Python 基础 之 多任务 yield/greenlet/gevent 协程知识点的简单整理,以及对应的使用(迭代器、协程、进程线程和协程的区别等)

Python 基础 之 多任务 yield/greenlet/gevent 协程知识点的简单整理,以及对应的使用(迭代器、协程、进程线程和协程的区别等)
目录
Python 基础 之 多任务 yield/greenlet/gevent 协程知识点的简单整理,以及对应的使用(迭代器、协程、进程线程和协程的区别等)
一、简单介绍
二、可迭代、迭代器、生成器、yield、greenlet、gevent、进程线程和协程的区别的相关概念
1、整理协程之前,我们先了解一下什么是可迭代,迭代器是什么
2、迭代器
3、生成器
4、协程
5、协程和线程差异
6、greenlet
7、gevent
8、进程、线程、协程对比
三、判断是否可迭代,创建自己的可迭代对象 class
四、判断是否是迭代器,创建自己的迭代器class
五、优化创建自定义的迭代器
六、生成器(斐波那契数列)
七、协程 yield 的使用
八、协程 greenlet 的使用
九、协程 gevent 的使用
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet 开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
本节简单介绍,简单的整理一下 python 中多任务 yield/greenlet/gevent 协程的一些知识点,和简单的案例说明。
二、可迭代、迭代器、生成器、yield、greenlet、gevent、进程线程和协程的区别的相关概念
1、整理协程之前,我们先了解一下什么是可迭代,迭代器是什么
1)可迭代对象
我们已经知道可以对list、tuple、str等类型的数据使用for...in...的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代
2)如何判断一个对象是否可以迭代
可以使用 isinstance() 判断一个对象是否是 Iterable 对象。
3)可迭代对象的本质
我们分析对可迭代对象进行迭代使用的过程,发现每迭代一次(即在for...in...中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)。
可迭代对象的本质就是可以向我们提供一个这样的中间“人”即迭代器帮助我们对其进行迭代遍历使用。
可迭代对象通过__iter__方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据.
那么也就是说,一个具备了__iter__方法的对象,就是一个可迭代对象。
4)iter()函数与next()函数
list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。iter()函数实际上就是调用了可迭代对象的__iter__方法。
注意,当我们已经迭代完最后一个数据之后,再次调用next()函数会抛出StopIteration的异常,来告诉我们所有数据都已迭代完成,不用再执行next()函数了。
并不是只有for循环能接收可迭代对象
除了for循环能接收可迭代对象,list、tuple等也能接收。
li = list(FibIterator(15))
print(li)
tp = tuple(FibIterator(6))
print(tp)
2、迭代器
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
1)如何判断一个对象是否是迭代器
可以使用 isinstance() 判断一个对象是否是 Iterator 对象。
2)迭代器Iterator
通过上面的分析,我们已经知道,迭代器是用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法(Python3中是对象的__next__方法,Python2中是对象的next()方法)。所以,我们要想构造一个迭代器,就要实现它的__next__方法。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
3)for...in...循环的本质
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
3、生成器
1) 生成器 (生成器是一类特殊的迭代器。)
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器。
在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是函数,而是一个生成器了。简单来说:只要在def中有yield关键字的 就称为 生成器
2)总结
使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器);
yield关键字有两点作用:
-
保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
-
将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数);
Python3中的生成器可以使用return返回最终运行的返回值,而Python2中的生成器不允许使用return返回一个返回值(即可以使用return从生成器中退出,但return后不能有任何表达式);
3)使用send唤醒
我们除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
4、协程
协程,又称微线程,纤程。英文名Coroutine。
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
5、协程和线程差异
在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。 所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
6、greenlet
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
7、gevent
greenlet已经实现了协程,但是这个还的人工切换,是不是觉得太麻烦了,不要捉急,python还有一个比greenlet更强大的并且能够自动切换任务的模块gevent
其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
# 有耗时操作时需要
monkey.patch_all() # 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
8、进程、线程、协程对比
请仔细理解如下的通俗描述:
1)有一个老板想要开个工厂进行生产某件商品(例如剪子)
2)他需要花一些财力物力制作一条生产线,这个生产线上有很多的器件以及材料这些所有的 为了能够生产剪子而准备的资源称之为:进程
3)只有生产线是不能够进行生产的,所以老板的找个工人来进行生产,这个工人能够利用这些材料最终一步步的将剪子做出来,这个来做事情的工人称之为:线程
4)这个老板为了提高生产率,想到3种办法:
-
在这条生产线上多招些工人,一起来做剪子,这样效率是成倍増长,即单进程 多线程方式
-
老板发现这条生产线上的工人不是越多越好,因为一条生产线的资源以及材料毕竟有限,所以老板又花了些财力物力购置了另外一条生产线,然后再招些工人这样效率又再一步提高了,即多进程 多线程方式
-
老板发现,现在已经有了很多条生产线,并且每条生产线上已经有很多工人了(即程序是多进程的,每个进程中又有多个线程),为了再次提高效率,老板想了个损招,规定:如果某个员工在上班时临时没事或者再等待某些条件(比如等待另一个工人生产完谋道工序 之后他才能再次工作) ,那么这个员工就利用这个时间去做其它的事情,那么也就是说:如果一个线程等待某些条件,可以充分利用这个时间去做其它事情,其实这就是:协程方式
简单总结:
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
三、判断是否可迭代,创建自己的可迭代对象 class
我们已经知道可以对list、tuple、str等类型的数据使用for...in...的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代
1)如何判断一个对象是否可以迭代
可以使用 isinstance() 判断一个对象是否是 Iterable 对象。
2)可迭代对象的本质
我们分析对可迭代对象进行迭代使用的过程,发现每迭代一次(即在for...in...中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)。
可迭代对象的本质就是可以向我们提供一个这样的中间“人”即迭代器帮助我们对其进行迭代遍历使用。
可迭代对象通过
__iter__方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据.那么也就是说,一个具备了
__iter__方法的对象,就是一个可迭代对象。
3)iter()函数与next()函数
list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。iter()函数实际上就是调用了可迭代对象的
__iter__方法。注意,当我们已经迭代完最后一个数据之后,再次调用next()函数会抛出StopIteration的异常,来告诉我们所有数据都已迭代完成,不用再执行next()函数了。
并不是只有for循环能接收可迭代对象
除了for循环能接收可迭代对象,list、tuple等也能接收。
效果:判断[]、{}、字符串、数是否可迭代,并创建自定义的可迭代对象class
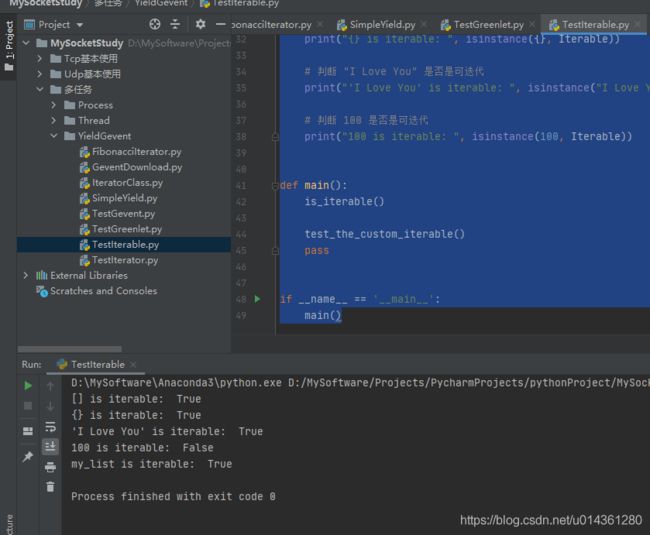
代码:
from collections.abc import Iterable
class TheCustomIterable(object):
"""创建自定义可迭代的对象class"""
def __init__(self):
self.my_list = []
def append(self, item):
self.my_list.append(item)
# 这个是可迭代的关键,去掉就不可迭代了哦
def __iter__(self):
"""返回一个迭代器"""
# 不是本次介绍内容,暂且忽略
pass
def test_the_custom_iterable():
my_list = TheCustomIterable()
# 判断 my_list 是否是可迭代
print("my_list is iterable: ", isinstance(my_list, Iterable))
def is_iterable():
# 判断 [] 是否是可迭代
print("[] is iterable: ", isinstance([], Iterable))
# 判断 {} 是否是可迭代
print("{} is iterable: ", isinstance({}, Iterable))
# 判断 "I Love You" 是否是可迭代
print("'I Love You' is iterable: ", isinstance("I Love You", Iterable))
# 判断 100 是否是可迭代
print("100 is iterable: ", isinstance(100, Iterable))
def main():
is_iterable()
test_the_custom_iterable()
pass
if __name__ == '__main__':
main()
四、判断是否是迭代器,创建自己的迭代器class
迭代器:
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
1)如何判断一个对象是否是迭代器
可以使用 isinstance() 判断一个对象是否是 Iterator 对象。
2)迭代器Iterator
通过上面的分析,我们已经知道,迭代器是用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。实际上,在使用next()函数的时候,调用的就是迭代器对象的
__next__方法(Python3中是对象的__next__方法,Python2中是对象的next()方法)。所以,我们要想构造一个迭代器,就要实现它的__next__方法。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。3)for...in...循环的本质
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
效果:判断[]、{}、字符串、数是否是迭代器,并自定义实现迭代器
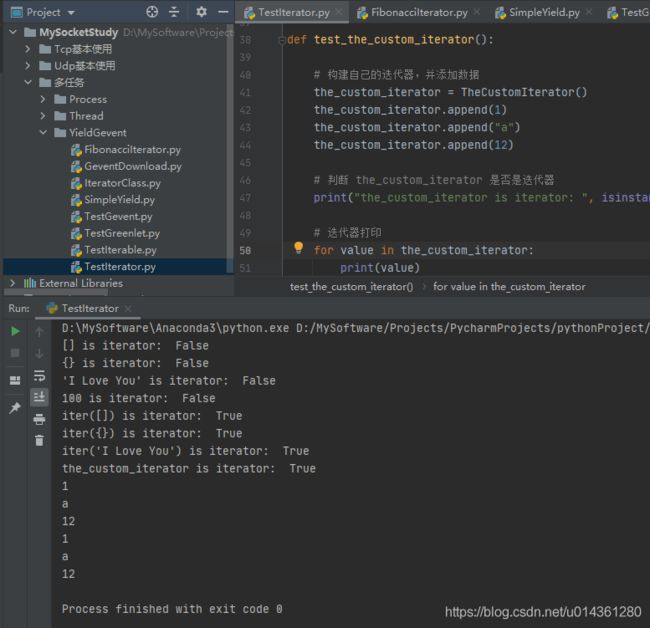
代码:
from collections.abc import Iterator
class TheCustomIterator(object):
"""自定义一个迭代器"""
def __init__(self):
self.my_list = []
def append(self, item):
self.my_list.append(item)
def __iter__(self):
my_iterator = MyIterator(self)
return my_iterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, the_custom_iterator):
self.the_custom_iterator = the_custom_iterator
# 标记当前访问的位置
self.current_index = 0
def __next__(self):
# 访问下一个
if self.current_index < len(self.the_custom_iterator.my_list):
item = self.the_custom_iterator.my_list[self.current_index]
self.current_index += 1
return item
else: # 这里是访问结束,退出,记住要有
raise StopIteration
def __iter__(self):
return self
def test_the_custom_iterator():
# 构建自己的迭代器,并添加数据
the_custom_iterator = TheCustomIterator()
the_custom_iterator.append(1)
the_custom_iterator.append("a")
the_custom_iterator.append(12)
# 判断 the_custom_iterator 是否是迭代器
print("the_custom_iterator is iterator: ", isinstance(iter(the_custom_iterator), Iterator))
# 迭代器打印
for value in the_custom_iterator:
print(value)
# 迭代器打印
for value in the_custom_iterator:
print(value)
def is_iterator():
# 判断 [] 是否是迭代器
print("[] is iterator: ", isinstance([], Iterator))
# 判断 {} 是否是迭代器
print("{} is iterator: ", isinstance({}, Iterator))
# 判断 "I Love You" 是否是迭代器
print("'I Love You' is iterator: ", isinstance("I Love You", Iterator))
# 判断 100 是否是迭代器
print("100 is iterator: ", isinstance(100, Iterator))
# 判断 iter([]) 是否是迭代器
print("iter([]) is iterator: ", isinstance(iter([]), Iterator))
# 判断 iter({}) 是否是迭代器
print("iter({}) is iterator: ", isinstance(iter({}), Iterator))
# 判断 iter("I Love You") 是否是迭代器
print("iter('I Love You') is iterator: ", isinstance(iter("I Love You"), Iterator))
def main():
is_iterator()
test_the_custom_iterator()
if __name__ == '__main__':
main()
五、优化创建自定义的迭代器
效果:把之前实现先的两个 class 迭代器,合并为一个 class 的迭代器
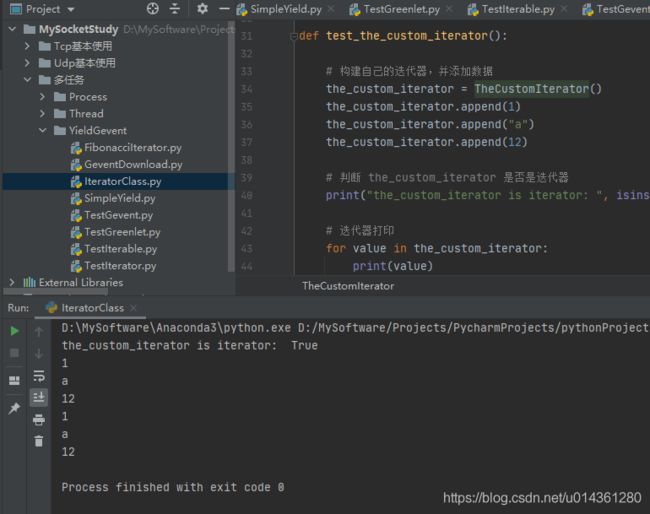
代码:
from collections.abc import Iterator
class TheCustomIterator(object):
"""自定义整合两个 class 的迭代器"""
def __init__(self):
self.my_list = []
# 标记当前访问的位置
self.current_index = 0
def append(self, item):
self.my_list.append(item)
def __next__(self):
# 访问下一个
if self.current_index < len(self.my_list):
item = self.my_list[self.current_index]
self.current_index += 1
return item
else: # 这里是访问结束,退出,记住要有
# 标记当前访问的位置 重新置为 0
self.current_index = 0
raise StopIteration
def __iter__(self):
return self
def test_the_custom_iterator():
# 构建自己的迭代器,并添加数据
the_custom_iterator = TheCustomIterator()
the_custom_iterator.append(1)
the_custom_iterator.append("a")
the_custom_iterator.append(12)
# 判断 the_custom_iterator 是否是迭代器
print("the_custom_iterator is iterator: ", isinstance(iter(the_custom_iterator), Iterator))
# 迭代器打印
for value in the_custom_iterator:
print(value)
# 迭代器打印
for value in the_custom_iterator:
print(value)
def main():
test_the_custom_iterator()
if __name__ == '__main__':
main()
六、生成器(斐波那契数列)
生成器 (生成器是一类特殊的迭代器):
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器。
效果:实现一个斐波那契数列迭代器
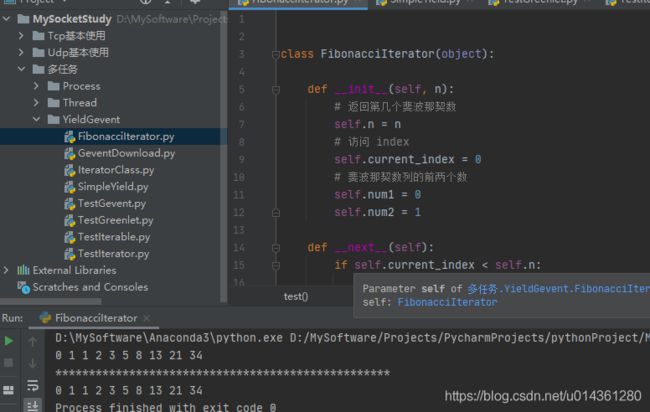
代码:
class FibonacciIterator(object):
def __init__(self, n):
# 返回第几个斐波那契数
self.n = n
# 访问 index
self.current_index = 0
# 斐波那契数列的前两个数
self.num1 = 0
self.num2 = 1
def __next__(self):
if self.current_index < self.n:
num = self.num1
self.num1, self.num2 = self.num2, self.num1+self.num2
self.current_index += 1
return num
else: # 这里是访问结束,退出,记住要有
# 重置 当前访问坐标
self.current_index = 0
# 重置 斐波那契数列的前两个数
self.num1 = 0
self.num2 = 1
raise StopIteration
def __iter__(self):
"""迭代器返回自身即可"""
return self
def test():
fibonacci_iterator = FibonacciIterator(10)
for num in fibonacci_iterator:
print(num, end=" ")
print()
print("*"*50)
for num in fibonacci_iterator:
print(num, end=" ")
def main():
test()
if __name__ == '__main__':
main()
七、协程 yield 的使用
协程:
协程,又称微线程,纤程。英文名Coroutine。
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
效果:yield 协程多任务的实现
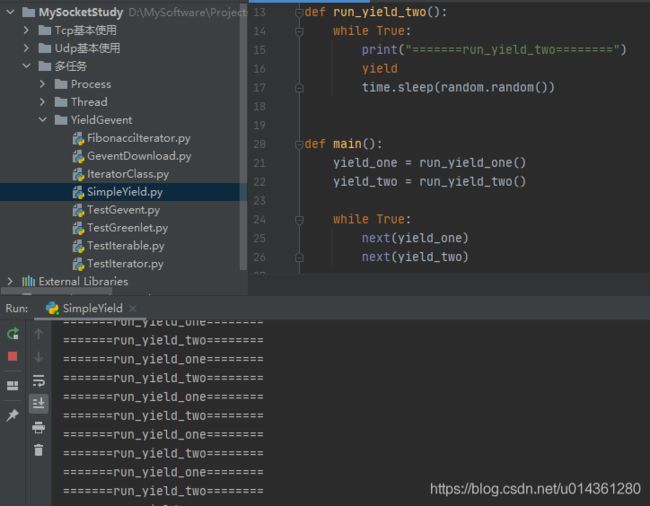
代码:
import time, random
def run_yield_one():
while True:
print("=======run_yield_one========")
yield
time.sleep(random.random())
def run_yield_two():
while True:
print("=======run_yield_two========")
yield
time.sleep(random.random())
def main():
yield_one = run_yield_one()
yield_two = run_yield_two()
while True:
next(yield_one)
next(yield_two)
pass
if __name__ == '__main__':
main()
八、协程 greenlet 的使用
greenlet:
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单。
效果:greenlet 协程多任务的实现
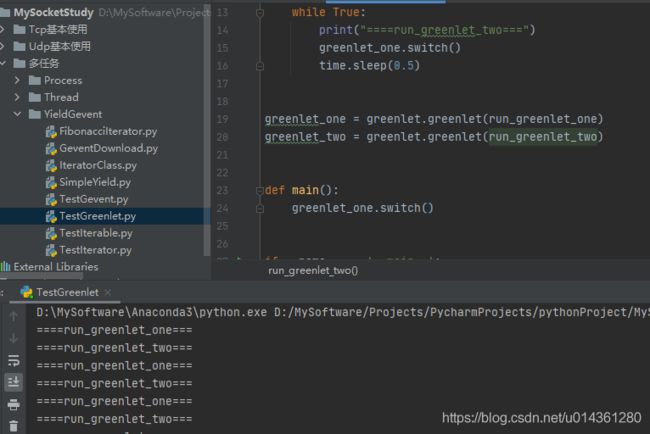
代码:
import greenlet,time
def run_greenlet_one():
while True:
print("====run_greenlet_one===")
greenlet_two.switch()
time.sleep(0.5)
def run_greenlet_two():
while True:
print("====run_greenlet_two===")
greenlet_one.switch()
time.sleep(0.5)
greenlet_one = greenlet.greenlet(run_greenlet_one)
greenlet_two = greenlet.greenlet(run_greenlet_two)
def main():
greenlet_one.switch()
if __name__ == '__main__':
main()
九、协程 gevent 的使用
gevent:
greenlet 已经实现了协程,但是这个还的人工切换,是不是觉得太麻烦了,不要捉急,python还有一个比greenlet更强大的并且能够自动切换任务的模块
gevent;其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行;
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO;
# 有耗时操作时需要 monkey.patch_all() # 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
效果:gevent 协程多任务的实现
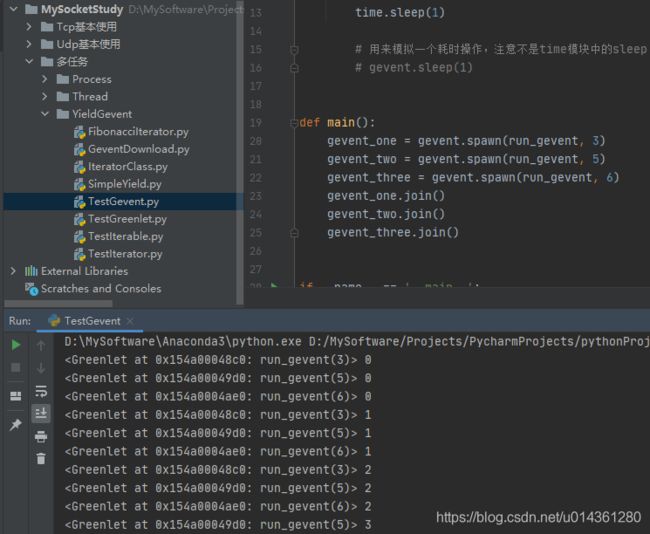
代码:
import time
import gevent
from gevent import monkey
# 有耗时操作时需要
monkey.patch_all() # 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
def run_gevent(num):
for value in range(num):
print(gevent.getcurrent(), value)
# 耗时操作
time.sleep(1)
# 用来模拟一个耗时操作,注意不是time模块中的sleep
# gevent.sleep(1)
def main():
gevent_one = gevent.spawn(run_gevent, 3)
gevent_two = gevent.spawn(run_gevent, 5)
gevent_three = gevent.spawn(run_gevent, 6)
gevent_one.join()
gevent_two.join()
gevent_three.join()
if __name__ == '__main__':
main()