NodeJS笔记
一、NodeJS概述
1、介绍
相关网址:
-
https://nodejs.org/zh-cn/
-
http://nodejs.cn/
Node.js 是一个开源与跨平台的JavaScript运行时环境。它是在浏览器外运行,它是一个事件驱动异步I/O单进程的服务端JS环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
注意:
-
浏览器是JS的前端运行环境。
-
Node.js是JS的后端运行环境,在后端中运行无法调用
DOM 和 BOM 等浏览器内置 API。
2、NodeJS应用场景
-
创建应用服务
-
web开发(后端)
-
接口开发(小程序)
-
客户端应用工具如webpack、vue脚手架、react脚手架、小程序等
3、模块化
NodeJs基于Commonjs模块化开发的规范,它定义一个JS文件就称之为一个模块。模块化是以后开发的主流形式(在vue、react中也存在:组件化)
模块化讲究的是分解。(可以理解为,原本一个项目就10个文件,将其改写成一个项目100个文件)
node的模块类型:
-
核心(内置)模块 - 安装nodejs自带的模块
-
第三方模块 - 需要手动通过(npm/yarn)来进行安装
-
自定义模块 - 开发者自己编写开发
// 导出(一般是需要写的)
// 当前文件已经将需要声明的方法全部定义完毕,在文件最后需要使用,将文件中的方法或属性暴露给其它模块(文件)使用
module.exports / exports
// 导入(可选环节)
// 当本文件中需要使用其它模块提供的方法和属性的时候就需要导入
require("module_name")
4、NodeJS安装
nodejs环境安装非常便捷,直接可通过官网地址,下载对应的安装软件包即可安装使用。
注:
尽量下载长期支持版本(LTS,有些软件是Release),如果在工作中有多个node环境的切换,可以安装ndoe环境管理工具NVM:https://github.com/coreybutler/nvm-windows/releasesnvm可以让你的电脑中有N多个node版本。
node8 A项目 B项目 node9 C项目 node10
二、NodeJS快速入门
1、运行JS文件
检查node是否安装成功:
node -v
如果需要让node运行JavaScript文件,则按照以下语法执行(该操作需要在cmd/命令行/终端/小黑窗中运行):
node JS文件路径
# 路径可以使用相对路径也可以是绝对路径,但是一定要确保通过路径能够正常的找到对应的文件
# 相对路径一般以“./”,“../”、“直接写名字”
# 绝对路径
# 以盘符开头(windwos系统)
# 以“/”开头(除windows系统),“/”称之为根目录
例如:

2、 全局变量
-
global:全局变量的宿主(类似于浏览器js中的window对象),这是一个特殊的对象,称为全局对象(Global Object),它及其所有属性都可以在程序的任何地方访问
-
__filename:当前正在执行的脚本的文件名(完整/绝对路径)
-
__dirname:当前执行脚本所在的目录路径(目录的绝对路径)
console.log(global);
console.log(__filename);
console.log(__dirname);
3、常用内置模块
更多内置模块及常用内置模块的更多API用法,可以参考:http://nodejs.cn/api/
3.1、os模块
os(operation system)模块提供了与操作系统相关的实用方法和属性。
const os = require('os')
// 换行符
os.EOL //根据操作系统生成对应的换行符 window \r\n,linux下面 \n
// cpu相关信息
os.cpus()
// 总内存大小 (单位 字节)
os.totalmem()
// 空余内存大小 (单位 字节)
os.freemem()
// 主机名
os.hostname()
// 系统类型
os.type()
// ...
3.2、path模块
path模块用于处理文件和目录(文件夹)的路径。
const path = require('path')
// 获取路径最后一部内容,一般用它来获取文件名称
path.basename('c:/a/b/c/d.html') // d.html
// 获取目录名,路径最后分隔符部分被忽略
path.dirname('c:/a/b/c/d.html') // c:/a/b/c
// 获取路径中文件扩展名(后缀)
path.extname('c:/a/b/c/d.html') // .html
// 给定的路径连接在一起
path.join('/a', 'b', 'c') // /a/b/c
// resolve:模拟cd(切换目录)操作同时拼接路径
console.log(path.resolve("a", "b", "c"));
console.log(path.resolve("a", "../b", "c"));
console.log(path.resolve("/a", "b", "c"));
// ...
3.3、url模块
URL字符串是结构化的字符串,包含多个含义不同的组成部分。 解析字符串后返回的 URL 对象,每个属性对应字符串的各个组成部分。

const url = require('url');
const href = 'http://www.xxx.com:8080/pathname?id=100#bbb'
// 解析网址,返回Url对象
// 参2 如果为true 则 query获取得到的为对象形式
url.parse(href,true)
//以一种 Web 浏览器解析超链接的方式把一个目标 URL 解析成相对于一个基础 URL。
url.resolve('https://lynnn.cn/foo/bar','bar')
注意:url模块中没有join方法。
3.4、querystring模块
用于解析和格式化 URL 查询字符串(URL地址的get形式传参)的实用工具。
const querystring = require('querystring')
// query字符串转为对象
querystring.parse('foo=bar&abc=xyz')
querystring.decode('foo=bar&abc=xyz')
// 对象转为query字符串
querystring.stringify({
foo: 'bar',abc: 'xyz'})
querystring.encode({
foo: 'bar',abc: 'xyz'})
3.5、fs模块
fs(file system)模块提供了用于与文件进行交互相关方法。
注意:fs模块提供了2大类api方法
- 同步操作
- 异步操作
后续写代码的时候有2个方案,一个是使用之前套娃式的写法,二是使用同步的api去实现操作。
const fs = require('fs')
// 写入数据(覆盖),追加写使用fs.appendFile
fs.writeFile(文件路径,待写入的数据,err => {
})
// 读取文件中数据
fs.readFile(文件路径, 'utf8’,(err,data) => {
})
// (同步)检查文件是否存在 返回true/false
// async:异步
// sync:同步
let ret = fs.existsSync(path)
// 获取文件信息(异步)
fs.stat(文件,(err,stats) => {
stats.isDirectory() // 是否是目录
stats.isFile() // 是否为文件
stats.size // 文件大小(以字节为单位)
})
// 删除文件(异步)
fs.unlink(文件路径,err => {
})
// 友情提醒:fs模块有点小坑
// 关于相对路径,在fs模块中,读写文件都会使用文件的路径,如果是相对路径则相对路径相对于谁?
// 答案:不会是相对于当前的js文件,而是相对于node命令执行的位置(即命令行的工作路径)。以后再用fs的时候建议文件的路径采用__dirname与文件名做拼接的方式来写文件名。
3.6、http模块
在讲解该模块时,我们需要了解web服务器的相关内容。
3.6.1、介绍
Web服务器一般指的是网站服务器(服务器:给用户提供服务的机器就是服务器),是指驻留因特网上某一台或N台计算机的程序,可以处理浏览器等Web客户端的请求并返回相应响应,在服务器上还需要安装服务器软件,目前最主流的三个Web服务器软件是Apache、 Nginx 、IIS。

整理文档(面试题):用户从浏览器打开页面到最终页面呈现在屏幕上,经历了哪些事?
3.6.2、两种开发模式
- 传统开发也叫前后端耦合开发(以前)
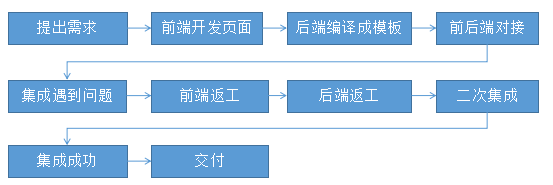
- 前后端分离开发(现在)

3.6.3、服务器相关概念
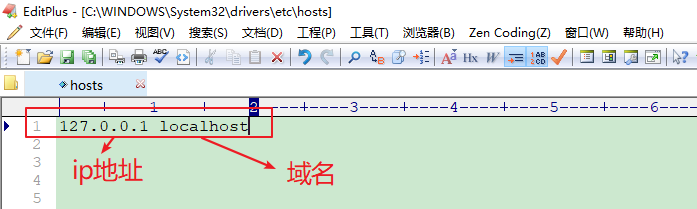
- ip地址或域名
ip地址:ip地址有v4和v6之分,IP地址就是互联网上每台计算机/电子设备的唯一地址,因此IP地址具有唯一性。在开发期间,自己的电脑既是一台服务器,也是一个客户端,可以在本机浏览器中输入127.0.0.1进行访问。
域名:尽管 IP地址能够唯一地标记网络上的计算机,但IP地址是一长串数字,不直观,而且不便于记忆,于是人们又发明了另一套字符型的地址方案,叫域名地址。IP地址和域名是一一对应的关系,这份对应关系存放在一种叫做域名服务器(DNS)的电脑中。在开发测试期间,127.0.0.1 对应的域名是 localhost。
域名与ip地址之间有一个转化过程的,是由DNS服务器完成域名转化的。
本地如果localhost无法使用,则是因为本机中的hosts文件中没有匹配上ip地址
- 网络协议
网络上的计算机之间交换信息,就像我们说话用某种语言一样,在网络上的各台计算机之间也有一种语言,这就是网络协议,不同的计算机之间必须使用相同的网络协议才能进行通信。如:TCP、UDP、HTTP、FTP等等。
- 端口号
服务器的端口号就像是现实生活中的门牌号一样。通过门牌号,外卖员就可以准确把外卖送到你的手中。同样的道理,在一台电脑中,可以运行N多个web 服务。每个 web 服务都对应一个唯一的端口号(0-65535,2^16,常见的端口号别占用:20,21,22,25,80,443,3306,3389,11211,27017…)。客户端发送过来的网络请求,通过端口号,可以被准确地交给对应的 web 服务进行处理。0-65535
注:服务器上的端口号是不可以重复的,必须是独一无二。http服务默认端口号为80,https的端口号默认是443。
2^16-1=65535
3.6.4、创建web服务器
NodeJs是通过官方提供的http模块来创建 web服务器的模块。通过几行简单的代码,就能轻松的手写一个web服务,从而对外提供 web 服务。
// 导入http模块
const http = require('http')
// 创建web服务对象实例
const server = http.createServer()
// 绑定监听客户端请求事件request
server.on('request', (request, response) => {
})
// request: 接受客户端请求对象,它包含了与客户端相关的数据和属性
// request.url 客户端请求的uri地址
// request.method 客户端请求的方式 get或post
// request.headers 客户端请求头信息(对象)
// ....
// response:服务器对客户端的响应对象
// 设置响应头信息 ,用于响应时有中文时乱码解决处理
// response.setHeader('content-type', 'text/html;charset=utf-8')
// 设置状态码(常见的HTTP状态码有:200,404,301、302、304、403、401、405、500,502)
// response.statusCode = 200
// 向客户端发送响应数据,并结束本次请求的处理过程
// response.end('hello world')
// 启动服务
server.listen(8080, () => {
console.log('服务已启动')
})
案例:手写一个服务器软件,启动后要求用户访问根“/”输出hello world,用户访问/html5输出2021。
// 1. 导入http模块
const http = require("http");
// 2. 创建web服务实例
const server = http.createServer();
// 3. 监听request请求
server.on("request", (req, res) => {
// 输出hello world
// res.end("hello world");
if (req.url === "/") {
res.end("hello world");
}
if (req.url === "/html5") {
res.end("2021");
}
});
// 4. 启动服务
server.listen(8080, () => {
// 仅是提示作用,可以不写,但是建议写
console.log("server is running at http://127.0.0.1:8080");
});
3.5.5、静态资源服务器
静态资源:常见的有html、css、js、图片、音频、视频等。特征:其展示的效果要想变化必须要更改文件的内容。
静态资源服务器:专门保存上述静态资源的服务器,称之为静态资源服务器。
- 实现思路
客户端请求的每个资源uri地址,作为在本机服务器指定目录中的文件。通过相关模块进行读取文件中数据进行响应给客户端,从而实现静态服务器。

- 实现步骤
需求:使用nodejs的http模块创建静态资源服务器,专门存放静态资源展示2张图片
// 创建服务器有以下几步:
// a. 导入
const http = require("http");
const path = require("path");
const fs = require("fs");
// b. 创建web实例
const server = http.createServer();
// c. 监听request事件
server.on("request", (req, res) => {
// 获取当前用户访问的资源路径
let uri = req.url;
// 由于“/”没有实体资源,需要将“/”做处理,如果访问“/”则让其对应访问“/index.html”
if (uri == "/") {
uri = "/index.html";
}
// 默认情况下,浏览器在第一次请求网站的时候会访问“/favicon.ico”图标文件,如果没有也会出现404
// 如果需要解决这个问题,则有3种方式:
// 方式1:去找个ico文件,存放在静态资源的public目录下,命名为“favicon.ico”
// 方式2:在处理的时候忽略“/favicon.ico”文件的处理,也就是下面的加了判断的写法
// 方式3:不管,不用处理,其不影响页面的显示
if(uri != '/favicon.ico'){
// 读取文件(fs模块),将内容返回给用户(res.end)
let filename = path.join("public", uri);
// 判断文件是否存在
if (fs.existsSync(filename)) {
fs.readFile(filename, (err, data) => {
if (!err) {
// ok
res.end(data);
} else {
// 不ok
res.setHeader("Content-Type", "text/html;charset=utf-8");
res.statusCode = 500;
res.end("请求资源出现错误。。。");
}
});
} else {
res.setHeader("Content-Type", "text/html;charset=utf-8");
res.statusCode = 404;
res.end("你要找的资源失踪了。。。");
}
}
});
// d. 监听端口,启动服务
server.listen(8080, () => {
console.log("server is running at http://127.0.0.1:8080");
});
3.6.6、get数据获取
get数据通过地址栏使用query方式进行传递的数据 例?id=1&name=zhangsan
// 导入
const http = require('http');
const url = require('url');
// 创建实例&监听request事件&监听端口
http.createServer((req, res) => {
// 之前第3步中的回调函数
// 获取地址栏中 query数据
let {
query } = url.parse(req.url, true);
console.log(query);
}).listen(8080)
3.6.7、post数据获取
表单数据多数为post进行提交到服务器端。需要监听req对象的data事件来获取客户端发送到服务器的数据。如果数据量比较大,无法一次性发送完毕,则客户端会把数据切割后分批次发送给服务器。所以data事件可能会被触发多次,每次触发data事件时,收到的数据只是全部数据的一部分,因此需要做数据的拼接才能得到完整的数据:
const http = require('http');
const queryString = require('querystring');
http.createServer((req, res) => {
let arr = [];
// 数据接受中
req.on('data', buffer => {
arr.push(buffer);
});
// 数据传输结束了
req.on('end', () => {
// 拼接接受到的所有数据
let buffer = Buffer.concat(arr);
let post = queryString.parse(buffer.toString())
console.log(post);
});
}).listen(8080)

三、npm包管理
1、介绍
npm是NodeJs项目模块管理工具,它已经集成了nodejs安装包中(自5.2以后新增了npx指令用于解决调用项目内部安装的模块繁琐的问题),使用npm可以实现从NPM服务器下载别人编写的第三方包到本地使用。
npm仓库地址:https://www.npmjs.com/
当然除了npm以外还有Facebook贡献的Yarn,功能和npm一样,也可以作为包管理工具。
问题:npm帮我们下载和安装的包,计算机关机后再开机还是否可以继续使用?
注意:可以在关机后开机继续使用,但是注意其两种安装方式:
- 全局安装:全局安装的包在任何命令行的位置,任何项目路径中都可以使用(辅助类型的工具安装全局,全局安装之后其安装的位置已经在环境变量中。例如:@vue/cli),全局安装使用选项
-g或--global - 项目安装:只在当前项目中可以被使用(默认,不带选项的时候安装即为项目安装,当然也可以使用选项
-S来或--save指定)
npx(了解)
- 为了临时帮我们去做安装操作(react)
- 更好的执行模块的内部命令
node-modules/.bin/mocha --version
# 简化成了:
npx mocha --version
2、切换npm源
源:源站、镜像源、镜像(专门提供npm包下载资源的服务器)。
yum源
composer源
npm源
docker源
npm使用国外镜像源地址,再有的时候可能网络不是很通顺,这时可以使用国内镜像源来完成npm下载模块功能。
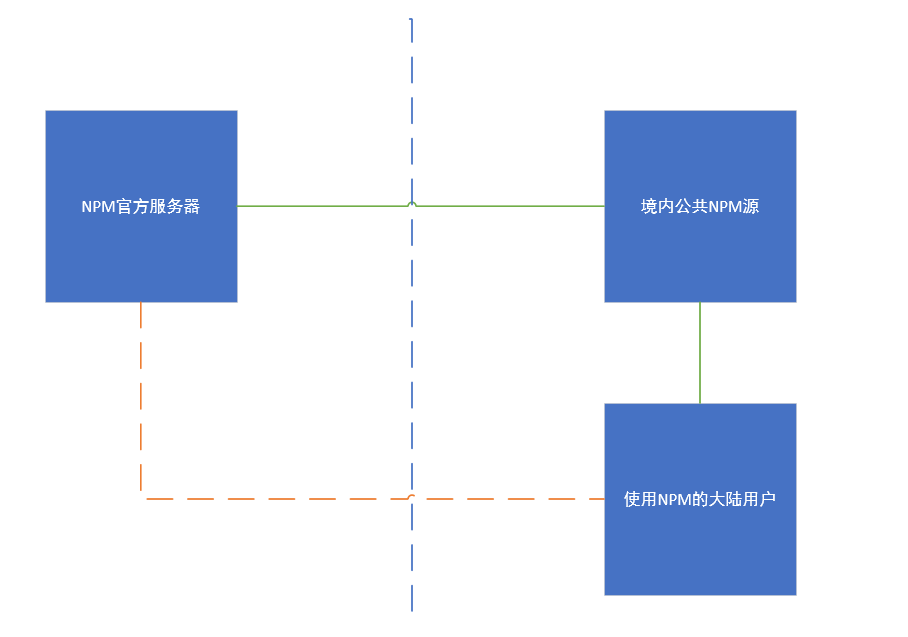
- 切换到阿里提供的npm镜像源(方式1)
地址:https://developer.aliyun.com/mirror/NPM?from=tnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org
执行完毕上述命名后,在系统中提供了一个cnpm包管理工具,功能和npm一样,所不同的是cnpm镜像源地址为阿里提供的源地址。
推荐,日后工作是安装软件都使用cnpm
- 使用nrm管理npm镜像源(方式2,与方式1任选其一,但是建议方式2)
nrm 是一个 npm 源管理器,允许你快速地在 npm源间切换。npm默认情况下是使用npm官方源(npm config list 来查看),如果直接修改npm源,如果后续需要连接到官方源才能工作,这样来回切换源就变得麻烦了,nrm通过简单的命令就可以解决此问题。
# 安装 通过cnpm来安装,cnpm使用的就是国内镜像源
npm i -g nrm
# i:install
# -g:global,全局安装(后续不管在什么地方打开命令行都可以使用该命令)
注:-g表示
global全局,让nrm不限于到某一个项目中,而是在所有的项目中都可使用
安装好nrm后可以通过nrm ls命令来查看效果:
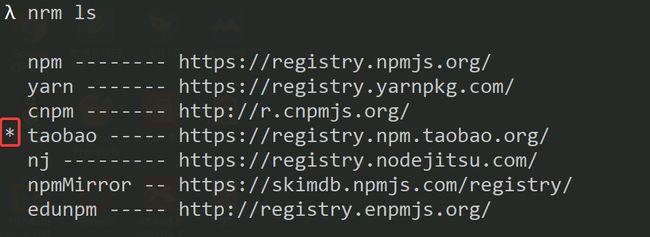
*表示当前正在使用的镜像源
如果想切换成其他的镜像源,可以通过nrm use 源名称进行切换,如需要切换成edunpm的源,则可以执行指令:
nrm use edunpm
3、npm相关命令
# 初始化生成package.json文件(创建项目的)
npm init -y[不询问]
npm init
# 查看本项目已安装模块
npm list
# 安装模块
npm install 模块名[@版本号 可选] 或 npm i 模块名[@版本号 可选]
# 版本号若指定则使用指定的,若不指定则使用最新的
# 卸载已安装模块
npm uninstall 模块名
# 查看全局node_modules的地址
npm root -g
## 安装参数
##--save -S 记录生产环境所需模块 默认
##--save-dev -D 记录开发环境所需模块
##-g 安装到全局
# 生产环境:代码已经上线了的运行环境
# 开发环境:开发人员在开发的时候环境
4、自定义npm命令
目的:npm允许我们执行npm以调用三方的模块,但是由于通过npm调用三方模块的指令写起来比较长,而且可能频繁被使用,这样用起来非常麻烦,因此可以通过自定义命令对原先非常长的命令做一个简化(别名)。
通过package.json文件中的scripts自定义脚本命令:
{
"scripts": {
"test": "echo hello"
}
}
随后就可以在命令行中运行(npm run 自定义指令名称):
npm run test

如果需要更多的自定义命令,只需要按照上述的格式进行套用即可。
后续的vue框架中就会使用到,还有webpack也会用到。
意义:允许我们将原本在命令行中执行的长命令,简化成短的写法,这样用起来很方便。
5、自动重启应用
在编写调试Node.js项目,修改代码后需要频繁的手动重启应用,非常繁琐。nodemon这个工具,它的作用是监听代码文件的变动,当代码改变之后,自动重启。
# 全局安装nodemon
npm i -g nodemon
# 执行node脚本
nodemon app.js

该工具应用非常广泛,后续的框架也是这样的应用。
四、Express【重点】
nodejs中的三方模块,使用最多的一个三方模块,也被称之为node中的一个成型的框架。其是node中http内置模块的替代方案。
正是因为express是与http是同一个需求的不同解决方案,因此后续在学习的时候很多代码或者思路会有一种似曾相似的感觉。
1、介绍
网址:https://www.expressjs.com.cn/
Express 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架。搭建web服务器
Express 的本质:就是一个 npm 上的第三方包,提供了快速创建 Web 服务器的便捷方法。
使用Express开发框架可以非常方便、快速的创建Web网站的服务器或API接口的服务器
2、基本使用
2.1、安装
在项目目录中,打开cmd命令窗口,执行如下命令:
npm init -y # 如果没有项目则先初始化
npm i -S express
2.2、创建web服务
基本遵循之前的四个步骤:
- 导入需要使用的express包
- 创建web实例
- 定义允许访问的地址(定义路由)【重复性步骤】
- 原先的输出:res.end()
- 现在的输出:res.send()
- 启动服务(监听端口)
const express = require('express')
// 创建web服务
const app = express()
// 监听 get请求
// req 请求对象
// res 响应对象
app.get('请求URI',(req,res)=>{
// 向客户端响应数据
res.send({
id:1,name:'张三'})
})
// ....
// 监听POST请求
app.post('请求URI',(req,res)=>{
})
// 其他app.形式的api方法,put/delete/use 等
app.put()
app.delete()
// ....
// 启动服务
app.listen(8080,()=>{
})
扩展:查看当前监听的端口
8080是否启动
- windows平台
- “|”,管道,变量修饰符,过滤器
netstat -ano | findStr 8080
- Unix系平台(macOS、Linux)
netstat -tnpl | grep 8080
案例:手写一个服务器软件,启动后要求用户访问根“/”输出hello world,用户访问/html5输出h5,用于通过post方式访问/post则输出post。
// 1. 导入模块
const express = require("express");
// 2. 创建web实例
const app = express();
// 3. 监听请求
// 用户访问根“/”输出hello world
app.get("/", (req, res) => {
// res.end('xxx')
res.send("hello world");
});
// 用户访问/html5输出2003
app.get("/html5", (req, res) => {
res.send("h5");
});
// 用于通过post方式访问/post则输出post。
app.post("/post", (req, res) => {
res.send("post方式");
});
// 4. 启动服务
app.listen(8080, () => {
console.log("server is running at http://127.0.0.1:8080");
});
地址在匹配的时候是自上而下,必须同时匹配
方法与路径。此外还支持PUT和DELETE请求类型。注意点:如果有
地址都一样,但是需要支持所有的请求动词这种需求,则可以简写成以下代码:app.all('/',(req,res) => { // 业务代码,只要路径匹配上即可 })but,这种方式尽量少用!!甚至别用。
2.3、获取query字符串
获取get传值的参数。
通过 req.query 对象,可以访问到客户端通过查询字符串的形式发送到服务器的参数:
app.get('/',(req,res)=>{
console.log(req.query) // 获取到的直接就是个对象
})
2.4、动态参数传递
默认情况下,express是不支持使用动态参数的,必须要声明路由后才支持。但是“?”号传参不需要声明。
Express也支持类似于Vue中动态路由的形式传递参数,传递的参数通过 req.params 对象可以访问到:
// 必须的路由参数(不传就匹配不上,返回404错误)
app.get('/:id',(req,res)=>{
console.log(req.params.id)
})
// 可选的路由参数(传递与否都不会报错)
app.get('/:id?',(req,res)=>{
console.log(req.params.id)
})
这个传参方式是符合restful传参规范的。
扩展Restful规范(规范不是标准!!!):
规范1:restful规范是一个接口开发的规范(一般用于后端,但前端也可以使用)
规范2:restful规范规定了多种请求类型来适配不同的操作,常见的如下:
GET请求类型:用于获取数据(获取xxx列表、获取xxx详情)
POST请求类型:用于数据新增(xxx添加)
PUT请求类型:用于数据修改(xxx修改、xxx编辑)
DELETE请求类型:用于数据删除(xxx删除)
规范3:请求地址规范,例如如果需要实现用户管理模块,则相关的地址可以参考:
用户列表:http://example.com/admin/users GET
用户详情:http://example.com/admin/users/100 GET
用户添加:http://example.com/admin/users POST
用户修改:http://example.com/admin/users/100 PUT
用户删除:http://example.com/admin/users/100 DELETE
规范4:响应内容格式规范(后端),返回的json节点名称要有意义
2.5、静态资源托管
express提供了一个非常好用的方法,叫做 express.static(),通过此方法,可以非常方便地创建一个静态web资源服务器:
app.use(express.static('public'))
// app.use()表示使用(中间件)
// 现在可以访问public目录下所有的文件
// 如public/aa.jpg文件,则可以通过 : http://xxxx/images/aa.jpg
express还支持给静态资源文件创建一个虚拟的文件前缀(实际上文件系统中并不存在),可以使用 express.static 函数指定一个虚拟的静态目录,就像下面这样:
前缀的使用意义:
- 可以迷惑别人,一定程度上阻止别人猜测我们服务器的目录结构
- 可以帮助我们更好的组织和管理静态资源
app.use('/static', express.static('public'))
前缀前面的“/”必须要加,否则就错。【404】
现在你可以使用 /static 作为前缀来加载 public 文件夹下的文件了:
http://localhost:3000/static/images/kitten.jpg
http://localhost:3000/static/css/style.css
http://localhost:3000/static/js/app.js
http://localhost:3000/static/images/bg.png
http://localhost:3000/static/hello.html
使用app.use()方法一般写在具体的路由监听之前。
3、路由
3.1、概述
路由在生活中如拨打服务电话时,按数字几能处理什么样的处理,它就是类似于按键与服务之间的映射关系。在Express中,路由指的就是客户端发起的请求(地址)与服务器端处理方法(函数)之间的映射关系。

express中的路由分3部份组成,分别是请求类型(方法)、请求uri(地址)和对应的处理函数。
当一个客户端请求到达服务端之后,先经过路由规则匹配,只有匹配成功之后,才会调用对应的处理函数。在匹配时,会按照路由的顺序进行匹配,如果请求类型和请求的 URL 同时匹配成功,则 Express 会将这次请求,转交给对应的函数进行处理。
app.<get/post/put/delete/use>(uri,(req,res)=>{
})
// use方法并不是请求类型方法,但是它放的位置与请求方法一致
3.2、路由模块化(重点)
含义:将原本可能写在一个文件中的路由规则,拆分成若干个路由文件(js文件,一个js文件就是一个模块)。
顾名思义,将路由进行模块化,以模块(js文件)为单位进行管理,物以类聚。
核心思想:能拆就拆(拆到不能拆为止,解耦,高内聚,低耦合)。
在开发项目时,如果将所有的路由规则都挂载到入口文件中,程序编写和维护都变得更加困难。所以express为了路由的模块化管理功能,通过express.Router()方法创建路由模块化处理程序,可以将不同业务需求分开到不同的模块中,从而便于代码的维护和项目扩展。
路由模块化处理可以分为以下步骤来完成
- 创建独立js空白文件(最后是统一放在一个目录下,一般是router目录)
- 该文件即路由
模块化文件
- 该文件即路由
- 在第一步js文件中使用
express.Router()方法创建路由模块对象 - 使用路由对象完成路由规则的对应的业务编写
- 使用模块化导出(
module.exports = router) - 在主入口文件中能够使用app.use方法来注册定义的路由模块
- 支持前缀的使用
- app.use(“前缀”,路由模块化路由)
a. 创建路由的主文件src/index.js
const express = require("express");
const app = express();
// 导入路由模块
const usersRouter = require("./router/users.js");
const goodsRouter = require("./router/goods.js");
// 使用路由路由
// app.use(usersRouter);
// app.use(goodsRouter);
// 路由也支持类似于静态资源托管的操作,设置特定的前缀
// 将公共的"/admin"提取出来
// 路由前缀:app.use(前缀,路由模块)
app.use("/admin", usersRouter);
app.use("/admin", goodsRouter);
app.listen(3000, () => {
console.log("server is running at http://127.0.0.1:3000");
});
b. 创建users模块路由文件src/router/users.js
// 获取router对象
const express = require("express");
const router = express.Router();
// 编写路由规则
// 用户列表
// 路由地址的第一个斜杠是不能去除的
router.get("/users", (req, res) => {
res.send("你访问的是用户列表");
});
// 用户详情
// 路由地址的第一个斜杠是不能去除的
router.get("/users/:uid", (req, res) => {
res.send("你访问的是用户详情,传递的id是" + req.params.uid);
});
// 导出
module.exports = router;
c. 创建goods模块的路由文件src/router/goods.js
const express = require("express");
const router = express.Router();
// 商品添加
router.post("/goods", (req, res) => {
res.send("你访问的是商品添加");
});
// 商品修改
router.put("/goods/:gid", (req, res) => {
res.send("你访问的是商品修改,传递的id是" + req.params.gid);
});
// 商品删除
router.delete("/goods/:gid", (req, res) => {
res.send("你访问的是商品删除,传递的id是" + req.params.gid);
});
// 导出
module.exports = router;
4、中间件(重点)
4.1、含义
中间件(middleware)可以理解为业务流程的中间(请求之后,响应之前)处理环节。如生活中吃一般炒青菜,大约分为如下几步骤:
 express中,当一个请求到达的服务器之后,可以在给客户响应之前(回调函数之前)连续调用多个中间件,来对本次请求和返回响应数据进行处理。
express中,当一个请求到达的服务器之后,可以在给客户响应之前(回调函数之前)连续调用多个中间件,来对本次请求和返回响应数据进行处理。
- 所处的位置:请求之后,响应之前,由于其在两者之间,所以被称之为中间件
- 中间件可以有多个,也可以有一个,也可以没有(中间件是可选的)
- 中间件有什么用:处理数据
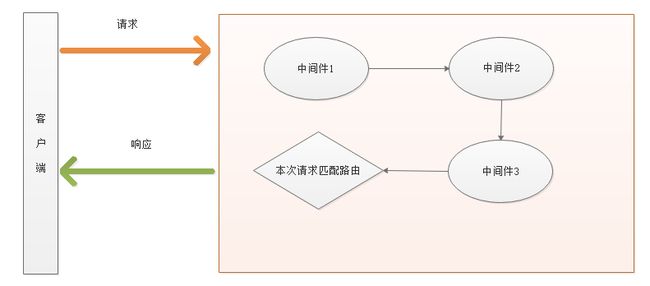
中间件的思想最早来自于后端。
4.2、中间件的分类
中间件可以分类可分如下几类(常说的分类):
-
内置中间件,也就是express本身自带无需npm安装
- express.static()
-
第三方中间件
非 Express 官方内置的,而是由第三方开发出来的中间件,叫做第三方中间件。在项目中可以通过npm进行安装第三方中间件并配置,从而提高项目的开发效率。例如body-parser (解析post数据的)此中间件可以很方便帮助我们获取到post提交过来的数据。
-
自定义中间件,开发者自己编写的
如果从使用层面去考虑,中间件可以划分为:
- 应用级别中间件(通过app.get/post/use等方法绑定到app实例的中间件)
- 全局使用中间件(所有路由都生效)
- app.use(中间件)
- 局部使用中间件(当前路由生效)
- app.请求方法(地址,[中间件…,]回调函数)
- app.请求方法(地址,中间件1,中间2,中间3…,]回调函数)
- 全局使用中间件(所有路由都生效)
- 路由级别中间件(绑定到express.Router()上的中间件)
- 其用法与应用级别的中间件没有任何区别,只是一个绑在app实例上,一个绑在router上
- router.use(中间件)
- router.请求方法(地址,[中间件…,]回调函数)
- 其用法与应用级别的中间件没有任何区别,只是一个绑在app实例上,一个绑在router上
4.3、内置中间件
express提供了好用的内置中间件,如提供一个静态资源管理的中间件,通过此中间件就可以帮助为我们快速搭建一个静态资源服务器:
app.use('前缀',express.static('托管目录地址'))
在express中,除了内置的express.static()中间件,还内置了另外2个常用的中间件:
- express.json()
- 作用:接收json格式提交的数据
- 兼容性:express >= 4.16.0
app.use(express.json())- 其在接收完数据后,会将数据的对象形式挂载到
req请求对象的body属性上
- express.urlencoded()
- 作用:处理post表单数据
- 兼容性:express >= 4.16.0
app.use(express.urlencoded({extended: false}))- 其在接收完数据后,会将数据的对象形式挂载到
req请求对象的body属性上
注意,
- 上述2个中间件都说把数据处理之后挂到req.body上,但是实际上并不会出现我们想的覆盖的问题。
案例:使用json、urlencoded中间件来接收json数据与表单post数据,发送可以通过postman来进行
注意:在使用postman发送JSON格式数据的时候请按照以下图示进行

并且需要注意,JSON数据数据名必须用双引号引起来,值如果是字符串的话也需要用双引号引起来,单引号不行!!!
以express.json()为例:

以express.urlencoded()中间件为例,如果发送post请求,则postman应该这样的设置:

// 局部中间件,处理表单提交的数据
app.post("/post", express.urlencoded({
extended: false }), (req, res) => {
// 输出得到的请求体
console.log(req.body);
});
注意:关于urlencoded中间件中的配置项
extended值的说明
- 值默认为true,但是不建议使用默认的true
- 值true与false的区别
- false:使用querystring库去解析post数据
- 去除获取到的数据对象的内置方法
- 接收到的数据只有字符串与数组的形式
- true:使用qs库去解析post数据
- 使得获取到的数据对象更加面向对象化
4.4、自定义中间件
自定义中间件,其本质就是定义一个处理请求的函数,只是此函数中除了有request和response参数外还必须包含一个next参数,此参数作用让中间件能够让流程向下执行下去直到匹配到的路由中发送响应给客户端。也可以通过给request对象添加属性来进行中间件数据的向下传递
function mfn(req,res,next){
//. 自己需要定义的逻辑流程
// 中间件最后一定要执行此函数,否则程序无法向下执行下去
next()
}
注意:在整个请求链路中,所有中间件与最终路由共用一份
req和res

案例:依据上述的共用特性,自定义一个中间件来接收post提交的表单数据(意义:内置那中间件是不是存在兼容性问题)
需求:自己手动模拟一个类似于express.urlencoded这样的中间件,以解析post提交到服务器的表单数据。
步骤分析:
- 定义中间件(本质:函数)
- 监听req的data事件
- 在中间件中,需要监听req对象的data事件来获取客户端发送到服务器的数据。如果数据量比较大,无法一次性发送完毕,则客户端会把数据切割后分批次发送给服务器。所以data事件可能会被触发多次,每次触发data事件时,收到的数据只是全部数据的一部分,因此需要做数据的拼接才能得到完整的数据。
- 监听req的end事件
- 当请求体数据传输完毕后会触发end事件,拿到全部数据后可以继续处理post数据
- 使用querystring模块来解析请求体数据
- 将解析出来的请求体对象挂载到req.body上
- 将自定义中间件封装为模块(可选,建议做)
- 为了优化代码的结构,我们可以把自定义的中间件函数封装成独立的模块
实现代码
独立的自定义中间件模块:cs-body-parse
// 引入querystring模块
const querystring = require("querystring")
// 核心代码
var csBodyParse = (req, res, next) => {
let data = []
req.on("data", (buffer) => {
data.push(buffer)
})
req.on("end", () => {
let post = querystring.parse(Buffer.concat(data).toString())
// 挂载到req.body上
req.body = post
// 继续后续的请求处理(end事件处理是异步的,所以next得写在函数里)
next()
})
}
// 导出
module.exports = csBodyParse
应用入口文件:app.js
// 自定义中间件服务器文件(入口文件)
const express = require('express')
const app = express()
// 引入自己封装的中间件模块cs-body-parse
const csBodyParse = require('./modules/cs-body-parse')
// csBodyParse的使用
app.use(csBodyParse)
// 路由
app.post('/post',(req,res) => {
console.log(req.body)
})
app.listen(3722,() => {
console.log('Server is running at http://127.0.0.1:3722')
})
4.5、第三方中间件
在express中,其允许我们使用第三方的中间件来进行对数据进行处理。例如有一个可以帮助我们解决跨域问题的中间件:cors
问题:
-
什么是跨域?
- 同源策略
-
解决跨域问题的方案有几种?
- 代理服务器
- jsonp
- 问题:jsonp与json是什么关系?
- cors
下载第三方的中间件:https://www.npmjs.com/package/cors
npm i cors
// 第三方中间件
// cors是否存在取决于是否有响应头信息
const express = require('express')
// 导入
const cors = require('cors')
const app = express()
// 最简单的用法
app.use(cors())
app.get("/cors",(req,res) => {
res.send("ajax请求")
})
app.listen(8080,() => {
console.log('server is running at http://127.0.0.1:8080');
})
作业:实现一个自定义中间件,要求能够记录用户访问信息,访问信息记录在logs/目录(目录手动创建)下的.log文件中,文件的名称以当天的日期进行命名,例如“20210421.log”,要求里面的访问记录一条一行,记录以下信息:用户访问时间、访问路径、访问请求类型、访问的浏览器头信息、访问者IP地址
4.6、错误类型中间件
4.6.1、异常中间件
**作用:**专门用来捕获整个项目发生的异常错误,从而防止项目异常崩溃的问题产生(友好显示异常)。
**格式:**错误级别中间件的函数参数中,必须有四个形参,分别是(err,req,res,next)
问:多出来的err参数有什么作用呢?
答:里面包含了错误的信息,err.message属性中就包含了错误的文本信息,这个信息可以在中间件中输出给用户看。
示例代码:
app.get('/',(req,res) => {
throw new Error('服务器内部发生了致命的错误!')
res.send('Welcome to my homepage')
})
app.use((err,req,res,next) => {
console.log('发生了错误:' + err.message)
res.send('Error!' + err.message)
})
**案例:**要求指定一个路径(可能路由对应的文件不存在),读取文件内容,输出给用户
默认情况下,程序如果崩溃了,会出现大致如下的错误:

这样的错误显示,既不友好,也不安全。以下是经过异常中间件处理好的显示页面:
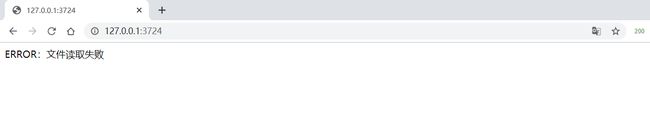
整体代码如下:
// 异常中间件:专门用于处理异常的中间件
// 注意点:
// a. 异常中间件(下面的404中间件也是),需要写在所有路由规则的最后;
// b. 异常中间件与常规中间件不一样,其形参有四个
// err:异常错误对象,里面包含了错误信息和错误代码等
// req:请求对象
// res:响应对象
// next:继续执行下一个的方法
// c. 异常中间件不用在函数体里执行next方法,但是即便不执行next方法,但形参中必须得有next
// 意义:可以美化程序崩溃的页面,使得程序更加安全
const express = require("express");
const fs = require("fs");
const app = express();
// 扩展补充:方法1,通过try-catch捕获错误,从而达到抑制错误输出的效果
app.get("/", (req, res) => {
// 尝试去读取一个文件的内容,地址是随便写的
// 尝试执行try中的内容,如果try内容抛异常了,则走catch中的内容
try {
fs.readFileSync("./abc.efg");
} catch (error) {
res.send("程序异常");
}
});
// 方法2:用过异常中间件来获取错误,进而抑制错误的显示
app.get("/mid", (req, res) => {
// 尝试去读取一个文件的内容,地址是随便写的
fs.readFileSync("./abc.efg");
});
// 异常中间件(兜底)
app.use((err,req,res,next) => {
// err里面包裹异常信息,可以被我们使用
res.send("通过异常中间件来抑制错误输出,获取到的异常信息是:" + err.message + err.errno)
})
app.listen(3000, () => {
console.log(`Server is Listening on 3000`);
});
注意事项:错误级别中间件要想发挥其作用,必须写在所有的路由的后面,是否是
app.listen之前无所谓。
4.6.2、404处理
**作用:**用于处理404的请求响应
示例代码
// 假设定义这个路由,但是实际请求的时候请求了/12345,这个时候就会404
app.post("/1234", (req, res, next) => {
res.send('你请求成功了')
});
// 404的输出
// 该中间件也需要写在最后(与异常中间件的顺序无所谓,只要确保其在所有的路由方法之后就可)
app.use((req,res,next) => {
// 输出404错误
res.status(404).send('404
')
// 先指定404状态码,然后再输出错误信息
})
404错误中间件也要求在所有的正常请求路由的后面去声明使用,不要放在路由的前面,否则会导致后面的路由都是404错误。
**注意点:**错误级别的中间件,必须在所有路由之后注册,至于404中间件与异常中间件,谁先谁后无所谓。
页面:https://404.life/
4.7、小结
在express中使用中间件时,需要注意以下几点:
- 在定义路由之前注册中间件(除了错误中间件)
- 一个请求中可以连续调用多个中间件
- 在一次请求链路中,多个中间件与最终路由方法中,他们共用一份
req与res - 每个中间件最后必须调用
next()(除了错误中间件,必须要有参数传递) - 不要在中间件的
next()后继续写任何代码(没意义) - 404中间件与异常中间件的顺序无所谓(只要确保都在路由后面即可)
5、cookie和session【会话控制】
前置点:HTTP是无状态协议。例如:生活中有些店家会为了吸引客户开设一些会员卡的业务,一种是记名的会员卡,还有一种是不记名的会员卡,其中不记名的会员卡使用的情形有一点类似于无状态的情况。但是实际的情况是,很多系统都需要去辨别用户,以及记录用户的一系列操作,那么此时就需要去实现“记名”的效果(所谓有状态的效果),但是http协议是不行的,因此就有了其他的手段:cookie和session(会话管理手段)。
两者区别:
- cookie:
- 存储于浏览器的(客户端)
- 有大小限制,大概是4kb的大小
- 有被用户修改、删除的风险
- session:
- 存储在服务端的(服务器上)
- 没有被用户说改就改的风险(相对于cookie更加安全)
- 默认情况下是基于cookie实现的(会将session会话id给cookie,id存储客户端上)
- 当然session的id是可以被删除的(客户端上),解决是需要后端技术去实现的
- 理论上讲,只要磁盘空间够,session是可以放很多数据的
5.1、cookie
HTTP是一个无状态协议,客户端每次发出请求时候,下一次请求得不到上一次请求的数据,我们如何将上一次请求和下一次请求的数据关联起来呢?如用户登录成功后,跳转到其他页面时候,其他的页面是如何知道该用户已经登录了呢?此时就可以使用到cookie中的值来判断用户是否登录,cookie可以保持用户数据。
cookie它是一个由浏览器(存储cookie)和服务器(产生cookie)共同协作实现的(cookie是存储于浏览器中)。cookie分为如下几步实现:
-
服务器端向客户端发送cookie并指定cookie的过期时间。
-
浏览器将cookie保存起来。
-
之后每次请求都会将cookie发向服务器端,在cookie没有过期时间内服务器都可以得到cookie中的值。
express中操作的cookie使用cookie-parser模块。
cookie-parser模块(也是中间件),所以其也会去操作req,res对象;
- 设置cookie是通过
res.cookie(name,value,[选项]),- 读cookie的时候需要通过
req.cookies对象来获取。
npm i -S cookie-parser
示例代码
const express = require("express");
const cookieParser = require("cookie-parser");
const app = express();
// 中间件引入
app.use(cookieParser());
app.get("/", (req, res) => {
// 服务器端通过req来获取cookie数据
if (req.cookies.username) {
console.log(req.cookies);
res.send("再次欢迎你");
} else {
// cookie设置过期时间为1天
// maxAge 设置cookie过期时间 毫秒
res.cookie("username", "admin", {
maxAge: 86400 * 1000 });
res.send("欢迎你~");
}
});
app.listen(8080);
5.2、session
cookie操作很方便,但是使用cookie安全性不高,cookie中的所有数据存储在客户端浏览器中,数据很容易被伪造;所以一些重要的数据就不能放在cookie当中了,并且cookie还有一个缺点就是不能存放太多的数据,一般浏览大约在4k左右,为了解决这些问题,session就产生了,session中的数据保留在服务端的。
数据放到cookie中是不安全的,我们可以在cookie中存放一个sessionId值,该sessionId会与服务器端之间会产生映射关系,如果sessionId被篡改的话,那么它就不会与服务器端数据之间产生映射,因此安全性就更好,并且session的有效期一般比较短,一般都是设置是20分钟左右,如果在20分钟内客户端与服务端没有产生交互,服务端就会将数据删除。
扩展阅读
session的原理是通过一个sessionid来进行的,sessionid是放在客户端的cookie中,当请求到来时候,服务端会检查cookie中保存的sessionid是否有,并且与服务端的session数据(一般是session文件)映射起来,进行数据的保存和修改,也就是说当我们浏览一个网页时候,服务端会随机生成一个1024比特长的字符串,然后存在cookie中的sessionid字段中,当我们下次访问时,cookie会带有sessionid这个字段。
express中操作的session使用cookie-seesion模块
cookie-session包的对session设置与获取都是基于req请求对象。
npm i -S cookie-session
示例代码
const express = require("express");
const session = require("cookie-session");
const app = express();
app.use(
session({
name: "sessionId",
// 给sessionid加密的key,随便填写,擦下键盘即可
secret: "afsfwefwlfjewlfewfef",
maxAge: 20 * 60 * 1000, // 20分钟
})
);
app.get("/", (req, res) => {
if (!req.session["view"]) {
req.session["view"] = 1;
} else {
req.session["view"]++;
}
res.send(`欢迎您第 ${
req.session["view"]} 次访问!`);
});
app.listen(8080);
6、mongodb
mongodb:就是一个数据库
6.1、介绍
Mongodb是一个介于关系数据库和非关系数据库之间的产品(Nosql),是非关系数据库当中功能最丰富,最像关系数据库的(在学习的时候有一种在学mysql的感觉),语法有点类似javascript面向对象的查询语言(又有一种在学习JavaScript的感觉),它是一个面向集合的,模式自由的文档型数据库。Mongodb数据库旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
- MongoDB是一个数据库
- 操作语法有点像JavaScript的面向对象写法
- 关系型数据库和非关系型数据库结构区别

mongodb数据体系
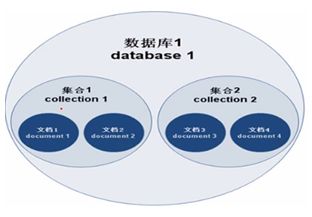
上图所表达的含义:
- 一个数据库中可以包含多个collection(表)
- 一个collection(表)里可以包含多个document(行)
6.2、下载安装
下载地址:https://www.mongodb.com/download-center/community
下载windows的安装版本:
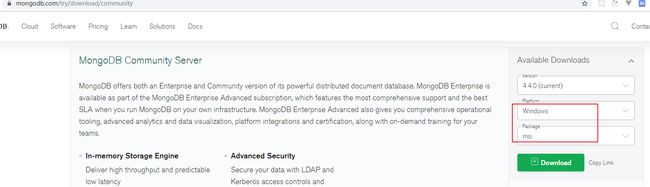
下载到本机后,双击进行安装mongodb数据库,一路下一步(next)即可(如果需要更改安装路径请自行选择):


安装完成后,可以通过服务方式启动,启动成功后,默认端口号为:27017

最后需要解决环境变量的问题:

解决完环境变量问题后,再次执行命令正常应该出现如下结果:

6.3、基本操作指令(了解)
- 打开cmd在命令行中输入命令:
此命令就是运行1_client.bat的执行效果
mongo

- 退出mongoDB使用
exit
exit
或
Ctrl + C 强制取消
或
Ctrl + D Ctrl+D在许多终端(命令行)中表示logout

- 查看所有的数据库列表:
在MySQL中,查询数据库信息是
show databases列出的库都是非空的库
show dbs

- 创建数据库或切换数据库:
use切换数据库时,若库存在则切换,如果数据库不存在则创建并切换
use创建的数据库只是一个空的数据库,没有集合,所以
show dbs不显示空数据库。
use 数据库名
可以使用db命令来查看当前所在的数据库名称:
db

- 给数据库中创建一个members的集合,并向集合中添加文档(行)数据:
表是不需要先行进行定义的,当我们往一个表中插入记录后,表就自动出来了。
JSON格式数据:不是严格意义上的json数据,key名可以不使用引号包裹
db.表名/集合名.insert(JSON格式数据)
# 表名/集合名是不存在的(第一次插入数据的时候),当数据插入完毕则表名就存在了

- 查看当前数据库中的集合列表:
# 查看当前数据库中的集合列表
show tables
# 或
show collections

- 删除表
db.表名/集合名.drop()

- 删除库
需要进入要删除的库,然后再去执行这个命令
# 删除的是当前的库
db.dropDatabase()
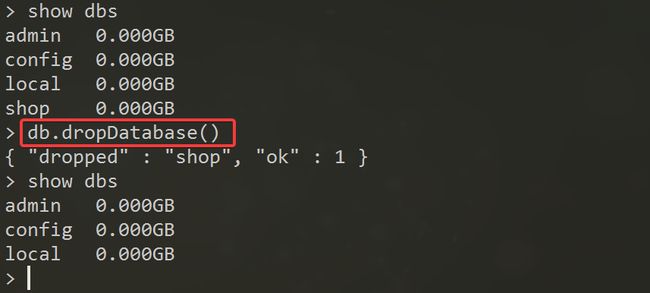
刚才命令集合:
- show dbs:查看数据库列表
- use db:使用/创建数据库
- db:查看当前库名
- db.表名.insert():新增数据&可能会创建出一个数据表
- show tables / show collections:查看当前库中的表列表
- db.表名.drop():删除指定的表
- db.dropDatabase():删除当前的库
6.4、增删改查(了解)
增删改查:英文名叫做C[create]U[update]R[read]D[delete]
6.4.1、添加
MySql需要先建立数据表,后才能使用数据表中的数据。但是mongodb不是这样,它不需要先建立数据表关系。
向集合中添加文档数据:
# 添加单条文档数据
db.表名/集合名.insertOne({
key: value , key: value...})
# 添加多条文档数据
db.表名/集合名.insertMany([{
}, {
}, {
}])
# 可以添加单条也可以多条数据(为主)
db.表名/集合名.insert( {
} )
db.表名/集合名.insert([{
}, {
} ])
例如:
- 使用
insertOne添加单个数据到shop库的members集合

- 使用
insertMany添加2个数据到shop库的members集合
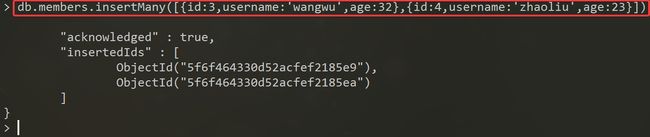
- 使用
insert添加2个数据到shop库的members集合

后续实际使用的比较多的是:insertOne()、insert({}),插入多个的形式仅作了解。
6.4.2、查询
- 查询所有的数据
类似于原生的SQL:select * from table [where xxx]
db.表名/集合名.find(); # 获取全部(推荐)
db.表名/集合名.find({
}); # 获取全部
{ }用于条件限制,当没条件的时候,上述两个用法效果一致

关于
_id{ “_id” : ObjectId(“5c0fa4758878caa23d36c0fb”), “name” : “zhangsan” }
objectID类型
ObjectId对象对象数据组成:时间戳 |机器码|PID|计数器 系统自动生成
_id的键值我们可以自己输入,但是不能重复,因此为了避免工作的复杂建议不要人为的去干预_id的是很工程
- 带条件查询
类似于MySQL的
where语句此处允许使用多个条件,如果有就在"{}"中多写几个,默认是“且”条件关系。
db.表名/集合名.find({
key:value,key:value....})

- 字段显示控制
类似于MySQL的
select后的字段选择,selectusername,passwordfrom members
db.表名/集合名.find(条件,{
字段名:0或1,....})
# 0:不显示
# 1:显示
# _id字段,由于其是系统产生的,默认情况下是显示的
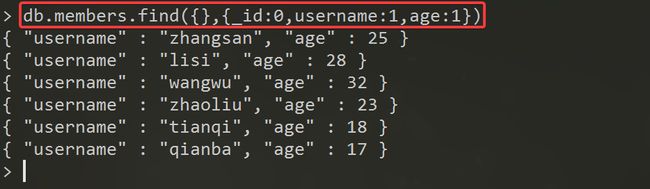
- 逻辑运算(稍微复杂一些)
### 条件表达式
# 年龄大于5的
db.表名/集合名.find({
age:{
$gt:5}}); #age > 5(great than)
# 年龄大于等于5的
db.表名/集合名.find({
age:{
$gte:5}}); #age >= 5 (great than & equal)
# 年龄小于5的
db.表名/集合名.find({
age:{
$lt:5}}); #age < 5 (less than)
# 年龄小于等于5的
db.表名/集合名.find({
age:{
$lte:5}}); #age <= 5
# 年龄不等于5的
db.表名/集合名.find({
age:{
$ne:5}}); #age != 5 (not equal)
# 在一个指定的数值中查询 $in 年龄在不在这几个指定数值当中
db.表名/集合名.find({
age:{
$in:[1,2,3]}) ## where xxx in '集合'
## 且关系 and
db.表名/集合名.find({
age:{
$lt:5},username:"user11"})
## where age < 5 & username = 'user11'
## 或关系 or(有点绕)
db.表名/集合名.find({
$or:[{
条件1},{
条件2}]})
## 例如
db.表名/集合名.find({
$or:[{
age:{
$ne:5}},{
username: "user11"}]});
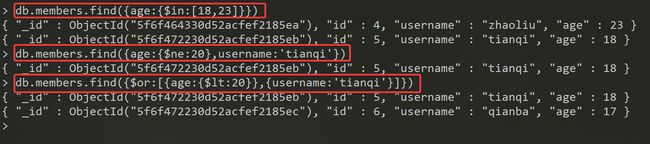
需求:查询出年龄小于30或者gender为0的数据
db.members.find({
$or:[{
age:{
$lt:30}},{
gender:0}]})

- 模糊查询
类似于原生的SQL语句:
where xxxx like '%YYY%'
#正则
db.表名/集合名.find({
字段名:/正则/i})
# i 不区分大小写
# `不能加引号`,否则就成了字符串,成了字符串就成了精确匹配

- 统计
类似于MySQL中的
select count(id) from table计数操作:数记录的数量
#统计总记录数
db.表名/集合名.count(); // 统计所有的记录的总数
db.表名/集合名.find({
}).count(); // 统计符合条件的结果的记录总数

注意点:find()顺序是否可以与count()颠倒。
count不能与find的顺序交换
- 排序
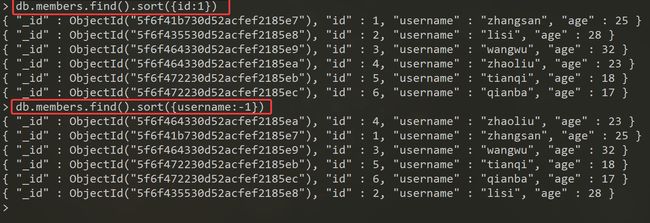
# 排序
# 1 升序 -1 降序 字段
# 以age字段来升序
db.表名/集合名.find().sort({
age:1})
# 以age字段来降序
db.表名/集合名.find().sort({
age:-1})
- 分页(实用)
原生的SQL中:
- select * from table where id > 50
limit 10,10- select * from table where id > 50
limit 10
# 指定获取几条 skip/limit 分页
db.表名/集合名.find().limit(3);
db.表名/集合名.find().skip(1).limit(3);
## skip表示起始位置,也就是从第几个开始
## limit表示获取的记录的个数(长度)
## skip与limit的顺序先后无所谓

6.4.3、更新
根据条件修改已存在集合中的文档数据:
# 更新是要有条件的,没有条件在数据库层面来讲是可以更新的,但是实际是没有对应的业务需求
# 只修改单条文档
db.表名/集合名.updateOne({
key:value},{
$set:{
key:value}})
# 修改符合条件所有文档数据
db.表名/集合名.updateMany({
key:value},{
$set:{
key:value}})
## 如果上述两个方法的条件一致,并且有多个符合条件的,那么:
# updateOne,不管有多少个符合条件的只修改第一个
# updateMany,有多少改多少
# ---------------------------------
# 数字字段的值的`自增和自减`
db.表名/集合名.updateOne({
key:value},{
$inc:{
key:1}}) // increments,自增
db.表名/集合名.updateMany({
key:value},{
$inc:{
key:1}})
db.表名/集合名.updateOne({
key:value},{
$inc:{
key:-1}}) // decrements
db.表名/集合名.updateMany({
key:value},{
$inc:{
key:-1}})
# 自增是整数,自减是负数
# 更新和删除操作允许不写条件,但是不能不写

6.4.4、删除(了解)
删除在实际开发的时候一般不用,正常做程序开发的时候所使用的删除实际上是修改。
删除分为:真删除(物理删除)、假删除(逻辑删除)。
删除集合中已存在的文档数据:
# 删除单条文档
db.表名/集合名.deleteOne({
key: value })
# 删除符合条件多条文档
db.表名/集合名.deleteMany({
key: value})
# 删除全部数据(慎用)
db.表名/集合名.deleteMany({
})

6.5、node操作mongoDB
6.5.1、Mongoose介绍
网址:http://www.mongoosejs.net/docs/index.html
mongoose是Node环境下异步操作mongodb数据库的扩展,仅限于Node环境下使用。
使用mongoose操作mongodb数据步骤:
- 使用npm安装mongoose
- 导入模块
- 然后使用(烦)
- 连接mongodb数据库
- 定义Schema:类似于表单的前端js验证的操作
- schema:简单的来讲就是规定了表结构的操作。比如:要求表中有username字段,该字段接着要求必填,可以继续要求该字段类型为string,还可以要求这个字段长度为10(相当于mysql建表时候的sql语句对字段的规定)
- 定义model:mvc模式
- mvc:开发模式,要求将一个项目拆分成三个大的主体部分(m模型、v视图、c控制器),其中m负责业务逻辑与数据库的交互部分、v负责展示给用户页面、c控制器负责请求与响应的整体调度。
- vue、react:mvvm
- 使用model进行数据增删改查操作
6.5.2、连接数据库
使用npm安装mongoose模块,并在使用模块中导入:
# 安装mongoose
npm i -S mongoose
// 导入模块
const mongoose = require('mongoose')
// 连接数据库 返回promise对象
mongoose.connect('mongodb://localhost:27017/数据库名', {
useNewUrlParser: true,
useUnifiedTopology: true
})
// 库必须要先存在
// connect方法参2在新版本需添加,否则会有警告提示
// useNewUrlParser:当前URL字符串分析器已弃用,将在将来的版本中删除。要使用新的解析器,请将选项{usenewurlparser:true}传递给mongoclient.connect。
// useUnifiedTopology:当前服务器发现和监视引擎已弃用,将在将来的版本中删除。要使用新的服务器发现和监视引擎,请将选项{useUnifiedTopology:true}传递给mongoclient构造函数
6.5.3、定义Schema
Schema是mongoose中会用到的一种数据模式,可以理解为数据表结构的定义;每个schema会映射到mongodb中的一个集合,它不具备操作数据库的能力。Schema中定义数据校验,默认值,字段名,字段类型等特性。
作用:
- 建表(也就是说,后期建表不再通过mongoDB的命令行的形式产生了,而是通过JavaScript代码实现)
在定义schema的是有使用到相关约束规则,可以查看:http://www.mongoosejs.net/docs/guide.html
// 创建用户集合规则
const UserSchema = new mongoose.Schema({
// 字段名/域名称
name: {
// 指字域类型
type: String,
// 必填字段
required: true,
// 字段最小长度 minlength 用于字符串类型
minlength: 2,
},
age: {
type: Number,
// 默认值
default: 10,
// 字段最小值 min用于数字类型
min: 1,
},
pwd: String,
email: String,
// 定义此字段为 字符串数组类型
hobbies: [String],
});
在Schema定义好后,后期增删改查时,如果对应的表不存在,则其会自动按照Schema的约束进行建表,如果表存在了则不重新建立。
6.5.4、定义model
model 是由schema 生成的模型,模型是最终用来进行数据增删改查操作使用的,可以对数据库的操作:
// 参数1:model名称,模型名一般会和表名一样
// 参数2:schema名称
// 参数3:操作的数据集合(表名) 如果参数3没有填写则以 参1的复数形式为操作数据集合名称
const Model = mongoose.model('User', UserSchema, 'users')
// 模型curd相关方法
Model.insertMany({
key:value})
Model.deleteMany({
条件},err=>{
})
Model.deleteOne({
条件},err=>{
})
Model.countDocuments({
条件})
Model.find({
条件},{
可选字段返回:0/1},{
skip:0,limit:10})
Model.findOne({
条件},{
可选字段返回:0/1})
Model.updateMany({
条件},{
$set:{
key:value}},res=>{
})
Model.updateOne({
条件},{
$set:{
key:value}},res=>{
})
6.5.5、在express中使用mongoose
需求:通过postman发送post数据给express服务器,能够对mongoDB中的shop库中的members表进行插入操作。
- 创建库
use shop
- 创建express服务器,接受post传参
- 连接数据库(mongoDB)
- 定义schema(创建表
members) - 定义模型实现数据的添加操作
// - 创建express服务器,接受post传参
const express = require('express')
const app = express()
const body = require('body-parser')
// 使用中间件解析post数据
app.use(body.urlencoded({
extended: false}))
// 1. 引入mongoose
const mongoose = require('mongoose')
// - 连接数据库(mongoDB)
mongoose.connect("mongodb://localhost:27017/shop", {
useNewUrlParser: true,
useUnifiedTopology: true,
});
// - 定义schema(创建表members)
const members_schema = new mongoose.Schema({
username: {
type: String,
minlength: 2,
},
password: {
type: String,
minlength: 8,
},
// 后续如果需要更多的字段,接着写即可
});
// - 定义模型实现数据的添加操作
const Model = mongoose.model('Member',members_schema,'members')
app.post('/',(req,res) => {
// console.log(req.body);
// 写入数据到mongoDB
// Model.insertMany(req.body)
// 查询
Model.find().then(ret => console.log(ret))
// 象征性输出
res.send('hi')
})
app.listen(9527,() => {
console.log('server is running at http://127.0.0.1:9527');
})
7、模版引擎
开发方式:耦合式开发(前后端会黏在一起的开发模式,模版引擎类似于提供了mvc中v的操作),在模版引擎中的模版中,会既有前端代码,又有后端代码。其最终的体现还是html文件
7.1、介绍
在一个web应用程序中,如果只是使用服务器端代码来编写客户端html代码,前后端不分离,那么会造成很大的工作量,而且写出来的代码会比较难以阅读和维护。如果只是使用客户端的静态的HTML文件,那么后端的逻辑也会比较难以融入到客户端的HTML代码中。为了便于维护,且使后端逻辑能够比较好的融入前端的HTML代码中,同时便于维护,很多第三方开发者就开发出了各种Nodejs模板引擎,其中比较常用的就是Jade/Pug、Ejs和art-template 等模板引擎。
目的:使后端逻辑能够比较好的融入前端的HTML代码中,同时便于维护
7.2、art-template
网址:
-
http://aui.github.io/art-template/zh-cn/
-
http://aui.github.io/art-template/express/
art-template 是一个简约、超快的模板引擎。
模板引擎渲染速度测试:

特性
-
拥有接近 JavaScript 渲染(DOM操作)极限的的性能(快)
-
调试友好:语法、运行时错误日志精确到模板所在行;支持在模板文件上打断点(Webpack Loader)
-
支持 Express、Koa、Webpack
-
支持模板继承(布局)与子模板(引入包含)
-
浏览器版本仅 6KB 大小
7.3、安装与配置
在express项目中通过npm来进行安装:
# 安装
npm i -S art-template express-art-template
# 安装所需要的依赖
// 模板引擎配置
// 指定art-template模板,并指定模块后缀为.html
app.engine('html', require('express-art-template'));
// 指定模板视图路径
app.set('views', path.join(__dirname, 'views'));
// 省略指定模块文件后缀后名称(可选,在渲染时可以省略的后缀)
app.set('view engine', 'html')
7.4、使用语法
art-template 支持**标准语法与原始语法**。标准语法可以让模板易读写,而原始语法拥有强大的逻辑表达能力。标准语法支持基本模板语法以及基本 JavaScript 表达式;原始语法支持任意 JavaScript 语句,这和 Ejs一样。
- 使用art-template展示一个视图(html文件)
- 将视图放入views目录下(允许分目录)
- 编写代码,展示视图的方式是
res.redner(文件的路径)
app.get('/', (req, res) => {
// 输出视图
res.render('404.html')
})
- 控制层返回数据(在js控制层中赋值变量到视图中)
app.get(uri,(req,res)=>{
res.render(模板,{
username: '张三',
age: 25,
gender: '女',
hobby: ['篮球','乒乓球','羽毛球']
})
})
- 模板视图层输出数据
在视图层中,使用art-template中的插值表达式完成数据的显示
{
{ username }}
<%= username %>
在默认情况下,上述输出方式不能将带有HTML标记的内容让浏览器解析,只会原样输出。如果需要将HTML标记让浏览器,则请使用下述方式输出数据:
{
{@ username}}
<%- username %>
- 条件判断
{
{if 条件}} … {
{else if 条件}} … {
{/if}}
<%if (条件){%> … <%}else if (条件){%> … <%}%>
案例:输出年龄,判断年龄的阶段(18岁以下未成年,18-30青年,30+老年)
思路:先写原生JavaScript的判断操作,然后转化,转化思路,去掉原先每一行的左{右},然后加上左{ {右}},最后在最后一行加上结束标记“{ {/if}}”
<p>当前的年龄是:{
{age}}p>
<div>
{
{if (age < 18)}}
未成年
{
{else if (age >= 18 && age < 30)}}
中年
{
{else}}
老年
{
{/if}}
<br>
<%if(age < 18){%>
未成年
<%}else if(age >= 18 && age < 30){%>
中年
<%}else{%>
老年
<%}%>
div>
- 循环
{
{each 循环的数据}}
{
{$index}} {
{$value}}
{
{/each}}
{
{each 循环的数据 val key}}
{
{key}} {
{val}}
{
{/each}}
<% for(var i = 0; i < target.length; i++){ %>
<%= i %> <%= target[i] %>
<% } %>
如果使用默认的键、值的名字(index,value)则其前面的
$一定要写!一定要写!!!如果使用的自定义的键、值的名字,则前面的
$一定不能写!!不能写!!
<h3>循环输出h3>
{
{each hobbies}}
{
{$index}}-{
{$value}}<br/>
{
{/each}}
{
{each hobbies val key}}
{
{key}}-{
{val}}<br/>
{
{/each}}
- 模板包含
在一个模板文件中引入另外一个模板文件。
{
{include '被引入文件路径'}}
<% include('被引入文件路径') %>
注:
- 如果是当前路径下的一定要写
./,不写则从磁盘根下开始寻找- 被include的文件后缀名默认为
.art,如果不是请勿省略- 在子模板中最好不要有html、head和body标签(否则容易出现样式错误的问题)
- 模板布局/模版继承
应用场景:主要应用在多个页面有重复布局的场景下,例如“上中下”布局,一般上与下是固定的,变化的是中间的部分。
思想:把所有公共的地方写在一个文件中。
布局文件layout.html(父/公共页面)
例如在vue中,如果见到
Layout.vue,在react中见到Layout.jsx或者Layout.js,毫无疑问,这些文件就是存放公共的页面的内容的布局文件。
<html>
<head>
<meta charset="utf-8">
<title>{
{block 'title'}}My Site{
{/block}}title>
head>
<body>
{
{block 'content'}}{
{/block}}
body>
html>
需要进行布局的文件(子/填坑)
{
{extend './layout.html'}}
{
{block 'title'}}首页{
{/block}}
{
{block 'content'}}
<p>This is just an awesome page.p>
{
{/block}}
注:渲染需要进行布局的文件后,将自动应用布局骨架
作业:使用mongoose+arttemplate完成如下页面及功能
- 查询并展示如下列表
- 实现编辑功能
- 实现删除功能
- 实现分页功能

附录:
- 布局在线实现:https://www.bootcss.com/p/layoutit/
- 需要引入的css文件:https://www.bootcss.com/p/layoutit/css/bootstrap-combined.min.css
五、综合案例
1、关于jwt
Json web token(JWT),是基于token(令牌)的鉴权机制,类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或者会话信息,为应用的扩展提供了便利。JWT具备以下几个优点:
-
因json的通用性,所以JWT是可以进行跨语言
-
JWT可以在自身存储一些其他业务逻辑所必要的非敏感信息
-
便于传输,jwt的构成非常简单,字节占用很小,所以它是非常便于传输的
-
它不需要在服务端保存会话信息,所以它非常适合应用在前后端分离的项目上
使用JWT进行鉴权的工作流程如下(重点):
- 用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息(查数据库)
- 服务器通过验证发送给用户一个token(令牌)
- 客户端存储token(Vuex+localStorage),并在每次请求时附送上这个token值
- 服务端验证token值,并返回数据

JWT是由三段信息构成的(头部、载荷、签名),将这三部分使用.连接在一起就组成了JWT字符串,形如:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiIsImp0aSI6IjNmMmc1N2E5MmFhIn0.eyJpYXQiOjE1NTk1Mjk1MjksImlzcyI6Imh0dHA6XC9cL3d3dy5weWcuY29tIiwiYXVkIjoiaHR0cDpcL1wvd3d3LnB5Zy5jb20iLCJuYmYiOjE1NTk1Mjk1MjgsImV4cCI6MTU1OTUzMzEyOSwianRpIjoiM2YyZzU3YTkyYWEiLCJ1c2VyX2lkIjoxfQ.4BaThL6_TbIMBGLIWZgpnoDQ-JlAjzbiK3y3BcvNiGI
其中:
- 头部(header),包含了两(可以更多)部分信息,分别是类型的声明和所使用的加密算法。
一个完整的头部就像下面的JSON:
{
'typ': 'JWT',
'alg': 'HS256'
}
然后将头部进行base64加密/编码(该加密是可以对称解密的),这就得到了jwt的第一部分。
- 载荷(payload)(body),载荷就是存放有效信息的地方。这些有效信息包含三个部分
- 标准中约定声明(建议但不强制)
- 签发人
- 使用者
- 签发时间
- 有效期
- …
- 公共的声明
- 私有的声明
- 标准中约定声明(建议但不强制)
定义一个payload:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
依旧进行base64加密,这就得到了jwt的第二部分。
- 签名(signature),这个签证信息由三部分组成:
- 经过base64编码后的
- header
- payload
- secret(就是一个字符串,自己定义,值是什么无所谓)
- 经过base64编码后的
例如:
var encodedString = base64UrlEncode(header) + '.' + base64UrlEncode(payload);
var signature = HMACSHA256(encodedString, 'secret');
这样就得到了jwt的第三部分。
var jwt = encodedString + '.' + base64UrlEncode(signature);
最终将三部分信息通过.进行连接就得到了最终的jwt字符串。后续不需要自己去写jwt怎么生成的。因此,此流程理解即可。
需要注意的是
- secret是保存在服务器端的
- jwt的签发生成也是在服务器端的
- secret是用来进行jwt的签发和jwt的验证
所以,secret它就是服务端的私钥,在任何场景都不应该泄露出去。一旦其他人(包括客户端的用户)得知这个secret,那就意味着他们可以自我签发jwt,接口就没有安全性可言了。
2、案例
2.1、准备
npm init -y
npm i -S express md5 mongoose jsonwebtoken cors
# md5:加密的模块
# jsonwebtoken:签发和验证jwt令牌的模块
# cors:解决跨域的中间件
在mongodb中创建一个库:maizuo
> use maizuo
数据表里后续大致有以下几个用户信息:
- 用户名:username
- 密码:password
- 手机号:mobile
- 用户id:user_id
- 头像:head_icon
创建文件src/index.js,编写基本的结构性代码:
const express = require("express");
const md5 = require("md5");
const mongoose = require("mongoose");
const jsonwebtoken = require("jsonwebtoken");
const cors = require("cors");
const secret = "KLJHmfmgmKHHJklyy67855RFJghkkTG";
// 使用cors解决跨域问题
app.use(cors());
const app = express();
// 连接mongodb
mongoose.connect("mongodb://127.0.0.1:27017/maizuo", {
useNewUrlParser: true,
useUnifiedTopology: true,
});
// 创建Schema
const UserSchema = new mongoose.Schema({
username: {
type: String,
required: true,
minlength: 4,
// 要求用户名唯一
unique:true
},
password: {
type: String,
required: true,
},
mobile: {
type: String,
required: true,
},
user_id: {
type: String,
required: true,
},
head_icon: {
type: String,
required: true,
},
});
// 创建模型
const Model = mongoose.model("User", UserSchema, "users");
// 用户注册
app.post("/api/v1/user/register", (req, res) => {
// 注册的业务逻辑....
});
// 用户登录
app.post("/api/v1/user/login", (req, res) => {
// 登录的业务逻辑....
});
// 用户信息获取
app.get("/api/v1/user/getUserInfo", (req, res) => {
// 获取用户信息的业务逻辑....
});
app.listen(3000, () => {
console.log(`Server is Listening on 3000`);
});
2.2、用户注册
思考:密码如何存储?【加密的结果】
// 封装中间件:用于对密码进行加密
function passwdCrypt(req, res, next) {
// 密码为req.body.password
// 加料加密/加盐加密
req.body.password = md5(md5(req.body.password).substr(6, 23));
next();
}
// 用户注册
app.post("/api/v1/user/register", passwdCrypt, (req, res) => {
// 注册的业务逻辑....
// 也可以在这里考虑加上判断用户名是否存在
// console.log(req.body);
Model.insertMany(req.body).then((ret) => {
// 判断是否注册成功
if(ret.length){
res.json({
errno: 0,
msg: "注册成功!"
})
}else{
res.json({
errno: 1000,
msg: "注册失败!"
})
}
});
});
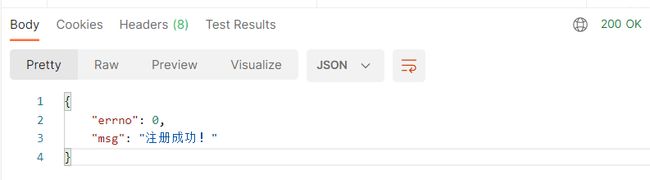
postman测试结果:
2.3、用户登录
流程:表单用户输入用户名和密码,然后后端验证
// 用户登录
app.post("/api/v1/user/login", passwdCrypt, (req, res) => {
// 登录的业务逻辑....
// 获取用户的登录信息
// console.log(req.body);
Model.findOne(req.body).then((ret) => {
if (ret) {
// 登录合法,发令牌【将之前写cookie的操作改成了令牌的签发】
// 语法:jsonwebtoken.sign(载荷,密钥)
const jwt = jsonwebtoken.sign(
{
// 过期时间,expire,单位是秒
exp: parseInt((Date.now() / 1000) + 86400),
// 用户id
uid: ret.user_id,
},
secret
);
res.json({
errno: 0,
msg: "登录成功!",
jwt
});
} else {
// 用户名或密码错误
res.json({
errno: 2000,
msg: "用户名或密码错误!",
});
}
});
});
2.4、用户信息获取
将登录成功后获取的令牌,在postman工具的头信息中添加以供测试:

// 封装中间件:验证jwt令牌
function checkJwt(req, res, next) {
// 获取token
const token = req.headers.authorization;
// 令牌验证的会抛异常
// jsonwebtoken.verify(验证的token,secret)
const payload = jsonwebtoken.verify(token, secret);
// 将业务需要的数据挂到req上
const jwt = jsonwebtoken.sign(
{
// 过期时间,expire,单位是秒
exp: parseInt(Date.now() / 1000 + 86400),
// 用户id
uid: payload.uid,
},
secret
);
req.yewu = {
};
req.yewu.uid = payload.uid;
req.yewu.jwt = jwt;
next();
}
// 用户信息获取
app.get("/api/v1/user/getUserInfo", checkJwt, (req, res) => {
// 获取用户信息的业务逻辑....
Model.findOne({
user_id: req.yewu.uid }).then((ret) => {
if (ret) {
// 用户查询正常
res.json({
errno: 0,
msg: "用户信息获取成功!",
user_info: {
username: ret.username,
// 手机号脱敏
// mobile: ret.mobile.substr(0,3) + "****" + ret.mobile.substr(-4),
mobile: ret.mobile.replace(/(\d{3})\d{4}(\d{4})/,"$1****$2"),
user_id: ret.user_id,
head_icon: ret.head_icon,
},
// 刷新一次token
jwt: req.yewu.jwt
});
} else {
// 查不到用户
res.json({
errno: 3000,
msg: "你号没了!",
});
}
});
});
最后显示的效果:

2.5、代码的模块化
核心:拆完之后还要可以正常运行
85487643)]
2.3、用户登录
流程:表单用户输入用户名和密码,然后后端验证
// 用户登录
app.post("/api/v1/user/login", passwdCrypt, (req, res) => {
// 登录的业务逻辑....
// 获取用户的登录信息
// console.log(req.body);
Model.findOne(req.body).then((ret) => {
if (ret) {
// 登录合法,发令牌【将之前写cookie的操作改成了令牌的签发】
// 语法:jsonwebtoken.sign(载荷,密钥)
const jwt = jsonwebtoken.sign(
{
// 过期时间,expire,单位是秒
exp: parseInt((Date.now() / 1000) + 86400),
// 用户id
uid: ret.user_id,
},
secret
);
res.json({
errno: 0,
msg: "登录成功!",
jwt
});
} else {
// 用户名或密码错误
res.json({
errno: 2000,
msg: "用户名或密码错误!",
});
}
});
});
2.4、用户信息获取
将登录成功后获取的令牌,在postman工具的头信息中添加以供测试:
[外链图片转存中…(img-a5fT2aIR-1627285487644)]
// 封装中间件:验证jwt令牌
function checkJwt(req, res, next) {
// 获取token
const token = req.headers.authorization;
// 令牌验证的会抛异常
// jsonwebtoken.verify(验证的token,secret)
const payload = jsonwebtoken.verify(token, secret);
// 将业务需要的数据挂到req上
const jwt = jsonwebtoken.sign(
{
// 过期时间,expire,单位是秒
exp: parseInt(Date.now() / 1000 + 86400),
// 用户id
uid: payload.uid,
},
secret
);
req.yewu = {
};
req.yewu.uid = payload.uid;
req.yewu.jwt = jwt;
next();
}
// 用户信息获取
app.get("/api/v1/user/getUserInfo", checkJwt, (req, res) => {
// 获取用户信息的业务逻辑....
Model.findOne({
user_id: req.yewu.uid }).then((ret) => {
if (ret) {
// 用户查询正常
res.json({
errno: 0,
msg: "用户信息获取成功!",
user_info: {
username: ret.username,
// 手机号脱敏
// mobile: ret.mobile.substr(0,3) + "****" + ret.mobile.substr(-4),
mobile: ret.mobile.replace(/(\d{3})\d{4}(\d{4})/,"$1****$2"),
user_id: ret.user_id,
head_icon: ret.head_icon,
},
// 刷新一次token
jwt: req.yewu.jwt
});
} else {
// 查不到用户
res.json({
errno: 3000,
msg: "你号没了!",
});
}
});
});
最后显示的效果:
[外链图片转存中…(img-3A0HMvBj-1627285487645)]
2.5、代码的模块化
核心:拆完之后还要可以正常运行