《Python 深度学习》刷书笔记 Chapter 5 Part-3 使用预训练的卷积神经网络(dogs-vs-cats)
文章目录
- 特征提取
-
- 5-16 将VGG16卷积基实例化
- 5-17 使用预训练的卷积基提取特征
- 5-18 定义训练密集连接分类器
- 5-19 绘制结果
- 5-20 在卷积上添加一个密集连接分类器
- 5-21 利用冻结卷积基端到端地训练模型
- 微调模型
-
- 模型3
- 5-22 冻结直到某一层的所有层
- 5-23 微调模型
- 5-24 使得曲线变平滑
- 模型准率以及损失趋势
- 图片数据平滑化
- 调整后的图片
-
- 显示最终训练结果
- 总结
- 写在最后
特征提取
图像分类一般包含两个部分
- 一系列的池化层和卷积层(卷积基)
- 密集连接分类器(全连接层)
特征提取的定义: 取出在第一部分训练好的卷积基,在上面运行新的数据,再在上面输出一个新的分类器
重复使用卷积基的原因: 卷积基所学到的图像特征可能更加统一,无论面对怎样的视觉问题,这种特征提取都是有用的,其表现了图像的位置信息
5-16 将VGG16卷积基实例化
from keras.applications import VGG16
conv_base = VGG16(weights = 'imagenet', # 指定模型初始化的权重检查点
include_top = False, # 指定模型是否包含密集链接分类器
input_shape = (150, 150, 3))
conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
5-17 使用预训练的卷积基提取特征
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
# 目录
base_dir = r'E:\code\PythonDeep\DataSet\sampledataSet2'
train_dir = os.path.join(base_dir, "train")
validation_dir = os.path.join(base_dir, "validation")
test_dir = os.path.join(base_dir, "test")
# 设置训练集
datagen = ImageDataGenerator(rescale = 1./255)
batch_size = 20
# 定义提取函数
def extract_features(directory, sample_count):
features = np.zeros(shape = (sample_count, 4, 4, 512))
labels = np.zeros(shape = (sample_count))
generator = datagen.flow_from_directory(directory,
target_size = (150, 150),
batch_size = batch_size,
class_mode = 'binary')
i = 0
for input_batch, labels_batch in generator:
features_batch = conv_base.predict(input_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
# 提取操作
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
# 将数据变形
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
5-18 定义训练密集连接分类器
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation = 'relu', input_dim = 4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation = 'sigmoid'))
# 编译模型
model.compile(optimizer = optimizers.RMSprop(lr = 2e-5),
loss = 'binary_crossentropy',
metrics = ['acc'])
# 训练模型
history = model.fit(train_features,
train_labels,
epochs = 30,
batch_size = 20,
validation_data = (validation_features, validation_labels))
Train on 2000 samples, validate on 1000 samples
Epoch 1/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.5998 - acc: 0.6785 - val_loss: 0.4559 - val_acc: 0.8320
Epoch 2/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.4227 - acc: 0.8205 - val_loss: 0.3670 - val_acc: 0.8600
Epoch 3/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3508 - acc: 0.8470 - val_loss: 0.3310 - val_acc: 0.8640
Epoch 4/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3114 - acc: 0.8770 - val_loss: 0.3012 - val_acc: 0.8890
Epoch 5/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.2883 - acc: 0.8780 - val_loss: 0.2829 - val_acc: 0.8880
Epoch 6/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.2590 - acc: 0.9010 - val_loss: 0.2731 - val_acc: 0.9010
Epoch 7/30
2000/2000 [==============================] - 5s 3ms/step - loss: 0.2430 - acc: 0.9045 - val_loss: 0.2627 - val_acc: 0.8990
Epoch 8/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.2249 - acc: 0.9150 - val_loss: 0.2565 - val_acc: 0.8990
Epoch 9/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.2182 - acc: 0.9135 - val_loss: 0.2521 - val_acc: 0.9030
Epoch 10/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.2072 - acc: 0.9245 - val_loss: 0.2515 - val_acc: 0.8980
Epoch 11/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.1951 - acc: 0.9325 - val_loss: 0.2443 - val_acc: 0.9080
Epoch 12/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.1883 - acc: 0.9275 - val_loss: 0.2413 - val_acc: 0.9040
Epoch 13/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1790 - acc: 0.9410 - val_loss: 0.2400 - val_acc: 0.9020
Epoch 14/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1733 - acc: 0.9315 - val_loss: 0.2379 - val_acc: 0.9060
Epoch 15/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1611 - acc: 0.9435 - val_loss: 0.2366 - val_acc: 0.9080
Epoch 16/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1564 - acc: 0.9460 - val_loss: 0.2373 - val_acc: 0.9050
Epoch 17/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.1434 - acc: 0.9520 - val_loss: 0.2365 - val_acc: 0.9040
Epoch 18/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1458 - acc: 0.9470 - val_loss: 0.2328 - val_acc: 0.9060
Epoch 19/30
2000/2000 [==============================] - 3s 2ms/step - loss: 0.1385 - acc: 0.9535 - val_loss: 0.2331 - val_acc: 0.9070
Epoch 20/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1307 - acc: 0.9545 - val_loss: 0.2327 - val_acc: 0.9040
Epoch 21/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1285 - acc: 0.9575 - val_loss: 0.2344 - val_acc: 0.9050
Epoch 22/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1167 - acc: 0.9580 - val_loss: 0.2414 - val_acc: 0.8990
Epoch 23/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1146 - acc: 0.9615 - val_loss: 0.2337 - val_acc: 0.9030
Epoch 24/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1091 - acc: 0.9650 - val_loss: 0.2351 - val_acc: 0.9010
Epoch 25/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.1038 - acc: 0.9650 - val_loss: 0.2347 - val_acc: 0.9010
Epoch 26/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.0972 - acc: 0.9710 - val_loss: 0.2410 - val_acc: 0.9040
Epoch 27/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.0998 - acc: 0.9680 - val_loss: 0.2376 - val_acc: 0.9050
Epoch 28/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.0963 - acc: 0.9700 - val_loss: 0.2350 - val_acc: 0.9040
Epoch 29/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.0897 - acc: 0.9745 - val_loss: 0.2374 - val_acc: 0.9040
Epoch 30/30
2000/2000 [==============================] - 3s 1ms/step - loss: 0.0914 - acc: 0.9700 - val_loss: 0.2375 - val_acc: 0.9010
5-19 绘制结果
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and Validation loss')
plt.show()
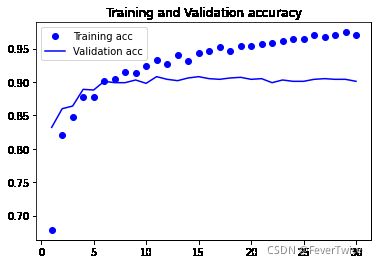

5-20 在卷积上添加一个密集连接分类器
from keras import models
from keras import layers
model_2 = models.Sequential()
model_2.add(conv_base)
model_2.add(layers.Flatten())
model_2.add(layers.Dense(256, activation = 'relu'))
model_2.add(layers.Dense(1, activation = 'sigmoid'))
model.summary()
# 对比冻结前后
conv_base.trainable = True
print('This is the number of trainable weights before freezing the conv base', len(model_2.trainable_weights))
conv_base.trainable = False
print('This is the number of trainable weights after freezing the conv base', len(model_2.trainable_weights))
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 256) 2097408
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_4 (Dense) (None, 1) 257
=================================================================
Total params: 2,097,665
Trainable params: 2,097,665
Non-trainable params: 0
_________________________________________________________________
This is the number of trainable weights before freezing the conv base 30
This is the number of trainable weights after freezing the conv base 4
5-21 利用冻结卷积基端到端地训练模型
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
# 增强数据
train_datagen= ImageDataGenerator(rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
# 注意:训练集数据不能被增强
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 目录
target_size = (150, 150), # 图片尺寸
batch_size = 20,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150, 150),
batch_size = 20,
class_mode = 'binary')
model_2.compile(loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop(lr=2e-5),
metrics = ['acc'])
history = model_2.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50,
verbose = 2)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/30
- 157s - loss: 0.6031 - acc: 0.6705 - val_loss: 0.6387 - val_acc: 0.8130
Epoch 2/30
- 168s - loss: 0.4890 - acc: 0.7855 - val_loss: 0.4977 - val_acc: 0.8490
Epoch 3/30
- 160s - loss: 0.4392 - acc: 0.7960 - val_loss: 0.1796 - val_acc: 0.8660
Epoch 4/30
- 161s - loss: 0.4029 - acc: 0.8325 - val_loss: 0.3445 - val_acc: 0.8760
Epoch 5/30
- 147s - loss: 0.3785 - acc: 0.8350 - val_loss: 0.3361 - val_acc: 0.8820
Epoch 6/30
- 147s - loss: 0.3677 - acc: 0.8380 - val_loss: 0.4432 - val_acc: 0.8760
Epoch 7/30
- 145s - loss: 0.3485 - acc: 0.8440 - val_loss: 0.3113 - val_acc: 0.8720
Epoch 8/30
- 148s - loss: 0.3523 - acc: 0.8420 - val_loss: 0.2281 - val_acc: 0.8910
Epoch 9/30
- 150s - loss: 0.3359 - acc: 0.8515 - val_loss: 0.1809 - val_acc: 0.8930
Epoch 10/30
- 153s - loss: 0.3366 - acc: 0.8505 - val_loss: 0.2247 - val_acc: 0.8750
Epoch 11/30
- 146s - loss: 0.3256 - acc: 0.8645 - val_loss: 0.4438 - val_acc: 0.8890
Epoch 12/30
- 148s - loss: 0.3294 - acc: 0.8565 - val_loss: 0.4329 - val_acc: 0.8910
Epoch 13/30
- 148s - loss: 0.3277 - acc: 0.8480 - val_loss: 0.3195 - val_acc: 0.8990
Epoch 14/30
- 148s - loss: 0.3169 - acc: 0.8660 - val_loss: 0.4066 - val_acc: 0.8770
Epoch 15/30
- 146s - loss: 0.3141 - acc: 0.8705 - val_loss: 0.3388 - val_acc: 0.8970
Epoch 16/30
- 146s - loss: 0.3074 - acc: 0.8680 - val_loss: 0.1526 - val_acc: 0.9020
Epoch 17/30
- 146s - loss: 0.2933 - acc: 0.8810 - val_loss: 0.3873 - val_acc: 0.8810
Epoch 18/30
- 150s - loss: 0.3111 - acc: 0.8625 - val_loss: 0.2633 - val_acc: 0.8990
Epoch 19/30
- 152s - loss: 0.2952 - acc: 0.8755 - val_loss: 0.2279 - val_acc: 0.9000
Epoch 20/30
- 151s - loss: 0.3073 - acc: 0.8610 - val_loss: 0.1034 - val_acc: 0.9020
Epoch 21/30
- 145s - loss: 0.3008 - acc: 0.8760 - val_loss: 0.4831 - val_acc: 0.8990
Epoch 22/30
- 156s - loss: 0.2931 - acc: 0.8695 - val_loss: 0.1807 - val_acc: 0.9020
Epoch 23/30
- 147s - loss: 0.2963 - acc: 0.8680 - val_loss: 0.1510 - val_acc: 0.9020
Epoch 24/30
- 147s - loss: 0.2927 - acc: 0.8765 - val_loss: 0.3414 - val_acc: 0.9040
Epoch 25/30
- 145s - loss: 0.2850 - acc: 0.8760 - val_loss: 0.2053 - val_acc: 0.9050
Epoch 26/30
- 146s - loss: 0.2820 - acc: 0.8800 - val_loss: 0.3000 - val_acc: 0.9000
Epoch 27/30
- 145s - loss: 0.2833 - acc: 0.8740 - val_loss: 0.0933 - val_acc: 0.8930
Epoch 28/30
- 146s - loss: 0.2807 - acc: 0.8895 - val_loss: 0.2153 - val_acc: 0.8950
Epoch 29/30
- 146s - loss: 0.2724 - acc: 0.8860 - val_loss: 0.2057 - val_acc: 0.9080
Epoch 30/30
- 146s - loss: 0.2804 - acc: 0.8815 - val_loss: 0.2843 - val_acc: 0.9060
# 保存模型
model.save('cats_and_dogs_small_3.h5')
# 画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


微调模型
另一种广泛使用模型复用地方法是模型微调,将其与特征相互补充,用于特征的提取,将模型后面几层“解冻”,然后加入全连接层进行训练
关于为什么不微调更多层,有以下几种解释
- 卷积层种更靠近底部的编码层是更加通用的特征,更高层应该是更加深入化的特征
- 训练的参数越大,过拟合的风险就越大
模型3
我们将这个模型与前面的两个模型区分开,作为模型3
注: 这里与原书不同,我是直接从新开始训练的,故准确率有一些差异
# 模型3
from keras import models
from keras import layers
model_3 = models.Sequential()
model_3.add(conv_base)
model_3.add(layers.Flatten())
model_3.add(layers.Dense(256, activation = 'relu'))
model_3.add(layers.Dense(1, activation = 'sigmoid'))
model_3.summary()
# 对比冻结前后
conv_base.trainable = True
print('This is the number of trainable weights before freezing the conv base', len(model_3.trainable_weights))
conv_base.trainable = False
print('This is the number of trainable weights after freezing the conv base', len(model_3.trainable_weights))
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
# 增强数据
train_datagen= ImageDataGenerator(rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
# 注意:训练集数据不能被增强
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 目录
target_size = (150, 150), # 图片尺寸
batch_size = 20,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150, 150),
batch_size = 20,
class_mode = 'binary')
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_3 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_9 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_10 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 9,177,089
Non-trainable params: 7,635,264
_________________________________________________________________
This is the number of trainable weights before freezing the conv base 10
This is the number of trainable weights after freezing the conv base 4
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
5-22 冻结直到某一层的所有层
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
5-23 微调模型
model_3.compile(loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop(lr = 1e-5),
metrics = ['acc'])
# 训练模型
history = model_3.fit_generator(train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50)
# 保存模型
model_3.save('cats_and_dogs_small_model_3.h5')
Epoch 1/100
100/100 [==============================] - 190s 2s/step - loss: 0.3557 - acc: 0.8475 - val_loss: 0.1021 - val_acc: 0.8990
Epoch 2/100
100/100 [==============================] - 187s 2s/step - loss: 0.2685 - acc: 0.8905 - val_loss: 0.2160 - val_acc: 0.9100
Epoch 3/100
100/100 [==============================] - 186s 2s/step - loss: 0.2451 - acc: 0.8950 - val_loss: 0.4439 - val_acc: 0.9260
Epoch 4/100
100/100 [==============================] - 188s 2s/step - loss: 0.2354 - acc: 0.9005 - val_loss: 0.0374 - val_acc: 0.9270
Epoch 5/100
100/100 [==============================] - 186s 2s/step - loss: 0.2251 - acc: 0.9020 - val_loss: 0.1117 - val_acc: 0.9330
Epoch 6/100
100/100 [==============================] - 187s 2s/step - loss: 0.2108 - acc: 0.9165 - val_loss: 0.1045 - val_acc: 0.9260
Epoch 7/100
100/100 [==============================] - 195s 2s/step - loss: 0.1959 - acc: 0.9150 - val_loss: 0.1455 - val_acc: 0.9360
Epoch 8/100
100/100 [==============================] - 196s 2s/step - loss: 0.1907 - acc: 0.9155 - val_loss: 0.0797 - val_acc: 0.9300
Epoch 9/100
100/100 [==============================] - 187s 2s/step - loss: 0.1857 - acc: 0.9235 - val_loss: 0.0491 - val_acc: 0.9280
Epoch 10/100
100/100 [==============================] - 187s 2s/step - loss: 0.1695 - acc: 0.9290 - val_loss: 0.0117 - val_acc: 0.9330
Epoch 11/100
100/100 [==============================] - 188s 2s/step - loss: 0.1612 - acc: 0.9345 - val_loss: 0.1458 - val_acc: 0.9370
Epoch 12/100
100/100 [==============================] - 188s 2s/step - loss: 0.1573 - acc: 0.9425 - val_loss: 0.1091 - val_acc: 0.9370
Epoch 13/100
100/100 [==============================] - 190s 2s/step - loss: 0.1464 - acc: 0.9440 - val_loss: 0.2060 - val_acc: 0.9330
Epoch 14/100
100/100 [==============================] - 185s 2s/step - loss: 0.1511 - acc: 0.9375 - val_loss: 0.2178 - val_acc: 0.9290
Epoch 15/100
100/100 [==============================] - 185s 2s/step - loss: 0.1399 - acc: 0.9455 - val_loss: 0.0173 - val_acc: 0.9290
Epoch 16/100
100/100 [==============================] - 189s 2s/step - loss: 0.1320 - acc: 0.9475 - val_loss: 0.0358 - val_acc: 0.9010
Epoch 17/100
100/100 [==============================] - 191s 2s/step - loss: 0.1434 - acc: 0.9440 - val_loss: 0.0291 - val_acc: 0.9250
Epoch 18/100
100/100 [==============================] - 185s 2s/step - loss: 0.1285 - acc: 0.9520 - val_loss: 0.4321 - val_acc: 0.9130
Epoch 19/100
100/100 [==============================] - 184s 2s/step - loss: 0.1183 - acc: 0.9490 - val_loss: 0.0125 - val_acc: 0.9380
Epoch 20/100
100/100 [==============================] - 183s 2s/step - loss: 0.1179 - acc: 0.9545 - val_loss: 0.2323 - val_acc: 0.9340
Epoch 21/100
100/100 [==============================] - 184s 2s/step - loss: 0.1026 - acc: 0.9665 - val_loss: 0.1341 - val_acc: 0.9320
Epoch 22/100
100/100 [==============================] - 182s 2s/step - loss: 0.1169 - acc: 0.9500 - val_loss: 0.0638 - val_acc: 0.9370
Epoch 23/100
100/100 [==============================] - 183s 2s/step - loss: 0.1017 - acc: 0.9580 - val_loss: 0.1406 - val_acc: 0.9260
Epoch 24/100
100/100 [==============================] - 182s 2s/step - loss: 0.1105 - acc: 0.9560 - val_loss: 0.0841 - val_acc: 0.9400
Epoch 25/100
100/100 [==============================] - 183s 2s/step - loss: 0.0941 - acc: 0.9660 - val_loss: 0.6658 - val_acc: 0.9280
Epoch 26/100
100/100 [==============================] - 182s 2s/step - loss: 0.1093 - acc: 0.9530 - val_loss: 0.0595 - val_acc: 0.9350
Epoch 27/100
100/100 [==============================] - 181s 2s/step - loss: 0.0887 - acc: 0.9655 - val_loss: 0.0744 - val_acc: 0.9380
Epoch 28/100
100/100 [==============================] - 183s 2s/step - loss: 0.0910 - acc: 0.9675 - val_loss: 0.0314 - val_acc: 0.9210
Epoch 29/100
100/100 [==============================] - 182s 2s/step - loss: 0.0909 - acc: 0.9655 - val_loss: 0.3329 - val_acc: 0.9410
Epoch 30/100
100/100 [==============================] - 182s 2s/step - loss: 0.0644 - acc: 0.9790 - val_loss: 0.0289 - val_acc: 0.9300
Epoch 31/100
100/100 [==============================] - 182s 2s/step - loss: 0.0839 - acc: 0.9660 - val_loss: 0.1584 - val_acc: 0.9340
Epoch 32/100
100/100 [==============================] - 183s 2s/step - loss: 0.0726 - acc: 0.9685 - val_loss: 0.1754 - val_acc: 0.9360
Epoch 33/100
100/100 [==============================] - 185s 2s/step - loss: 0.0717 - acc: 0.9705 - val_loss: 0.1397 - val_acc: 0.9380
Epoch 34/100
100/100 [==============================] - 182s 2s/step - loss: 0.0942 - acc: 0.9655 - val_loss: 0.1882 - val_acc: 0.9460
Epoch 35/100
100/100 [==============================] - 182s 2s/step - loss: 0.0709 - acc: 0.9735 - val_loss: 0.0086 - val_acc: 0.9390
Epoch 36/100
100/100 [==============================] - 183s 2s/step - loss: 0.0661 - acc: 0.9770 - val_loss: 0.0542 - val_acc: 0.9260
Epoch 37/100
100/100 [==============================] - 183s 2s/step - loss: 0.0774 - acc: 0.9685 - val_loss: 0.0794 - val_acc: 0.9360
Epoch 38/100
100/100 [==============================] - 190s 2s/step - loss: 0.0640 - acc: 0.9775 - val_loss: 0.4202 - val_acc: 0.9300
Epoch 39/100
100/100 [==============================] - 188s 2s/step - loss: 0.0599 - acc: 0.9755 - val_loss: 0.0293 - val_acc: 0.9350
Epoch 40/100
100/100 [==============================] - 183s 2s/step - loss: 0.0549 - acc: 0.9785 - val_loss: 0.4010 - val_acc: 0.9340
Epoch 41/100
100/100 [==============================] - 184s 2s/step - loss: 0.0756 - acc: 0.9740 - val_loss: 0.1048 - val_acc: 0.9380
Epoch 42/100
100/100 [==============================] - 184s 2s/step - loss: 0.0628 - acc: 0.9780 - val_loss: 0.1143 - val_acc: 0.9380
Epoch 43/100
100/100 [==============================] - 183s 2s/step - loss: 0.0569 - acc: 0.9805 - val_loss: 0.1404 - val_acc: 0.9390
Epoch 44/100
100/100 [==============================] - 183s 2s/step - loss: 0.0646 - acc: 0.9740 - val_loss: 0.2518 - val_acc: 0.9210
Epoch 45/100
100/100 [==============================] - 184s 2s/step - loss: 0.0668 - acc: 0.9755 - val_loss: 0.0395 - val_acc: 0.9280
Epoch 46/100
100/100 [==============================] - 184s 2s/step - loss: 0.0638 - acc: 0.9745 - val_loss: 0.5453 - val_acc: 0.9370
Epoch 47/100
100/100 [==============================] - 183s 2s/step - loss: 0.0542 - acc: 0.9805 - val_loss: 0.0602 - val_acc: 0.9310
Epoch 48/100
100/100 [==============================] - 184s 2s/step - loss: 0.0460 - acc: 0.9845 - val_loss: 0.0033 - val_acc: 0.9350
Epoch 49/100
100/100 [==============================] - 185s 2s/step - loss: 0.0634 - acc: 0.9800 - val_loss: 0.0440 - val_acc: 0.9380
Epoch 50/100
100/100 [==============================] - 186s 2s/step - loss: 0.0542 - acc: 0.9780 - val_loss: 0.4446 - val_acc: 0.9390
Epoch 51/100
100/100 [==============================] - 186s 2s/step - loss: 0.0438 - acc: 0.9810 - val_loss: 0.0345 - val_acc: 0.9380
Epoch 52/100
100/100 [==============================] - 184s 2s/step - loss: 0.0383 - acc: 0.9865 - val_loss: 0.0236 - val_acc: 0.9410
Epoch 53/100
100/100 [==============================] - 186s 2s/step - loss: 0.0491 - acc: 0.9835 - val_loss: 0.9112 - val_acc: 0.9130
Epoch 54/100
100/100 [==============================] - 184s 2s/step - loss: 0.0520 - acc: 0.9800 - val_loss: 0.1400 - val_acc: 0.9400
Epoch 55/100
100/100 [==============================] - 187s 2s/step - loss: 0.0445 - acc: 0.9830 - val_loss: 0.1486 - val_acc: 0.9200
Epoch 56/100
100/100 [==============================] - 184s 2s/step - loss: 0.0424 - acc: 0.9840 - val_loss: 0.0021 - val_acc: 0.9340
Epoch 57/100
100/100 [==============================] - 185s 2s/step - loss: 0.0477 - acc: 0.9845 - val_loss: 0.1740 - val_acc: 0.9340
Epoch 58/100
100/100 [==============================] - 184s 2s/step - loss: 0.0503 - acc: 0.9805 - val_loss: 0.2252 - val_acc: 0.9410
Epoch 59/100
100/100 [==============================] - 190s 2s/step - loss: 0.0448 - acc: 0.9835 - val_loss: 0.5368 - val_acc: 0.9370
Epoch 60/100
100/100 [==============================] - 192s 2s/step - loss: 0.0475 - acc: 0.9825 - val_loss: 0.1248 - val_acc: 0.9250
Epoch 61/100
100/100 [==============================] - 185s 2s/step - loss: 0.0539 - acc: 0.9815 - val_loss: 8.9203e-06 - val_acc: 0.9360
Epoch 62/100
100/100 [==============================] - 184s 2s/step - loss: 0.0477 - acc: 0.9830 - val_loss: 0.2630 - val_acc: 0.9470
Epoch 63/100
100/100 [==============================] - 184s 2s/step - loss: 0.0434 - acc: 0.9845 - val_loss: 0.0139 - val_acc: 0.9320
Epoch 64/100
100/100 [==============================] - 184s 2s/step - loss: 0.0376 - acc: 0.9880 - val_loss: 0.0221 - val_acc: 0.9370
Epoch 65/100
100/100 [==============================] - 184s 2s/step - loss: 0.0333 - acc: 0.9865 - val_loss: 0.0837 - val_acc: 0.9390
Epoch 66/100
100/100 [==============================] - 185s 2s/step - loss: 0.0291 - acc: 0.9875 - val_loss: 0.2700 - val_acc: 0.9340
Epoch 67/100
100/100 [==============================] - 184s 2s/step - loss: 0.0452 - acc: 0.9845 - val_loss: 0.1057 - val_acc: 0.9260
Epoch 68/100
100/100 [==============================] - 183s 2s/step - loss: 0.0362 - acc: 0.9860 - val_loss: 0.7325 - val_acc: 0.9020
Epoch 69/100
100/100 [==============================] - 185s 2s/step - loss: 0.0416 - acc: 0.9865 - val_loss: 0.0521 - val_acc: 0.9290
Epoch 70/100
100/100 [==============================] - 184s 2s/step - loss: 0.0334 - acc: 0.9890 - val_loss: 0.1649 - val_acc: 0.9350
Epoch 71/100
100/100 [==============================] - 184s 2s/step - loss: 0.0377 - acc: 0.9870 - val_loss: 0.1268 - val_acc: 0.9370
Epoch 72/100
100/100 [==============================] - 185s 2s/step - loss: 0.0269 - acc: 0.9920 - val_loss: 0.1654 - val_acc: 0.9320
Epoch 73/100
100/100 [==============================] - 183s 2s/step - loss: 0.0297 - acc: 0.9895 - val_loss: 0.1947 - val_acc: 0.9320
Epoch 74/100
100/100 [==============================] - 185s 2s/step - loss: 0.0213 - acc: 0.9905 - val_loss: 0.1808 - val_acc: 0.9200
Epoch 75/100
100/100 [==============================] - 183s 2s/step - loss: 0.0298 - acc: 0.9910 - val_loss: 0.0030 - val_acc: 0.9320
Epoch 76/100
100/100 [==============================] - 185s 2s/step - loss: 0.0397 - acc: 0.9855 - val_loss: 0.6953 - val_acc: 0.9320
Epoch 77/100
100/100 [==============================] - 184s 2s/step - loss: 0.0328 - acc: 0.9880 - val_loss: 0.1312 - val_acc: 0.9380
Epoch 78/100
100/100 [==============================] - 184s 2s/step - loss: 0.0306 - acc: 0.9890 - val_loss: 0.5388 - val_acc: 0.9320
Epoch 79/100
100/100 [==============================] - 184s 2s/step - loss: 0.0304 - acc: 0.9905 - val_loss: 0.4356 - val_acc: 0.9270
Epoch 80/100
100/100 [==============================] - 186s 2s/step - loss: 0.0276 - acc: 0.9910 - val_loss: 0.0083 - val_acc: 0.9400
Epoch 81/100
100/100 [==============================] - 189s 2s/step - loss: 0.0324 - acc: 0.9890 - val_loss: 0.0740 - val_acc: 0.9300
Epoch 82/100
100/100 [==============================] - 186s 2s/step - loss: 0.0301 - acc: 0.9915 - val_loss: 1.3459 - val_acc: 0.9230
Epoch 83/100
100/100 [==============================] - 183s 2s/step - loss: 0.0328 - acc: 0.9890 - val_loss: 0.7568 - val_acc: 0.9400
Epoch 84/100
100/100 [==============================] - 184s 2s/step - loss: 0.0360 - acc: 0.9880 - val_loss: 0.3492 - val_acc: 0.9460
Epoch 85/100
100/100 [==============================] - 183s 2s/step - loss: 0.0456 - acc: 0.9870 - val_loss: 0.1622 - val_acc: 0.9430
Epoch 86/100
100/100 [==============================] - 182s 2s/step - loss: 0.0213 - acc: 0.9925 - val_loss: 0.2036 - val_acc: 0.9300
Epoch 87/100
100/100 [==============================] - 182s 2s/step - loss: 0.0290 - acc: 0.9895 - val_loss: 0.2388 - val_acc: 0.9390
Epoch 88/100
100/100 [==============================] - 182s 2s/step - loss: 0.0267 - acc: 0.9890 - val_loss: 0.2678 - val_acc: 0.9390
Epoch 89/100
100/100 [==============================] - 182s 2s/step - loss: 0.0311 - acc: 0.9865 - val_loss: 0.0209 - val_acc: 0.9380
Epoch 90/100
100/100 [==============================] - 183s 2s/step - loss: 0.0317 - acc: 0.9895 - val_loss: 0.3031 - val_acc: 0.9350
Epoch 91/100
100/100 [==============================] - 183s 2s/step - loss: 0.0236 - acc: 0.9885 - val_loss: 0.5610 - val_acc: 0.9340
Epoch 92/100
100/100 [==============================] - 184s 2s/step - loss: 0.0299 - acc: 0.9925 - val_loss: 1.0192 - val_acc: 0.9210
Epoch 93/100
100/100 [==============================] - 182s 2s/step - loss: 0.0266 - acc: 0.9895 - val_loss: 0.3322 - val_acc: 0.9320
Epoch 94/100
100/100 [==============================] - 182s 2s/step - loss: 0.0233 - acc: 0.9925 - val_loss: 0.5287 - val_acc: 0.9380
Epoch 95/100
100/100 [==============================] - 183s 2s/step - loss: 0.0190 - acc: 0.9925 - val_loss: 0.2976 - val_acc: 0.9370
Epoch 96/100
100/100 [==============================] - 182s 2s/step - loss: 0.0366 - acc: 0.9900 - val_loss: 0.3915 - val_acc: 0.9350
Epoch 97/100
100/100 [==============================] - 182s 2s/step - loss: 0.0232 - acc: 0.9920 - val_loss: 0.0214 - val_acc: 0.9260
Epoch 98/100
100/100 [==============================] - 182s 2s/step - loss: 0.0281 - acc: 0.9890 - val_loss: 0.2113 - val_acc: 0.9360
Epoch 99/100
100/100 [==============================] - 182s 2s/step - loss: 0.0209 - acc: 0.9925 - val_loss: 0.2206 - val_acc: 0.9290
Epoch 100/100
100/100 [==============================] - 182s 2s/step - loss: 0.0254 - acc: 0.9925 - val_loss: 1.5934 - val_acc: 0.9380
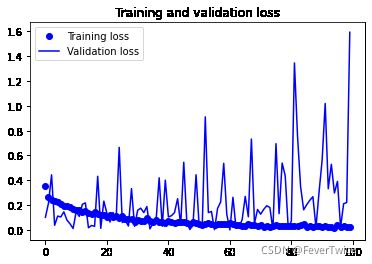
5-24 使得曲线变平滑
# 普通画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
模型准率以及损失趋势

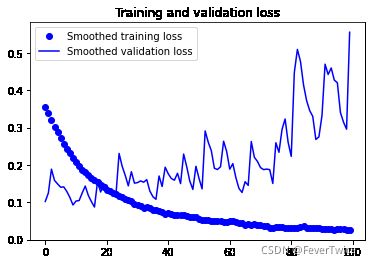
图片数据平滑化
# 平滑画图
# 平滑化
def smooth_cruve(points, factor = 0.8):
smoothed_points = []
for point in points:
if smoothed_points:
# 如果当前数组3有原素
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
# 画图
plt.plot(epochs, smooth_cruve(acc), 'bo', label = 'Smoothed training acc')
plt.plot(epochs, smooth_cruve(val_acc), 'b', label = 'Smoothed validation acc')
plt.title('Training and Validation accuracy')
plt.figure()
plt.plot(epochs, smooth_cruve(loss), 'bo', label = 'Smoothed training loss')
plt.plot(epochs, smooth_cruve(val_loss), 'b', label = 'Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
调整后的图片

显示最终训练结果
test_generator = test_datagen.flow_from_directory(test_dir,
target_size = (150, 150),
batch_size = 20,
class_mode = 'binary')
test_loss, test_acc = model_3.evaluate_generator(test_generator, steps = 50)
print('test acc:', test_acc)
Found 1000 images belonging to 2 classes.
test acc: 0.9419999718666077
总结
从上图来看,我们训练的模型从整体上还是有过拟合的特征,训练精度直接逼近100,而验证精度则一直在70左右,训练精度应该在第5轮左右达到了最小值,为解决过拟合问题,我们在下一节中将使用数据增强的方法。
写在最后
注:本文代码来自《Python 深度学习》,做成电子笔记的方式上传,仅供学习参考,作者均已运行成功,如有遗漏请练习本文作者
各位看官,都看到这里了,麻烦动动手指头给博主来个点赞8,您的支持作者最大的创作动力哟!
<(^-^)>
才疏学浅,若有纰漏,恳请斧正
本文章仅用于各位同志作为学习交流之用,不作任何商业用途,若涉及版权问题请速与作者联系,望悉知