最优化方法小结
线性搜索方法
梯度下降
在我的文章深度学习中常见的优化器小结中已经提到梯度下降法,这里,将重要的部分提炼过来。
其计算方法是:
给定待优化模型参数 θ ∈ R d \theta \in R^d θ∈Rd和目标函数 J ( θ ) J(\theta) J(θ)后,算法沿着梯度的相反方向更新 θ \theta θ来最小化 J ( θ ) J(\theta) J(θ)。学习率 η \eta η决定了每一时刻的更新步长。对于每一时刻t用以下步骤来说明梯度下降的流程:
(1)计算目标函数关于参数的梯度 g t = ∇ θ J ( θ ) g_t=\nabla_\theta J(\theta) gt=∇θJ(θ)
(2)更新模型参数
θ t + 1 = θ − η g t \theta_{t+1}=\theta-\eta g_t θt+1=θ−ηgt
梯度下降与一阶泰勒展开:
假设损失函数是 J ( θ ) J(\theta) J(θ),对其做一阶泰勒展开:
J ( θ ) = J ( θ 0 ) + ( θ − θ 0 ) ∇ θ J ( θ 0 ) J(\theta) = J(\theta_0)+(\theta-\theta_0)\nabla_\theta J(\theta_0) J(θ)=J(θ0)+(θ−θ0)∇θJ(θ0)
假设, θ − θ 0 = λ d ⃗ \theta-\theta_0=\lambda \vec d θ−θ0=λd,其中 d ⃗ \vec d d是方向向量, λ \lambda λ为标量,描述其长度。不难得出:
( θ − θ 0 ) ∇ θ J ( θ 0 ) = λ ∣ d ⃗ ∣ ∣ ∇ θ J ( θ 0 ) ∣ c o s ( α ) (\theta-\theta_0)\nabla_\theta J(\theta_0) =\lambda |\vec d| |\nabla_\theta J(\theta_0)|cos(\alpha) (θ−θ0)∇θJ(θ0)=λ∣d∣∣∇θJ(θ0)∣cos(α),这里的 α \alpha α是两个向量的夹角。如果我们期望梯度下降的方向最大,那么易知, d ⃗ \vec d d与梯度是反向的,则: d ⃗ = − ∇ θ J ( θ 0 ) ∣ ∣ ∇ θ J ( θ 0 ) ∣ ∣ \vec d=\frac{-\nabla_\theta J(\theta_0)}{||\nabla_\theta J(\theta_0)||} d=∣∣∇θJ(θ0)∣∣−∇θJ(θ0)。
那么,我们有:
θ − θ 0 = λ d ⃗ = λ − ∇ θ J ( θ 0 ) ∣ ∣ ∇ θ J ( θ 0 ) ∣ ∣ θ = θ 0 − λ ∣ ∣ ∇ θ J ( θ 0 ) ∣ ∣ ∇ θ J ( θ 0 ) \theta-\theta_0=\lambda \vec d = \lambda \frac{-\nabla_\theta J(\theta_0)}{||\nabla_\theta J(\theta_0)||} \\ \theta = \theta_0 - \frac{\lambda}{||\nabla_\theta J(\theta_0)||}\nabla_\theta J(\theta_0) θ−θ0=λd=λ∣∣∇θJ(θ0)∣∣−∇θJ(θ0)θ=θ0−∣∣∇θJ(θ0)∣∣λ∇θJ(θ0)
也就得到了梯度下降的公式。
牛顿法
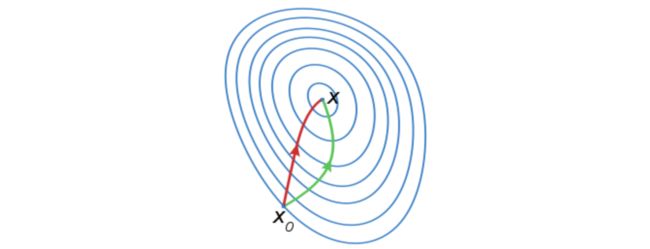
红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
从几何的角度出发,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
牛顿法是怎么推导出来的呢?之前做梯度下降的时候我们对其进行了泰勒一阶展开,那么这里我们对其进行二阶展开,可得:
J ( θ ) = J ( θ 0 ) + ( θ − θ 0 ) ∇ θ J ( θ 0 ) + 1 2 ( θ − θ 0 ) T H ( θ 0 ) ( θ − θ 0 ) J(\theta) = J(\theta_0)+(\theta-\theta_0)\nabla_\theta J(\theta_0)+\frac{1}{2}(\theta-\theta_0)^TH(\theta_0)(\theta-\theta_0) J(θ)=J(θ0)+(θ−θ0)∇θJ(θ0)+21(θ−θ0)TH(θ0)(θ−θ0)
我们想要在 θ \theta θ处取得极值点,那么只需要 ∇ θ J ( θ ) = 0 \nabla_\theta J(\theta)=0 ∇θJ(θ)=0,于是我们对上式求导,易得:
∇ θ J ( θ ) = ∇ θ J ( θ 0 ) + H ( θ 0 ) ( θ − θ 0 ) = 0 \nabla_\theta J(\theta)=\nabla_\theta J(\theta_0)+H(\theta_0)(\theta-\theta_0)=0 ∇θJ(θ)=∇θJ(θ0)+H(θ0)(θ−θ0)=0
有:
θ t + 1 = θ t − H t − 1 g t \theta_{t+1}=\theta_t-H_t^{-1}g_t θt+1=θt−Ht−1gt
这就是牛顿法。
拟牛顿法
我们知道求解海瑟矩阵的逆是一个非常复杂的计算,考虑使用一个n阶矩阵 G G G 替代 H − 1 H^{-1} H−1 , 这就是拟牛顿法。
条件1:G 需要满足正定矩阵:
从牛顿法可知:
θ t + 1 = θ t − H t − 1 g t \theta_{t+1}=\theta_t-H_t^{-1}g_t θt+1=θt−Ht−1gt
其实会在其中再增加一个学习率,也就是:
θ t + 1 = θ t − λ H t − 1 g t θ t + 1 − θ t = − λ H t − 1 g t \theta_{t+1}=\theta_t-\lambda H_t^{-1}g_t \\ \theta_{t+1}-\theta_t=-\lambda H_t^{-1}g_t θt+1=θt−λHt−1gtθt+1−θt=−λHt−1gt
带入到一阶泰勒展开式中,我们有:
J ( θ ) = J ( θ 0 ) − λ g t T H t − 1 g t J(\theta) = J(\theta_0)-\lambda g_t^TH_t^{-1}g_t J(θ)=J(θ0)−λgtTHt−1gt
因为 H − 1 H^{-1} H−1正定,所以, g t T H t − 1 g t > 0 g_t^TH_t^{-1}g_t >0 gtTHt−1gt>0。易知 J ( θ ) < J ( θ 0 ) J(\theta) < J(\theta_0) J(θ)<J(θ0)。
那么,要有一个 G G G去拟合 H − 1 H^{-1} H−1,显然,他需要是正定的
条件2:
显然,只有一个正定条件是不行的,首先牛顿法满足这样的性质:
∇ θ J ( θ ) = ∇ θ J ( θ 0 ) + H ( θ 0 ) ( θ − θ 0 ) ⇒ g t + 1 = g t + H t ( θ t + 1 − θ t ) ⇒ g t + 1 − g t = H t ( θ t + 1 − θ t ) \nabla_\theta J(\theta)=\nabla_\theta J(\theta_0)+H(\theta_0)(\theta-\theta_0) \\ ⇒ g_{t+1} = g_{t}+H_{t}(\theta_{t+1}-\theta_t) \\ ⇒ g_{t+1}-g_t = H_t(\theta_{t+1}-\theta_t) ∇θJ(θ)=∇θJ(θ0)+H(θ0)(θ−θ0)⇒gt+1=gt+Ht(θt+1−θt)⇒gt+1−gt=Ht(θt+1−θt)
令 y t = g t + 1 − g t , δ t = θ t + 1 − θ t y_{t}=g_{t+1}-g_t,\delta_{t}=\theta_{t+1}-\theta_t yt=gt+1−gt,δt=θt+1−θt
y t = H t δ t ⇒ H t − 1 y t = δ t y_{t}=H_t\delta_{t} \\ ⇒ H_t^{-1}y_{t}=\delta_{t} yt=Htδt⇒Ht−1yt=δt
成为拟牛顿条件,因此 G t G_t Gt需要满足这样的拟牛顿条件,则有:
G t y t = δ t G_ty_t=\delta_t Gtyt=δt
我们希望有 G t + 1 = G t + Δ G t G_{t+1}=G_t+\Delta G_t Gt+1=Gt+ΔGt。有以下两种算法:
DFP(Davidon-Fletcher-Powell)算法(DFP algorithm)

BFGS(Broyden-Fletcher-Goldfard-Shano)算法(BFGS algorithm):

置信域方法
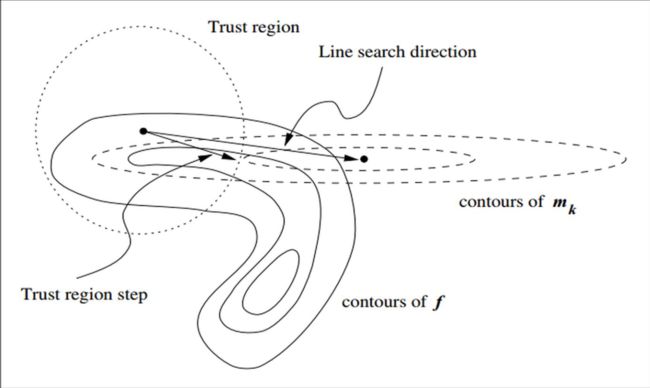
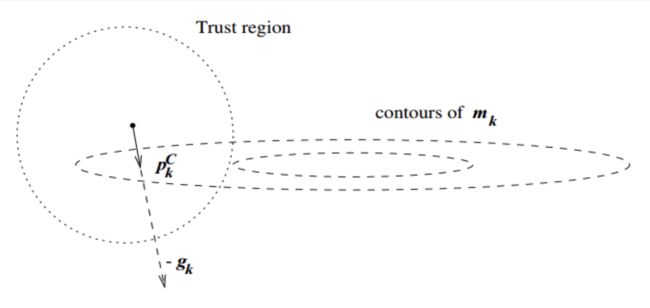
在信赖域方法的每次迭代中,先确定一个信赖域半径,然后在该半径内计算目标函数的二阶近似的极小值。如果该极小值使得目标函数取得了充分的下降,则进入下一个迭代,并扩大信赖域半径,如果该极小值不能令目标函数取得充分的下降,则说明当前信赖域区域内的二阶近似不够可靠,需要缩小信赖域半径,重新计算极小值。如此迭代下去,直到满足收敛所需的条件。我们结合上图做进一步的解释。
图中,实线表示的是目标函数的等高线,虚线是泰勒二阶近似的等高线:
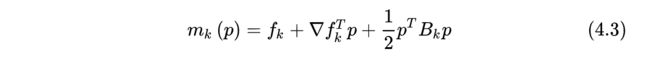
因为泰勒二阶近似并不与目标函数完全相同,后面还有个高阶无穷小的值,因此他们的等高线不相同。如果我们使用牛顿法,那么他就会走到 m k ( p ) m_k(p) mk(p)的极值点。但从图中不难看出,这个点根本没有充分的下降,在信頼域内最好的步骤是Trust region step,这个点比牛顿法的结果要好很多(在该例下)。
不过,这一现象比较依赖于信赖域半径的选取。可以想象,如果信赖域半径非常大,我们仍然会找到 m k ( p ) m_k(p) mk(p) 的极小值点,但此时,这一步长是不能接受的,我们不会进入下一次迭代,而是要重新设置信赖域半径,重新计算步长。那么步长是否可接受的条件是什么呢?定义变量
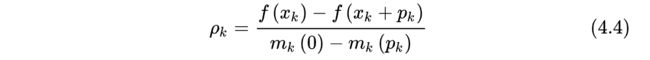
分母表示目标函数的二阶近似的减小量,分子表示目标函数的减小量。如果结果接近于1,说明二阶近似很接近目标函数,这一步长是可以接受的。如果结果接近于0甚至小于0,说明二阶近似与真实的目标函数差距较大,我们需要减小信赖域半径,并重新计算步长。
那么,问题只剩下,如何找到 m k ( p ) m_k(p) mk(p)的极小值,这里只介绍Cauchy Point这一种方案,对Dogleg感兴趣的同学可以看信頼域这篇文章。
柯西点(Cauchy Point):
这是一种近似求解的方法,固定 p p p方向是梯度下降的方向,沿着这个方向寻找极小值,有:
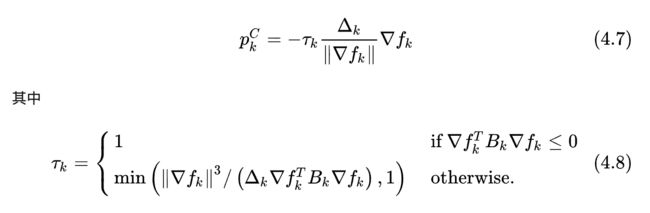
可以看出,步长为 τ k Δ k \tau_k\Delta_k τkΔk,方向为负梯度方向。至于 τ k \tau_k τk的来源,可以直接将4.7的结果带入4.3
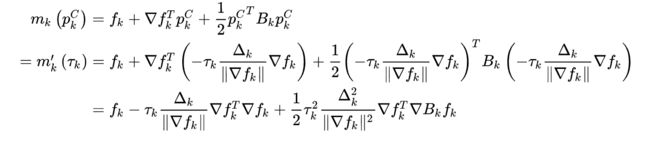

下面展示这种方法在例子中的效果:
启发式算法
在我的博文启发式算法中已经详细的介绍了相关算法,这里就不再赘述。
参考资料
梯度下降与一阶泰勒展开的关系
李航:《统计学习方法》,清华大学出版社
梯度下降法、牛顿法和拟牛顿法
信頼域