自动驾驶nuScenes数据集——一个KITTI以外的新数据集
1. 数据集简介
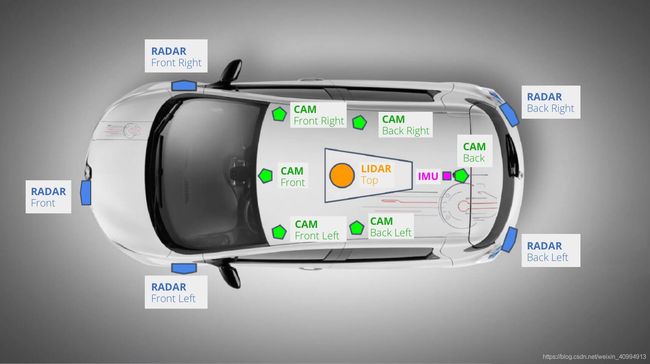 (图片来源:https://www.nuscenes.org/data-collection )
(图片来源:https://www.nuscenes.org/data-collection )
nuScenes数据集 是自动驾驶公司nuTonomy建立的大规模自动驾驶数据集,该数据集不仅包含了Camera和Lidar,还记录了雷达数据,是我所知道的唯一一个有雷达数据的数据集。
这个数据集由1000个场景组成(即scenes,这就是该数据集名字的由来),每个scenes长度为20秒,包含了各种各样的情景。在每一个scenes中,有40个关键帧(key frames),也就是每秒钟有2个关键帧,其他的帧为sweeps。关键帧经过手工的标注,每一帧中都有了若干个annotation,标注的形式为bounding box。不仅标注了大小、范围、还有类别、可见程度等等。这个数据集不久前发布了一个teaser版本(包含100个scenes),正式版(1000个scenes)的数据要2019年发布。
这个数据集在sample的数量上、标注的形式上都非常好,记录了车的自身运动轨迹(相对于全局坐标),包含了非常多的传感器,可以用来实现更加智慧的识别算法和感知融合算法。
本文描述了如何在一个新的Google Cloud Platform(下文简称GCP)Compute Engine - VM instance上使用这个数据集,关于如何创建和使用GCP,有很多现成的材料可以学习,作者最早是通过Stanford CS231n课的谷歌云教程学习的谷歌云。本教程所使用的谷歌云镜像参数如下:
| 参数名称 | 数值 |
|---|---|
| Machine type | n1-standard-4 (4 vCPUs, 15 GB memory) |
| Boot disk and local disks | 100GB SSD persistent disk |
| Source image | ubuntu-1604-xenial-v20181030 |
如果读者想在自己的PC机上面使用这个数据集,则可以跳过从Google Bucket把数据拷贝到server的硬盘中的步骤。
1.1 Setup
数据集可以通过注册nuScenes网站后,在 Download 页面下载,里面有五个下载项,其中metadata and annotation 是必须要下载的,其他数据可以根据需要下载。下载后的数据是 tbz2 格式的压缩文件,需要经过两次解压缩。
在 nuScenes-devkit github page 上面有一个可以用来visualization的开发工具。
1.1.1 Python version
如果想要用nuScenes的开发工具,需要Python 3.7版本,具体的安装方式在上文的github上面有提到,但是较为推荐的是在一个虚拟环境下安装python 3.7。
1.1.2 Python virtual environment
nuScenes-devkit github page 的教程中用的是虚拟环境管理包 virtualenvwrapper 来创建虚拟环境,关于虚拟环境,可以参考 这篇文章 或者virtualenvwrapper 和 virtualenv。其实我个人是偏好使用Anaconda内嵌的虚拟环境管理工具的,关于Anaconda与Virtualenv的比较,“You actually can install (some) conda packages within a virtualenv, but better is to use Conda’s own environment manager: it is fully-compatible with pip and has several advantages over virtualenv.”
Anaconda创建新环境的命令为:
conda create --name myenv
创建了新环境以后进入新环境的命令为:
source activate myenv
(其他命令可以查阅conda 文档 )
1.1.3 Storage buckets
想要使用Google Cloud Platform来下载数据集,我主要采取两个方法,一个方法是在terminal中输入wget + [http address],但是如果想要下载nuScenes数据集,直接用wget是不行的,该数据集需要一定的权限才能访问。另一个方法是这篇博客使用的方法——将数据集从我的本地硬盘传到cloud storage的bucket中,再进入GCP VM instance将数据从bucket拷贝到VM instance的硬盘里。过程如下:
- 进入cloud storage创建一个object
- 将数据集上传到object
- 将数据集从buckets拷贝到instance
在拷贝和解压数据集的过程中,VM instance的硬盘空间可能会不够用(数据占50GB),因此可以考虑讲硬盘的内存调大。这就是Google VM instance的方便之处:随时根据需要设置硬件的参数
命令如下
gsutil cp gs://[buckets object name]/[filename] [target folder name]
for example:
gsutil cp gs://[buckets object name]/nuscenes_teaser_meta_v1.tbz2 ./
2. 数据集的使用
- 解压
bzip2 -d [filename]
- 二次解压
tar xf [filename]
PCD文件
文件 nuscenes.py 的第453行
pc = PointCloud.from_file(osp.join(self.nusc.dataroot, pointsensor['filename']))
Metadata
javascript文件中是每一个元数据的表格,可以用token来identify,这些元数据是用来表达数据之间的对应关系的。比如某一个scene对应哪些sample,这个sample有哪些传感器,传感器又有哪些数据。radar 和 lidar 都是用pcd文件记录的数据,camera 是 jpg。
Shortcut
这个数据集中所有的标注是通过json文件完成的,json文件如同为我们定义了一个graph结构,这个graph里的每一个节点是scene, sample, instance, data, category等等,我们可以通过token在这个graph中寻找我们需要的部分,比如说在多个sample关键帧中找到同一个骑自行车的人。
这个数据集的标注中,只有一对一的对应关系,很少有一对多的对应关系,但是有时候这种对应关系又非常重要,比如说给定一个sample,我想要sample中所有的annotation,又或者给定一个instance,我想要得到所有该instance的annotation,于是在nuScenes提供的dev-kit中,为使用者设置了很多的Shortcuts。即整理好了的“一对多”。
开发者提供的函数
开发者在github上提供了可以用来可视化Nuscenes数据集的函数,叫nusenes.py,在随同提供的Jupyter notebook中这个函数被声明为nusc。注意,真正在Jupyter notebook中使用的很多函数其实在nusc.explore类中,因此如果要在nusc.explorer中定义新的方法,要在nusc中把shortcut加上。
3. 遇到的问题
3.1 没有足够的空间
3.2 opencv版本问题
在运行Jupyter notebook的时候出现错误
cannot open shared object file: No such file or directory
解决办法
sudo apt-get install libsm6 libxrender1 libfontconfig1pip install opencv-contrib-python
3.3 Dataset的位置
如果没有把dataset存到根目录下,也可以把它存到nuscenes-devkit的目录下,然后把路径从dataroot='/data/nuscenes'换成dataroot='./data/nuscenes'。
4. 数据集的可视化
(待填)