实习项目——分布式智能环卫系统开发总结
分布式智能环卫:
项目背景:这是分布式智能环卫系统项目,主要是针对小区物业、环卫公司和政府监管部门以及居民用户等使用的系统。为了小区物业更加智能化,环卫的托运效率提高,社区的管理高效,方便政府和街道部门的监控。而构建的一个系统。
项目架构图

我的工作:
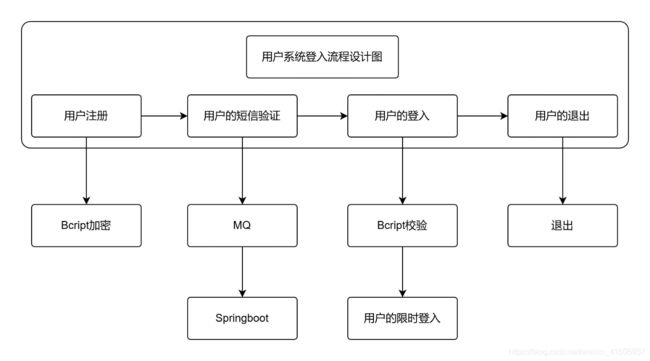
1负责用户登入系统流程设计和开发。
2负责的是数据库部分数据表的优化操作。
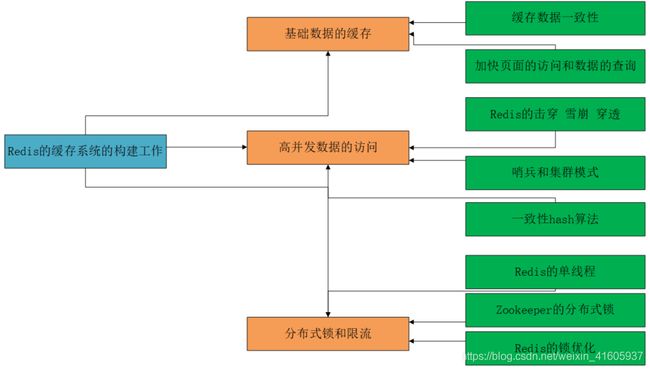
3负责构建redis集群的缓存系统。
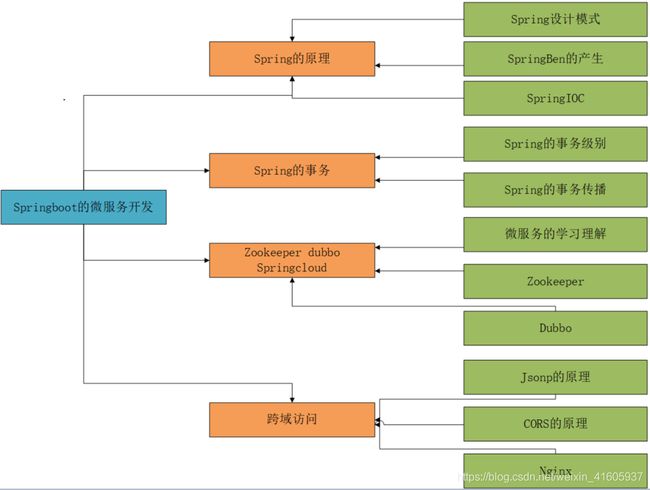
4 Springboot的微服务开发。
这个项目的亮点是:

1单点登入系统的流程原理

这是一个单点登入系统的,我是负责的是用户的注册和登入功能的实现。
过滤器与拦截器原理分析与区别
|
|
实现原理 |
目的 |
场景 |
配置方式 |
| Filter(过滤器) |
基于函数回调,它可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。 |
是用来做一些过滤操作,获取我们想要的数据,比如:JavaWeb中对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作。 |
修改字符编码(CharacterEncodingFilter)、过滤HttpServletRequest中敏感字符(XSSFilter自定义过滤器) |
web.xml |
| 拦截器 |
基于Java的反射机制,属于面向切面编程(AOP)的一种运用,就是在Service或者一个方法前调用一个方法,或者在方法后调用一个方法,甚至在抛出异常的时候做业务逻辑的操作 |
由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个Controller生命周期之内可以多次调用。 |
但缺点是只能对Controller请求进行拦截,也可以拦截静态资源,必须要添加上配置才可以避免静态资源被拦截,拦截器不能拦截的只有jsp。 |
Spring mvc的文件中配置 |
| 监听器 |
监听器主要用来监听只用。通过listener可以监听web服务器中某一个执行动作,并根据其要求作出相应的响应。 |
|
Servlet的监听器Listener,它是实现了javax.servlet.ServletContextListener 接口的服务器端程序,它也是随web应用的启动而启动,只初始化一次,随web应用的停止而销毁。 |
在web.xmL中配置 |
用户的跨域访问原理解决方案



解决的方法:
1、 通过jsonp跨域:主要的核心思想就是将本域中cookie数据发送到其他域中,去做一个相应的请求的。就是相当于是的重新访问一次目标的域名的下的服务。目标域名下可以数据返回到本域中
2、 document.domain + iframe跨域
3、 location.hash + iframe
4、 window.name + iframe跨域
5、 postMessage跨域
6、 跨域资源共享(CORS):利用设置CORS的请求头协议的。以保证能够实现跨域的访问
7、 nginx代理跨域
8、 nodejs中间件代理跨域
9、 WebSocket协议跨域




用户注册、登入系统的流程
5用户登入怎么样获取限权?
授予角色,其实也就是在保存的时候,去添加用户角色关联表,将用户id和角色id关联起来。这样就在一个用户上绑定了多个角色,如果你这些角色上带有对应的site_id ,即站点,那相当于你可以对当前用户赋予多个系统站点的角色,这样在登录的时候,可以通过site_id 来筛选是否有某个系统的登录权限了。有些人可能觉得siteid应该放到功能表里,我这里放到角色里,是方便于在登录系统验证的时候少关联两张表,只要自己合理应用,我觉得没问题。
以下是用户在授予多个角色下结构图,挺简单的:


6关于用户的session怎样存储?
系统中的seesion是存储在的redis中。保持以key-value的形式进行存储,key是sessionid value是session对象。使用的注解类@EnableRedisation 来实现的
Redis的怎么样存储的session?
过滤器中的包装了一个httprequset中get session()

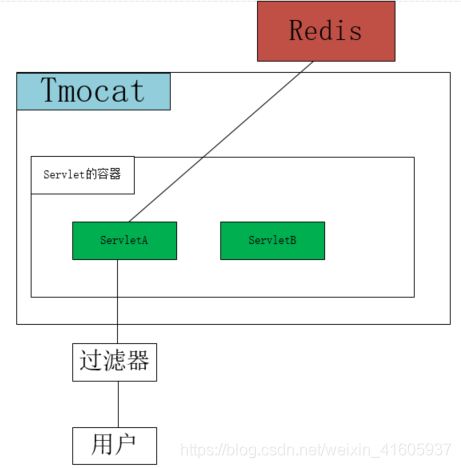
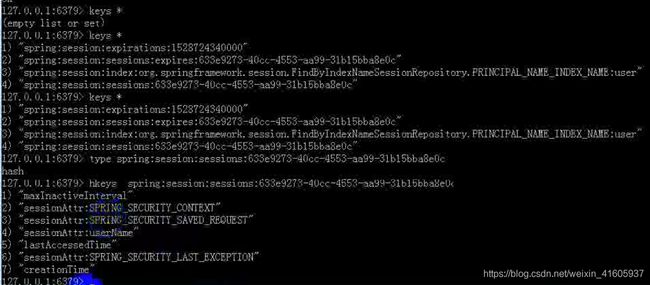
Seesion创建:sessionid第一次产生是在直到某server端程序调用 HttpServletRequest.getSession(true)这样的语句时才被创建。
Session删除:超时;程序调用HttpSession.invalidate();程序关闭。
Session存放在哪里:Redis。
session的id是从哪里来的,sessionID是如何使用的:
当客户端第一次请求session对象时候,服务器会为客户端创建一个session,并将通过特殊算法算出一个session的ID,用来标识该session对象。
session会因为浏览器的关闭而删除吗?不会,session只会通过:1超时2程序调用HttpSession.invalidate()3、程序关闭。
Session技术的选型:

如果是的而大型的分布式的环境的可以采用的第三方缓存来实现session的保存,以保证session的共享。(session存储在redis中的 设置过期的时间的事为分钟失效)
如过是较小的分布式的环境采用基于的Tomcatsession复制技术。利用的tomcat的广播机制来实现的session的共享。(seesion 是存储在的tomcat中的内存中的)
如果是的单点的系统可以采用的一种的无侵入的IP—hash算法来实现的session的共享。(seesion 是存储在的tomcat中的内存中的)
第三方账号登陆还是自主账号登录?
应为这个项目是的政府的相关项目,考虑到的有一些数据是作为的有效的依法的证据。所以对安全性有所考虑。所以选择的是自主登入的实现
第二是因为培养的这个系统的自己的用户。根据调研发现国内还没有完善的这样的系统。
8第三方登入的原理和流程:

9用户的注册功能的问题
1、用户的加密方式和原理:解决方案:Bcript算法:包括四个部分:版本号码+hash的运算次数、+明文+密文:Bcrypt有四个变量:1saltRounds: 正数,代表hash杂凑次数,数值越高越安全,默认10次。
2、myPassword: 明文密码字符串。3salt: 盐,一个128bits随机字符串,22字符。4 myHash: 经过明文密码 password和盐salt进行hash,个人的理解是默认10次下 ,循环加盐hash10次,得到myHash。每次明文字符串myPassword过来,就通过10次循环加盐salt加密后得到myHash, 然后拼接BCrypt版本号+salt盐+myHash等到最终的bcrypt密码 ,存入数据库中。
这样同一个密码,每次登录都可以根据自省业务需要生成不同的myHash, myHash中包含了版本和salt,存入数据库。bcrypt密码图解:

用户的安全校验、限时登入、权限获取问题
采用这样的随机噪声加密的方式的放置数据在校验的过程中的被其他人窃取,而造成用户账户和密码泄露。因为生成的密码是没有存储明文密码,而是采用的是随机盐+明文加密得到hash结果。当用户在一次登入的时候,通过账户的来找到这个用户的随机盐(128位)在和用户输入的明文密码经过计算所得hash结果。在和已经存在的后面的第四部分对比。判断是否为同一个用户。
为什么加盐?加盐的目的是为了什么?
加盐的目的是为了使得每一个用户能够获得一个不一样的随机盐。保证每一个用户的计算后的一样的结果。保证数据的唯一性。2^128大约是的3*e^38次方的结果
10用户的安全校验、用户的权限获取:
Bcrypt是如何验证密码的?:通过用户的账号,来查到获取到用的噪声盐,再将用户的盐和用户的输入的密码进行加密。匹配用户密码是否正确。
在下次校验时,从myHash中取出salt,salt跟password进行hash;得到的结果跟保存在DB中的hash进行比对。salt一般是用户相关的,且要保证在一个系统内每一个用户的盐都不相同,这样就可以保证即使密码相同,hash值也一定不相同。一般的做法是用用户表中的主键作为盐。
SpringSecuritycrypto项目中实现的BCrypt 密码验证BCrypt.checkpw(candidatePassword, dbPassword)
11用户的限时,登入:
通过利用是的JWT的的token的认证来实现用的限时登入状态。
1. 客户端使用用户名跟密码请求登录
2. 服务端收到请求,去验证用户名与密码
3. 验证成功后,服务端会签发一个 Token,再把这个Token 发送给客户端
4. 客户端收到 Token 以后可以把它存储起来,比如放在 Cookie 里
5. 客户端每次向服务端请求资源的时候需要带着服务端签发的 Token
6. 服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向
客户端返回请求的数据
注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
12数据库什么数据表进行优化的
系统中有一张涉及到小区和环卫公司的订单服务表,当时我们对订单表进行了表的拆分,分库分表,读写分离,等优化操作。
数据库优化的技术是什么
数据的字段和表的优化
数据库表的索引优化
数据的查询优化
数据的引擎选择
数据库的读写分离
数据的双主双从备份
数据库的分库分表操作
数据库的集群模式
14数据库优化的具体的实现
1读写分析本系统的数据采用的是mysql数据库集群,设计初期,对数据有进行优化,利用数据库的读写分离技术,提高数据库的访问的效率。采用的数据的双主双从的机制。保证数据库的高可用性。
2 分库分表:我们对业务系统数据进行了垂直切分,将用户系统和其他的系统使用的数据分别放置在不同的Mysql并采用了双主双从的备份以保证数据的读写分离和高可用性。在进行了水平的拆分,将用户表,拆分为用户基础表,用户扩展表用户其他多张表,并对用户的UUID值取hash值,分别放置在不同的数据表中。
15数据库优化存在问题和怎么解决方案
分库分表中,数据多表和的查询问题:
解决方案:将用户表和与用户逻辑相关的表放一个数据库中并把用户的表格以防止跨库的查询。
跨库关联查询:
字段冗余:比如我们查询合同库的合同表的时候需要关联客户库的客户表,我们可以直接把一些经常关联查询的客户字段放到合同表,通过这种方式避免跨库关联查询的问题
数据同步:比如商户系统要查询产品系统的产品表,我们干脆在商户系统创建一张产品表,通过ETL 或者其他方式定时同步产品数据。
全局表(广播表):比如行名行号信息被很多业务系统用到,如果我们放在核心系统,每个系统都要去关联查询,这个时候我们可以在所有的数据库都存储相同的基础数据。
ER 表(绑定表):将一下存在逻辑外键的一下表格放置在同一个数据库中。
排序、翻页、函数计算问题
跨节点多库进行查询时,会出现limit 分页,order by 排序的问题。max、min、sum、count 之类的函数在进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回
全局主键避重问题:利用UUID/雪花算法。把序号维护在数据库的一张表中。这张表记录了全局主键的类型、位数、起始值。Snowflake(64bit)
16分库分表后你的主键Id怎么确定?
1UUID (Universally Unique Identifier),通用唯一识别码的缩写。
2Redis实现分布式唯一ID
3雪花算法是由Twitter开源的分布式ID生成算法.
17数据分布式的最终一致性和分布式事务
CPA的原则:一致性、可用性、容忍性
解决方案有两种:1中是利用两阶段的提交的方式俩保证分区和可用性, 或者是采用的全局事务处理的方式,利用的是seata的方式。
18 Redis的基本数据结构
String Hash list set Zset
String:是采用的结构体+链表的结构 SDS这样的一个结构。
List:采用的是结构体+双链表
Hash:数组+链表的的这样的一种的
Set: inset的结构+hashtable的这样的这样的一种结构
Zset:采用的是跳跃表(skiplist)/ziplist两种数据结构
当存储的信息是不需要修改的情况采用的是的String 结构。当对象的某个属性需要频繁修改时,采用的hash结构,如果使用hash类型,则可以针对某个属性单独修改,没有序列化,也不需要修改整个对象。比如,商品的价格、销量、关注数、评价数等可能经常发生变化的属性,就适合存储在hash类型里。
19你们的在的redis中怎么应用的?
1当做缓存用,加快页面的访问2、常用、热门商品数据的信息访问3、存储用户的session信息、4 使用redis来实现并发的访问限流控制。
1 当做缓存用,加快页面的访问(主要需要解决的是的保持的数据的一致性)
2 redis的分布式的集群 一致性的hash算法的理解
3 redis 分布式锁的实现
20 Redis的哨兵机制是什么

如图,是 Redis Sentinel(哨兵)的架构图。Redis Sentinel(哨兵)主要功能包括主节点存活检测、主从运行情况检测、自动故障转移、主从切换。
21 Redis的集群模式
该缓存系统中一共使用了33个Redis的节点。其中一个11个主从节点的为redis的主节点,每个节点的读写高峰qps可能可以达到每秒 5 万,11台机器最多是 50 万读写请求/s。首先在系统正式上线之前都是进行缓存预热缓存的加载,利用hash算法加载数据到redis槽,(分散哈希槽的概念,一种16384个槽)将数据散列的散列的分布在redis各个节点中。以保证防止热点数据在一台redis中。减少访问的压力。为了保证集群节点的高可用性,对一个主节点配置2个从节点,这样能够实现在主节点在宕机的情况下能够利用的redis的哨兵机制模型来实现的高可用的这样的一个状态。如果是发生某一个主节点发生宕机的情况下会进行领导者选举模式,进行主备切换的一个操作,选择出主节点。但是在选择的过程中该节点是不工作的。整个集群其他的节点还是正常工作的。
22你们项目是一个什么配置。
32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 redis 进程的是10g内存,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。11台机器对外提供读写,一共有 55g 内存。因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
23 Redis中分布式集群的数据倾斜问题:
采用的是一致性hash算法。在数据扩容的是时候会产生的数据的不均匀。会造成数据倾斜的问题。一致性hash算法避免将数据重新分布在redis中。解决小范围的数据的移动,不至于全盘扩展。可能造成数据的数据的倾斜问题。这样的时候在redis内部维护了一张的虚拟hash和真实机器的一张关系表格。从而保证的数据在访问虚拟节点的时能够访问真实的数据。
你往内存里写的是什么数据?每条数据的大小是多少?商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。
23 Redis可能存在的问题是
在采用的Redis可能存在缓存击穿,缓存雪崩。
缓存雪崩:(数据同一时间失效)1一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。2给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。3为 key 设置不同的缓存失效时间。
缓存击穿:(查询的数据为空)1最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。 2如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短。
24Redis缓存系统的数据和数据库的一致性
如果保证的缓存的和数据库的数据的一致性:先更新数据库,再删除缓存

25redis的分布式锁实现控制超卖问题
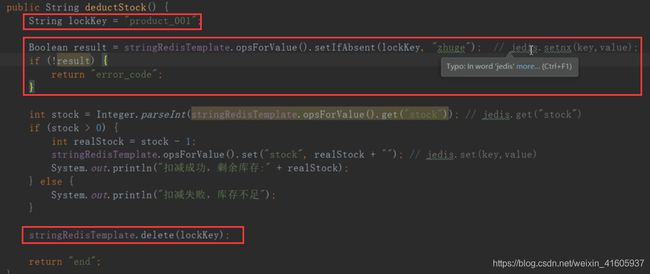
利用的redis分布式锁的时候控制的数据库中的热门商品的超买的一个错误。
1第一种的方式的是采用的synchronize(JVM层面的锁)方法来实现的。还是存在问题是就是在多个分布式的项目中的出现的超卖问题。原因的是的不同的tomcat中的请求不同的服务还是存在高并发的一个问题。
2 使用的redis的单线程的原理,实现的一个对象的加锁。使用setIfAbsent(“锁”,“对象”)
相当于时候的使用了redis中的setnx();
3 但是主从架构的时候还是存在问题。这个问题是很难解决的,最好采用的是的zookeeper来解决。(后者是后者在采用一个redis的来保证加锁,考虑场景的时候访问的数量的时候)
4 但是还是存在性能的问题,解决的访问是是将数据的模拟一个分段锁的机制来实现。在主从架构的时候还是有问题的:利用的currenthashmap的思想 采用的是分段的锁的机制来实现的原理,将数据的分成很多的数据的锁。
Synchronize是一个单进程的是的锁但是的在分布式的下还有有可能的问题。这个是一个JVM的锁。
这个会造成的什么问题? 死锁的问题,但是采用的是的try catch 但是还是存在的死锁问题。可以设置对锁加一个过期的时间。
还是存在的原子问题。但是redis有原子的命令。但是

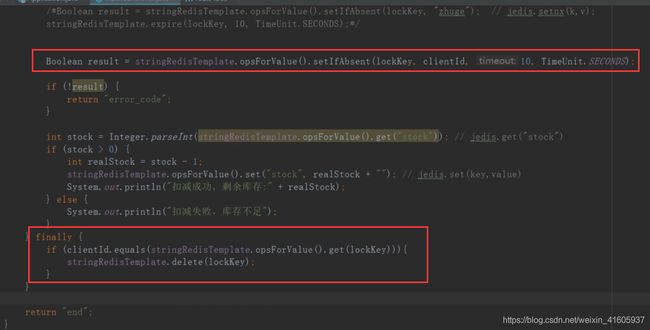
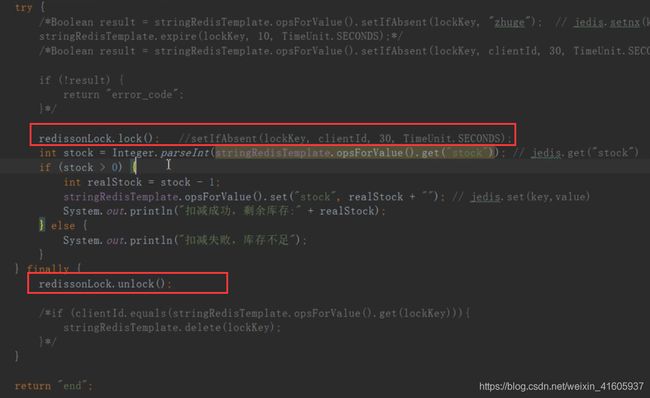
对锁的设置一个过期的时间,使用resdis中的SelfAbsent()设置过一个锁的过期时间。但是还是存在问题。当任务的长度时间大于过期时间。这个时候就可能被其他对象获取了。当其他的锁被其他的销毁了。

在主从架构的时候还是有问题的:
利用的currenthashmap的思想 采用的是分段的锁的机制来实现的原理,将数据的分成很多的数据的锁。
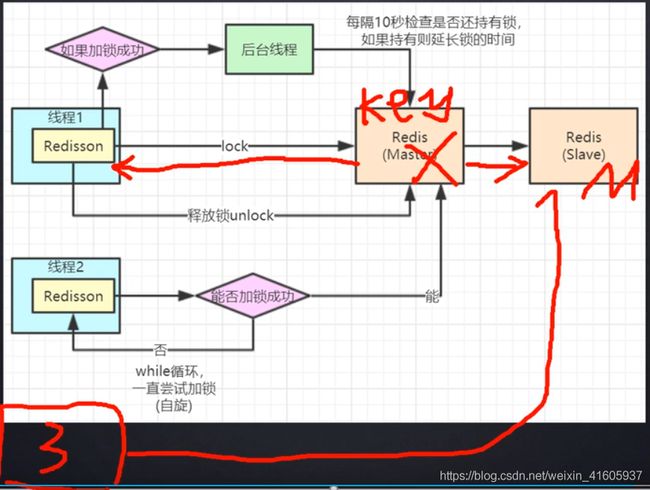
利用的zookeeper的才能保证的这个成功的。

采用的redlocak,但是目前还是存在发争议的问题。
26数据迁移是怎么样迁移过来?
解决方案:1停机迁移方案2简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,都除了对老库增删改,都加上对新库的增删改,这就是所谓双写,同时写俩库,老库和新库。
27MQ的原理:
RabbitMQ高级级消息队列协议。是一种的跨进程的通信的机制,用于上下游之间的管道方式的传递的消息。RabbitMQ的作用是解耦。异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。日志处理 - 解决大量日志传输。消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
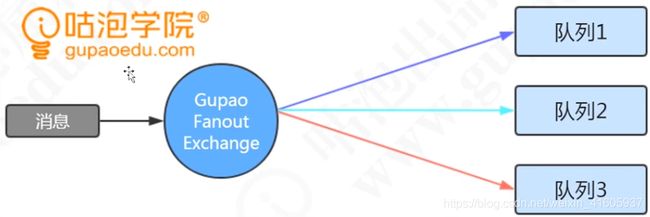
287MQ中的路由机制是什么
有三种的路由机制 :第一是由于消息发送到MQ后通过绑定key值。来将消息发送到指定的制定服务上。第二种是的将消息经过交换机来实现发送到不同的消费者端,可以使用的通配符的方式,第三中就是将消息发送到不同的消息的队列的上给消费。
1 Direct exchange

2 Topic exchange(可以使用通配符)

3 Fanout exchange:
29MQ中如何确保消息的唯一性,以及MQ中事务
给每一个消息添加一个全局唯一的id。消费者接收到消息时,将消息对象进行MD5加密,作为消息唯一性。如果发现messageObj(发送到mq的数据)已经存在,则忽略,进而保证消息不被重复消费。
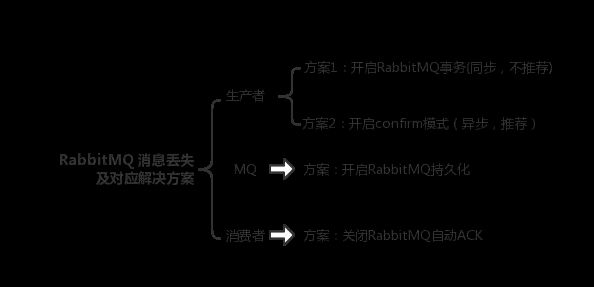
30MQ中消息丢失的三种情况——生产者、消息队列、消费者

31生产者传输过程中丢失数据——Confirm机制
所以一般来说,如果你要确保说写 RabbitMQ 的消息别丢,可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个ack消息,告诉你说这个消息 ok 了。如果 RabbitMQ 没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息 id 的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
就是说如果一直发送消息失败,我们应该先将消息缓存起来。等在消息的再一次的发送。使用的redis缓存系统的来维护这样一个消息发送失败的时候的。在一定的时候内在一次发送给MQ中。
32消息队列自身丢失——持久化处理
就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,RabbitMQ 还没持久化,自己就挂了,可能导致少量数据丢失,但是这个概率较小。
33消费者还未处理就宕机了
这个时候得用 RabbitMQ 提供的ack机制,简单来说,就是你关闭 RabbitMQ 的自动ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里ack一把。这样的话,如果你还没处理完,不就没有ack?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
MQ中的消息队列是如何及时的消费的?
如果初见不能及时消费消息的情况怎么处理,就是出现消息堆积的时候怎么解决的?MQ中的消息挤压怎么解决。
解决方案:
这种时候只能操作临时扩容,以更快的速度去消费数据了。具体操作步骤和思路如下:
①先修复consumer的问题,确保其恢复消费速度,然后将现有consumer都停掉。
②临时建立好原先10倍或者20倍的queue数量(新建一个topic,partition是原来的10倍)。
③然后写一个临时分发消息的consumer程序,这个程序部署上去消费积压的消息,消费之后不做耗时处理,直接均匀轮询写入临时建好分10数量的queue里面。
④紧接着征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的消息。
⑤这种做法相当于临时将queue资源和consumer资源扩大10倍,以正常速度的10倍来消费消息。
⑥等快速消费完了之后,恢复原来的部署架构,重新用原来的consumer机器来消费消息。
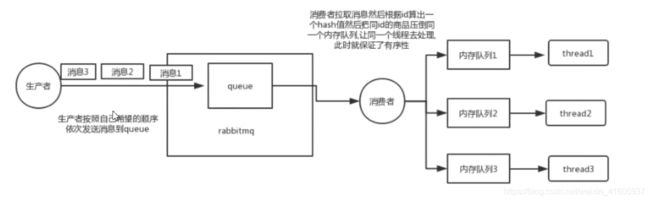
35 MQ中的怎么样实现有序消费的问题

36 PRC和MQ的区别?
RPC的一般需要经历4个步骤:
1、建立通信:首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接,主要是通过在客户端和服务器之间建立TCP连接。
2、服务寻址:要解决寻址的问题,A服务器上如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称是什么。
3、网络传输:
序列化:当A服务器上的应用发起一个RPC调用时,调用方法和参数数据都需要先进行序列化。
反序列化:当B服务器接收到A服务器的请求之后,又需要对接收到的参数等信息进行反序列化操作。
4、服务调用
B服务器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A服务器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A服务器。
通常,一次完整的PRC调用需要经历如上4个步骤。
消息队列(MQ)是一种能实现生产者到消费者单向通信的通信模型,一般来说是指实现这个模型的中间件。典型的MQ中间件:
RabbitMQ、ActiveMQ、Kafka等:典型的特点:1、解耦 2、可靠投递 3、广播 4、最终一致性 5、流量削峰 6、消息投递保证 7、异步通信(支持同步)8、提高系统吞吐、健壮性。典型的使用场景:秒杀业务中利用MQ来实现流量削峰,应用解耦使用。
37RPC和MQ的区别和关联
1.在架构上,RPC和MQ的差异点是,Message有一个中间结点MessageQueue,可以把消息存储。
2.同步调用:对于要立即等待返回处理结果的场景,RPC是首选。
3.MQ 的使用,一方面是基于性能的考虑,比如服务端不能快速的响应客户端(或客户端也不要求实时响应),需要在队列里缓存。另外一方面,它更侧重数据的传输,因此方式更加多样化,除了点对点外,还有订阅发布等功能。
4.而且随着业务增长,有的处理端处理量会成为瓶颈,会进行同步调用改造为异步调用,这个时候可以考虑使用MQ。
38服务的降级和限流实现
降级:当访问量剧增,服务出现问题时,需要做一些处理,比如服务降级。
服务降级就是将某些服务停掉或者不进行业务处理,释放资源来维持主要服务的功能。释放掉一些资源,将一些不那么重要的服务采取降级措施。
限流:限流的目的是为了保护系统不被大量请求冲垮,通过限制请求的速度和次数来保护系统。
实现方式
服务降级有很多种方式,最好的方式就是利用 Docker 来实现。当需要对某个服务进行降级时
直接将这个服务所有的容器停掉,需要恢复的时候重新启动就可以了。
还有就是在 API 网关层进行处理,当某个服务被降级了,前端过来的请求就直接拒绝掉,不往内部服务转发,将流量挡回去。
限流的方式也有多种,可以在 Nginx 层面限流,也可以在应用当中限流,比如在 API网关中。
那么在分布式应用程序中,有没有分布式限流的方法呢?这里提供几种思路:
Nginx层限流,一般http服务需要经过网关,Nginx层相当于网关限流
Redis限流,redis是线程安全的,redis支持LUA脚本
开源组件Hystrix、resilience4j、Sentinel
采用的是限流的算法:滑动窗口、计数器 、漏桶算法、令牌桶的算法、
39 第三方账号登陆还是自主账号登录?
我认为这个还是要根据你应用或网站的定位、功能来决定。如果你的应用重分享、重评论、重社交,并不定位于做行业的标杆,是比较轻量级的应用,那么你可以选择放弃自主账号体系,让用户无需纠结于是用第三方账号还是重新注册一个账号,让注册流程更加简洁,用户目标更加明确(如啪啪、Instagram、你画我猜等)。 而如果你的应用是重内容、轻社交,独立性较强,有可能形成一个社区或闭环,可以经过时间培养起一批有自己风格的用户,有自己的用户文化,那么还是应该保留有自己的登录体系,一来可能适应更多用户的需求,二来也容易让用户产生一种归属感。如果有信心的话甚至可以放弃第三方登录,让用户对你的产品有着更深的需求与认知,这样慢慢发展也许你也会成为另一个第三方平台,不过这毕竟是少数。另外移动端跟PC端注册的成本也不同,在移动端输入更少的应用也许让用户会更舒服一些,这也是要考虑到的。
我咨询了周围的一些朋友,看看他们平时是用第三方登录体系还是应用的自主登录体系,下面是几个发现:1. 女性朋友为了方便更喜欢用第三方等账号登陆,而男性朋友则对隐私有着更多一些的关注,有些更倾向于自主账号登陆; 2. 如果应用正规、名气大、口碑良好,则对隐私泄露的担忧会下降; 3. 如果发现应用会自动在第三方平台更新用户动态,则对该应用好感度明显下降; 4. 如果第三方登录会带来明显好处(如一些社交类游戏就是为了与好友一起玩),则更倾向于使用第三方登录。我咨询的朋友不多,而且用户模型也较为相似,所以不具有很强的代表性,不过从中也能学到一些东西,如在授权第三方时默认授权不要过多,要尊重用户,要让自己的产品更加专业与正规,给用户留下正面的印象等。
总结一下就是自主登录体系与第三方登录体系均有利弊,在要结合自己产品的形态、定位、风格以及愿景来进行选择,无论何种选择,永远要做到尊重用户
40 什么是的http和Retful的区别?
restfull是一种风格,不是规范,也不是所谓的封装,REST是所有Web应用都应该遵守的架构设计指导原则。而http是一种的数据的传输的一种标准和协议。
41 API的设计和实现?
使用加签名方式(JWT),防止数据篡改
信息加密与密钥管理
搭建OAuth2.0认证授权
使用令牌方式(Token)
搭建网关实现黑名单和白名单
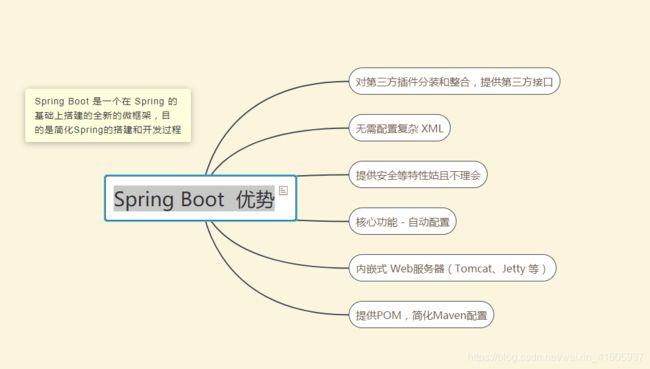
42Springboot的启动原理?Springboot怎么样启动的tomcat的? Springboot和Spring的区别?
43你怎么来说明自己的学习的能力强?
1能够很快的自主学习新的技术和方法:首先是对软件开发有一个清楚的认识。其次能够在短时间通过自己的自主学习能够快速的掌握好Spring的高级框架,Redis的使用,集群的相关知识。最后能够在团队中独立的完成需求分析和demo的演示,并在实习中独立的完成相关需求的开发。
2 能够在解决基本的问题后还能去扩展以外的知识:在能够解决自己的redis的缓存的相关问题后,自己还主动学习了redis的其他性能,例如redis的NIO原理,利用redis实现分布式锁的相关的原理……,还自己主动的学了zookeeper DubboX的相关的使用和原理。还主动的学的springboot springcloud的微服务的开发技术。
3 以前在学校没有接触过数据库的优化和相关表的设计工作,在实习中也掌握了不少的数据有的优化方法和手段。并且能够快速的融合工作团队,能够很好的和团队相处。
44Springboot是怎么启动的?
这个博客详细说了Springboot的启动原理:https://www.cnblogs.com/xiaopotian/p/11052917.html。Springboot的启动是使用的是三大配置注解的理解:
@Configuration
@Configuration的注解类标识这个类可以使用Spring IoC容器作为bean定义的来源。
@Bean注解告诉Spring,一个带有@Bean的注解方法将返回一个对象,该对象应该被注册为在Spring应用程序上下文中的bean。
@EnableAutoConfiguration
@ComponentScan这个注解在Spring中很重要,它对应XML配置中的元素,@ComponentScan的功能其实就是自动扫描并加载符合条件的组件(比如@Component和@Repository等)或者bean定义,最终将这些bean定义加载到IoC容器中。
我们可以通过basePackages等属性来细粒度的定制@ComponentScan自动扫描的范围,如果不指定,则默认Spring框架实现会从声明@ComponentScan所在类的package进行扫描。
注:所以SpringBoot的启动类最好是放在root package下,因为默认不指定basePackages。
@ComponentScan
@EnableAutoConfiguration这个Annotation最为重要,所以放在最后来解读,大家是否还记得Spring框架提供的各种名字为@Enable开头的Annotation定义?比如@EnableScheduling、@EnableCaching、@EnableMBeanExport等,@EnableAutoConfiguration的理念和做事方式其实一脉相承,简单概括一下就是,借助@Import的支持,收集和注册特定场景相关的bean定义。
@EnableScheduling是通过@Import将Spring调度框架相关的bean定义都加载到IoC容器。
@EnableMBeanExport是通过@Import将JMX相关的bean定义加载到IoC容器。
而@EnableAutoConfiguration也是借助@Import的帮助,将所有符合自动配置条件的bean定义加载到IoC容器,仅此而已!
@EnableAutoConfiguration会根据类路径中的jar依赖为项目进行自动配置,如:添加了spring-boot-starter-web依赖,会自动添加Tomcat和Spring MVC的依赖,Spring Boot会对Tomcat和Spring MVC进行自动配置。

45你在实习中学习到了什么
1 在专业上面学习:我学习的更多的新的知识,新的架构,新的框架,很多系统的解决方案。对计算机的数据库,操作系统,计算机网络有了新的认知。并且能够在专业上紧跟大牛的步伐。
2 团队关系和沟通上学习到了什么:在团队中,注意团队和合作,要善于听取同事的意见和帮助,遇到解决不了的问题一定要大胆提出,不能害怕。
3 在未来的职业发展方向上学习到了:让我对自己的工作有了新的认识,也善于去发现问题,并对自己对学习和生活有了一个明确的目标和期待。同时在自己的职业化有了新的目标和追求。