【python--爬虫】百度图片爬虫
如何快速收集某个关键字的图片呢?有的小伙伴可能会说百度图片,bingo答对了!o( ̄▽ ̄)o,博主本次就讲解下如何爬取百度图片
环境准备
为了优雅的享用这盘python爬虫大餐,请各位读者大大准备要以下的内容哦!= ̄ω ̄=
一台可以上百度的win7或win10的电脑(32位64位的都可以)
火狐浏览器(版本没啥限制,最好用新一点的)
python(博主使用的python3.7)
requests库(版面没啥要求)
re库(这个是python自带的,不用准备)
最后还需要准备:点赞关注加评论(皮一下很开心o(▽)q)
网页分析
又,又,又到了我们分析网页的时间了,请各位聪明睿智的读者大大,耐心观看,学习下博主的思路,看看博主是如何从网页中找到自己想要的信息的。( ̄_ ̄ )一本正经的胡说八道中。。。
首先我们打开百度图片首页,页面如下:
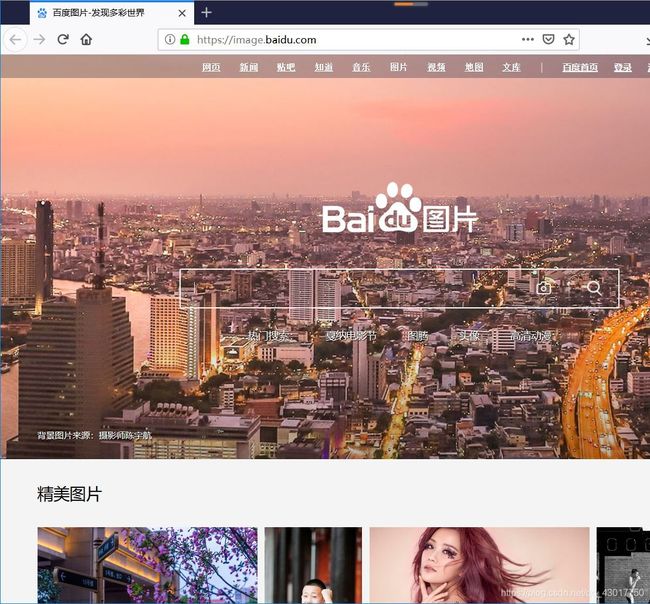 比如说我搜索【可爱的猫猫图片】,
比如说我搜索【可爱的猫猫图片】,
好可爱,看的我心都要化了 (❤ ω ❤),我们按下【F12】,打开开发者工具,看下浏览器发出了哪些请求!
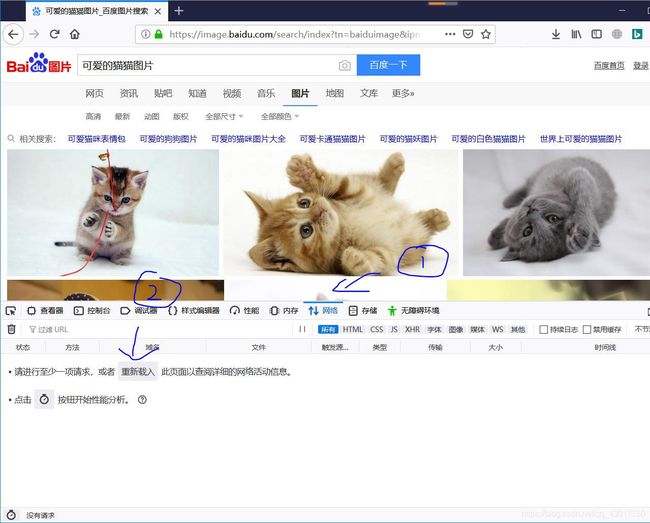 首先点击【网络】,然后点击【重新加载】刷新下网页。
首先点击【网络】,然后点击【重新加载】刷新下网页。
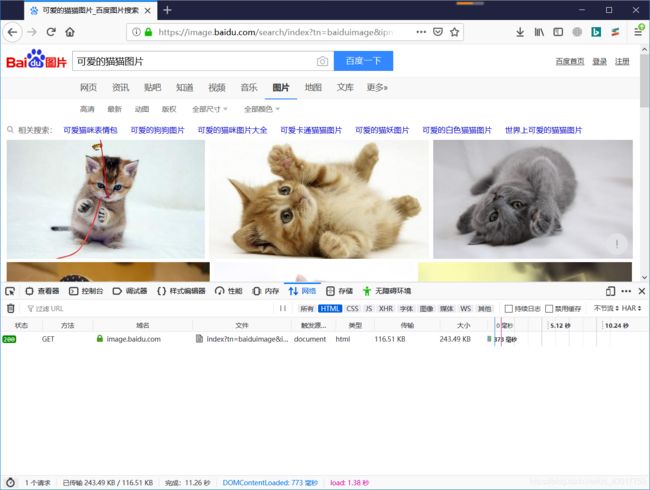 点击 html切换到网页源码请求栏中。点击第一个请求。
点击 html切换到网页源码请求栏中。点击第一个请求。
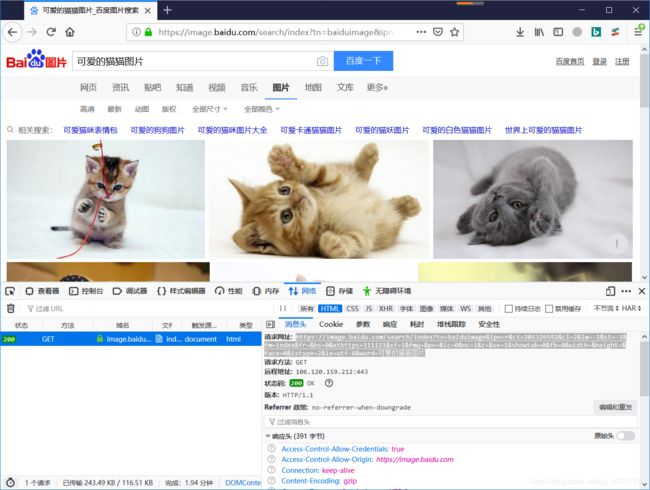 可以看到访问的网址是【https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的猫猫图片 】
可以看到访问的网址是【https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的猫猫图片 】
可以看到请求的网址的最后一个参数是【word=可爱的猫猫图片】
正好是我们搜索的关键字,不妨大胆的猜测下,是不是修改最后面【word=】的值,就可以搜索不同的内容呢!
比如说我要搜索 【可爱的狗狗图片】,得到如下的一个网址
【https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的狗狗图片 】
在浏览器中打开验证下!
成功的搜索到了狗狗的图片,证明我们的猜想是对的
通过修改【word=】的内容即可得到搜索对应的内容的网址。
现在返回猫猫网页。看看能不在网页源代码中找到图片的url
随便【右键】一张猫猫图片,在弹出的选项框中选择【查看元素】,即可条跳转到当前图片的代码
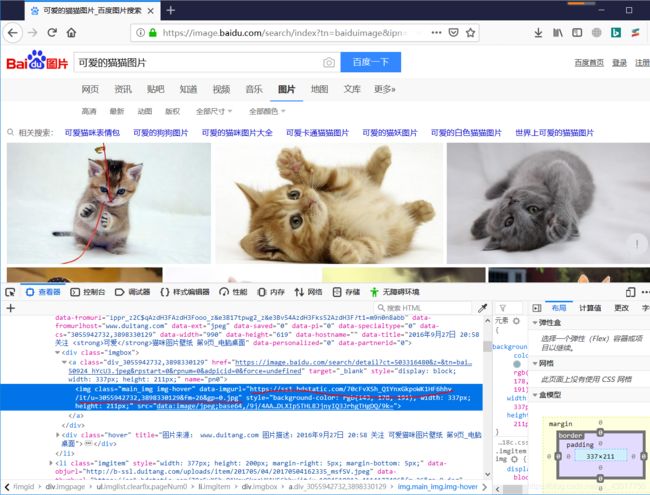 可以看到有着一个类似于图片网址的Url【https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=3055942732,3898330129&fm=26&gp=0.jpg 】我们使用浏览器打开该网址看看是不是就是我们要的那张图片
可以看到有着一个类似于图片网址的Url【https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=3055942732,3898330129&fm=26&gp=0.jpg 】我们使用浏览器打开该网址看看是不是就是我们要的那张图片
好棒,我们猜对了,就是我们要的图片。ヾ(≧▽≦*)o
我们在回到图片页面按【ctrl + U】即可调出 收到的基础网页源码。为啥我要说基础网页源码,(ps:这个名词可能不太准确§( ̄▽ ̄)§,各位看官请见谅),众所周知现在好多的网页为了加快访问速度,采取的方式是,我先将网页框架写出来,具体的数据,通过js脚本进行填充。所以就有可能出现,在网页中存在某个值,但是在网页的基础源码中找不到的问题。该解释可能说的不是那么准确,请各位大佬多多指点!
现在我们就去网页的源代码中查找下是否存在有这个值,打开网页的基础源代码后可以看到如下画面。
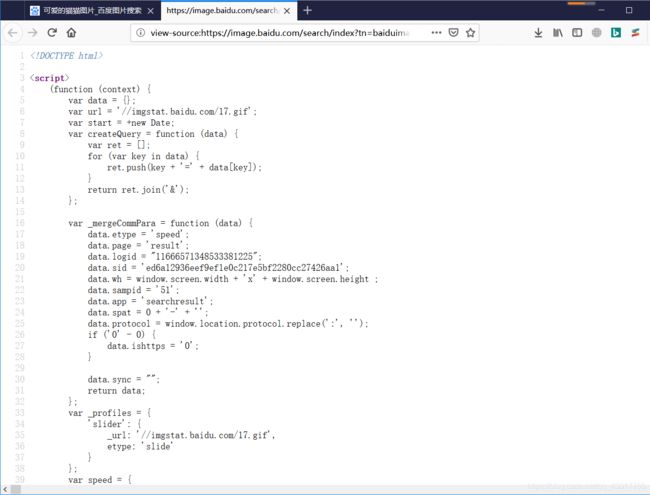
我们按【ctrl + F】即可调出查找对话框,将图片的前面我们找到的图片网址【https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=3055942732,3898330129&fm=26&gp=0.jpg 】输入其中进行查找,
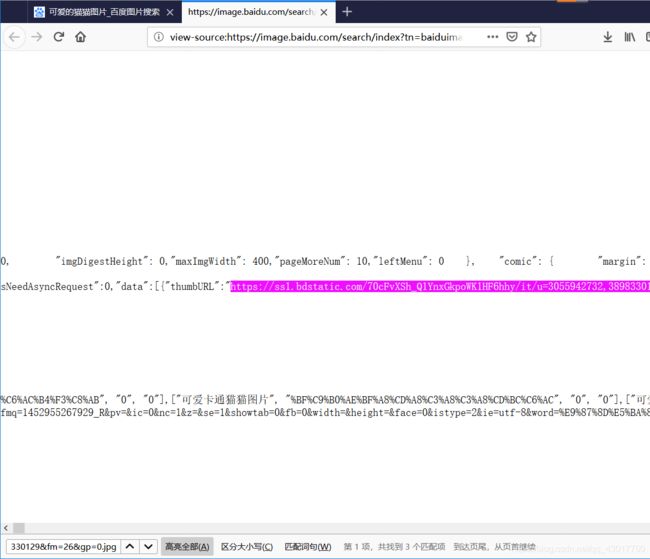 可以看到在网页基础源码中找到了图片的网址,但是位置不太对,再挂观察下url存在的位置,看看是包含在哪的!
可以看到在网页基础源码中找到了图片的网址,但是位置不太对,再挂观察下url存在的位置,看看是包含在哪的!
观察后可以看出图片url存在于字符串【“thumbURL”:"】和字符串【",“replaceUrl”】之间。现在图片的url我们也找到了存在的位置
分析总结
-
要搜索什么关键字的图片就将网址【https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的猫猫图片 】后面的【可爱的猫猫图片】替换成什么。就可以的到搜索页面的url。
-
图片的url存在于网页代码中字符串【“thumbURL”:"】和字符串【",“replaceUrl”】之间。
实战代码
- 设置前提参数
依旧是我们的老传统,设置默认编码,作者,编写时间
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月22日
第一行 # -- coding:utf-8 --的意思是:设置该程序运行时使用的编码格式为utf-8编码
第二行是设置作者是谁,可省略
第三行是设置编写时间,可省略
- 导入模块
导入我们后面要使用的模块
import requests
import re
requests库用于下载网页代码,和下载图片等。
re库 ,正则表达式,用于提取出来网页源码中我们想要的内容
- 设置变量
main_url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的猫猫图片'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Referer':'https://www.baidu.com',}
name = 0
这个main_url 指的是图片搜索页面的url,也就是【网页分析】中的第二张图片
header,存储的是浏览器头部信息。
header中User-Agent 存储的信息,相当于告诉服务器访问他的设备的信息,比如说,我的这个信息相当于告诉对方,我使用的是通过一台win10,64位的电脑的火狐浏览器访问的。至于这个Referer相当于告诉对方我是通过网址【https://www.baidu.com】跳转过来的。
至于这个name,是用于后期生成图片名称
- 下载网页
现在我们定义一个函数专门用于下载网页代码
def get_html(url):
'''下载网页'''
html = requests.get(url=url,headers=header).text
return html
我编写了一个名为get_html的函数专门用于下载网页代码,调用这个函数时需要传递进来一个网址作为参数。
函数中写着,使用requests库的get方法去下载网页代码,将函数调用时传递进来的Url作为get方法中请求的url的参数,将前面设置的header作为请求头的参数。将下载到的内容以文本的形式存储再变量html中,然后将变量html,也就时下载到的网页的源代码作为函数执行的结果弹出。
我们来看看执行效果:
html = get_html(main_url)
print (html)
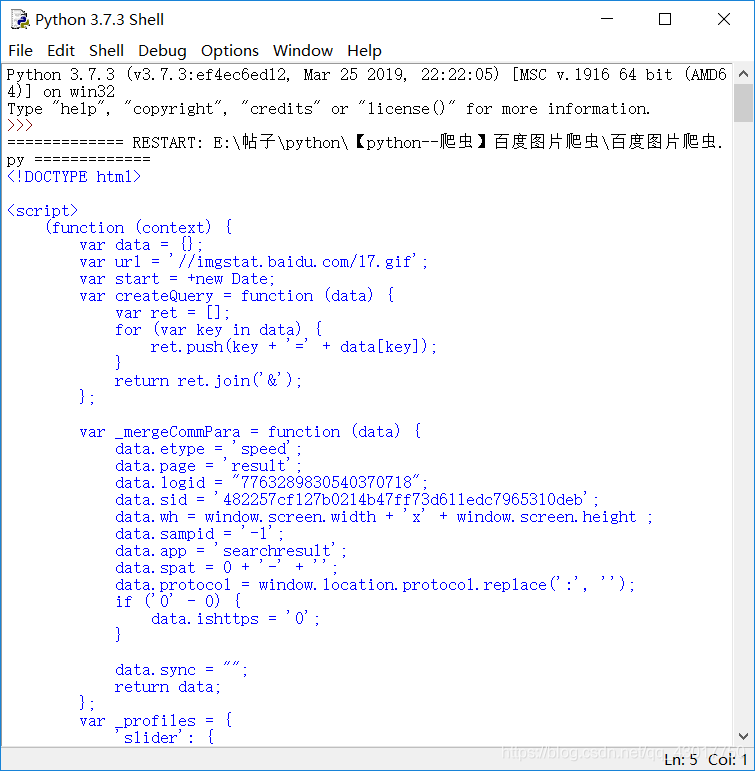 成功的将网页的源代码下载到了! (。・∀・)
成功的将网页的源代码下载到了! (。・∀・)
- 提取图片url
我们可以获取到网页的源代码了,还需要将图片的url提取出来。
def get_img_url(data):
'''匹配出图片的url'''
url_re = re.compile('"thumbURL":"(.*?)","replaceUrl"')
url_list = url_re.findall(data)
return url_list
这里我先创建了一个名为get_img_url的函数专门用于提取网页源码中图片的url,调用该函数时需要将网页的源代码作为参数传递进来,首先我先使用re.compile将【“thumbURL”:"(.*?)",“replaceUrl”】编译成正则表达式的格式,那么这个正则表达式匹配的格式是如何来的呢?我们在分析总结中提到了图片的存在于网页代码中字符串【“thumbURL”:"】和字符串【",“replaceUrl”】之间。那么这个(.*?)又是从哪来的呢?这个是正则表达式的一个匹配条件,采用的是非贪婪模式。具体的细节博主将会在后面出一篇专门讲正则表达式的帖子,各位读者只要知道我们爬取网页时写的最多的匹配条件就是这个。= ̄ω ̄= 博主这里先贴一张当初学正则时记录的笔记图片
 正如图中讲到的,
正如图中讲到的,url_re = re.compile('"thumbURL":"(.*?)","replaceUrl"')就是讲正则匹配的条件编译成正则的格式,然后使用url_list = url_re.findall(data)讲搜索到的所有内容存入 url_list中。最后使用return讲匹配到的url_list作为程序的执行结果弹出。
我们执行看下效果。
html = get_html(main_url)
url_list = get_img_url(html)
print (url_list)
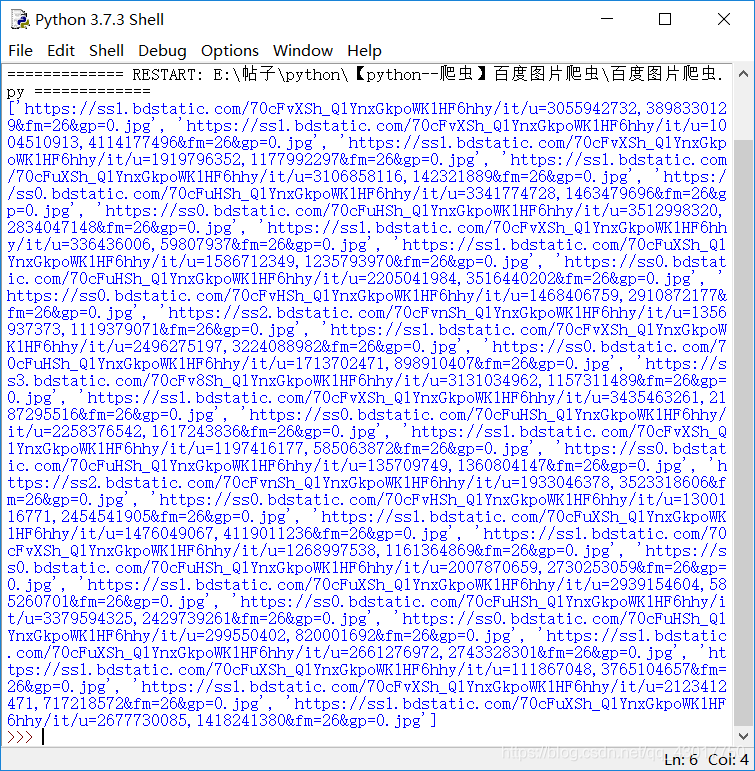 可以看到我们将图片的url都提取出来了。比如说我复制第一个url,在浏览器打开验证下【https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=3055942732,3898330129&fm=26&gp=0.jpg 】
可以看到我们将图片的url都提取出来了。比如说我复制第一个url,在浏览器打开验证下【https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=3055942732,3898330129&fm=26&gp=0.jpg 】
是我们需要爬取的图片 现在图片的url 也有了,就差下载保存了。感觉自己棒棒的( ̄︶ ̄)。
- 下载图片
我们还需要在python程序所在的目录中创建一个名为【picture】的文件夹专门用于保存图片
def get_img(url):
'''下载并保存图片'''
global name
name += 1
file_name = 'picture\\{}.jpg'.format(name)
img = requests.get(url=url,headers=header).content
with open(file_name,'wb') as save_img:
save_img.write(img)
首先我定义了一个名为get_img的函数用于下载并保存图片,调用该函数时需要传递一个图片的url作为参数。global name的作用是啥呢?相当于设置这个函数可以修改全局变量name的值。name +=1 的作用是每次执行函数就将name的值增加一。 file_name = 'picture\\{}.jpg'.format(name)设置图片保存的名称。img = requests.get(url=url,headers=header).content使用requests库的get方法下载图片,将函数调用时传递进来的图片url作为请求的url,将前面设置的header作为请求头,将下载到的数据以二进制的形式保存在变量img中。
with open(file_name,'wb') as save_img:
save_img.write(img)
将下载的图片二进制数据保存下来
我们执行后看下效果
html = get_html(main_url)
url_list = get_img_url(html)
for url in url_list:
get_img(url)
print ("正在下载第{}张图片".format(name))
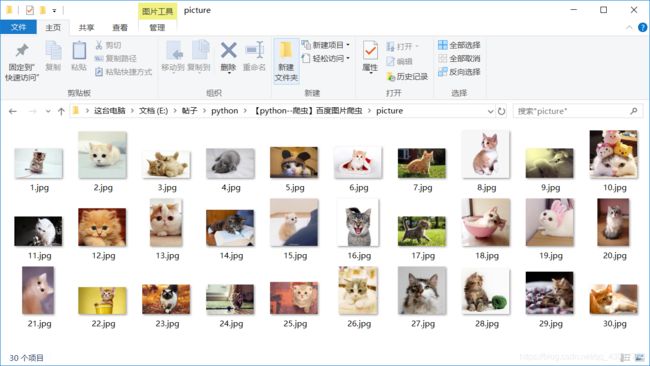
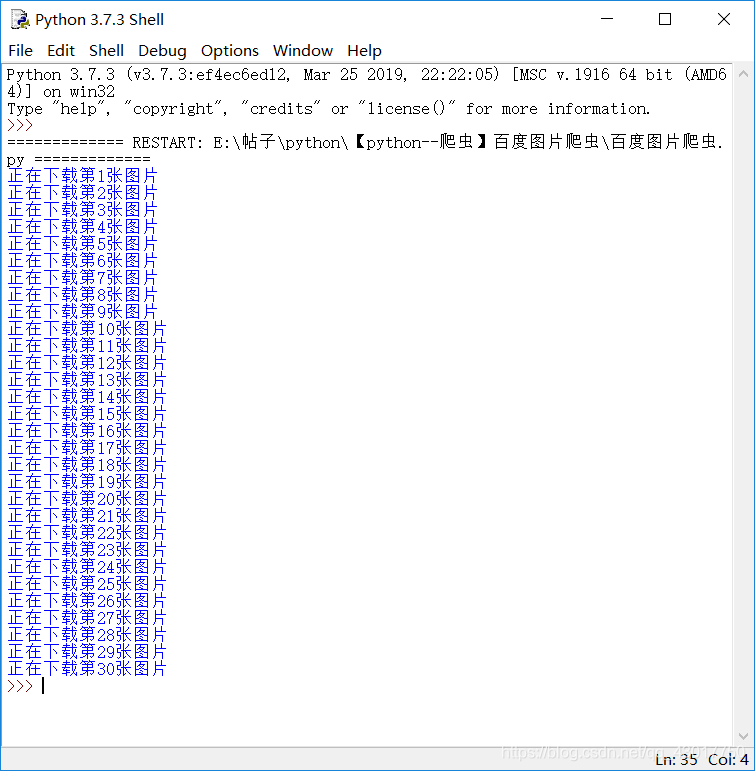 可以看到下载了30张图片
可以看到下载了30张图片
完整代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月22日
import requests
import re
main_url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=可爱的猫猫图片'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Referer':'https://www.baidu.com',}
name = 0
def get_html(url):
'''下载网页'''
html = requests.get(url=url,headers=header).text
return html
def get_img_url(data):
'''匹配出图片的url'''
url_re = re.compile('"thumbURL":"(.*?)","replaceUrl"')
url_list = url_re.findall(data)
return url_list
def get_img(url):
'''下载并保存图片'''
global name
name += 1
file_name = 'picture\\{}.jpg'.format(name)
img = requests.get(url=url,headers=header).content
with open(file_name,'wb') as save_img:
save_img.write(img)
html = get_html(main_url)
url_list = get_img_url(html)
for url in url_list:
get_img(url)
print ("正在下载第{}张图片".format(name))