kafka的基本体系结构
一个完整的kafka消息中间件应该包含如下几个节点:
- 生产者:生产消息的节点
- 消费者:消费消息的节点
- broker:接收生产者发送消息存储的节点
- zookeeper:管理维护broker集群,保存broker集群的元数据信息,保证集群高可用。

kafka消息存储方式
kafka是如何进行消息存储的?如何保证整个集群的负载均衡和高可用?讲解之前需要对kafka的一些基本概念做下补充
主题:生产者发送一个消息都必须挂靠一个主题,也就是说我们发的消息都是发往这个主题下
分区:本质上就是存储消息的一个物理文件概念,分区内的每一条消息都是有序的,遵循FIFO原则
消息:发送的一条条消息就是存放在分区之上的
副本:kafka往往都会搭建成集群,所以相同消息是有多份的,java培训也就是分区在集群上存在多份。而集群中,分区都会分为leader副本和follower副本,leader副本主要负责读/写请求,而follower副本主要负责同步leader副本数,保证leader副本节点宕机时,仍然能够通过选举机制保证集群高可用
broker:kafka集群中每一个节点
生产者:生成消息的节点
消费者:消费消息的节点,同一条消只能被消费组内的一个消费者消费
消费组:kafka 中每个消费者都会属于一个消费者组
ok,通过下图再来直观感受下以上几个基本概念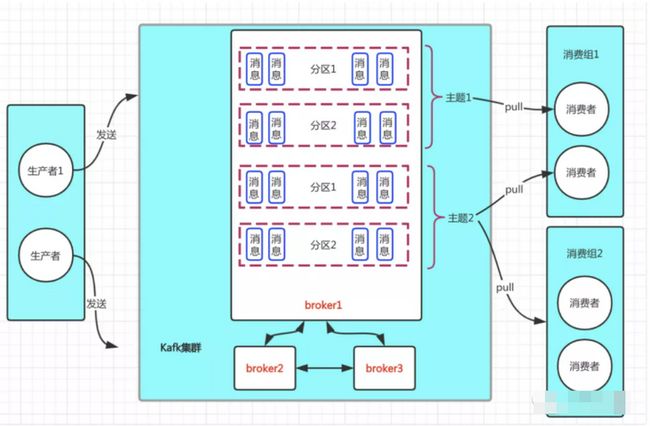
消息存入kafka集群中需要有几个步骤
- 创建主题指定分区数量和副本数,同时会根据分配算法将分区副本分配到指定broker
- 生产者向该主题发送消息
- kafka根据消息的key确定对应的分区(如果没有key自动生一个),将消息发往该分区的leader副本节点
2、3步没什么可说的,着重看下kafka是如何将分区副本分配给集群broker的,来做到负载均衡。
现假设主题A有x个分区,3个副本数。副本分配规则会根据设定的副本数量对主题下的每个分区进行逐一分配,首先对分区0的副本数量分配完后,紧接着才分配分区1的副本数量。而不是把主题的所有分区进行第一个副本数的分配,再接着第二个副本数的分配。说得有点绕,可以看下图理解理解: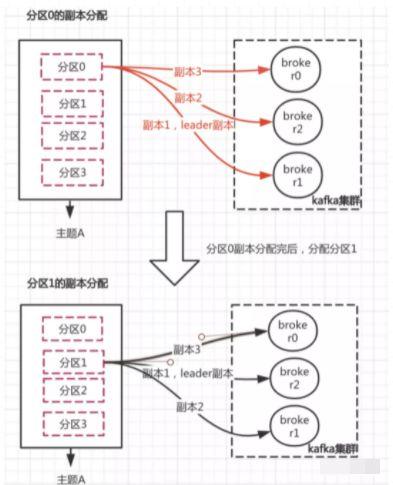
那么具体分配规则的大致算法是这样子的:
- 随机确定分区0第一个副本的broker位置,此时该分区0分配到的broker即为我们leader副本存储的节点。(再强调一遍,对于读/写分区0的消息都在这个节点进行)
- 随机确定分区0下一副本分配到broker的偏移步长,然后对剩余副本数基于这个偏移步长定位broker
具体计算公式如下
分区0第一个副本(leader副本)的broker位置:
(分区0的索引位置 + 随机起始索引 ) % broker数
分区0剩余副本broker位置:
val shift = 1+(随机的偏移步长+ 第i个副本的索引i ) % (broker数 -1 )
最终位置 = (第一个副本分配的broker位置 + shift) % broker数
随机的偏移步长:分配下一个分区的时候,会在上一个分区偏移步长之上加1
通过随机起始索引和随机的偏移步长,能够尽量的保证所有分区的leader副本均匀的分配到kafka集群。而leader副本的节点负责所有的读写操作,这样就保证不会由于leader副本分布过于集中而导致负载不均衡问题。
生产者端核心处理流程
生产者在创建消息的时候,必须在broker上创建一个主题并指定分区数和分区副本数量,此后消息发送时会往该主题下的分区进行发送。主题创建完毕后,进行消息发送,可以分为如下几个核心步骤
- 实例化核心组件
此阶段会实例化一些核心数据 如broker集群的核心元数据信息、可用的分区列表、消息key和value的序列化方式。
- 发送消息
首先会将消息填入缓冲区然后另开线程从缓冲区中批量取出数据发送到broker,缓冲区的数据大体设计结构如下。
填入缓冲区的规则会根据消息的key计算出消息需要放入那个分区,分区内部的消息是有序的,同时是一种先进先出的双端队列结构(FIFO)。之所以是双端队列结构是因为它内部有一个重试机制,在消息发送失败时,保证下次取的消息还是那个未发送的。而在消息写入缓冲区的时候,只需要加在队列的尾部即可。整个发送消息的大体核心流程如下: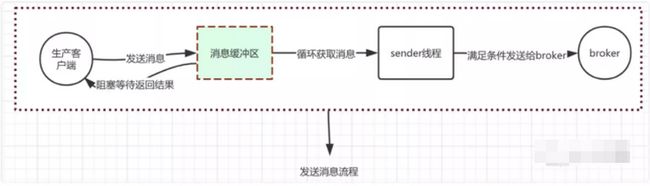
消费者端核心处理流程
消费端进行消息消费的主要核心流程分为以下几个步骤:
- 消费组内的消费者根据分配策略,订阅分区
- 从指定分区中拉取消息,进行消费
- 提交消费偏移量
• 消费组内的消费者根据分配策略订阅分区
kafka中提供了3种分配策略:RoundRobinAssignor、RangeAssignor、StickyAssignor
RoundRobinAssignor:round-robin 是一种轮询的策略方式,它将订阅主题的分区和消费者进行排序,然后将所有主题的分区均匀分配给消费组内的每个消费者(PS:类似与我们斗地主发牌的方式,分区就是牌,消费者就是玩游戏的人)。
假设有两个主题 t0、t1 分别有3个分区(PS:总共有6个分区 t0p0,t0p1,t0p2,,t1p0,t1p1,t1p2),同一个消费组内有两个消费者(c0,c1)进行订阅,那么分区的分配最终结果如下:
c0:[t0p0,t0p2,t1p1]
c1:[t0p1,t1p0,t1p2]

RangeAssignor: range的分配策略(默认的分配策略),首先对消费者按照字典顺序进行排序,然后对一个主题下的所有分区均匀分配,分配剩余的分区就会按照消费者顺序逐一分配给每个消费者,分配完后接着分配下一个主题的分区,逻辑同第一个一样。
假设有两个主题 t0、t1 分别有3个分区(PS:总共有6个分区 t0p0,t0p1,t0p2,t1p0,t1p1,t1p2),那么分区分配的最终结果如下:
c0:[t0p0,t0p2,t1p0,t1p2]
c1:[t0p1,t1p1]
StickyAssignor: 是对于 round-robin和range 更近一步的优化。因为这两种策略当存在同一个消费组内消费者订阅的主题不一样时,那么么可能会存在某个消费者分配的分区较多的情况,导致不均衡问题。而sticky策略对于这种情况也能进行更优的分配,同时对于消费组内新上线/下线消费者时,会基于之前已分配的分区上进行分配,而不是重新进行分配,它尽可能的保证少移动分区(PS:round-robin和range策略对于新上线、下线消费者时,会重新进行分区分配)
举个例子有3个同属于一个消费组的Consumer:C0、C1、C2,都订阅了4个Topic:T0、T1、T2、T3,每个Topic有2个分区
那么StickyAssignor的分配结果如下图所示(增加RoundRobinAssignor分配作为对比):
• 从指定分区中拉取消息,进行消费
fetcher.fetchedRecords判断是否有数据,无数据调用fetcher.sendFetches()拉取数据fetcher.sendFetches() 会根据元数据信息,确定消费者需要往哪几个分区拉取消息,同时创建FetchRequest的请求消息(此阶段会确定区消息偏移量的起始位置),然后调用ConsumerNetworkClient.send 方法获取消息。
这边需要着重讲一下消费者如何确定消费偏移量的起始位置,起始位置的确定跟auto.offset.reset配置值有比较大的关系,主要有两个核心值earliest和latest(默认策略)。消费者会先检查本地是否已经有提交的偏移量,如有那么根据当前偏移量继续往下读取。如果没有那么会根据auto.offset.reset的值确定偏移量。earliest和latest都会向kafka集群中获取已提交的偏移位置,基于该偏移量继续消费。如果没有已提交的偏移量,earliest会从头消费,latest将消费新产生的消息(PS:latest这种策略如果新建消费组的话在发布应用阶段出现消息丢失的情况)
不太明白的话举个例子,假设6条消息,消费组A还有两条消息未消费。
当reset为earliest:重启消费组A,收到2条消息;新建消费组B,收到6条消息.
当reset为latest:重启消费组A,收到2条消息;新建消费组B,无收到消息.
• 提交消费偏移量
手动提交:客户端调用相应API 进行提交
自动提交:自动提交并不是通过定时任务去周期性的提交,而是在一些特定事件发生时触发进行提交
两种提交方式都是最终调用ConsumerCoorditor的同步提交和异步提交方法。可以通过设置enable.auto.commit属性来指定手动还是自动提交。
保证分布式事务
对于发送端,kafka内部有自己的重试次数配置,当重试次数达到,消息还未发送成功,我们可以采取日志记录,后续通过补偿任务进行重试。
对于消费端,kafka是通过消息偏移量来拉取消息,所以对于broker发送给到消费端失败这个问题就不存在了。我们讨论的只有在消费端接收到数据,然后消费失败的这种情况。消费失败如果我们将偏移量重置,下次不就可以继续拉取了吗?但此方案会存在一定的问题,kafka消息在分区内都是顺序读和顺序写的,如果前一条消息一直消费失败,那么会导致后续消息消费不了,产生堆积问题。因此我们依然还是通过记录日志的方式,将消费失败的消息记录,后续通过定时任务进行补偿,来保证数据的最终一致。