RPA手把手——【数据结构与算法】遗传算法(四)应用篇之 TPOT 库实现
艺赛旗 RPA9.0全新首发免费下载 点击下载
http://www.i-search.com.cn/index.html?from=line1
相信这个部分是你在一开始读本文时心里最终想实现的那个目标。即:实现。那么首先我们来快速浏览一下 TPOT 库(Tree-based Pipeline Optimisation Technique,树形传递优化技术),该库基于 scikit-learn 库建立。
TPOT 是一个 Python 编写的软件包,利用遗传算法行特征选择和算法模型选择,仅需几行代码,就能生成完整的机器学习代码。
自动化机器学习(AML)是一种流水线(也称管线),它能够让你自动执行机器学习(ML)问题中的重复步骤,从而节省时间,让你专注于使你的专业知识发挥更高价值。 最重要的是,它不仅是一些模糊的想法,而且还有一些基于标准 python ML 包建立的应用包,如 scikit-learn。
在这种情况下,任何熟悉机器学习的人都可能会回想起网格搜索(grid search)这个概念。 他们这样想是完全正确的。 实际上,AML 是在 scikit-learn 中应用的网格搜索的扩展,而不是迭代这些值预先定义的集合和其组合,它通过搜索方法,特征,变换和参数值来获得最佳解决方案。 因此,AML“网格搜索”不需要在可能的配置空间上进行详尽的搜索 - AML 有一个很赞的应用叫做 TPOT 包,其提供了像遗传算法这样的应用,可用来在某个配置中混合各个参数并达到最佳设置。
下图为一个基本的传递结构。
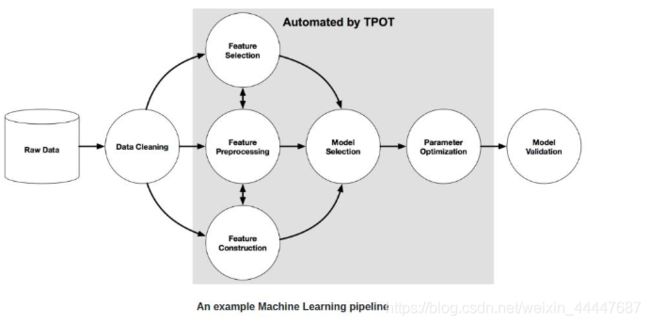
图中的灰色区域用 TPOT 库实现了自动处理。实现该部分的自动处理需要用到遗传算法。
我们这里不深入讲解,而是直接应用它。为了能够使用 TPOT 库,你需要先安装一些 TPOT 建立于其上的 python 库。下面我们快速安装它们:
安装 DEAP, update_checker和tqdm库
pip install deap
pip install update_checker
pip install tqdm
安装TPOT库
pip install tpot
然后下载上一篇给出的训练和测试集,下面给出详细代码及相关注释,大家可以对着敲一下代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
分别读取训练集和测试集,分隔符为逗号
train = pd.read_table(‘Train_UWu5bXk.txt’, sep=’,’)
test = pd.read_table(‘Test_u94Q5KV.txt’, sep=’,’)
可以输出一下 train 看看:
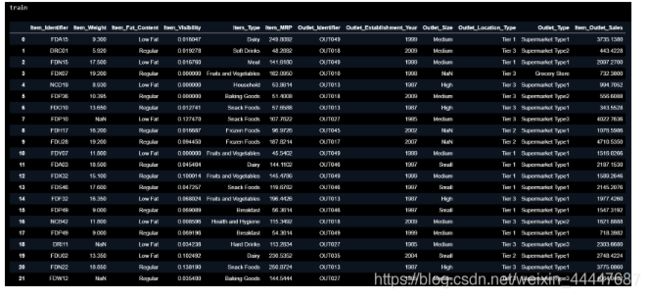
下面是一些数据清洗工作:
产品重量为空的单元格用这列的平均值填充
train[‘Item_Weight’].fillna((train[‘Item_Weight’].mean()), inplace=True)
test[‘Item_Weight’].fillna((test[‘Item_Weight’].mean()), inplace=True)
产品脂肪含量为low fat和LF的一律改为Low Fat,为reg的一律改为Regular
train[‘Item_Fat_Content’] = train[‘Item_Fat_Content’].replace([‘low fat’,‘LF’], [‘Low Fat’,‘Low Fat’])
train[‘Item_Fat_Content’] = train[‘Item_Fat_Content’].replace([‘reg’], [‘Regular’])
test[‘Item_Fat_Content’] = test[‘Item_Fat_Content’].replace([‘low fat’,‘LF’], [‘Low Fat’,‘Low Fat’])
test[‘Item_Fat_Content’] = test[‘Item_Fat_Content’].replace([‘reg’], [‘Regular’])
商店成立年份统一转化为已经成立的年数(用2013作为被减数是因为这份数据集是2013年采集的)
train[‘Outlet_Establishment_Year’] = 2013 - train[‘Outlet_Establishment_Year’]
test[‘Outlet_Establishment_Year’] = 2013 - test[‘Outlet_Establishment_Year’]
商店占地面积为空的单元格都用Small填充
train[‘Outlet_Size’].fillna(‘Small’,inplace=True)
test[‘Outlet_Size’].fillna(‘Small’,inplace=True)
对比重开根号
train[‘Item_Visibility’] = np.sqrt(train[‘Item_Visibility’])
test[‘Item_Visibility’] = np.sqrt(test[‘Item_Visibility’])
col = [‘Outlet_Size’, ‘Outlet_Location_Type’, ‘Outlet_Type’, ‘Item_Fat_Content’]
测试集添加一列产品销售情况,数据都用0填充,方便将训练集和测试集拼接起来
test[‘Item_Outlet_Sales’] = 0
拼接后的新DataFrame
combi = train.append(test)
对于商店占地面积、商店所在城市类型、商店类型和产品脂肪含量这四列都调用scikit-learn库中的降维方法,会把各种类型都转为0、1、2这样的简单结构
for i in col:
combi[i] = preprocessing.LabelEncoder().fit_transform(combi[i].astype(‘str’))
combi[i] = combi[i].astype(‘object’)
将拼接后的DataFrame根据原来大小重新拆分成训练集和测试集
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
刚才为了方便拼接,给测试集添加了一列虚假的产品销售情况,现在将这列删除
test.drop(‘Item_Outlet_Sales’, axis=1, inplace=True)
删除产品ID、产品类型和商店ID后的结果赋值给tpot_train训练集和tpot_test测试集
tpot_train = train.drop([‘Outlet_Identifier’, ‘Item_Type’, ‘Item_Identifier’], axis=1)
tpot_test = test.drop([‘Outlet_Identifier’, ‘Item_Type’, ‘Item_Identifier’], axis=1)
把产品销售情况设为目标标签列
target = tpot_train[‘Item_Outlet_Sales’]
在tpot_train训练集中把产品销售情况这列也删除
tpot_train.drop(‘Item_Outlet_Sales’, axis=1, inplace=True)
接下来开始训练模型:
from tpot import TPOTRegressor
from sklearn.model_selection import train_test_split
将tpot_train训练集和目标标签列随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
X_train, X_test, y_train, y_test = train_test_split(tpot_train, target, train_size=0.75, test_size=0.25)
初始化一个TPOT实例
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2)
利用fit函数来寻找最优的管道
tpot.fit(X_train, y_train)
fit函数初始化了遗传算法,以找到基于平均k倍交叉验证的最高评分管道,然后对整个提供的样本进行训练,TPOT实例可以作为一个合适的模型使用。
运行效果如下:
【数据结构与算法】遗传算法(四)应用篇之 TPOT 库实现
可以看到 TPOT 寻找到的最优的机器学习模型是极端随机森林回归
然后,可以使用score函数来评估测试集中的最终管道
print(tpot.score(X_test, y_test))
可以用TPOT将相应的Python代码导出到文件中
tpot.export(‘tpot_boston_pipeline.py’)
使用TPOT优化后的代码对测试集进行预测
tpot_pred = tpot.predict(tpot_test)
sub1 = pd.DataFrame(data=tpot_pred)
预测结果列重命名为Item_Outlet_Sales
sub1 = sub1.rename(columns={‘0’:‘Item_Outlet_Sales’})
新增Item_Identifier列
sub1[‘Item_Identifier’] = test[‘Item_Identifier’]
新增Outlet_Identifier列
sub1[‘Outlet_Identifier’] = test[‘Outlet_Identifier’]
对三个列重命名
sub1.columns = [‘Item_Outlet_Sales’, ‘Item_Identifier’, ‘Outlet_Identifier’]
DataFrame列重新排序
sub1 = sub1[[‘Item_Identifier’, ‘Outlet_Identifier’, ‘Item_Outlet_Sales’]]
输出符合比赛要求提交格式的csv文件
sub1.to_csv(‘tpot.csv’, index=False)
如果你提交了这个 csv,那么你会发现其实效果没有那么好。实际上,TPOT 库有一个简单的规则。如果你不运行 TPOT 太久,那么它就不会为你的问题找出最可能传递方式。
所以,你得增加进化的代数,拿杯咖啡出去走一遭,其它的交给 TPOT 就行。此外,你也可以用这个库来处理分类问题。进一步内容可以参考这个文档:http://rhiever.github.io/tpot/
除了比赛,在生活中我们也有很多应用场景可以用到遗传算法。