kubernetes集群搭建
kubernetes集群搭建
- kubernetes概念
- kubernetes 常用命令
- apiVersion对照表
- 部署kubernetes-master
-
-
- 环境配置
- 相关镜像的配置
- 初始化操作
- 相关文件汇总
-
- 安装过程
- 部署kubernetes-node
-
-
- 测试
-
- Harbor搭建
-
-
- server1
- server2&server3
-
- 添加ipvs负载
- kubernetes高可用架构
-
-
- haproxy-keepalived架构
-
前期准备
| server1-172.25.70.11 | k8smaster |
| server2-172.25.70.12 | k8snode1 |
| server3-172.25.70.13 | k8snode2 |
参考文献
k8s中文社区文档
k8s官网
api解释
kubernetes概念
Kubernetes的几个重要概念
| Cluster | Cluster是计算、存储和网络资源的集合,Kubernetes利用这些资源运行各种基于容器的应用 |
| Master | Master是Cluster的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master运行Linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个Maste |
| Node | Node的职责是运行容器应用。Node由Master管理,Node负责监控并汇报容器的状态,同时根据Master的要求管理容器的生命周期。Node运行在Linux操作系统上,可以是物理机或者是虚拟机 |
| Pod | Pod是Kubernetes的最小工作单元。每个Pod包含一个或多个容器。Pod中的容器会作为一个整体被Master调度到一个Node上运行 |
| Controller | Kubernetes通常不会直接创建Pod,而是通过Controller来管理Pod的。Controller中定义了Pod的部署特性,比如有几个副本、在什么样的Node上运行等。为了满足不同的业务场景,Kubernetes提供了多种Controller,包括Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job等,我们逐一讨论 |
| Service | Deployment可以部署多个副本,每个Pod都有自己的IP,外界如何访问这些副本呢?通过Pod的IP吗?要知道Pod很可能会被频繁地销毁和重启,它们的IP会发生变化,用IP来访问不太现实。答案是ServiceKubernetes Service定义了外界访问一组特定Pod的方式。Service有自己的IP和端口,Service为Pod提供了负载均衡。Kubernetes运行容器(Pod)与访问容器(Pod)这两项任务分别由Controller和Service执行 |
| Namespace | 如果有多个用户或项目组使用同一个Kubernetes Cluster,如何将他们创建的Controller、Pod等资源分开呢?答案就是Namespace。Namespace可以将一个物理的Cluster逻辑上划分成多个虚拟Cluster,每个Cluster就是一个Namespace。不同Namespace里的资源是完全隔离的。 |
Kubernetes引入Pod主要基于下面两个目的:
- 可管理性。
有些容器天生就是需要紧密联系,一起工作。Pod提供了比容器 更高层次的抽象,将它们封装到一个部署单元中。Kubernetes以Pod 为最小单位进行调度、扩展、共享资源、管理生命周期- 通信和资源共享。
Pod中的所有容器使用同一个网络namespace,即相同的IP地址和 Port空间。它们可以直接用localhost通信。同样的,这些容器可以共享存储,当Kubernetes挂载volume到Pod,本质上是将volume挂载到

kubernetes 常用命令
基础命令
create,delete,get,run,expose,set,explain,edit。
create命令:根据文件或者输入来创建资源
# 创建Deployment和Service资源
kubectl create -f javak8s-deployment.yaml
kubectl create -f javak8s-service.yaml
delete命令:删除资源
# 根据yaml文件删除对应的资源,但是yaml文件并不会被删除,这样更加高效
kubectl delete -f javak8s-deployment.yaml
kubectl delete -f javak8s-service.yaml
# 也可以通过具体的资源名称来进行删除,使用这个删除资源,需要同时删除pod和service资源才行
kubectl delete 具体的资源名称
get命令:获得资源信息
# 查看所有的资源信息
kubectl get all
# 查看pod列表
kubectl get pod
# 显示pod节点的标签信息
kubectl get pod --show-labels
# 根据指定标签匹配到具体的pod
kubectl get pods -l app=example
# 查看node节点列表
kubectl get node
# 显示node节点的标签信息
kubectl get node --show-labels
# 查看pod详细信息,也就是可以查看pod具体运行在哪个节点上(ip地址信息)
kubectl get pod -o wide
# 查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
kubectl get svc
# 查看命名空间
kubectl get ns
# 查看所有pod所属的命名空间
kubectl get pod --all-namespaces
# 查看所有pod所属的命名空间并且查看都在哪些节点上运行
kubectl get pod --all-namespaces -o wide
# 查看目前所有的replica set,显示了所有的pod的副本数,以及他们的可用数量以及状态等信息
kubectl get rs
# 查看目前所有的deployment
kubectl get deployment
# 查看已经部署了的所有应用,可以看到容器,以及容器所用的镜像,标签等信息
kubectl get deploy -o wide
run命令:在集群中创建并运行一个或多个容器镜像。
# 基本语法
run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] [--overrides=inline-json] [--command] -- [COMMAND] [args...]
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例
kubectl run nginx --replicas=3 --labels="app=example" --image=nginx:1.10 --port=80
其他用法参见:http://docs.kubernetes.org.cn/468.html
expose命令:创建一个service服务,并且暴露端口让外部可以访问
# 创建一个nginx服务并且暴露端口让外界可以访问
kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service
关于expose的详细用法参见:http://docs.kubernetes.org.cn/475.html
set命令: 配置应用的一些特定资源,也可以修改应用已有的资源
# 使用kubectl set --help查看,它的子命令,env,image,resources,selector,serviceaccount,subject。
set命令详情参见:http://docs.kubernetes.org.cn/669.html
语法:
resources (-f FILENAME | TYPE NAME) ([--limits=LIMITS & --requests=REQUESTS]
kubectl set resources 命令
这个命令用于设置资源的一些范围限制。
资源对象中的Pod可以指定计算资源需求(CPU-单位m、内存-单位Mi),即使用的最小资源请求(Requests),限制(Limits)的最大资源需求,Pod将保证使用在设置的资源数量范围。
对于每个Pod资源,如果指定了Limits(限制)值,并省略了Requests(请求),则Requests默认为Limits的值。
可用资源对象包括(支持大小写):replicationcontroller、deployment、daemonset、job、replicaset。
例如:
# 将deployment的nginx容器cpu限制为“200m”,将内存设置为“512Mi”
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 为nginx中的所有容器设置 Requests和Limits
kubectl set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
# 删除nginx中容器的计算资源值
kubectl set resources deployment nginx --limits=cpu=0,memory=0 --requests=cpu=0,memory=0
kubectl set selector命令
设置资源的selector(选择器)。如果在调用"set selector"命令之前已经存在选择器,则新创建的选择器将覆盖原来的选择器。
selector必须以字母或数字开头,最多包含63个字符,可使用:字母、数字、连字符" - " 、点"."和下划线" _ "。如果指定了--resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
注意:目前selector命令只能用于Service对象。
# 语法
selector (-f FILENAME | TYPE NAME) EXPRESSIONS [--resource-version=version]
kubectl set image命令
用于更新现有资源的容器镜像。
可用资源对象包括:pod (po)、replicationcontroller (rc)、deployment (deploy)、daemonset (ds)、job、replicaset (rs)。
# 语法
image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ... CONTAINER_NAME_N=CONTAINER_IMAGE_N
# 将deployment中的nginx容器镜像设置为“nginx:1.9.1”。
kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
# 所有deployment和rc的nginx容器镜像更新为“nginx:1.9.1”
kubectl set image deployments,rc nginx=nginx:1.9.1 --all
# 将daemonset abc的所有容器镜像更新为“nginx:1.9.1”
kubectl set image daemonset abc *=nginx:1.9.1
# 从本地文件中更新nginx容器镜像
kubectl set image -f path/to/file.yaml nginx=nginx:1.9.1 --local -o yaml
explain命令:用于显示资源文档信息
kubectl explain rs
edit命令:用于编辑资源信息
# 编辑Deployment nginx的一些信息
kubectl edit deployment nginx
# 编辑service类型的nginx的一些信息
kubectl edit service/nginx
设置命令
label,annotate,completion
label命令:用于更新(增加、修改或删除)资源上的 label(标签)
label 必须以字母或数字开头,可以使用字母、数字、连字符、点和下划线,最长63个字符。
如果--overwrite 为 true,则可以覆盖已有的 label,否则尝试覆盖 label 将会报错。
如果指定了--resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
# 语法
label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
# 给名为foo的Pod添加label unhealthy=true
kubectl label pods foo unhealthy=true
# 给名为foo的Pod修改label 为 'status' / value 'unhealthy',且覆盖现有的value
kubectl label --overwrite pods foo status=unhealthy
# 给 namespace 中的所有 pod 添加 label
kubectl label pods --all status=unhealthy
# 仅当resource-version=1时才更新 名为foo的Pod上的label
kubectl label pods foo status=unhealthy --resource-version=1
# 删除名为“bar”的label 。(使用“ - ”减号相连)
kubectl label pods foo bar-
annotate命令:更新一个或多个资源的Annotations信息。也就是注解信息,可以方便的查看做了哪些操作。
Annotations由key/value组成。
Annotations的目的是存储辅助数据,特别是通过工具和系统扩展操作的数据,更多介绍在这里。
如果--overwrite为true,现有的annotations可以被覆盖,否则试图覆盖annotations将会报错。
如果设置了--resource-version,则更新将使用此resource version,否则将使用原有的resource version。
# 语法
annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
# 更新Pod“foo”,设置annotation “description”的value “my frontend”,如果同一个annotation多次设置,则只使用最后设置的value值
kubectl annotate pods foo description='my frontend'
# 根据“pod.json”中的type和name更新pod的annotation
kubectl annotate -f pod.json description='my frontend'
# 更新Pod"foo",设置annotation“description”的value“my frontend running nginx”,覆盖现有的值
kubectl annotate --overwrite pods foo description='my frontend running nginx'
# 更新 namespace中的所有pod
kubectl annotate pods --all description='my frontend running nginx'
# 只有当resource-version为1时,才更新pod ' foo '
kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
# 通过删除名为“description”的annotations来更新pod ' foo '。#不需要- overwrite flag。
kubectl annotate pods foo description-
completion命令:用于设置kubectl命令自动补全
$ source <(kubectl completion bash) # setup autocomplete in bash, bash-completion package should be installed first.
$ source <(kubectl completion zsh) # setup autocomplete in zsh
kubectl 部署命令
rollout,rolling-update,scale,autoscale
rollout命令:用于对资源进行管理
可用资源包括:deployments,daemonsets。
子命令:
history(查看历史版本)
pause(暂停资源)
resume(恢复暂停资源)
status(查看资源状态)
undo(回滚版本)
# 语法
kubectl rollout SUBCOMMAND
# 回滚到之前的deployment
kubectl rollout undo deployment/abc
# 查看daemonet的状态
kubectl rollout status daemonset/foo
rolling-update命令:执行指定ReplicationController的滚动更新。
该命令创建了一个新的RC, 然后一次更新一个pod方式逐步使用新的PodTemplate,最终实现Pod滚动更新,new-controller.json需要与之前RC在相同的namespace下。
# 语法
rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --image=NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
# 使用frontend-v2.json中的新RC数据更新frontend-v1的pod
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 使用JSON数据更新frontend-v1的pod
cat frontend-v2.json | kubectl rolling-update frontend-v1 -f -
# 其他的一些滚动更新
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
kubectl rolling-update frontend --image=image:v2
kubectl rolling-update frontend-v1 frontend-v2 --rollback
scale命令:扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量
scale也可以指定多个前提条件,如:当前副本数量或 --resource-version ,进行伸缩比例设置前,系统会先验证前提条件是否成立。这个就是弹性伸缩策略
# 语法
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
# 将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
# 将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
kubectl scale --replicas=3 -f foo.yaml
# 如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# 设置多个RC中Pod副本数量
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
autoscale命令: 这个比scale更加强大,也是弹性伸缩策略 ,它是根据流量的多少来自动进行扩展或者缩容
指定Deployment、ReplicaSet或ReplicationController,并创建已经定义好资源的自动伸缩器。使用自动伸缩器可以根据需要自动增加或减少系统中部署的pod数量。
# 语法
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
# 使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
kubectl autoscale deployment foo --min=2 --max=10
# 使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
kubectl autoscale rc foo --max=5 --cpu-percent=80
集群管理命令:certificate,cluster-info,top,cordon,uncordon,drain,taint
certificate命令:用于证书资源管理,授权等
[root@master ~]# kubectl certificate --help
Modify certificate resources.
Available Commands:
approve Approve a certificate signing request
deny Deny a certificate signing request
Usage:
kubectl certificate SUBCOMMAND [options]
Use "kubectl --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands).
# 例如,当有node节点要向master请求,那么是需要master节点授权的
kubectl certificate approve node-csr-81F5uBehyEyLWco5qavBsxc1GzFcZk3aFM3XW5rT3mw node-csr-Ed0kbFhc_q7qx14H3QpqLIUs0uKo036O2SnFpIheM18
cluster-info命令:显示集群信息
kubectl cluster-info
[root@master ~]# kubectl cluster-info
Kubernetes master is running at http://localhost:8080
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
top命令:用于查看资源的cpu,内存磁盘等资源的使用率
kubectl top pod --all-namespaces
它需要heapster运行才行
cordon命令:用于标记某个节点不可调度
uncordon命令:用于标签节点可以调度
drain命令: 用于在维护期间排除节点。
taint命令:参见:https://blog.frognew.com/2018/05/taint-and-toleration.html
集群故障排查和调试命令
describe,logs,exec,attach,port-foward,proxy,cp,auth
describe命令:显示特定资源的详细信息
# 语法
kubectl describe TYPE NAME_PREFIX
(首先检查是否有精确匹配TYPE和NAME_PREFIX的资源,如果没有,将会输出所有名称以NAME_PREFIX开头的资源详细信息)
支持的资源包括但不限于(大小写不限):pods (po)、services (svc)、 replicationcontrollers (rc)、nodes (no)、events (ev)、componentstatuses (cs)、 limitranges (limits)、persistentvolumes (pv)、persistentvolumeclaims (pvc)、 resourcequotas (quota)和secrets。
#查看my-nginx pod的详细状态
kubectl describe po my-nginx
logs命令:用于在一个pod中打印一个容器的日志,如果pod中只有一个容器,可以省略容器名
# 语法
kubectl logs [-f] [-p] POD [-c CONTAINER]
# 返回仅包含一个容器的pod nginx的日志快照
$ kubectl logs nginx
# 返回pod ruby中已经停止的容器web-1的日志快照
$ kubectl logs -p -c ruby web-1
# 持续输出pod ruby中的容器web-1的日志
$ kubectl logs -f -c ruby web-1
# 仅输出pod nginx中最近的20条日志
$ kubectl logs --tail=20 nginx
# 输出pod nginx中最近一小时内产生的所有日志
$ kubectl logs --since=1h nginx
# 参数选项
-c, --container="": 容器名。
-f, --follow[=false]: 指定是否持续输出日志(实时日志)。
--interactive[=true]: 如果为true,当需要时提示用户进行输入。默认为true。
--limit-bytes=0: 输出日志的最大字节数。默认无限制。
-p, --previous[=false]: 如果为true,输出pod中曾经运行过,但目前已终止的容器的日志。
--since=0: 仅返回相对时间范围,如5s、2m或3h,之内的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--since-time="": 仅返回指定时间(RFC3339格式)之后的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--tail=-1: 要显示的最新的日志条数。默认为-1,显示所有的日志。
--timestamps[=false]: 在日志中包含时间戳。
exec命令:进入容器进行交互,在容器中执行命令
# 语法
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
#命令选项
-c, --container="": 容器名。如果未指定,使用pod中的一个容器。
-p, --pod="": Pod名。
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 进入nginx容器,执行一些命令操作
kubectl exec -it nginx-deployment-58d6d6ccb8-lc5fp bash
attach命令:连接到一个正在运行的容器。
#语法
kubectl attach POD -c CONTAINER
# 参数选项
-c, --container="": 容器名。如果省略,则默认选择第一个 pod
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 获取正在运行中的pod 123456-7890的输出,默认连接到第一个容器
kubectl attach 123456-7890
# 获取pod 123456-7890中ruby-container的输出
kubectl attach 123456-7890 -c ruby-container
# 切换到终端模式,将控制台输入发送到pod 123456-7890的ruby-container的“bash”命令,并将其输出到控制台/
# 错误控制台的信息发送回客户端。
kubectl attach 123456-7890 -c ruby-container -i -t
cp命令:拷贝文件或者目录到pod容器中
用于pod和外部的文件交换,类似于docker 的cp,就是将容器中的内容和外部的内容进行交换。
其他命令
api-servions,config,help,plugin,version
api-servions命令:打印受支持的api版本信息
# kubectl api-versions
kubectl api-versions
```powershell
help命令:用于查看命令帮助
# 显示全部的命令帮助提示
kubectl --help
# 具体的子命令帮助,例如
kubectl create --help
config:用于修改kubeconfig配置文件(用于访问api,例如配置认证信息)
version命令:打印客户端和服务端版本信息
[root@master ~]# kubectl version
Client Version: version.Info{
Major:"1", Minor:"15", GitVersion:"v1.15.3", GitCommit:"2d3c76f9091b6bec110a5e63777c332469e0cba2", GitTreeState:"clean", BuildDate:"2019-08-19T11:13:54Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{
Major:"1", Minor:"9", GitVersion:"v1.9.0", GitCommit:"925c127ec6b946659ad0fd596fa959be43f0cc05", GitTreeState:"clean", BuildDate:"2017-12-15T20:55:30Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
plugin命令:运行一个命令行插件
高级命令
apply,patch,replace,convert
apply命令: 通过文件名或者标准输入对资源应用配置
通过文件名或控制台输入,对资源进行配置。 如果资源不存在,将会新建一个。可以使用 JSON 或者 YAML 格式。
# 语法
kubectl apply -f FILENAME
# 将pod.json中的配置应用到pod
kubectl apply -f ./pod.json
# 将控制台输入的JSON配置应用到Pod
cat pod.json | kubectl apply -f -
选项
-f, --filename=[]: 包含配置信息的文件名,目录名或者URL。
--include-extended-apis[=true]: If true, include definitions of new APIs via calls to the API server. [default true]
-o, --output="": 输出模式。"-o name"为快捷输出(资源/name).
--record[=false]: 在资源注释中记录当前 kubectl 命令。
-R, --recursive[=false]: Process the directory used in -f, --filename recursively. Useful when you want to manage related manifests organized within the same directory.
--schema-cache-dir="~/.kube/schema": 非空则将API schema缓存为指定文件,默认缓存到'$HOME/.kube/schema'
--validate[=true]: 如果为true,在发送到服务端前先使用schema来验证输入。
patch命令: 使用补丁修改,更新资源的字段,也就是修改资源的部分内容
# 语法
kubectl patch (-f FILENAME | TYPE NAME) -p PATCH
# Partially update a node using strategic merge patch
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# Update a container's image; spec.containers[*].name is required because it's a merge key
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
replace命令: 通过文件或者标准输入替换原有资源
# 语法
kubectl replace -f FILENAME
# Replace a pod using the data in pod.json.
kubectl replace -f ./pod.json
# Replace a pod based on the JSON passed into stdin.
cat pod.json | kubectl replace -f -
# Update a single-container pod's image version (tag) to v4
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
# Force replace, delete and then re-create the resource
kubectl replace --force -f ./pod.json
convert命令: 不同的版本之间转换配置文件
# 语法
kubectl convert -f FILENAME
# Convert 'pod.yaml' to latest version and print to stdout.
kubectl convert -f pod.yaml
# Convert the live state of the resource specified by 'pod.yaml' to the latest version
# and print to stdout in json format.
kubectl convert -f pod.yaml --local -o json
# Convert all files under current directory to latest version and create them all.
kubectl convert -f . | kubectl create -f -

apiVersion对照表
api官方文档
kubectl api-versions
| CertificateSigningRequest | certificates.k8s.io/v1beta1 |
| ClusterRoleBinding | rbac.authorization.k8s.io/v1 |
| ClusterRole | rbac.authorization.k8s.io/v1 |
| ComponentStatus | v1 |
| ConfigMap | v1 |
| ControllerRevision | apps/v1 |
| CronJob | batch/v1beta1 |
| DaemonSet | extensions/v1beta1 |
| Deployment | extensions/v1beta1 |
| Endpoints | v1 |
| Event | v1 |
| HorizontalPodAutoscaler | autoscaling/v1 |
| Ingress | extensions/v1beta1 |
| Job | batch/v1 |
| LimitRange | v1 |
| Namespace | v1 |
| NetworkPolicy | extensions/v1beta1 |
| Node | v1 |
| PersistentVolumeClaim | v1 |
| PersistentVolume | v1 |
| PodDisruptionBudget | policy/v1beta1 |
| Pod | v1 |
| PodSecurityPolicy | extensions/v1beta1 |
| PodTemplate | v1 |
| ReplicaSet | extensions/v1beta1 |
| ReplicationController | v1 |
| ResourceQuota | v1 |
| RoleBinding | rbac.authorization.k8s.io/v1 |
| Role | rbac.authorization.k8s.io/v1 |
| Secret | v1 |
| ServiceAccount | v1 |
| Service | v1 |
| StatefulSet | apps/v1 |
| alpha | 名称中带有alpha的API版本是进入Kubernetes的新功能的早期候选版本。这些可能包含错误,并且不保证将来可以使用。 |
| beta | API版本名称中的beta表示测试已经超过了alpha级别,并且该功能最终将包含在Kubernetes中。 虽然它的工作方式可能会改变,并且对象的定义方式可能会完全改变,但该特征本身很可能以某种形式将其变为Kubernetes。 |
| stable | 稳定的apiVersion这些名称中不包含alpha或beta。 它们可以安全使用。 |
| v1 | 这是Kubernetes API的第一个稳定版本。 它包含许多核心对象。 |
| apps/v1 | apps是Kubernetes中最常见的API组,其中包含许多核心对象和v1。 它包括与在Kubernetes上运行应用程序相关的功能,如Deployments,RollingUpdates和ReplicaSets。 |
| autoscaling/v1 | 此API版本允许根据不同的资源使用指标自动调整容器。此稳定版本仅支持CPU扩展,但未来的alpha和beta版本将允许您根据内存使用情况和自定义指标进行扩展。 |
| batch/v1 | batchAPI组包含与批处理和类似作业的任务相关的对象(而不是像应用程序一样的任务,如无限期地运行Web服务器)。 这个apiVersion是这些API对象的第一个稳定版本。 |
| batch/v1beta1 | Kubernetes中批处理对象的新功能测试版,特别是包括允许您在特定时间或周期运行作业的CronJobs。 |
| certificates.k8s.io/v1beta1 | 此API版本添加了验证网络证书的功能,以便在群集中进行安全通信。 您可以在官方文档上阅读更多内容。 |
| extensions/v1beta1 | 此版本的API包含许多新的常用Kubernetes功能。 部署,DaemonSets,ReplicaSet和Ingresses都在此版本中收到了重大更改。 |
| policy/v1beta1 | 此apiVersion增加了设置pod中断预算和pod安全性新规则的功能 |
| rbac.authorization.k8s.io/v1 | 此apiVersion包含Kubernetes基于角色的访问控制的额外功能。 |

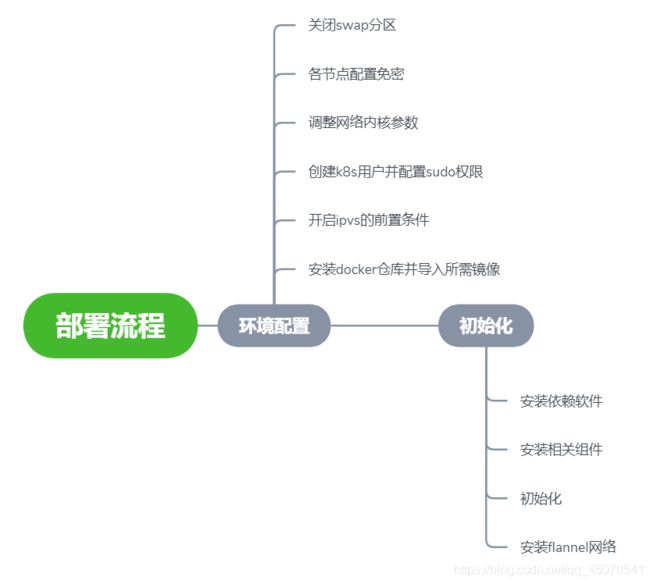
部署kubernetes-master
整个部署过程脑图
| 组件 | 作用 | 版本 |
|---|---|---|
| API Server | 提供HTTP/HTTPS RESTful API,即Kubernetes API。API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源 | k8s.gcr.io/kube-apiserver:v1.16.2 |
| Controller Manager | 负责管理Cluster各种资源,保证资源处于预期的状态 | k8s.gcr.io/kube-controller-manager:v1.16.2 |
| Scheduler | 负责决定将Pod放在哪个Node上运行。Scheduler在调度时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求",service在逻辑上代表了后端的多个Pod,外界通过service访问 | k8s.gcr.io/kube-scheduler:v1.16.2: |
| Pod | service接收到的请求是如何转发到Pod的呢?这就是kube-proxy要完成的工作 | k8s.gcr.io/kube-proxy:v1.16.2 k8s.gcr.io/pause:3.1 |
| etcd | 负责保存Kubernetes Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速地通知Kubernetes相关组件 | k8s.gcr.io/etcd:3.3.15-0 k8s.gcr.io/coredns:1.6.2 |
版本问题需要查看镜像
环境配置
配置免秘
ssh-keygen
ssh-copy-id server2
ssh-copy-id server3
关闭swap分区
vim /etc/fstab #三个节点都要做
swapoff -a
调整内核参数
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
echo "1" >/proc/sys/net/bridge/bridge-nf-call-ip6tables
kube-proxy开启ipvs的前置条件
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules <#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modutes && bash
/etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
相关镜像的配置
- 在安装k8s过程中,会先从本地找所需镜像,如果没有则去网络上下载,下载所需的时间非常长,建议先下载到本地或者上传私有仓库
- 如果不想配置私有仓库,也可以配置镜像加速器,即从国内找镜像站点,这里找的是阿里云
搭建私有仓库
#yum install -y yum-utils device-mapper-persistent-data lvm2
#yum-config-manager \
#--add-repo \
#http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce
#yum update -y && yum install -y docker-ce
#配置daemon.
cat > /etc/docker/daemon.json <{
"exec-opts" : [ "native.cgroupdriver=systemd"],
"log-driver" : "json-file",
"log-opts" : {
"max-size" : "100m"
}
"insecure-registries" : ["https://www.westos.com"] #信任私有仓库
}
mkdir -p /etc/systemd/system/docker.service.d
#重启服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
将所需镜像导入仓库
| API Server(k8s.gcr.io/kube-apiserver) | 是kubernetes cluster的前端接口,各种客户端工具以及kubernetes其他组件可以通过它管理cluster的各种资源 |
| k8s.gcr.io/kube-scheduler | 负责决定将pod放在哪个node上运行 |
| k8s.gcr.io/kube-controller-manager | 负责管理cluster各种资源,保证资源处于预期状态 |
| k8s.gcr.io/etcd | 负责保存集群的配置信息和各种资源的状态信息,当数据发生变化的时候,etcd会快速通知kubernetes相关组件 |
| pod网络 | pod要能够相互通信,kubernetes cluster必须部署pod网络,flannel是其中一个可选的方案 |
配置镜像加速器
#编辑下载镜像的脚本
vim kubernetes.sh
# 配置阿里云镜像加速器
vim/etc/yum.repos.d/kubernetes.repo
#编辑下载镜像的脚本
vim kubernetes.sh
#!/bin/bash
pull image form aliyun registry and docker tag k8s
image_name=(
kube-proxy:v1.15.3
kube-apiserver:v1.15.3
kube-controller-manager:v1.15.3
kube-scheduler:v1.15.3
pause:3.1
etcd:3.3.10
coredns:1.3.1
)
aliyun_registry="registry.cn-hangzhou.aliyuncs.com/google_containers/"
k8s_registry="k8s.gcr.io/"
for image in ${
image_name[@]};do
docker pull $aliyun_registry$image
docker tag $aliyun_registry$image $k8s_registry$image
docker load -i $image
done
docker rmi registry.cnhangzhou.aliyuncs.com/google_containers/coredns:1.6.2
docker images
vim/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
初始化操作
安装相关组件
kubeadm config images list #查看所需要的版本
vim /etc/yum.repos.d/kubernetes.repo
yum install -y conntrack ntpdate ntp ipvsadm ipset jq curl sysstat libseccomp wget net-tools git
yum install kubelet kubeadm kubectl docker-ce -y
systemctl start docker
systemctl enable docker
- kubelet:运行在cluster所有节点上,负责启动pod和容器
- kubeadm:用于初始化cluster
- kubectl:是kubernetes命令行工具,通过kubectk可以部署和管理应用,查看各种资源,创建,删除和更新各种组件,配置阿里云网络yum源(三台虚拟机都做)
初始化
#初始化一:命令行初始化
vim kubernetes.sh #编写导入镜像的脚本
sh kubernetes.sh
kubeadm init --apiserver-advertise-address 172.25.0.1 --pod-network-cidr=10.244.0.0/16
--kubernetes-version=v1.12.0 --service-cidr=10.96.0.0/12
–apiserver-advertise-address指明用master的哪个intserface与cluster的其他节点通信(如果master有多个intserface,建议明确指定,如果不指定,kubeadm会自动选择有默认网关的interface)
–pod-network-cidr= 指定pos网络的范围(lubernetes支持多种网络方案,而且不同的网络方案对–pod-network-cidr
有自己的要求,这里设定为 10.244.0.0/16 是因为我们将使用flannel网络方案,必须设置成这个CIDR)
#初始化二:脚本初始化
#导出初始化模板
kubeadm config print init-defaults > kubeadm-config.yml
kubeadm init --config=kubeadm-config.yml --experimental-upload-certs | tee kubeadm-init.log
创建k8s用户,增加安全性
useradd k8s
passwd k8s
vim /etc/sudoers
su - k8s
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
启用kubectl命令的自动补全功能
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
配置flannel网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#flannel.yml文件是网络清单模板,运行后会创建网络pod。如果不执行,master节点的状态就不会是running状态
#或者
mkdir -p install-k8s/core/plugin/flannel
cd install-k8s/core/plugin/flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl create -f kube-flannel.yml
# 以上两种操作均可
kubectl get pod -n kube-system
ifconfig #会出现flannel
#所有组件默认安装在kube-system命名空间下,如果不加-n参数,就显示default命名空间
相关文件汇总
下载镜像的脚本
#编辑下载镜像的脚本
vim kubernetes.sh
#!/bin/bash
pull image form aliyun registry and docker tag k8s
image_name=(
kube-proxy:v1.15.3
kube-apiserver:v1.15.3
kube-controller-manager:v1.15.3
kube-scheduler:v1.15.3
pause:3.1
etcd:3.3.10
coredns:1.3.1
)
aliyun_registry="registry.cn-hangzhou.aliyuncs.com/google_containers/"
k8s_registry="k8s.gcr.io/"
for image in ${
image_name[@]};do
docker pull $aliyun_registry$image
docker tag $aliyun_registry$image $k8s_registry$image
docker load -i $image
done
docker rmi registry.cnhangzhou.aliyuncs.com/google_containers/coredns:1.6.2
docker images
这些镜像在k8s初始化和pod的创建等过程中会用到,可以先去阿里云上下载到本地,也可以上传到Harbor仓库
vim kubeadm-config.yml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system: bootstrappers : kubeadm: default-node-token
token: abcdef .0123456789abcdef
ttl: 24h0m0s
usages :
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint :
advertiseAddress: 172.25.70.11
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
cluste rName: kubernetes
controllerManager: {
}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kube rnetesVersion: v1.14.0
networking :
dnsDomain: cluster. local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {
}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
# 配置阿里云镜像加速器
vim/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行状态
问题概述
#报错一:有的虚拟机上运行会有如下报错,要求关闭swap分区
[ERROR Swap]: running with swap on is not supported. Please disable swap
vim /etc/fstab
Created by anaconda on Sat May 18 17:02:46 2019
#
Accessible filesystems, by reference, are maintained under '/dev/disk'
See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=c24172a6-4f86-450f-91f7-8542c07f7254 /boot xfs defaults 0 0
#/dev/mapper/rhel-swap swap swap defaults 0 0
#报错二:
2.[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
安装过程
- kubeadm 执行初始化前的检查
- 生成token和证书
- 生成kubeconfig文件,kubelet需要用这个文件与master通信
- 安装附加组建kube-proxy 和kube-dns
- kubernetes master初始化成功
- 提示如何配置kubectl
- 提示如何安装pod网络
- 提示如何注册其他节点到cluster
部署kubernetes-node
安装k8s
vim /etc/yum.repos.d/kubernetes.repo
yum install -y conntrack ntpdate ntp ipvsadm ipset jq curl sysstat libseccomp wget net-tools git
yum install kubelet kubeadm kubectl docker-ce -y
systemctl start docker
systemctl enable docker
vim /etc/fstab #关闭swap分区
swapoff -a
#调整内核参数
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
echo "1" >/proc/sys/net/bridge/bridge-nf-call-ip6tables
添加节点到集群中
kubeadm join 172.25.0.1:6443 --token jnclxq.kv2t3s3twn6m0e0f \
--discovery-token-ca-cert-hash sha256:c93d17daed5b3d5b51ee81ea239c557923a496236647a104dcb8b6709904911b
master初始化完成后会有提示,token和hash参数参考master的反馈结果
测试
kubectl get namespaces
NAME STATUS AGE
default Active 10d
kube-node-lease Active 10d
kube-public Active 10d
kube-system Active 10d
#default:创建资源时如果不指定,将被放到这个Namespace中
kubectl run http-app --image=httpd --replicas=2 #创建两个pod
kubectl get deployment
k8s创建pod的过程
- kubectl发送部署请求到API Server
- API Server通知Controller Manager创建一个deployment资源
- Scheduler执行调度任务,将两个副本Pod分发到k8s-node1和k8s-node2
- k8s-node1和k8s-node2上的kubectl在各自的节点上创建并运行Pod
补充两点:
- 应用的配置和当前状态信息保存在etcd中,执行kubectl get pod时API Server会从etcd中读取这些数据
- flannel会为每个Pod都分配IP。因为没有创建service,所以目前kube-proxy还没参与进来

Harbor搭建
Harbor 官方地址: https://github.com/vmware/harbor/releases
server1
要有解析
vim /etc/hosts
172.25.70.11 www.westos.com
tar -zxvf harbor-ofline-insaler.tgz
https:/github.com/vmware/harbor/releases/download/v1.2.0/harbor-offline-installer-v.1.2.0.tgz
修改harbor.cfg参数
vim /usr/local/harbor/harbor.cfg
hostmame: www.westos.com #目标的主机名或者完全限定域名
ui_url_protocol: https #默认http
db_ password: 123456 # 用于db_auth的MySQL数据库的根密码。更改此密码进行任何生产用途
max_job_workers: 3
#(默认值为3) 作业服务中的复制工作人员的最大数量。对于每个映像复制作业,工作人员将存储库的所有标签同步到远程目标。
#增加此数字允许系统中更多的并发复制作业。但是,由于每个工作人员都会消耗一定数量的网络/CPU/I0资源,请根据主机的硬件资源,仔细选择该属性的值
customize_crt: /data/cert/server.crt #(on或off. 默认为on)当此属性打开时,prepare脚本将为注册表的令牌的生成验证创建私钥和根证书
ssl_cert = /data/cert/server.crt #SSL证书的路径,仅当协议设置为https时才应用
ssl_cert_key = /data/cert/server.key #SSL密 钥的路径,仅当协议设置为https时才应用
secretkey_path: #用于在复制策略中加密或解密远程注册表的密码的密钥路径
创建https证书以及配置相关目录权限
openssl genrsa -des3 -out server.key 2048 #创建私钥
openssl req -new -key server.key -out server.csr #创建证书
cp server.key server.key.org #备份
openssl rsa -in server.key.org -out server.key #私钥退密码
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt #签名证书
upgrade
mkdir /data/cert
chmod -R 777 /data/cert
cd /usr/local/harbor
./install.sh
server2&server3
vim /etc/hosts
172.25.70.11 www.westos.com
docker login https://www.westos.com
kubectl run nginx-deployment --image= --port=80 --repicas=1 #创建的数量
kubectl scale --replicas=3 deployment/nginx-deployment #扩容,如果数量小于三个就会自动创建新的

添加ipvs负载
安装ipvsadm、conntrack
yum -y install ipvsadm conntrack-tools
2.加载ipvs模块
vim /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4"
for kernel_module in \${
ipvs_modules}; do
/sbin/modinfo -F filename \${
kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${
kernel_module}
fi
done
执行
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
3.修改服务器内核参数,增加
cat >>/etcsysctl.conf <.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
再执行
sysctl -p
4.修改kube-proxy配置参数
vim /etc/kubernetes/proxy
KUBE_PROXY_ARGS="--bind-address=192.168.0.210 \ #服务器IP
--hostname-override=192.168.0.210 \ #服务器IP
--masquerade-all=true \ #确保反向流量通过
--feature-gates=SupportIPVSProxyMode=true \ #打开支持ipvs模式
--proxy-mode=ipvs \ #明确代理模式为ipvs
--ipvs-min-sync-period=5s \
--ipvs-sync-period=5s \
--ipvs-scheduler=rr \ #选择调度方式为轮询调度
--kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig \
--cluster-cidr=10.254.0.0/16"
摘自https://blog.51cto.com/fengwan/2345983
kubernetes高可用架构
haproxy-keepalived架构
- 环境配置和搭建过程类似,不同的地方是在初始化时需要更改初始化文件
- 这里使用的是睿云的部署架构,文件和镜像的获取连接在文中有说明
搭建haproxy-keepalived架构
在安装master,修改kube-config.yaml中节点IP和VIP两个参数
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.1.10 # 当前节点地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.1.100:6444" #VIP
controllerManager: {
}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.15.1 # 注意
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # 注意
serviceSubnet: 10.96.0.0/12
scheduler: {
}
--- # 注意
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
导入keepalived-k8s和haproxy-k8s镜像
docker pull registry.cn-hangzhou.aliyuncs.com/shitou-aliyun/haproxy-k8s
docker pull registry.cn-hangzhou.aliyuncs.com/shitou-aliyun/haproxy-k8s
下载配置包
https://github.com/wise2c-devops/haproxy-k8s.git
https://github.com/wise2c-devops/keepalived-k8s.git
修改haproxy配置文件
vim haproxy.cfg
#配置文件信息....
backend be_k8s_6443
mode tcp
timeout queue 1h
timeout server 1h
timeout connect 1h
log global
balance roundrobin
server rancher01 192.168.100.10:6443 #节点IP
server rancher02 192.168.100.1:6443
修改启动脚本
vim start-haproxy.sh
#!/bin/bash
MasterIP1=192.168.100.10
MasterIP2=192.168.100.1
MasterPort=6443
docker run -d --restart=always --name HAProxy-K8S -p 6444:6444
-e MasterIP1=$MasterIP1
-e MasterIP2=$MasterIP2
-e MasterIP3=$MasterIP3
-e MasterPort=$MasterPort
-v /home/edjackson/kubernetes/good_master/data/lb/etc/haproxy.cfg
wise2c/haproxy-k8s
vim start-keepalived.sh
#!/bin/bash
VIRTUAL_IP=192.168.100.100 #VIP
INTERFACE=vboxnet0
NETMASK_BIT=24
CHECK_PORT=6444
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=Keepalived-K8S
--net=host --cap-add=NET_ADMIN
-e VIRTUAL_IP=$VIRTUAL_IP
-e INTERFACE=$INTERFACE
-e CHECK_PORT=$CHECK_PORT
-e RID=$RID
-e VRID=$VRID
-e NETMASK_BIT=$NETMASK_BIT
-e MCAST_GROUP=$MCAST_GROUP
wise2c/keepalived-k8s
启动执行
./start-haproxy.sh
./start-keepalived.sh
启动后查看网口是否挂载浮动地址
ip addr
初始化master
kubeadm init --config=kubernetes-config.yaml --experimental-upload-certs | tee kubeadm-init.log
添加master节点
安装成功后按照上述步骤安装另一台master主机,先安装haproxy和keepalived。在执行安装master时输入,
注意:此处和添加node节点不同,其他master节点也需进行搭建过程中的环境配置
kubeadm join 192.168.100.100:6444 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c3342da96a073e77fe4be9087f600518dd14bda91065021dcb76d94a2c5f654 --control-plane --certificate-key 3795ff83ce3e28aff0ae012c20eefb4ed003218ad3f8be7cd4dd58ccb798c527
直接添加master节点,添加成功后创建,kube/config并赋权,如果没有/etc/kubenternetes/admin.conf文件时可以在master主节点上拷贝一个即可
如果在主master重启之后想要加入master从节点,找不到join信息可以通过以下命令查找拼接即可
kubeadm token create --print-join-command
kubeadm init phase upload-certs --experimental-upload-certs
添加成功后kubectl get nodes 可以看到添加的master节点信息此时将.kube/config中的地址修改为本机地址。
参考链接
