170 亿参数!微软对内发布最强模型 Turing-NLG
_
By 超神经
内容导读:近日,微软公布了史上最大的语言生成模型,Turing-NLG。通过 DeepSpeed 深度学习库,以及 ZeRO 优化的技术带来的突破,这个庞大的模型得以被训练而出。而在多项基准测试方面,Turing-NLG 也达到了最优异的水平。
关键词:自然语言生成 参数量 微软
2 月 10 日,微软发布了新的语言生成模型 Turing-NLG ,将该领域拉到了一个全新的高度。

Turing-NLG 的消息在微软官方博客发布
Turing-NLG 拥有 170 亿参数量,是英伟达 Megatron 模型参数的两倍。而此前足够以假乱真的 GPT-2 ,也仅仅只有 15 亿参数。
拥有史无前例的参数量的同时,也让 Turing-NLG 的具备了无与伦比的性能,它在诸多语言模型基准上,都超越了当前性能最佳的其他模型。
参数越大,性能越强
Turing-NLG 是基于 Transformer 的生成语言模型,它可以通过生产单词,来完成开放式的文本任务:补充句子,编写故事,生成答案以及进行文本摘要等。
让 AI 像人一样直接、准确、流畅地对文本问题作出回应,是自然语言处理领域试图达到的目标。这其中生成模型显得十分重要。
但在此前的问题解答和摘要系统中,大多都依赖于从文档中提取现有内容,此类方式存在很大的弊端,最后给出的反馈,往往是不够自然或者不连贯。
而 Turing-NLG,则能够自然流畅地总结或回答此类问题,尤其是在有关个人文件或电子邮件整理方面,而且在问答和文本总结等实际任务中也表现出色。

Turing-NLG 将同类模型远远地甩在了身后
实际的测试中, Turing-NLG 在多项语言模型的基准上,均实现了 SOTA (最先进性能)。
微软介绍到,模型背后依据在于:即使训练样本较少,但模型越大,预训练的数据越多样化和全面,它就越能更好地推广到多个下游任务。
因此,训练大型的集中式多任务模型,并在众多任务中共享其功能,要比单独为每个任务训练新模型更为有效。
新方法铸就「庞然大物」
庞大的模型并不容易得到。其中一个难点是,训练超过 13 亿参数的模型,就不能仅靠一个 GPU。必须在多个 GPU 之间并行训练,或者将模型进行分解。
微软在博客中介绍到,本次能够训练出 Turing-NLG,得益于软硬件上三个方面的突破:
使用 NVIDIA DGX-2 硬件设置,通过 InfiniBand 连接,以便在 GPU 之间实现快速的通信。
使用了四个英伟达 V100 GPU,并在在英伟达 Megatron-LM 框架中应用张量切片来分割模型。
使用 Deepspeed 和 ZeRO ,以降低了模型的并行度 ,将每个节点的批处理大小增加 4 倍,减少了三倍的训练时间。
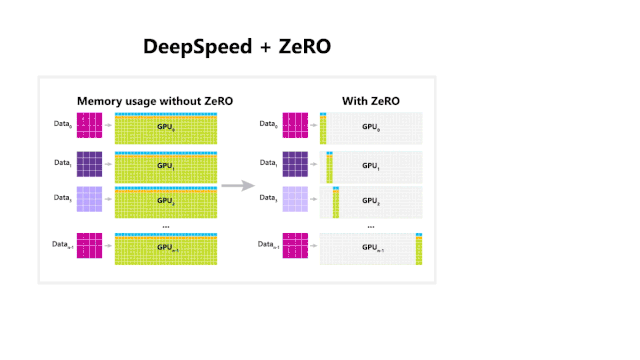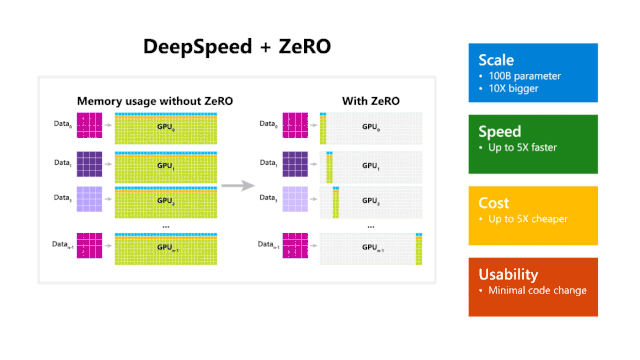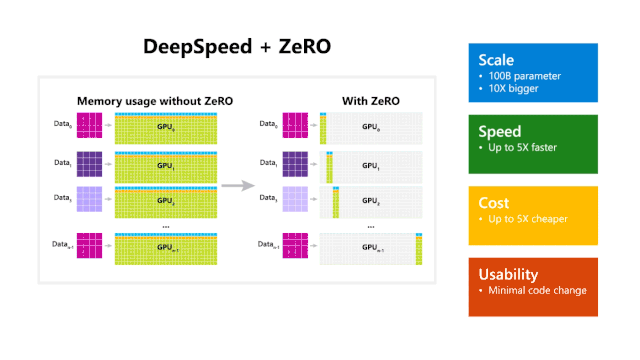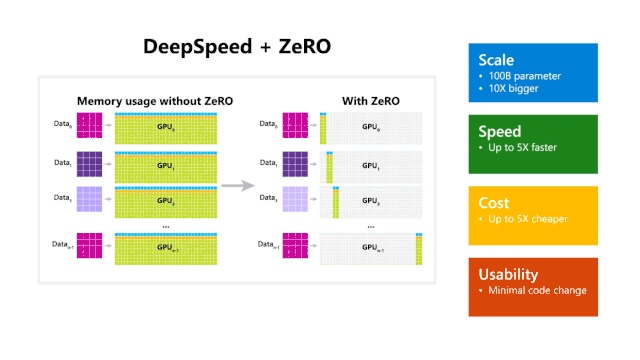
DeepSpeed 和 ZeRO 的使用带来了性能提升
其中,DeepSpeed 是微软推出的深度学习库,可以在更少 GPU 的前提下,提高大型模型的训练效率;
ZeRO 是一个新的并行优化组件,能够降低模型和数据并行需要的资源,提升可训练的参数量。

DeepSpeed 在规模,速度,成本和可用性上具有优势
使用 ZeRO 可以大幅提升可训练模型的大小
通过这些方法的使用,在最终的模型中,有 78 个Transformer 层,4256 个隐藏层参数,包含 28 个注意头。
Turing-NLG 吊打其他模型
模型预训练完成后,为了验证其性能,微软将 Turing-NLG 和英伟达 Megatron-LM ,以及 OpenAI 的 GPT-2 完整版做了性能对比。
分别在 WikiText-103(分数越低越好)和 LAMBADA(分数越高越好)数据集上,进行了指标评分。

可以看到,Turing-NLG 和这两个当下最先进的模型相比,性能上均有所超越。
此外,在有关问答和摘要任务的实际测试中,Turing-NLG 也取得了极大的突破。
它实现了直接生成问答,或者说在零样本下生成问答的能力。在该情况下,Turing-NLG 模型依赖预训练期间所获得的知识,生成了最终的答案。

直接提问,模型也能给出答案
下图展示了Turing-NLG 模型和此前的基准系统,在事实正确性(Factual Correctness)和语法正确性(Grammatical Correctness)两项指标上的对比情况:

另外,模型能够在更少的监督条件下生成抽象式摘要。
比如为电子邮件、博客文章、Word 文档,甚至是 Excel 表格和 PPT 演示,编写出抽象式内容摘要。
这其中一个主要的挑战,便是面向这些面向和个人化的场景,缺少有监督的训练数据,而 Turing-NLG 的机制则决定了它可以胜任此类工作。
Turing-NLG 的潜在应用
该模型目前并不对外公开。微软表示其初衷在于,让模型可以帮助用户对文档和邮件进行摘要化处理,同时能够应用在 Office 系列软件中,提供写作帮助和疑难解答。
微软还认为该模型的出现,为下一代聊天机器人和数字助理铺平了道路,有望被用于客服、销售等方向。
此外,Turing-NLG 还是 Project Turing(图灵计划)的一部分,模型也由此得名。
微软图灵项目首页
该计划正尝试将文本和视觉处理技术,应用到产品开发之中,包括与 Bing、Office、Xbox 等方面软硬件相关的服务。
模型一发布,Reddit 就沸腾了
模型一经发布,就在 Reddit 论坛上引起了热议,网友们纷纷发帖表述自己的看法。
称赞 当前最高赞回答,强调了对参数增加的看法,并表达了他的支持。

“
幸运的是,模型具有 170 亿个参数,而不是 170 亿个超参数。
毕竟,目前最智能的结构(人),具有超过 100 万亿个参数。虽然参数增多会造成带来效率的问题,但是我认为拥有更多参数没什么问题(尤其是在资金雄厚的研究环境下)。
”看衰 也人并不看好,认为没有解决根本问题。
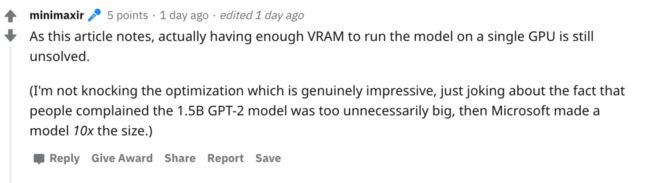
“
从发布的博客来看,即使有足够的 VRAM ,无法在单个 GPU 上运行模型的问题,依然没有得到解决。
我不是针对他们令人印象深刻的优化方法,只是在模型体量上开个玩笑,因为人们在抱怨 15 亿参数的 GPT-2 太庞大之后,微软就造出了大 10 倍的模型。
”官方 参与图灵项目的研究成员,也亲自出场,发帖进行热心答疑。

在该条目下,有关 Turing-NLG 的多个关键问题,也得到了详细回答。
包括团队正在内部讨论,是否会发出缩减版的预训练模型;更详细的技术细节将会在后续放出;模型目前仅支持英语,支持多语言的版本正在计划之中等。
目前帖子下的问题和讨论仍在发酵之中。
—— 完 ——

扫描二维码,加入讨论群
获得更多优质数据集
了解人工智能落地应用
关注顶会&论文
回复「读者」了解详情
更多精彩内容(点击图片阅读)



_
_
_
_
