【IT168评测中心】早在10月14日,在Intel发布Nehalem架构处理器桌面版——Core i7的一个月之前,我们IT168就已经发布了《再攀性能之巅 Intel全新酷睿i7深度评测》。在其中,我们可以看到以下的图像文字:
最后,在Pentium 4时代被大家所熟知的HyperThreading超线程技术回归到了Nehalem架构当中,现在它被称之为SMT同步多线程技术,从执行上而言它和HT技术是完全一样的,只是借助Nehalem增强的RSB和ITLB架构,Nehalem的超线程性能比起老前辈来要更为强大。
这是笔者在4月份参加IDF2008上海Intel春季开发者论坛上的报道《[IDF08]英特尔下一代处理器:Nehalem》所采用的内容,并一直沿用至今。很多媒体也采用了这样的说法。然而,“现在它被称之为SMT同步多线程技术” 这个说法确是不正确的。
| Intel Core i7支持HT超线程(SMT的一种),共具有4个处理内核,每内核支持两个线程,共8个线程 |
SMT(Simultaneous Multi-Threading,同步多线程)实乃是一个专有名词,是一种类技术的名称,不仅仅Nehalem有采用,Pentium 4也有采用,还有很多其他商用处理器也有采用。正确的情况应该是,Nehalem的HT技术和Pentium 4的HT技术一样,都是属于SMT技术。
实际上,超线程技术在Intel的很多处理器里面都有使用,除了Pentium 4(NetBurst架构)、Core i7(Nehalem架构)之外,Itanium 2(Mondecito)和Atom(Silverthorne)处理器里面都有,然而它们携带的HT技术却不属于SMT!
在整理Intel的多种HT超线程技术之前,我们先来回顾一下MultiThreading多线程技术的分类,MultiThreading多线程就是在一个单个的处理核心内同时运行多个工作线程的技术,和CMP(Chip MultiProcessing,芯片多处理)不同,后者是通过集成多个处理内核的方式来让系统的处理能力提升——也就是现在常见的多核技术。现在主流的处理器都使用了CMP技术。
然而CMP技术大规模增加了相应的电路,从而增加了成本,MT(MultiThreading)技术却不是这样,它只需要增加规模很少的部分线路(通常,约2%)就可以提升处理器的总体处理器能力,从而可以很简单地提升相关应用的性能。
MultiThreading(或作Multi-Threading)来源于可以追溯到上个世纪90年×××始的一个叫做ILP(Instruction Level Parallelism,指令级并行化)的思想,这个思想产生了一个叫做Throughput Computing(吞吐量计算)的名词,用来提升如在线交易这样的并行计算的性能。Throughput Computing的两种主要方式就是MultiProcessing和MultiThreading。
一开始,为了开发ILP,在过去的几十年中利用了超标量(Superscalar,同时具备多个执行器)、乱序执行(Out-Of-Order Execute,允许无数据关联性的指令同时运行)、动态分支预测、VLIW(Very Long Instruction Word,超长指令集 ) 等技术(前三种可在经典的Pentium Pro架构上看到,最后一个就是Itanium的特色技术)。然而,超标量使设计的复杂性急剧增加,同时,指令之间的数据和控制相关,可以开发的ILP 也有限,以及一些其它因素,使得经典的超标量结构处理器难以进一步提高处理器性能。
而且从应用的角度看,如在线事务处理OLTP、决策支持系统DSS、Web服务等这样的应用的特点是具有丰富的线程级并行性(Thread Level Parallelism)而缺乏ILP,因此也就促使了MultiProcessing和MultiThreading的出现。
MultiThreading多线程技术的思想有些类似于早期的分时共享计算系统,执行多个线程的处理器在遇到某个线程由于Cache Miss或者分支预测失败而停顿的时候,可以切换到另一个线程来执行。目前主流的MultiThreading具有着三种形式,差别在于线程间共享的资源以及线程切换的机制:
多线程架构异同 |
|||||
多线程技术 |
线程间共享资源 | 线程切换机制 | 资源利用率 | ||
粗粒度多线程 |
除取指令缓冲、寄存器、控制逻辑外 | 流水线停顿时 |
提升单个执行单元利用率 |
||
细粒度多线程 |
除寄存器、控制逻辑外 | 每时钟周期 | 提升单个执行单元利用率 | ||
同步多线程 |
除取指令缓冲、返回地址堆栈、寄存器、控制逻辑、重排序缓冲、Store队列外 | 所有线程同时活动,无切换 | 提升多个执行单元利用率 | ||
其中CMT和FMT都是在单个执行单元下的技术,不同的线程在指令级别上并不是真正的“并行”,而SMT则具有多个执行单元,同一时间内可以同时执行多个指令,因此前两者有时先归类为TMT(Temporal MultiThreading,时间多线程),以和SMT相区分。
首先介绍CMT——Coarse-Grained MultiThreading是因为:它是最简单的多线程技术,当单一执行线程遇到长时间的延迟,如Cache Missed时,就进行线程切换,直到原线程等待的操作完成,才切换回去。Coarse-Grained MultiThreading有时也叫Block MultiThreading堵塞多线程或者Cooperative MultiThreading协作多线程。
Fujitsu SPARC64 VI/VI+处理器,双核,每核两个线程
Fujitsu SPARC64 VI/VI+的CMT技术叫做VMT(Vertical Multi-Threading垂直多线程)
由于CMT很简单,因此很多处理器都有实现,除了下面列出之外,很多嵌入式微控制器都有实现:
1999年的IBM RS64 III「Pulsar」(单核心/双线程)
2005年Fujitsu SPARC64 VI「Olympus-C」(双核心/4线程)
2006年Intel Itanium 2「Montecito」(双核心/4线程)
2007年Intel Itanium 2「Montvale」(双核心/4线程)
Intel的Itanium 2赫然在目!
FMT——Fine-Grained MultiThreading随时可以在每个时钟周期内切换多个线程,以追求最大的输出能力——当然,随时可以切换也是有代价的,它拉长了每个执行线程的平均执行时间。Fine-Grained MultiThreading有时也叫Interleaved MultiThreading交错多线程或者Pre-emptive MultiThreading抢先多线程。
Sun UltraSPARC T1处理器,8核心,每核4个线程
Sun UltraSPARC T2处理器,8核心,每核8个线程
最后一段表明UltraSPARC T2使用了FMT
和CMT比起来,FMT要复杂一些,因此相应的处理器就没有那么多,例:
2005年Sun UltraSPARC T1「Niagara」(8核心/32线程)
2007年Sun UltraSPARC T2「Niagara 2」(8核心/64线程)
其实UltraSPARC T2同时还使用了其他的MT技术,才实现了比T1多了一倍的多线程能力,仔细看看上图,T2还使用了什么MT技术(注意第一段的CMT是Chip MultiThreading的意思而不是Coarse-Grained MultiThreading的意思)?
虽然CPU上使用FMT技术的并不多,不过我们可以看看另一个领域:GPU,现在NVIDIA和ATI的GPU,都使用了FMT技术:
|
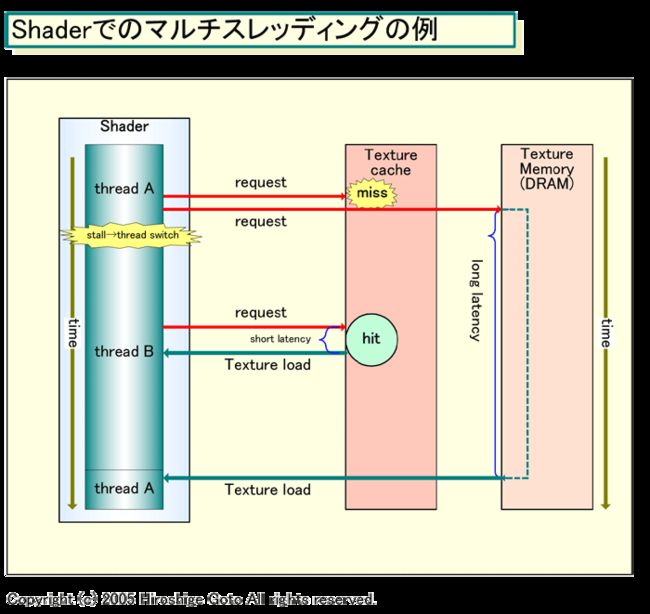
前面说过,SMT其实和其他两种多线程技术都不同——那两种技术被称之为TMT时间多线程。SMT——Simultaneous MultiThreading具有多个执行单元,可以同时运行多条指令,因此才叫做“同步多线程”!SMT起先源自充分挖掘超标量架构处理器的潜力——超标量的意思就是可以同时执行多个不同的指令。因此SMT具有最大的灵活性和资源利用率,然而实现也最复杂(当然比起多核结构来说就是小意思了)。
Intel Pentium 4,单核,每核两个线程
最典型的:Intel Pentium 4或者Core i7
2002年Intel Pentium 4 Xeon「Prestonia」(单核心/双线程)
2007年Sun UltraSPARC T2「Niagara 2」(8核心/64线程)
2008年Intel Core i7「Nehalem」(4核心/8线程)
这里又看到了UltraSPARC T2,这是因为它同时采用了FMT和SMT技术:因为UltraSPARC T2具有两个执行单元,每一个线程组使用一个,线程组内则按照T1那样执行4个线程。现代的GPU也采用了类似的混合设计:
|
NV G80的GigaThread架构 |
不同的流处理器可以同时执行不同的线程,当然同一个流处理器也可以在不同的线程之间切换。
介绍了所有的MT多线程技术种类之后,我们可以来看Intel的HyperThreading超线程技术了,前面说过,Intel具有超线程技术的CPU有:Pentium 4(NetBurst架构)、Core i7(Nehalem架构)、Itanium 2(Mondecito)、Atom(Silverthorne)。我们已经知道具有超线程技术的Pentium 4/Pentium 4 Xeon(不是所有的P4都有超线程技术)采用的是SMT架构,Core i7的则是其改进版本。我们再来看看Itanium 2:
Itanium 2 Montecito采用了双核心设计,每核心两个线程
Itanium 2 Montecito的超线程技术采用了CMT架构
Itanium 2的超线程技术:在遇到如L3 cache missed的时候进行线程切换
可见,Itanium 2的超线程技术和Pentium 4的SMT不同,它实际上是CMT粗粒度多线程技术。这是因为Itanium 2是In-Order架构的,SMT的原始构想就是充分压榨OOOE(Out-Of-Order Execution)的能力,因此In-Order架构的Itanium 2就没有采用SMT的方式。因为要创建多个线程的代价太大。
那是否In-Order架构的处理器就不能实现SMT了呢?并不是,Intel的Atom就是一个典型的例子:
迷你处理器:Intel Atom(凌动),还有一种叫法是阿童木处理器……
Atom的超线程基于In-Order架构的SMT技术
除了Atom之外,IBM的怪物Power6(起始频率4.7GHz)也采用了基于In-Order架构的SMT技术(Power5的SMT是基于Out-Of-Order):
IBM Power6处理器,双核,每核两个线程
Power6:In-Order + SMT,Power5则是Out-Of-Order + SMT
【IT168评测中心】现在,我们知道Core i7的超线程技术的名称的正确对待方法了。最后,我们来回顾一下,Intel的超线程技术到底有几种?
基于NetBurst架构的超线程:OOOE + SMT
基于Itanium架构的超线程:IOE + CMT
基于Atom架构的超线程:IOE + SMT
基于Nehalem架构的超线程:OOOE + SMT