 5, 6}
27
28 #在原集合基础上修改原集合
29 s1.intersection_update(s2)30 s1.difference_update(s2)31 s1.symmetric_difference_update(s2)
View Code
用一张图来解释一下:
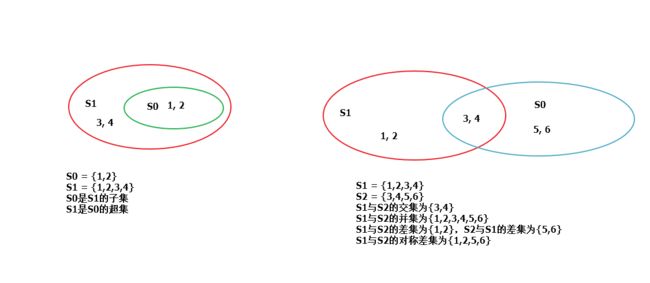
2017年9月20日更新
1. 推导式
有列表推导式,字典推导式,集合推导式
1)列表推导式
1 li_1 = [item for item in range(5)] #结果li_1 = [0, 1, 2, 3, 4]2
3 li_2 = [item for item in range(5) if item > 2] #结果li_2 = [3, 4]4
5 li_3 = [item if item>2 else 0 for item in range(5)] #结果li_3 = [0, 0, 0, 3, 4]6
7 li_4 = [(x,y) for x in range(3) for y in range(3,6)] #结果li_4 = [(0, 3), (0, 4), (0, 5), (1, 3), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5)]8
9 li_raw = [['winter', 'tom', 'lily'], ['winter']]10 li_5 = [item for li in li_raw for item in li if item.count('l') > 1] #结果li_5 = ['lily']
View Code
2)集合推导式
和列表推导式一样,只要把[]换成{}即可
3)字典推导式
和列表推导式一样,只是没有if...else...形式
4)有元祖推导式吗?
(x for x in range(5))就是元祖推导式呢?
答案是:不是的
(x for x in range(5)得到的是一个生成器
>>>a = (x for x in range(10))>>>a>>> at 0x0000000004B09F68>
>>>a.__next__()
>>>0
>>>a.__next__()
>>>1