⭐全网最强Java基础总结 ⭐,质量不行你直接拉黑我就行
个人主页: Java程序鱼
如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和订阅专栏
微信号:hzy1014211086,想加入技术交流群的小伙伴可以加我好友,群里会分享学习资料、学习方法
| 序号 | 内容 |
|---|---|
| 1 | 面试题专栏 |
| 2 | Redis专栏 |
| 3 | SpringBoot专栏 |
文章目录
- 一、第一个Java程序
- 二、八种基本数据类型
- 三、包装类型
- 四、缓存池
- 五、String
-
- 1.常用API
- 2.字符串池(String Pool)
- 3.字符串拼接操作
- 4.拼接操作与append操作的效率对比
- 5.为什么 String 在 Java 中是不可变的?
- 6.String、StringBuffer、StringBuilder的区别
- 五、变量
-
- 1.局部变量
- 2.实例变量
- 3.静态变量
- 五、运算符
-
- 1.赋值运算符
- 2.算术运算符
- 3.关系运算符
- 4.逻辑运算符
- 5.位运算符
- 6.位移操作符
- 7.三元运算符
- 六、条件语句
-
- 1.if
- 2.if...else
- 3.if...else if...else
- 4.嵌套的 if…else
- 八、switch case
- 九、循环
-
- 1.while循环
- 2.do…while 循环
- 3.for 循环
- 4.break 关键字
- 5.continue
- ❤️ 彩蛋
一、第一个Java程序
public class HelloWorld {
public static void main(String[] args) {
System.out.println("hello world");
}
}
我给大家介绍下上述代码:
- class:这是一个关键字,用于在Java中声明一个类。
- public:这是一个关键字,表示公开的访问修饰符。这意味着它对所有人可见。
- static:这是是一个关键字。如果我们将任何方法声明为静态方法,则称为静态方法。静态方法的核心优点是,不需要创建对象来调用静态方法。main方法由JVM执行,因此不需要创建对象来调用main方法。这样可以节省内存。
- void:是方法的返回类型。意味着它不返回任何值。
- main:代表程序的起点。
- String[] args:用于命令行参数。我们稍后会学习。
- System.out.println():用于打印输出的语句。System是一个类,out是PrintStream类的对象,println() 是PrintStream类的方法。
二、八种基本数据类型
Java 中有 8 种基本数据类型,分别为:
4 种「 整数 」类型:byte、short、int、long
2 种「 浮点 」类型 :float、double
1 种「 字符 」类型:char
1 种「 布尔 」型:boolean
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 基本类型 | 位数 | 字节 | 默认值 |
|---|---|---|---|
| int | 32 | 4 | 0 |
| short | 16 | 2 | 0 |
| long | 64 | 8 | 0L |
| byte | 8 | 1 | 0 |
| char | 16 | 2 | ‘u0000’ |
| float | 32 | 4 | 0f |
| double | 64 | 8 | 0d |
| boolean | 1 | false |
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是官方未明确定义,它依赖于 JVM 厂商的具体实现。
三、包装类型
每个基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 100; // 装箱 调用了 Integer.valueOf(100)
int y = x; // 拆箱 调用了 x.intValue()
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
Integer x = 100 等价于 Integer x = Integer.valueOf(100);
int y = x 等价于 int y = x.intValue();
四、缓存池
Java 基本类型的包装类的大部分都实现了常量池技术。Byte、Short、Integer、Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在[0,127]范围的缓存数据,Boolean 直接返回 True Or False。
Integer 缓存源码:
/**
* 此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
* @param i
* @return
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
}
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
System.out.println(i1 == i2); // 输出 true
Integer y1 = 128;
Integer y2 = 128;
System.out.println(y1 == y2); // 输出 false
}
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
public static void main(String[] args) {
Float i1 = 1f;
Float i2 = 1f;
System.out.println(i1 == i2);// 输出 false
Double y1 = 1.2;
Double y2 = 1.2;
System.out.println(y1 == y2);// 输出 false
}
两种浮点数类型的包装类 Float、Double 「 并没有实现常量池技术 」。
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = new Integer(100);
System.out.println(i1 == i2); // false
}
new Integer(100) 与 Integer.valueOf(100) 的区别在于:
- new Integer(100) 「 每次都会新建一个对象 」。
- Integer.valueOf(100) 会使用缓存池中的对象,「 多次调用会取得同一个对象的引用 」。
五、String
字符串就是一系列字符,在Java中,字符串可以包含任意 Unicode 字符。例如,字符串Java™或字符串Java\u2122 是由5个Unicode字符J、a、v、a和™组成的。最后一个字符是"U+211商标"。
public static void main(String[] args) {
System.out.println("Java\u2122");
}
打印结果:Java™
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,「 因此可以保证 String 不可变 」。
1.常用API
这块大家可以自行上官网查看,然后自己动手写一写,这块比较简单。
Java官网 String:https://docs.oracle.com/javase/8/docs/api/java/lang/String.html
2.字符串池(String Pool)
在工作中,String类是我们使用频率非常高的一种对象类型。JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,即字符串池(String Pool)。字符串池由 String 类私有的维护。
我们知道,在Java中有两种创建字符串对象的方式:
- 采用字面值的方式赋值
- 采用new关键字新建一个字符串对象。
这两种方式在性能和内存占用方面存在着差别。
public static void main(String[] args) {
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2); // true
}
采用字面值的方式创建一个字符串时, 「 首先会去字符串池中查找是否存在"abc"这个对象 」,如果不存在,则在字符串池中创建"abc"这个对象,然后将池中"abc"这个对象的引用地址返回给字符串常量str,这样str会指向池中"abc"这个字符串对象;如果存在,则不创建任何对象,直接将池中"abc"这个对象的地址返回,赋给字符串常量。因此,上面案例中,str1==str2 得到的结果是 true。
public static void main(String[] args) {
String str3 = new String("abc");
String str4 = new String("abc");
System.out.println(str3 == str4); // false
}
采用new关键字新建一个字符串对象时,JVM首先在字符串池中查找有没有"abc"这个字符串对象,如果有,则不在池中再去创建"abc"这个对象了,直接在堆中创建一个"abc"字符串对象,然后将堆中的这个"abc"对象的地址返回赋给引用str3,这样,str3就指向了堆中创建的这个"abc"字符串对象;如果没有,则首先在字符串池中创建一个"abc"字符串对象,然后再在堆中创建一个"abc"字符串对象,然后将堆中这个"abc"字符串对象的地址返回赋给str3引用,这样,str3指向了堆中创建的这个"abc"字符串对象。因此,上面案例中,str3==str4 得到的结果是 false。
字符串池的实现有一个前提条件:「 String对象是不可变的 」。因为这样可以保证多个引用可以同事指向字符串池中的同一个对象。如果字符串是可变的,那么一个引用操作改变了对象的值,对其他引用会有影响,这样显然是不合理的。
3.字符串拼接操作
@Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";//编译期优化(在编译时得到的结果,s4会指向字符串常量池)
//如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果:javaEEhadoop(在运行时得到的结果)
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//false
System.out.println(s5 == s6);//false
System.out.println(s5 == s7);//false
System.out.println(s6 == s7);//false
//intern():判断字符串常量池中是否存在javaEEhadoop值,如果存在,则返回常量池中javaEEhadoop的地址;
//如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回次对象的地址。
String s8 = s6.intern();
System.out.println(s3 == s8);//true
final String s9 = "a";
final String s10 = "b";
String s11 = "ab";
String s12 = s9 + s10;
System.out.println(s11 == s12);//true
}
- 常量与常量的拼接结果在常量池,原理是编译期优化
- 拼接过程中,只要其中有一个是变量,结果就在堆中(相当于在堆空间中new String)。变量拼接的原理是StringBuilder
- intern():判断字符串常量池中是否存在javaEEhadoop这个值,如果存在,则返回常量池中地址,如果不存在,则在常量池中加载一份并返回地址
- 如果拼接符左右两边都是字符串常量或常量引用,则仍然使用编译期优化
这部分内容可能比较难理解,如果有小伙伴理解不了,可以先记录下来,跳过去学习其他的内容,等你有一定的代码量积累了,在反过头来看就简单了。
4.拼接操作与append操作的效率对比
public void test1(int highLevel){
String src = "";
for (int i = 0; i < highLevel; i++) {
src = src + "a";
}
}
public void test2(int highLevel){
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
}
通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式。
- StringBuilder的append方式,自始至终只创建一个StringBuilder的对象,使用String的字符串拼接方式会创建多个StringBuilder对象和String对象
- 使用 String 的字符串拼接方式会创建多个 StringBuilder 对象和 String 对象,内存占用更大,如果进行GC,需要花费额外的时间
改进空间:如果基本确定长度,建议使用构造器指定StringBuilder底层数组的长度,避免多次扩容消耗
这部分内容可能比较难理解,如果有小伙伴理解不了,可以先记录下来,跳过去学习其他的内容,等你有一定的代码量积累了,在反过头来看就简单了。
5.为什么 String 在 Java 中是不可变的?
- 提供程序运行效率,只有字符串是不可变时,我们才能实现JVM中的字符串常量池,字符串常量池可以为我们缓存字符串,提供程序运行效率
- 安全,比如在核心业务操作之前,可能会有一系列校验,校验String字符串的合法性,如果是可变的话,在校验过后,它的内部值又被改变了,这可能会引发一系列问题,这是迫使String类设计成不可变的一个重要原因。
- 缓存hashCode,字符串的 hashCode 在 Java 中经常使用。例如,在 HashMap 或 HashSet 中。不可变保证了 hashcode 始终相同,这意味着只需要计算一次hashCode就行了,这样效率更高。
- 线程安全,String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
6.String、StringBuffer、StringBuilder的区别
String、StringBuffer、StringBuilder 三个都可以存储字符串,其中String只读字符串,它的值不可改变长度也是固定的,而StringBuffer、StringBuilder类表示的字符串可以直接进行修改。StringBuilder是JDK1.5中引入的,他和StringBuffer的方法完全相同,区别在于StringBuilder是单线程环境下使用的,因为它的所有方法都没有被synchronized修饰,因此它的效率比StringBuffer高。
五、变量
变量是在执行Java程序时保存值的容器。变量分配有数据类型。
变量是内存位置的名称。Java中存在三种类型的变量:局部变量,实例变量和静态变量。
1.局部变量
- 局部变量声明在方法、构造方法或者语句块中
- 局部变量在「 方法、构造方法、或者语句块被执行的时候创建」,当它们执行完成后,变量将会被销毁
- 局部变量只在声明它的方法、构造方法或者语句块中可见
- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用
- 局部变量不能用「 static 」关键字定义
2.实例变量
在类内部但在方法主体外部声明的变量称为「 实例变量 」。它没有声明为static。
- 实例变量声明在一个类中,但在方法、构造方法和语句块之外
- 实例变量在「 对象创建的时候创建 」,在对象被销毁的时候销毁
- 实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见
- 实例变量具有默认值
3.静态变量
- 类变量也称为静态变量,在类中以static关键字声明,但必须在方法构造方法和语句块之外
- 无论一个类创建了多少个对象,类只拥有类变量的一份拷贝
- 静态变量在「 第一次被访问时创建 」,在程序结束时销毁
- 与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为public类型
- 静态变量具有默认值
静态变量和实例变量的区别:
- 调用方式
- 可以直接通过类名调用。也可以通过对象实例调用。这个变量属于类。(new Student().name、Student.name)
- 只能通过对象实例调用。这个变量属于对象。(new Student().name)
- 生命周期
- 静态变量随着类的加载而存在,随着类的消失而消失。生命周期长。
- 实例变量随着对象的创建而存在,随着对象的消失而消失。
- 与对象的相关性
- 静态变量是所有对象共享一份数据。
- 实例变量是每个对象独享一份数据。
public class HelloWorld {
int x = 50; // 实例变量
static int y = 100; // 静态变量
void method() {
int z = 90; // 局部变量
}
}
五、运算符
1.赋值运算符
赋值运算符(=)用于为变量赋值
int count = 1;
2.算术运算符
public static void main(String[] args) {
int x = 1 + 2;
int y = 2 - 1;
int z = 2 * 1;
int i = 4 / 2;
int t = 9 % 3; // 结果是0,取余
int k = -i; // 结果是-2,取反运算
// ++和--运算符可以放在变量之前,也可以放在变量之后,当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。
int q = 0;
System.out.println(q++); // 0
int w = 0;
System.out.println(++w); // 1
}
3.关系运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| == | 检查如果两个操作数的值是否相等,如果相等则条件为真。 | (A == B)为假。 |
| != | 检查如果两个操作数的值是否相等,如果值不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是那么条件为真。 | (A> B)为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是那么条件为真。 | (A |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是那么条件为真。 | (A> = B)为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是那么条件为真。 | (A <= B)为真。 |
4.逻辑运算符
| 操作符 | 描述 | 例子 |
|---|---|---|
| && | 称为逻辑与运算符。当且仅当两个操作数都为真,条件才为真。 | (A && B)为假。 |
| | | | 称为逻辑或操作符。如果任何两个操作数任何一个为真,条件为真。 | (A || B)为真。 |
| ! | 称为逻辑非运算符。用来反转操作数的逻辑状态。如果条件为true,则逻辑非运算符将得到false。 | !(A && B)为真。 |
- && 与 & 区别:&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。&&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式
- || 与 | 区别:短路或与短路与同理。
5.位运算符
A = 0011 1100
B = 0000 1101
--------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~A= 1100 0011
下表列出了位运算符的基本运算,假设整数变量 A 的值为 60 和变量 B 的值为 13:
| 操作符 | 描述 | 例子 |
|---|---|---|
| & | 如果相对应位都是1,则结果为1,否则为0 | (A&B),得到12,即0000 1100 |
| | | 如果相对应位都是 0,则结果为 0,否则为 1 | (A | B)得到61,即 0011 1101 |
| ^ | 如果相对应位值相同,则结果为0,否则为1 | (A ^ B)得到49,即 0011 0001 |
| 〜 | 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 | (〜A)得到-61,即1100 0011 |
public class Test {
public static void main(String[] args) {
int a = 60; /* 60 = 0011 1100 */
int b = 13; /* 13 = 0000 1101 */
int c = 0;
c = a & b; /* 12 = 0000 1100 */
System.out.println("a & b = " + c );
c = a | b; /* 61 = 0011 1101 */
System.out.println("a | b = " + c );
c = a ^ b; /* 49 = 0011 0001 */
System.out.println("a ^ b = " + c );
c = ~a; /*-61 = 1100 0011 */
System.out.println("~a = " + c );
}
}
6.位移操作符
(1)<<
左移位运算符为 << ,其运算规则是:按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。
例如,将整数 11 向左位移 1 位的过程如下图所示。

从上图可以看到,原来数的所有二进制位都向左移动 1 位。原来位于左边的最高位 0 被移出舍弃,再向尾部追加 0 补位。最终到的结果是 22,相当于原来数的 2 倍。
(2)>>
右位移运算符为 >> ,其运算规则是:按二进制形式把所有的数字向右移动对应的位数,低位移出(舍弃),高位的空位补零。
例如,将整数 11 向右位移 1 位的过程如下图所示。
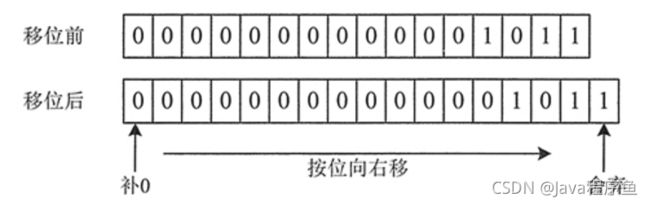
从上图可以看到,原来数的所有二进制位都向右移动 1 位。原来位于右边的最低位 1 被移出舍弃,再向最高位追加 0 补位。最终到的结果是 5,相当于原数整除 2 的结果。
(3)>>>
无符号右移运算符
无符号右移运算符和右移运算符是一样的,不过无符号右移运算符在右移的时候是补0的,而右移运算符是补符号位的。
7.三元运算符
条件运算符也被称为三元运算符。该运算符有3个操作数,并且需要判断布尔表达式的值。该运算符的主要是决定哪个值应该赋值给变量。
variable x = (expression) ? value if true : value if false
public class Test {
public static void main(String[] args){
int a , b;
a = 10;
// 如果 a 等于 1 成立,则设置 b 为 20,否则为 30
b = (a == 1) ? 20 : 30;
System.out.println( "Value of b is : " + b );
// 如果 a 等于 10 成立,则设置 b 为 20,否则为 30
b = (a == 10) ? 20 : 30;
System.out.println( "Value of b is : " + b );
}
}
六、条件语句
一个 if 语句包含一个布尔表达式和一条或多条语句。
1.if
if(布尔表达式)
{
//如果布尔表达式为true将执行的语句
}
2.if…else
if 语句后面可以跟 else 语句,当 if 语句的布尔表达式值为 false 时,else 语句块会被执行。
if(布尔表达式){
//如果布尔表达式的值为true
}else{
//如果布尔表达式的值为false
}
3.if…else if…else
if(布尔表达式 1){
//如果布尔表达式 1的值为true执行代码
}else if(布尔表达式 2){
//如果布尔表达式 2的值为true执行代码
}else if(布尔表达式 3){
//如果布尔表达式 3的值为true执行代码
}else {
//如果以上布尔表达式都不为true执行代码
}
4.嵌套的 if…else
if(布尔表达式 1){
如果布尔表达式 1的值为true执行代码
if(布尔表达式 2){
如果布尔表达式 2的值为true执行代码
}else{
如果布尔表达式 2的值为false执行代码
}
}
八、switch case
switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。
switch(表达式){
case 值1 :
//语句块1
break; //可选
case 值2 :
//语句块2
break; //可选
//你可以有任意数量的case语句
default : //可选
//语句
}
switch case 语句有如下规则:
- switch表达式,表达式的值必须为 byte、short、int 或者 char。从 Java SE 7 开始,switch 支持字符串 String 类型了,同时 case 标签必须为字符串常量或字面量。
- switch 语句可以拥有多个 case 语句。每个 case 后面跟一个要比较的值和冒号。
- case的值数据类型必须与表达式的值的数据类型相同。而且只能是常量或者字面常量;case值必须唯一。如果值重复,则会产生编译时错误。
- 当变量的值与 case 语句的值相等时,那么 case 语句之后的语句开始执行,直到 break 语句出现才会跳出 switch 语句。
- 当遇到 break 语句时,switch 语句终止。程序跳转到 switch 语句后面的语句执行。case 语句不必须要包含 break 语句。如果没有 break 语句出现,程序会继续执行下一条 case 语句,直到出现 break 语句。
- switch 语句可以包含一个 default 分支,该分支一般是 switch 语句的最后一个分支(可以在任何位置,但建议在最后一个)。default 在没有 case 语句的值和变量值相等的时候执行。default 分支不需要 break 语句。
switch case 执行时,一定会先进行匹配,匹配成功返回当前 case 的值,再根据是否有 break,判断是否继续输出,或是跳出判断。
public class Test {
public static void main(String[] args) {
int score = 90;
switch (score) {
case 10:
System.out.println("学神");
break;
case 9:
System.out.println("成绩为A");
break;
case 8:
System.out.println("成绩为B");
break;
case 7:
System.out.println("成绩为C");
break;
case 6:
System.out.println("成绩为D");
break;
default:
System.out.println("成绩为E");
break;
}
}
}
九、循环
在Java语言中,循环用于重复执行一组指令/功能。Java中有三种主要的循环结构:
- for循环
- while循环
- do-while循环
1.while循环
// 打印1-10
public class Test {
public static void main(String[] args) {
int i = 1;
// 只要布尔表达式(i<=10)为true,循环就会一直执行下去。
while (i <= 10) {
System.out.println(i++);
}
}
}
2.do…while 循环
对于 while 语句而言,如果不满足条件,则不能进入循环。但有时候我们需要即使不满足条件,也至少执行一次。
do…while 循环和 while 循环相似,不同的是,do…while 循环至少会执行一次。
public class Test {
public static void main(String[] args) {
int i = 1;
do {
System.out.println(i++);
} while (i < 0);
}
}
布尔表达式在循环体的后面,所以语句块在检测布尔表达式之前已经执行了。 如果布尔表达式的值为 true,则语句块一直执行,直到布尔表达式的值为 false。
3.for 循环
for(初始化; 布尔表达式; 更新) {
//代码语句
}
关于 for 循环有以下几点说明:
- 最先执行初始化步骤。可以声明一种类型,但可初始化一个或多个循环控制变量,也可以是空语句。
- 然后,检测布尔表达式的值。如果为 true,循环体被执行。如果为false,循环终止,开始执行循环体后面的语句。
- 执行一次循环后,更新循环控制变量。
- 再次检测布尔表达式。循环执行上面的过程。
// 打印1-10
public class Test {
public static void main(String args[]) {
for (int i = 1; i <= 10; i++) {
System.out.println(i);
}
}
}
Java5 引入了一种主要用于数组的增强型 for 循环。
for(声明语句 : 表达式)
{
//代码句子
}
声明语句:声明新的局部变量,该变量的类型必须和数组元素的类型匹配。其作用域限定在循环语句块,其值与此时数组元素的值相等。
表达式:表达式是要访问的数组名,或者是返回值为数组的方法。
public class Test {
public static void main(String args[]) {
int[] numbers = {
10, 20, 30, 40, 50 };
for (int number : numbers) {
System.out.println(number);
}
}
}
4.break 关键字
break 主要用在循环语句或者 switch 语句中,用来跳出整个语句块。
break 跳出最里层的循环,并且继续执行该循环下面的语句。
public class Test {
public static void main(String args[]) {
for (int i = 1; i <= 10; i++) {
System.out.println(i);
// 执行到i==5就停止
if(i == 5){
break;
}
}
}
}
如果有两层for循环,我们想让最外层的for停止怎么办?
方案一:
public static void main(String args[]) {
outCycle: for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
if (j == i) {
break outCycle;
}
}
}
}
方案二:
public static void main(String args[]) {
boolean outCycle = true;
boolean innerCycel = true;
for (int i = 0; i < 10 && outCycle; i++) {
for (int j = 0; j < 10 && innerCycel; j++) {
if (j == i) {
outCycle = false;
}
}
}
}
想要停止内层的for循环,我们可以直接break或者把 innerCycel=false,停止外层的for循环只需要把outCycle=false;
5.continue
continue 适用于任何循环控制结构中。作用是让程序立刻跳转到下一次循环的迭代。
在 for 循环中,continue 语句使程序立即跳转到更新语句。
在 while 或者 do…while 循环中,程序立即跳转到布尔表达式的判断语句。
// 打印1-10
public class Test {
public static void main(String args[]) {
for (int i = 1; i <= 10; i++) {
System.out.println(i);
// 跳过i等于5的打印,其他的数字正常打印
if(i == 5){
break;
}
}
}
}
❤️ 彩蛋

「粉丝福利、三连送书 」
「 粉丝专属福利(包邮送书2本,书单里5本书可任选一本) 」

「 抽奖方式:截止到10月10日 14:00,留言获赞最高的两位同学,将获得图书一本,上述5本书可以任选一本 」

Spring Boot 企业级应用开发实战 - 京东图书
Spring Boot 企业级应用开发实战 - 当当图书
作者:柳伟卫(英文名Way Lau),关注编程、系统架构、性能优化。在大型IT公司担任过项目经理、架构师、高级开发顾问等职位,具有多年软件开发管理及系统架构经验。负责过多个大型分布式系统的设计与研发,参与了多个大型项目的微服务架构的技术改造,在实际工作中积累了大量的微服务架构经验。
亮点:
- 「 新 」,本书基于新的Spring Boot 2.0版本编写,深入浅出地讲解了Spring与Spring Boot。
- 「 实战 」,跳脱纯理论讲述,案例贯穿全书,一步步讲述使用Spring Boot开发企业系统的方法。读者不仅能全面学到软件开发技能,还能学到项目实战经验。
- 「 全 」,弥补市面上有关 Spring Boot 学习资料的不足,重新编写整个教学案例,使读者轻松脱离“Hello World”阶段,向Spring Boot企业级快速应用开发跃迁。
「 没中的小伙伴可以等下期,或者自行购买哈 」
Spring Boot 企业级应用开发实战 - 京东图书
Spring Boot 企业级应用开发实战 - 当当图书
亿级流量Java高并发与网络编程实战 - 京东图书
亿级流量Java高并发与网络编程实战 - 当当图书
Java高并发编程指南 - 京东图书
Java高并发编程指南 - 当当图书
Java核心技术及面试指南 - 京东图书
Java核心技术及面试指南 - 当当图书
Spring Cloud 微服务架构开发实战 - 京东图书
Spring Cloud 微服务架构开发实战 - 当当图书
参考文献:
《Java核心技术卷I》
《Oracle Java tutorial》:https://docs.oracle.com/javase/tutorial/java/index.html
因为篇幅问题,面向对象、异常、反射、IO、集合等内容下篇文章发,大家可以持续关注。