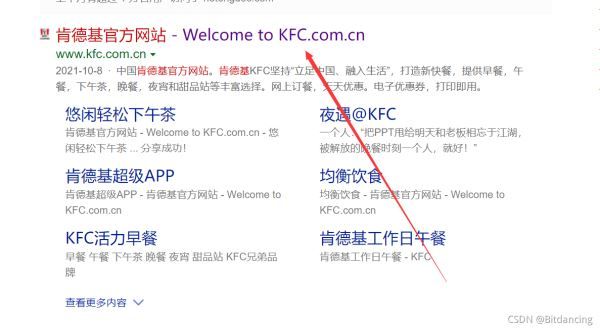
准备工作
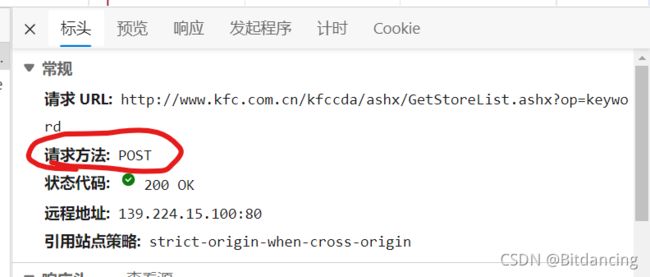
查看肯德基官网的请求方法:post请求。
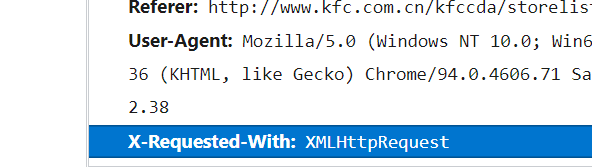
X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求
通过这两个准备步骤,明确本次爬虫目标:
ajax的post请求肯德基官网 获取上海肯德基地点前10页。
分析
获取上海肯德基地点前10页,那就需要先对每页的url进行分析。
第一页
# page1 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 1 # pageSize: 10
第二页
# page2 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 2 # pageSize: 10
第三页依次类推。
程序入口
首先回顾urllib爬取的基本操作:
# 使用urllib获取百度首页的源码
import urllib.request
# 1.定义一个url,就是你要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面的源码 content内容
# read方法 返回的是字节形式的二进制数据
# 将二进制数据转换为字符串
# 二进制-->字符串 解码 decode方法
content = response.read().decode('utf-8')
# 4.打印数据
print(content)
1.定义一个url,就是你要访问的地址
2.模拟浏览器向服务器发送请求 response响应
3.获取响应中的页面的源码 content内容
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
对应的,我们在主函数中也类似声明方法。
url组成数据定位
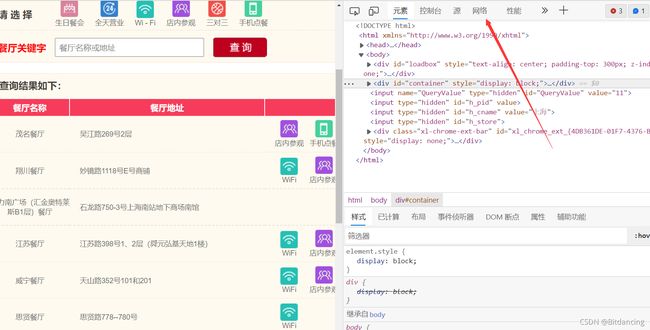
爬虫的关键在于找接口。对于这个案例,在预览页可以找到页面对应的json数据,说明这是我们要的数据。
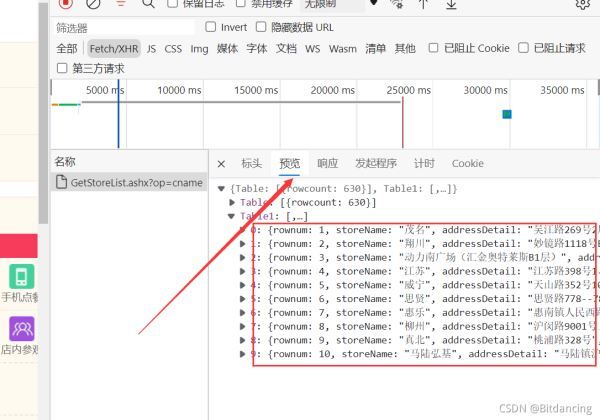
构造url
不难发现,肯德基官网的url的一个共同点,我们把它保存为base_url。
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
参数
老样子,找规律,只有'pageIndex'和页码有关。
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
post请求
- post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
- 编码之后必须调用encode方法
- 参数放在请求对象定制的方法中:post的请求的参数,是不会拼接在url后面的,而是放在请求对象定制的参数中
所以将data进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
标头获取(防止反爬的一种手段)

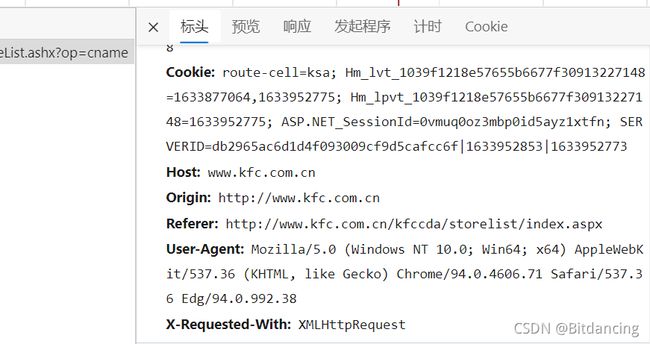
即 响应头中UA部分。
User Agent,用户代理,特殊字符串头,使得服务器能够识别客户使用的操作系统及版本,CPU类型,浏览器及版本,浏览器内核,浏览器渲染引擎,浏览器语言,浏览器插件等。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
请求对象定制
参数,base_url,请求头都准备得当后,就可以进行请求对象定制了。
request = urllib.request.Request(base_url, headers=headers, data=data)
获取网页源码
把request请求作为参数,模拟浏览器向服务器发送请求 获得response响应。
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
获取响应中的页面的源码,下载数据
使用 read()方法,得到字节形式的二进制数据,需要使用 decode进行解码,转换为字符串。
content = response.read().decode('utf-8')
然后我们将下载得到的数据写进文件,使用 with open() as fp 的语法,系统自动关闭文件。
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
全部代码
# ajax的post请求肯德基官网 获取上海肯德基地点前10页
# page1
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 1
# pageSize: 10
# page2
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request, urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
request = urllib.request.Request(base_url, headers=headers, data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
爬取后结果
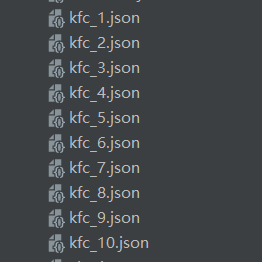
以上就是Python爬取肯德基官网ajax的post请求实现过程的详细内容,更多关于Python爬取肯德基官网ajax的post请求的资料请关注脚本之家其它相关文章!