详解宏任务、微任务与事件循环 Event Loop
文章目录
- 前言
- 浏览器中的事件循环
-
- js执行顺序入门
- 事件循环 Event Loop
- 执行栈与事件队列
- 宏任务(macro task)和微任务(micro task)
- 实例详解
- node中的事件循环
-
- 与浏览器环境有何不同
- node 中的宏任务和微任务
- 来自官方的 Node.js 事件循环介绍
- 调用堆栈
- 一个简单的事件循环的阐释
- 入队函数执行
- 消息队列
- 了解 process.nextTick()
- 了解 setImmediate()
- setImmediate() setTimeout() 和 process.nextTick() 的区别
- node 事件循环模型
- node 版本差异
- 参考
前言
我们都知道,javascript从诞生之日起就是一门 单线程 的 非阻塞 的脚本语言。这是由其最初的用途来决定的:与浏览器交互。
-
单线程意味着,javascript代码在执行的任何时候,都只有一个主线程来处理所有的任务。 -
而
非阻塞则是当代码需要进行一项异步任务(无法立刻返回结果,需要花一定时间才能返回的任务,如I/O事件)的时候,主线程会挂起(pending)这个任务,然后在异步任务返回结果的时候再根据一定规则去执行相应的回调。
单线程是必要的,也是javascript这门语言的基石,原因之一在其最初也是最主要的执行环境——浏览器中,我们需要进行各种各样的dom操作。试想一下 如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
当然,现如今人们也意识到,单线程在保证了执行顺序的同时也限制了javascript的效率,因此开发出了web worker技术。这项技术号称让javascript成为一门多线程语言。
然而,使用web worker技术开的多线程有着诸多限制,例如:所有新线程都受主线程的完全控制,不能独立执行。这意味着这些“线程” 实际上应属于主线程的子线程。另外,这些子线程并没有执行I/O操作的权限,只能为主线程分担一些诸如计算等任务。所以严格来讲这些线程并没有完整的功能,也因此这项技术并非改变了javascript语言的单线程本质。
可以预见,未来的javascript也会一直是一门单线程的语言。
话说回来,前面提到javascript的另一个特点是“非阻塞”,那么javascript引擎到底是如何实现的这一点呢?答案就是今天这篇文章的主角——event loop(事件循环)。
注:虽然nodejs中的也存在与传统浏览器环境下的相似的事件循环。然而两者间却有着诸多不同,故把两者分开,单独解释。
浏览器中的事件循环
js执行顺序入门
不论是面试求职,还是日常开发工作,我们经常会遇到这样的情况:给定的几行代码,我们需要知道其输出内容和顺序。因为javascript是一门单线程语言,所以我们可以得出结论:
- javascript是按照语句出现的顺序执行的
正因为js是一行一行执行的,所以我们以为js都是这样的:
let a = '1';
console.log(a);
let b = '2';
console.log(b);
然而实际上js是这样的:
setTimeout(function(){
console.log('定时器开始啦')
});
new Promise(function(resolve){
console.log('马上执行for循环啦');
for(var i = 0; i < 10000; i++){
i == 99 && resolve();
}
}).then(function(){
console.log('执行then函数啦')
});
console.log('代码执行结束');
依照js是 按照语句出现的顺序执行 这个理念,它的输出结果是不是下面这样呢?
//"定时器开始啦"
//"马上执行for循环啦"
//"执行then函数啦"
//"代码执行结束"
我们打开chrome浏览器验证一下:

可以发现我们前面推测的结果完全不对 ❗
讲到这里,应该已经发现我们必须要彻底弄明白javascript的执行机制。
◾ 关于javascript
javascript是一门单线程语言,在最新的HTML5中提出了Web-Worker,但javascript是单线程这一核心仍未改变。所以一切javascript版的"多线程"都是用单线程模拟出来的,一切javascript多线程都是纸老虎!
事件循环 Event Loop
既然js是单线程,那么js任务就要一个一个顺序执行。如果一个任务耗时过长,那么后一个任务也必须等着。那么问题来了,假如我们想浏览新闻,但是新闻包含的超清图片加载很慢,难道我们的网页要一直卡着直到图片完全显示出来?当然不需要,js任务分为两类:
- 同步任务
- 异步任务
当我们打开网站时,网页的渲染过程就是一大堆同步任务,比如页面骨架和页面元素的渲染。而像加载图片视频之类占用资源大耗时久的任务,就是异步任务。
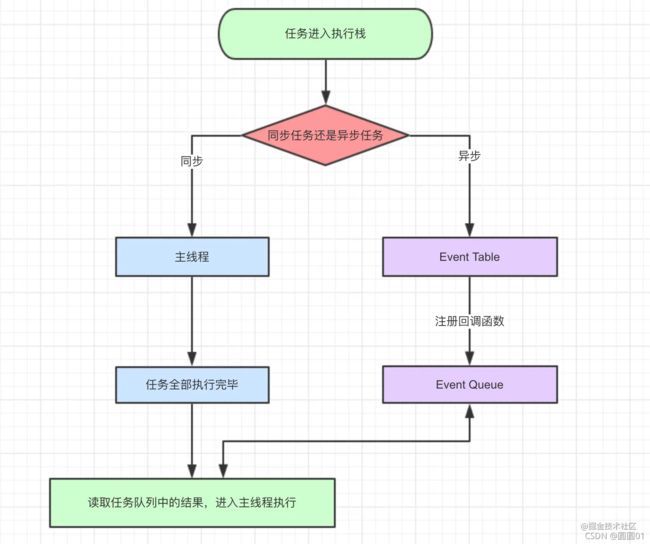
上述图片包含了几个知识点:
- 同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册函数。
- 当指定的事情完成时,Event Table会将这个函数移入Event Queue
(事件队列)。 - 主线程执行栈的任务执行完毕为空,会去Event Queue读取对应的函数,进入主线程执行。
- 上述过程会不断重复,也就是常说的Event Loop(事件循环)。
那怎么知道 主线程执行栈 为空 啊?js引擎存在monitoring process进程 (监视进程),会持续不断的检查主线程执行栈是否为空,一旦为空,就会去Event Queue (事件队列) 那里检查是否有等待被调用的函数。
执行栈与事件队列
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
我们知道,当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。这个过程反复进行,直到执行栈中的代码全部执行完毕。
下面这个图片非常直观的展示了这个过程,其中的global就是初次运行脚本时向执行栈中加入的代码:

从图片可知,一个方法执行会向执行栈中加入这个方法的执行环境,在这个执行环境中还可以调用其他方法,甚至是自己,其结果不过是在执行栈中再添加一个执行环境。这个过程可以是无限进行下去的,除非发生了栈溢出,即超过了所能使用内存的最大值。
以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?前文提过,js的另一大特点是非阻塞,实现这一点的关键在于下面要说的这项机制——事件队列(Task Queue)。
js引擎遇到一个异步事件后并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务。当一个异步事件返回结果后,js会将这个事件加入与当前执行栈不同的另一个队列,我们称之为事件队列。被放入事件队列不会立刻执行其回调,而是等待当前执行栈中的所有任务都执行完毕, 主线程处于闲置状态时,主线程会去查找事件队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件,并把这个事件对应的回调放入执行栈中,然后执行其中的同步代码…,如此反复,这样就形成了一个无限的循环。这就是这个过程被称为“事件循环(Event Loop)”的原因。
这里还有一张图来展示这个过程:
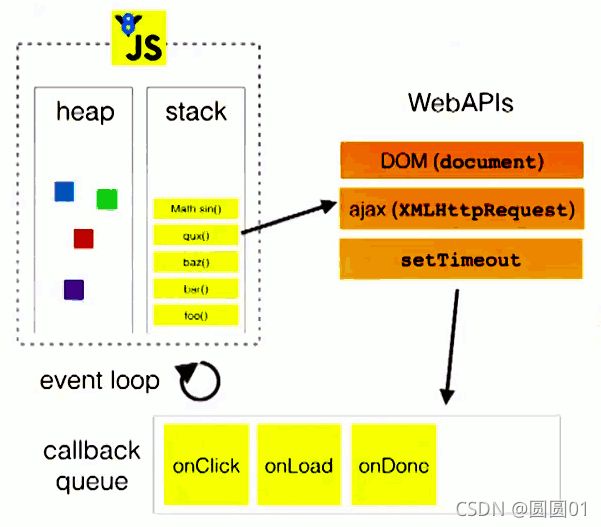
图中的stack表示我们所说的执行栈,web apis则是代表一些异步事件,而callback queue即事件队列。
◾ 事件队列
所有的任务可以分为同步任务和异步任务,同步任务,顾名思义,就是立即执行的任务,同步任务一般会直接进入到主线程中执行;而异步任务,就是异步执行的任务,比如ajax网络请求,setTimeout 定时函数等都属于异步任务,异步任务会通过事件队列( Event Queue )的机制来进行协调。具体的可以用下面的图来大致说明一下:
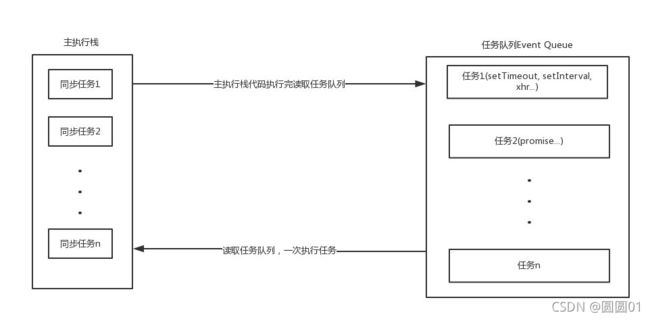
同步和异步任务分别进入不同的执行环境,同步的进入主线程,即主执行栈,异步的进入 Event Queue 。主线程内的任务执行完毕为空,会去 Event Queue 读取对应的任务,推入主线程执行。 上述过程的不断重复就是我们说的 Event Loop (事件循环)。
宏任务(macro task)和微任务(micro task)
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务 (micro task) 和宏任务 (macro task)。
以下事件属于宏任务:
setInterval()setTimeout()
以下事件属于微任务:
new Promise()Async/Await(实际就是promise)new MutaionObserver()
前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈…如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。
◾ 这样就能解释下面这段代码的结果:
setTimeout(function () {
console.log(1);
});
new Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
结果为:
2
3
1
实例详解
console.log('script start');
setTimeout(function () {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function () {
console.log('promise1');
}).then(function () {
console.log('promise2');
});
console.log('script end');
输出结果是下面这样的吗?
script start
promise1
promise2
script end
setTimeout
不对!!!
正确的输出结果是:
script start
script end
promise1
promise2
setTimeout
这里忘掉了 必须是当前执行栈为空的时候,主线程才会 查看微任务队列是否有事件存在。
最后一句console.log('script end'); 还是当前执行栈的任务,肯定是先执行完这段代码,然后才能检查是否有微任务呀! 这点要注意,不要不小心忽略啦~
让我们来详细分析,一步步执行解析一下上面的例子,先贴一下例子代码 (免得你往上翻) :
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
- 整体 script 作为第一个宏任务进入主线程,遇到 console.log,输出 script start
- 遇到 setTimeout,其回调函数被分发到宏任务 Event Queue 中
- 遇到 Promise,其 then函数被分到到微任务 Event Queue 中,记为 then1,之后又遇到了 then 函数,将其分到微任务 Event Queue 中,记为 then2
- 遇到 console.log,输出 script end
这里,输出结果为:
script start
script end
至此,Event Queue 中存在三个任务,如下表:
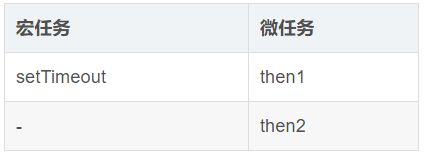
接下来:
- 执行微任务,首先执行then1,输出 promise1, 然后执行 then2,输出 promise2,这样就清空了所有微任务
- 执行 setTimeout 任务,输出 setTimeout,这样就清空了所有宏任务
至此,最后得输出顺序为:
script start
script end
promise1
promise2
setTimeout
◾ 如果你已经有些轻车熟路了,那不妨再来看看下面这道题:
(function test() {
setTimeout(function() {
console.log(4)}, 0);
new Promise(function executor(resolve) {
console.log(1);
for( var i=0 ; i<10000 ; i++ ) {
i == 9999 && resolve();
}
console.log(2);
}).then(function() {
console.log(5);
});
console.log(3);
})()
输出结果为:
1
2
3
5
4
node中的事件循环
与浏览器环境有何不同
在node中,事件循环表现出的状态与浏览器中大致相同。不同的是node中有一套自己的模型。node中事件循环的实现是依靠的libuv引擎。
我们知道node选择chrome v8引擎作为js解释器,v8引擎将js代码分析后去调用对应的node api,而这些api最后则由libuv引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。因此实际上node中的事件循环存在于libuv引擎中。
node 中的宏任务和微任务
node 中也有宏任务和微任务,与浏览器中的事件循环类似:
宏任务(macro-task) 包括:
setTimeout()setInterval()setImmediate()I/O 操作
微任务(micro-task) 包括:
process.nextTick()(与普通微任务有区别,在微任务队列执行之前执行)new Promise()等。
来自官方的 Node.js 事件循环介绍
Node.js 事件循环是了解 Node.js 最重要的方面之一。为什么这么重要? 因为它阐明了 Node.js 如何做到异步且具有非阻塞的 I/O,所以它基本上阐明了 Node.js 的“杀手级应用”。
Node.js JavaScript 代码运行在单个线程上。 每次只处理一件事。
这个限制实际上非常有用,因为它大大简化了编程方式,而不必担心并发问题。
只需要注意如何编写代码,并避免任何可能阻塞线程的事情,例如同步的网络调用或无限的循环。
通常,在大多数浏览器中,每个浏览器选项卡都有一个事件循环,以使每个进程都隔离开,并避免使用无限的循环或繁重的处理来阻止整个浏览器的网页。
该环境管理多个并发的事件循环,例如处理 API 调用。 Web 工作进程也运行在自己的事件循环中,这个前文我们已经讲过。
调用堆栈
调用堆栈是一个 LIFO 队列(后进先出)。
事件循环不断地检查调用堆栈,以查看是否需要运行任何函数。
当执行时,它会将找到的所有函数调用添加到调用堆栈中,并按顺序执行每个函数。
你知道在调试器或浏览器控制台中可能熟悉的错误堆栈跟踪吗? 浏览器在调用堆栈中查找函数名称,以告知你是哪个函数发起了当前的调用:
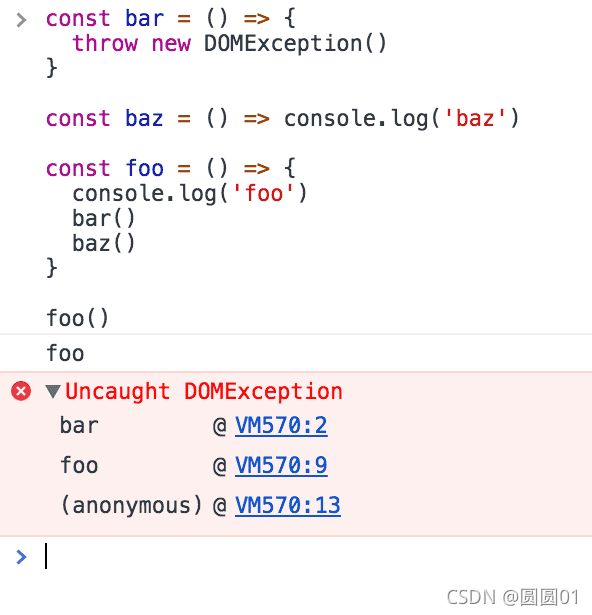
一个简单的事件循环的阐释
举个例子:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
bar()
baz()
}
foo()
此代码会如预期地打印:
foo
bar
baz
当运行此代码时,会首先调用 foo()。 在 foo() 内部,会首先调用 bar(),然后调用 baz()。
此时,调用堆栈如下所示:
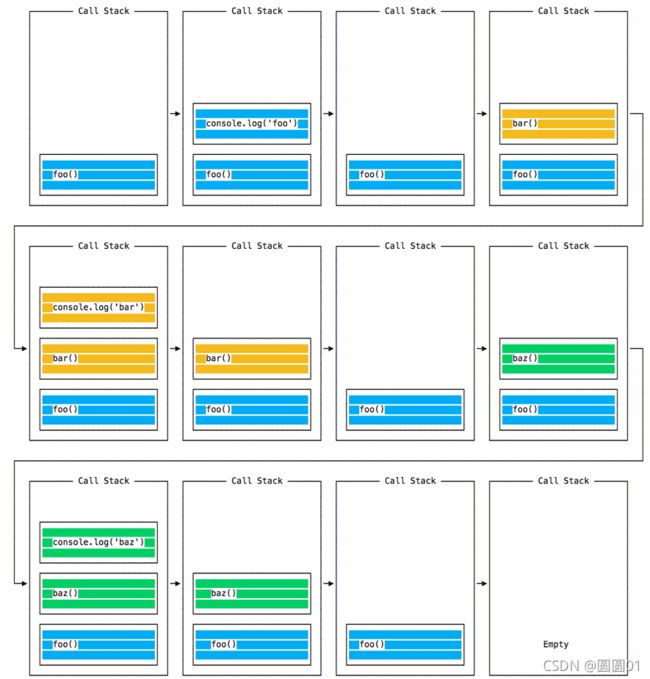
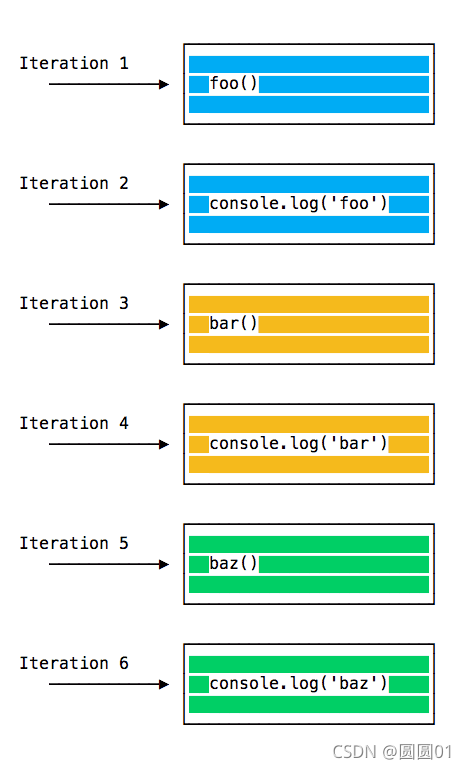
每次迭代中的事件循环都会查看调用堆栈中是否有东西并执行它直到调用堆栈为空:
入队函数执行
上面的示例看起来很正常,没有什么特别的:JavaScript 查找要执行的东西,并按顺序运行它们。
让我们看看如何将函数推迟直到堆栈被清空。
setTimeout(() => {}, 0) 的用例是调用一个函数,但是是在代码中的每个其他函数已被执行之后。
举个例子:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
setTimeout(bar, 0)
baz()
}
foo()
该代码会打印:
foo
baz
bar
当运行此代码时,会首先调用 foo()。 在 foo() 内部,会首先调用 setTimeout,将 bar 作为参数传入,并传入 0 作为定时器指示它尽快运行。 然后调用 baz()。
此时,调用堆栈如下所示:
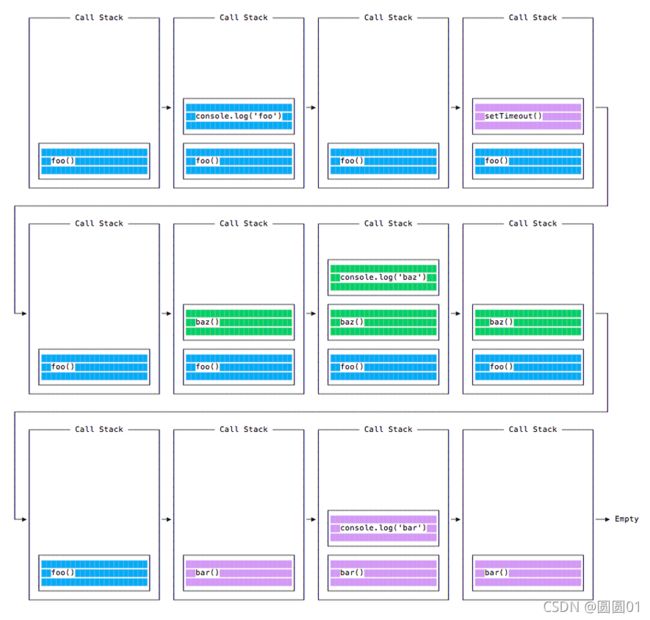
这是程序中所有函数的执行顺序:
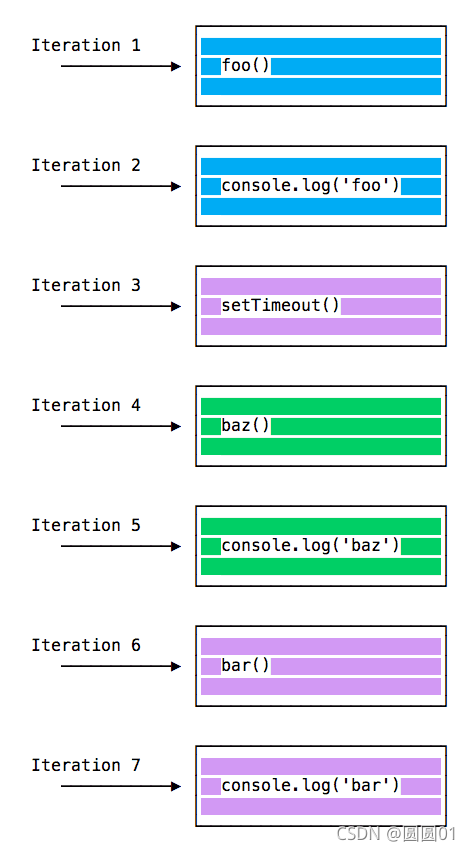
为什么会这样呢?
消息队列
当调用 setTimeout() 时,浏览器或 Node.js 会启动定时器。 当定时器到期时(在此示例中会立即到期,因为将超时值设为 0),则回调函数会被放入“消息队列”中。
在消息队列中,用户触发的事件(如单击或键盘事件、或获取响应)也会在此排队,然后代码才有机会对其作出反应。 类似 onLoad 这样的 DOM 事件也如此。
事件循环会赋予调用堆栈优先级,它首先处理在调用堆栈中找到的所有东西,一旦其中没有任何东西,便开始处理消息队列中的东西。
◾ ES6 作业队列
ECMAScript 2015 引入了作业队列的概念,Promise 使用了该队列(也在 ES6/ES2015 中引入)。 这种方式会尽快地执行异步函数的结果,而不是放在调用堆栈的末尾。
在当前函数结束之前 resolve 的 Promise 会在当前函数之后被立即执行。
示例:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
setTimeout(bar, 0)
new Promise((resolve, reject) =>
resolve('应该在 baz 之后、bar 之前')
).then(resolve => console.log(resolve))
baz()
}
foo()
这会打印:
foo
baz
应该在 baz 之后、bar 之前
bar
这是 Promise(以及基于 promise 构建的 async/await)与通过 setTimeout() 或其他平台 API 的普通的旧异步函数之间的巨大区别。
了解 process.nextTick()
当尝试了解 Node.js 事件循环时,其中一个重要的部分就是 process.nextTick()。
每当事件循环进行一次完整的行程时,我们都将其称为一个 tick (滴答、记号、标记好)。
当将一个函数传给 process.nextTick() 时,则指示引擎在当前操作结束(在下一个事件循环滴答开始之前)时调用此函数:
process.nextTick(() => {
//做些事情
})
事件循环正在忙于处理当前的函数代码。当该操作结束时,JS 引擎会运行在该操作期间传给 nextTick 调用的所有函数。
调用 setTimeout(() => {}, 0) 会在下一个滴答结束时执行该函数,比使用 nextTick()(其会优先执行该调用并在下一个滴答开始之前执行该函数)晚得多。
当要确保在下一个事件循环迭代中代码已被执行,则使用 nextTick()。
了解 setImmediate()
当要异步地(但要尽可能快)执行某些代码时,其中一个选择是使用 Node.js 提供的 setImmediate() 函数:
setImmediate(() => {
//运行一些东西
})
作为 setImmediate() 参数传入的任何函数都是在事件循环的下一个迭代中执行的回调。
setImmediate() setTimeout() 和 process.nextTick() 的区别
setImmediate() 与 setTimeout(() => {}, 0)(传入 0 毫秒的超时)、process.nextTick() 有何不同?
传给 process.nextTick() 的函数会在事件循环的当前迭代中(当前操作结束之后)被执行。 这意味着它会始终在 setTimeout 和 setImmediate 之前执行。
延迟 0 毫秒的 setTimeout() 回调与 setImmediate() 非常相似。 执行顺序取决于各种因素,但是它们都会在事件循环的下一个迭代中运行。
node 事件循环模型
下面是一个libuv引擎中的事件循环的模型,下图显示了事件循环操作顺序的简化概述:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
注:模型中的每一个方块代表事件循环的一个阶段
这个模型是node官网上的一篇文章中给出的,node 事件循环简化图
图中的每个框被称为事件循环机制的一个阶段,每个阶段都有一个 FIFO 队列来执行回调。虽然每个阶段都是特殊的,但通常情况下,当事件循环进入给定的阶段时,它将执行特定于该阶段的任何操作,然后执行该阶段队列中的回调,直到队列用尽或最大回调数已执行。当该队列已用尽或达到回调限制,事件循环将移动到下一阶段。
注:先入先出队列 (First Input First Output,FIFO),这是一种传统的按序执行方法,先进入的指令先完成并引退,跟着才执行第二条指令。
因此,从上面这个简化图中,我们可以分析出 node 的事件循环的阶段顺序为:
输入数据阶段(incoming data)->轮询阶段(poll)->检查阶段(check)->关闭事件回调阶段(close callback)->定时器检测阶段(timers)->I/O事件回调阶段(I/O callbacks)->闲置阶段(idle, prepare)->轮询阶段…
◾ 阶段概述
- 定时器检测阶段(timers):本阶段执行 timer 的回调,即 setTimeout、setInterval 里面的回调函数。
- I/O事件回调阶段(I/O callbacks):执行延迟到下一个循环迭代的 I/O 回调,即上一轮循环中未被执行的一些I/O回调。
- 闲置阶段(idle, prepare):仅系统内部使用。
- 轮询阶段(poll):检索新的 I/O 事件;执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些由计时器和 setImmediate() 调度的之外),其余情况 node 将在适当的时候在此阻塞。
- 检查阶段(check):setImmediate() 回调函数在这里执行
- 关闭事件回调阶段(close callback):一些关闭的回调函数,如:socket.on(‘close’, …)。
◾ 三大重点阶段
日常开发中的绝大部分异步任务都是在 poll、check、timers 这3个阶段处理的,所以我们来重点看看。
▪ timers
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。 同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
▪ poll
poll 是一个至关重要的阶段,poll 阶段的执行逻辑流程图如下:
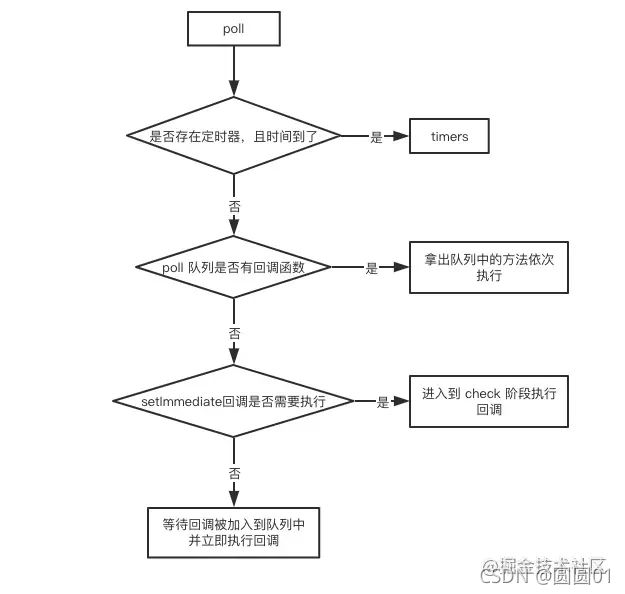
如果当前已经存在定时器,而且有定时器到时间了,拿出来执行,eventLoop 将回到 timers 阶段。
如果没有定时器, 会去看回调函数队列。
▪ 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
▪ 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去,一段时间后自动进入 check 阶段。
▪ check
check 阶段。这是一个比较简单的阶段,直接执行 setImmdiate 的回调。
▪ process.nextTick
process.nextTick 是一个独立于 eventLoop 的任务队列。
在每一个 eventLoop 阶段完成后会去检查 nextTick 队列,如果里面有任务,会让这部分任务优先于微任务执行。
看一个例子:
setImmediate(() => {
console.log('timeout1')
Promise.resolve().then(() => console.log('promise resolve'))
process.nextTick(() => console.log('next tick1'))
});
setImmediate(() => {
console.log('timeout2')
process.nextTick(() => console.log('next tick2'))
});
setImmediate(() => console.log('timeout3'));
setImmediate(() => console.log('timeout4'));
▪ 在 node11 之前,因为每一个 eventLoop 阶段完成后会去检查 nextTick 队列,如果里面有任务,会让这部分任务优先于微任务执行,因此上述代码是先进入 check 阶段,执行所有 setImmediate,完成之后执行 nextTick 队列,最后执行微任务队列,因此输出为:
timeout1
timeout2
timeout3
timeout4
next tick1
next tick2
promise resolve
▪ 在 node11 之后,process.nextTick 是微任务的一种,因此上述代码是先进入 check 阶段,执行一个 setImmediate 宏任务,然后执行其微任务队列,再执行下一个宏任务及其微任务,因此输出为:
timeout1
next tick1
promise resolve
timeout2
next tick2
timeout3
timeout4
我们可以看一下上述代码在node环境中的执行情况:
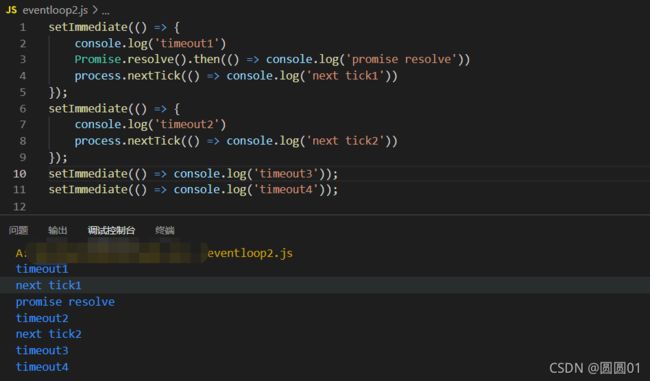
注:本人node版本为 v14.15.4
![]()
node 版本差异
这里主要说明的是 node11 前后的差异,因为 node11 之后一些特性已经向浏览器看齐了,总的变化一句话来说就是,如果是 node11 版本一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行对应的微任务队列,一起来看看吧~
◾ timers 阶段的执行时机变化
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
在node环境中的执行情况 (node版本 v14.15.4):
![]()
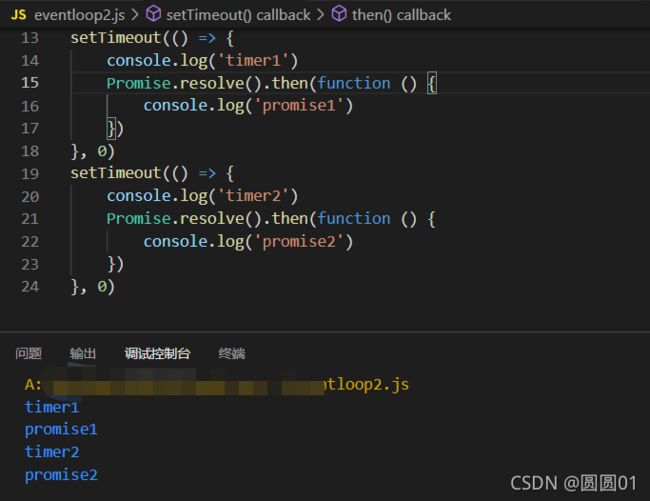
▪ 如果是 node11 以上版本,一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这就跟浏览器端运行一致,最后的结果为
timer1
promise1
timer2
promise2
▪ 如果是 node10 及其之前版本要看第一个定时器执行完,第二个定时器是否在完成队列中.
- 如果是第二个定时器还未在完成队列中,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是第二个定时器已经在完成队列中,则最后的结果为
timer1=>timer2=>promise1=>promise2
◾ check 阶段 和 nextTick 队列的执行时机变化和上述类似,这里就不再赘述。
通过上面的几个例子,我们应该可以清晰感受到它的变化了,反正记着一个结论,node11 以后的版本 一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行对应的微任务队列。
参考
- 详解JavaScript中的Event Loop(事件循环)机制 - 苍青浪
- Node.js 事件循环 (nodejs.cn)
- 深入理解JavaScript事件循环机制 - ChessZhang
- 这一次,彻底弄懂 JavaScript 执行机制
- 面试题:说说事件循环机制(满分答案来了)
- 一次弄懂Event Loop(彻底解决此类面试问题)
- 微任务、宏任务与Event-Loop