pythonweb开发实战pdf百度贴吧_爬虫大全,爬虫工具汇总
开源爬虫
开发语言
软件名称
软件介绍
许可证
Java
Arachnid
微型爬虫框架,含有一个小型 HTML 解析器。是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。 Arachnid的下载包中包含两个spider应用程序例子用于演示如何使用该框架。
http://arachnid.sourceforge.net/
GPL
crawlzilla
安装简易,拥有中文分词功能。
Apache2
Ex-Crawler
由守护进程执行,使用数据库存储网页信息。
GPLv3
Heritrix
一个互联网档案馆级的爬虫,设计的目标是对大型网络的大部分内容的定期存档快照,用 java 编写。严格遵照 robots 文件的排除指示和 META robots 标签。http://crawler.archive.org/
LGPL
heyDr
轻量级开源多线程垂直检索爬虫框架。
GPLv3
ItSucks
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。下载地址:http://itsucks.sourceforge.net/
不详
jcrawl
轻量、性能优良,可以从网页抓取各种类型的文件。
Apache
JSpider
在 GPL 许可下发行,高度可配置、可定制、功能强大、容易扩展的网络爬虫引擎。你可以利用它来检查网站的错误(内在的服务器错误等),网站内外部链接检查,分析网站的结构(可创建一个网站地图),下载整个Web站点,你还可以写一个JSpider插件来扩展你所需要的功能。
LGPL
Leopdo
包括全文和分类垂直搜索,以及分词系统。
Apache
MetaSeeker
网页抓取、信息提取、数据抽取工具包,操作简单。
不详
Playfish
通过 XML 配置文件实现高度可定制性与可扩展性。
MIT
Spiderman
灵活、扩展性强,微内核+插件式架构,通过简单的配置就可以完成数据抓取,无需编写一句代码。
Apache
webmagic
功能覆盖整个爬虫生命周期,使用 Xpath 和正则表达式进行链接和内容的提取。
Apache
Web-Harvest
运用 XSLT、XQuery、正则表达式等技术来实现对 Text 或 XML 的操作,具有可视化的界面。Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。
http://web-harvest.sourceforge.net
BSD
WebSPHINX
(Miller and Bharat, 1998) 由 java 类库构成,基于文本的搜索引擎。它使用多线程进行网页检索,html 解析,拥有一个图形用户界面用来设置开始的种子 URL 和抽取下载的数据;WebSPHINX 由两部分组成:爬虫工作平台和 WebSPHINX 类包。由两部分组成:爬虫工作平台和WebSPHINX类包。
http://www.cs.cmu.edu/~rcm/websphinx/
Apache
YaCy
基于 P2P 网络的免费分布式 Web 搜索引擎(在 GPL 许可下发行)。其核心是分布在数百台计算机上的被称 为YaCy-peer的计算机程序,基于P2P网络构成了YaCy网络,整个网络是一个分散的架构,在其中所有的YaCy-peers都处于对等的地位, 没有统一的中心服务器,每个YaCy-peer都能独立的进行互联网的爬行抓取、分析及创建索引库,通过P2P网络与其他YaCy-peers进行共享, 并且每个YaCy-peer又都是一个独立的代理服务器,能够对本机用户使用过的网页进行索引,并且采取多机制来保护用户的隐私,同时用户也通过本机运行 的Web服务器进行查询及返回查询结果。
YaCy搜索引擎主要包括五个部分,除普通搜索引擎所具有的爬行器、索引器、反排序的索引库外,它还包括了一个非常丰富的搜索与管理界面以及用于数据共享的P2P网络。
GPL
Nutch
用 java 编写,在 Apache 许可下发行的爬虫。它可以用来连接 Lucene 的全文检索套件。Nutch是Lucene的作者Doug
Cutting发起的另一个开源项目,它是构建于Lucene基础上的完整的Web搜索引擎系统,虽然诞生时间不长,但却以其优良血统及简洁方便的使用方
式而广收欢迎。我们可以使用Nutch搭建类似Google的完整的搜索引擎系统,进行局域网、互联网的搜索。
Apache
Agent Kernel
当一个爬虫抓取时,用来进行安排,并发和存储的 java 框架。
/
Dine
一个多线程的 java 的 http 客户端。它可以在 LGPL 许可下进行二次开发。
LGPL
Python
QuickRecon
具有查找子域名名称、收集电子邮件地址并寻找人际关系等功能。
GPLv3
PyRailgun
简洁、轻量、高效的网页抓取框架。
MIT
Scrapy
基于 Twisted 的异步处理框架,文档齐全。
BSD
Ruya
一个在广度优先方面表现优秀,基于等级抓取的开放源代码的网络爬虫。在英语和日语页面的抓取表现良好,它在 GPL 许可下发行,并且完全用 Python 编写。按照 robots.txt 有一个延时的单网域延时爬虫。
GPL
PySipder
C
GNU Wget
一个在 GPL 许可下用 C 语言编写的命令行式的爬虫。主要用于网络服务器和 FTP 服务器的镜像。
GPL
HTTrack
HTTrack 用网络爬虫创建网络站点镜像,以便离线观看。它使用 C 语言编写,在 GPL 许可下发行。
GPL
Methabot
用 C 语言编写,高速优化,可使用命令行方式运行,在 2-clause BSD 许可下发布的网页检索器。它的主要的特性是高可配置性,模块化;它检索的目标可以是本地文件系统,HTTP 或者 FTP。2013后不再更新。
BSD
Pavuk
在 GPL 许可下发行,使用命令行的 WEB 站点镜像工具,可以选择使用 X11 的图形界面。与 wget 和 httprack 相比,他有一系列先进特性,如以正则表达式为基础的文件过滤规则和文件创建规则。2013后不再更新。
GPL
C++
hispider
支持多机分布式下载,支持网站定向下载。严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
BSD
larbin
高性能的爬虫软件,只负责抓取不负责解析。拥有易于操作的界面,不过只能跑在LINUX下,在一台普通PC下larbin每天可以爬5百万个页面(当然啦,需要拥有良好的网络), 2013年后已停止维护.
http://larbin.sourceforge.net/index-eng.html
GPL
ICDL Crawler
用 C++ 编写,跨平台的网络爬虫。它仅仅使用空闲 CPU 资源,在 ICDL 标准上抓取整个站点。
/
Methanol
模块化、可定制的网页爬虫,速度快。
不详
WIRE
网络信息检索环境 (Baeza-Yates 和 Castillo, 2002) 用 C++ 编写,在 GPL 许可下发行的爬虫,内置了几种页面下载安排的策略,还有一个生成报告和统计资料的模块,所以,它主要用于网络特征的描述。
GPL
C#
NWebCrawler
统计信息、执行过程可视化。
GPLv2
Sinawler
国内第一个针对微博数据的爬虫程序,功能强大。
GPLv3
spidernet
以递归树为模型的多线程 web 爬虫程序,支持以 GBK (gb2312) 和 utf8 编码的资源,使用 sqlite 存储数据。
MIT
Web Crawler
为 .net 准备的开放源代码的网络检索器。多线程,支持抓取 PDF/DOC/EXCEL 等文档来源。http://www.ideagrace.com/sf/web-crawler/
LGPL
网络矿工
功能丰富,毫不逊色于商业软件。
BSD
Arachnod.net
是一个使用C#编写,需要SQL Server 2005支持的,在GPL许可下发行的多功能的开源的机器人。它可以用来下载,检索,存储包括电子邮件地址,文件,超链接,图片和网页在内的各种数据。
PHP
OpenWebSpider
开源多线程网络爬虫,有许多有趣的功能。
不详
PhpDig
适用于专业化强、层次更深的个性化搜索引擎。PHPdig是国外非常流行的垂直搜索引擎产品(与其说是产品,不如说是一项区别于传统搜索引擎的搜索技术),采用PHP语言编写,利用了PHP程序运行 的高效性,极大地提高了搜索反应速度,它可以像Google或者Baidu以及其它搜索引擎一样搜索互联网,搜索内容除了普通的网页外还包括txt, doc, xls, pdf等各式的文件,具有强大的内容搜索和文件解析功能。
GPL
Snoopy
具有采集网页内容、提交表单功能。
GPL
ThinkUp
采集推特、脸谱等社交网络数据的社会媒体视角引擎,可进行交互分析并将结果以可视化形式展现。
GPL
微购
可采集淘宝、京东、当当、等 300 多家电子商务数据。
GPL
ErLang
Ebot
可伸缩的分布式网页爬虫。
GPLv3
Ruby
Spidr
可将一个或多个网站、某个链接完全抓取到本地。
MIT
Perl
LWP:RobotUA
(Langheinrich, 2004) 是一个在 Perl5 许可下发行的,可以优异的完成并行任务的 Perl 类库构成的机器人。
Perl5
其它
DataparkSearch
一个在 GNU GPL 许可下发布的爬虫搜索引擎。
GPL
Ht://Dig
在它和索引引擎中包括一个网页爬虫。
/
WebVac
斯坦福 WebBase 项目使用的一个爬虫。
/
Sherlock Holmes
收集和检索本地和网络上的文本类数据(文本文件,网页),该项目由捷克门户网站中枢(Czech web portal Centrum)赞助并且主要用于商用。
/
Universal Information Crawler
快速发展的网络爬虫,用于检索存储和分析数据。
/
其它爬虫
开发语言
软件名称
作者
发布时间
软件介绍
许可证
/
RBSE
Eichmann
1994 年
第一个发布的爬虫。它有 2 个基础程序。第一个是 “spider”,抓取队列中的内容到一个关系数据库中,第二个程序是 “mite”,是一个修改后的 www 的 ASCII 浏览器,负责从网络上下载页面。
/
Web Crawler
Pinkerton
1994 年
是第一个公开可用的用来建立全文索引的一个子程序,他使用库 www 来下载页面;另外一个程序使用广度优先来解析获取 URL 并对其排序;它还包括一个根据选定文本和查询相似程度爬行的实时爬虫。
/
World Wide Web Worm
McBryan
1994 年
用来为文件建立包括标题和URL 简单索引的爬虫。索引可以通过 grep 式的 Unix 命令来搜索。
C++、Python
Google Crawler
Brin and Page
1998 年
用了一些细节来描述,但是这些细节仅仅是关于使用 C++ 和 Python 编写的、一个早期版本的体系结构。因为文本解析就是全文检索和 URL 抽取的过程,所以爬虫集成了索引处理。这里拥有一个 URL 服务器,用来给几个爬虫程序发送要抓取的 URL 列表。在解析文本时,新发现的 URL 传送给 URL 服务器并检测这个 URL 是不是已经存在,如果不存在的话,该URL 就加入到 URL 服务器中。
Perl
CobWeb
da Silva et al.
1999 年
使用了一个中央 “调度者” 和一系列的 “分布式搜集者”。搜集者解析下载的页面并把找到的 URL 发送给调度者,然后调度者反过来分配给搜集者。调度者使用深度优先策略,并且使用平衡礼貌策略来避免服务器超载。爬虫是使用 Perl 语言编写的。
Java
Mercator
Heydon and Najork
1999 年
一个分布式的,模块化的使用 java 编写的网络爬虫。它的模块化源自于使用可互换的 “协议模块” 和 “处理模块”。协议模块负责怎样获取网页(譬如:使用 HTTP),处理模块负责怎样处理页面。标准处理模块仅仅包括了解析页面和抽取 URL,其他处理模块可以用来检索文本页面,或者搜集网络数据。
Java
Mercator
Najork and Heydon
2001 年
一个分布式的,模块化的使用 java 编写的网络爬虫。它的模块化源自于使用可互换的 “协议模块” 和 “处理模块”。协议模块负责怎样获取网页(譬如:使用 HTTP),处理模块负责怎样处理页面。标准处理模块仅仅包括了解析页面和抽取 URL,其他处理模块可以用来检索文本页面,或者搜集网络数据。
C++
WebFountain
Edwards et al.
2001 年
一个与 Mercator 类似的分布式的模块化的爬虫,但使用 C++ 编
写。它的特点是一个管理员机器控制一系列的蚂蚁机器。经过多次下载页面后,页面的变化率可以推测出来,这时,一个非线性的方法必须用于求解方程以获得一个
最大的新鲜度的访问策略。作者推荐在早期检索阶段使用这个爬虫,然后用统一策略检索,就是所有的页面都使用相同的频率访问。
C++、Python
PolyBot
Shkapenyuk and Suel
2002 年
一个使用 C++ 和 Python 编写的分布式网络爬虫。它由一个爬虫管理者,一个或多个下载者,一个或多个 DNS 解析者组成。抽取到的 URL 被添加到硬盘的一个队列里面,然后使用批处理的模式处理这些 URL。平衡礼貌方面考虑到了第 2、3 级网域,因为第 3 级网域通常也会保存在同一个网络服务器上。
Java
WebRACE
Zeinalipour-Yazti and Dikaiakos
2002 年
一个使用 java 实现的,拥有检索模块和缓存模块的爬虫,它是一个很通用的称作 eRACE 的系统的一部分。系统从用户得到下载页面请求,爬虫行为有点像一个聪明的代理服务器。系统还监视订阅网页请求,当网页发生改变时,它必须使爬虫下载更新这个页面并且通知订阅者。WebRACE 最大的特色是,当大多数的爬虫都从一组 URL 开始时,WebRACE 可连续接收抓取开始的 URL 地址。
/
FAST Crawler
Risvik and Michelsen
2002 年
一个分布式爬虫,在 Fast Search & Transfer 中使用,关于其体系结构的一个大致的描述可以在 [citation needed] 找到。
/
Cho
Cho and Garcia-Molina
2002 年
一般爬虫体系结构。
/
Chakrabarti
Chakrabarti
2003 年
一般爬虫体系结构。
Java
Ubicrawe
Boldi et al.
2004 年
一个使用 java 编写的分布式爬虫。它没有中央程序。它有一组完全相同的代理组成,分配功能通过主机前后一致的散列计算进行。这里没有重复的页面,除非爬虫崩溃了(然后,另外一个代理就会接替崩溃的代理重新开始抓取)。爬虫设计为高伸缩性和允许失败的。
/
Labrador
/
/
/
eezirCrawler
/
/
一个非开源的可伸缩的网页抓取器,在 Teezir 上使用。该程序被设计为一个完整的可以处理各种类型网页的爬虫,包括各种 JavaScript 和 HTML 文档。爬虫既支持主题检索也支持非主题检索。
Java
Spinn3r
/
/
一个通过博客构建反馈信息的爬虫。 Spinn3r 基于 java,它的大部分的体系结构都是开源的。
C、PHP
HotCrawler
/
/
一个使用 C 语言和 php 编写的爬虫。
/
ViREL Microformats Crawler
/
WebLech
WebLech是一个功能强大的Web站点下载与镜像工具。它支持按功能需求来下载web站点并能够尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
http://weblech.sourceforge.net/
Arale
Arale主要为个人使用而设计,而没有像其它爬虫一样是关注于页面索引。Arale能够下载整个web站点或来自web站点的某些资源。Arale还能够把动态页面映射成静态页面。
http://web.tiscali.it/_flat/arale.jsp.html
spindle
spindle 是一个构建在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spindle项目提供了一组JSP标签库使得那些基于JSP的站点不需要开发任何Java类就能够增加搜索功能。
http://www.bitmechanic.com/projects/spindle/
LARM
LARM能够为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含能够为文件,数据库表格建立索引的方法和为Web站点建索引的爬虫。
http://larm.sourceforge.net/
JoBo
JoBo 是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能够自动填充form(如:自动登录)和使用cookies来处理session。JoBo还有灵活的下载规则(如:通过网页的URL,大小,MIME类型等)来限制下载。
http://www.matuschek.net/software/jobo/index.html
snoics-reptile
snoics -reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方式获取到的资源全部抓取到本地,包括网页和各种类型的文件,如:图片、flash、mp3、zip、rar、exe等文件。可以将整个网站完整地下传至硬盘内,并能保持原有的网站结构精确不变。只需要把抓取下来的网站放到web服务器(如:Apache)中,就可以实现完整的网站镜像。
http://www.blogjava.net/snoics
spiderpy
spiderpy是一个基于Python编码的一个开源web爬虫工具,允许用户收集文件和搜索网站,并有一个可配置的界面。
http://pyspider.sourceforge.net/
The Spider Web Network Xoops Mod Team
pider Web Network Xoops Mod是一个Xoops下的模块,完全由PHP语言实现。
http://www.tswn.com/
Fetchgals
Fetchgals是一个基于perl多线程的Web爬虫,通过Tags来搜索色情图片。
https://sourceforge.net/projects/fetchgals
apache tika。项目地址为http://tika.apache.org/ 。tika使用解析器从文档中发现以及提取元数据和文本内容。
php开源网络爬虫
2、Sphider is a lightweight web spider and search engine written in PHP, using MySQL as its back end database. It is a great tool for adding search functionality to your web site or building your custom search engine. Sphider is small, easy to set up and modify, and is used in thousands of websites across the world.
Sphider supports all standard search options, but also includes a plethora of advanced features such as word autocompletion, spelling suggestions etc. The sophisticated adminstration interface makes administering the system easy. The full list of Sphider features can be seen in the about section; also be sure to check out the demo and take a look at the showcase, displaying some sites running Sphider. If you run into problems, you can probably get an answer to your question in the forum.
3、iSearch
The iSearch PHP search engine allows you to build a searchable database for your web site. Visitors can search for key words and a list of any pages that match is returned to them.
Introduction
iSearch is a tool for allowing visitors to a website to perform a search on the contents of the site. Unlike other such tools the spidering engine is written in PHP, so it does not require binaries to be run on the server to generate the search index for HTML pages.
C#开源示例
http://www.codeproject.com/useritems/ZetaWebSpider.asp
http://www.codeproject.com/aspnet/Spideroo.asp
http://www.codeproject.com/cs/internet/Crawler.asp
开放源代码搜索引擎为人们学习、研究并掌握搜索技术提供了极好的途径与素材,推动了搜索技术的普及与发展,使越来越多的人开始了解并推广使用搜索技术。使用开源搜索引擎,可以大大缩短构建搜索应用的周期,并可根据应用需求打造个性化搜索应用,甚至构建符合特定需求的搜索引擎系统。搜索引擎的开源,无论是对技术人员还是普通用户,都是一个福音。
首先需要一个能访问网络的爬虫器程序,依据URL之间的关联性自动爬行整个互联网,并对爬行过的网页进行抓取收集。当网页被收集回来后,采用索引分析程序进行网页信息的分析,依据一定的相关度算法(如超链接算法)进行大量计算,创建倒排序的索引库。索引库建好后用户就可以通过提供的搜索界面提交关键词进行搜索,依据特定的排序算法返回搜索结果。因此,搜索引擎并不是对互联网进行直接搜索,而是对已抓取网页索引库的搜索,这也是能快速返回搜索结果的原因,索引在其中扮演了最为重要的角色,索引算法的效率直接影响搜索引擎的效率,是评测搜索引擎是否高效的关键因素。
网页爬行器、索引器、查询器共同构成了搜索引擎的重要组成单元,针对特定的语言,如中文、韩文等,还需要分词器进行分词,一般情况下,分词器与索引器一起使用创建特定语言的索引库。它们之间的协同关系如图1所示。
而开放源代码的搜索引擎为用户提供了极大的透明性,开放的源代码、公开的排序算法、随意的可定制性,相比于商业搜索引擎而言,更为用户所需要。目前,开放源代码的搜索引擎项目也有一些,主要集在中搜索引擎开发工具包与架构、Web搜索引擎、文件搜索引擎几个方面,本文概要介绍一下当前比较流行且相对比较成熟的几个搜索引擎项目。
开源搜索引擎工具包
1.Lucene
Lucene是目前最为流行的开放源代码全文搜索引擎工具包,隶属于Apache基金会,由资深全文索引/检索专家Doug Cutting所发起,并以其妻子的中间名作为项目的名称。Lucene不是一个具有完整特征的搜索应用程序,而是一个专注于文本索引和搜索的工具包,能够为应用程序添加索引与搜索能力。基于Lucene在索引及搜索方面的优秀表现,虽然由Java编写的Lucene具有天生的跨平台性,但仍被改编为许多其他语言的版本:Perl、Python、C++、.Net等。
同其他开源项目一样,Lucene具有非常好的架构,能够方便地在其基础上进行研究与开发,添加新功能或者开发新系统。Lucene本身只支持文本文件及少量语种的索引,并且不具备爬虫功能,而这正是Lucene的魅力所在,通过 Lucene提供的丰富接口,我们可以根据自身的需要在其上添加具体语言的分词器,针对具体文档的文本解析器等,而这些具体的功能实现都可以借助于一些已有的相关开源软件项目、甚至是商业软件来完成,这也保证了Lucene在索引及搜索方面的专注性。目前,通过在Lucene的基础上加入爬行器、文本解析器等也形成了一些新的开源项目,如LIUS、Nutch等。并且Lucene的索引数据结构已经成了一种事实上的标准,为许多搜索引擎所采用。
2.LIUS
LIUS即Lucene Index Update and Search的缩写,它是以Lucene为基础发展起来的一种文本索引框架,和Lucene一样,同样可以看作搜索引擎开发工具包。它在Lucene的基础上作了一些相应的研究及添加了一些新的功能。LIUS借助于许多开源软件,可以直接对各种不同格式/类型的文档进行文本解析与索引,这些文档格式包括 MS Word、MS Excel、MS PowerPoing、RTF、PDF、XML、HTML、TXT、Open Office及JavaBeans等,对Java Beans的支持对于进行数据库索引非常有用,在用户进行对象关系映射(如:Hibernate、JDO、TopLink、Torque等)的数据库连接编程时会变得更加精确。LIUS还在Lucene的基础上增加了索引更新功能,使针对索引的维护功能进一步完善。并且支持混和索引,可以把同一目录下与某一条件相关的所有内容整合到一起,这种功能对于需要对多种不同格式的文档同时进行索引时非常有用。
3.Egothor
Egothor是一款开源的高性能全文搜索引擎,适用于基于全文搜索功能的搜索应用,它具有与Luccene类似的核心算法,这个项目已经存在了很多年,并且拥有一些积极的开发人员及用户团体。项目发起者Leo Galambos是捷克布拉格查理大学数学与物理学院的一名高级助理教授,他在博士研究生期间发起了此项目。
更多的时候,我们把Egothor看作一个用于全文搜索引擎的Java库,能够为具体的应用程序添加全文搜索功能。它提供了扩展的Boolean模块,使得它能被作为Boolean模块或者Vector模块使用,并且Egothor具有一些其他搜索引擎所不具有的特有功能:它采用新的动态算法以有效提高索引更新的速度,并且支持平行的查询方式,可有效提高查询效率。在Egothor的发行版中,加入了爬行器、文本解析器等许多增强易用性的应用程序,融入了Golomb、Elias-Gamma等多种高效的压缩方法,支持多种常用文档格式的文本解析,如HTML、PDF、PS、微软Office文档、XLS等,提供了GUI的索引界面及基于Applet或者Web的查询方式。另外,Egothor还能被方便地配置成独立的搜索引擎、元数据搜索器、点对点的HUB等多种且体的应用系统。
4.Xapian
Xapian是基于GPL发布的搜索引擎开发库,它采用C++语言编写,通过其提供绑定程序包可以使Perl、Python、PHP、Java、Tck、C#、Ruby等语言方便地使用它。
Xapian还是一个具有高适应性的工具集,使开发人员能够方便地为他们的应用程序添加高级索引及搜索功能。它支持信息检索的概率模型及丰富的布尔查询操作。Xapian的发布包通常由两部分组成:xapian-core及xapian- bindings,前者是核心主程序,后者是与其他语言进行绑定的程序包。
Xapian为程序开发者提供了丰富的API及文档进行程序的编制,而且还提供了许多编程实例及一个基于Xapian的应用程序Omega,Omega由索引器及基于CGI的前端搜索组成,能够为HTML、PHP、PDF、 PostScript、OpenOffice/StarOffice、RTF等多种格式的文档编制索引,通过使用Perl DBI模块甚至能为MySQL、PostgreSQL、SQLite、Sybase、MS SQL、LDAP、ODBC等关系数据库编制索引,并能以CSV或XML格式从前端导出搜索结果,程序开发者可以在此基础上进行扩展。
5.Compass
Compass是在Lucene上实现的开源搜索引擎架构,相对比于Lucene而言,提供更加简洁的搜索引擎API。增加了索引事务处理的支持,使其能够更方便地与数据库等事务处理应用进行整合。它更新时无需删除原文档,更加简单更加高效。资源与搜索引擎之间采用映射机制,此种机制使得那些已经使用了Lucene或者不支持对象及XML的应用程序迁移到Compass上进行开发变得非常容易。
Compass还能与Hibernate、Spring等架构进行集成,因此如果想在Hibernate、Spring项目中加入搜索引擎功能,Compass是个极好的选择。
开源桌面搜索引擎系统
1.Regain
regain是一款与Web搜索引擎类似的桌面搜索引擎系统,其不同之处在于regain 不是对Internet内容的搜索,而是针对自己的文档或文件的搜索,使用regain可以轻松地在几秒内完成大量数据(许多个G)的搜索。Regain 采用了Lucene的搜索语法,因此支持多种查询方式,支持多索引的搜索及基于文件类型的高级搜索,并且能实现URL重写及文件到HTTP的桥接,并且对中文也提供了较好的支持。
Regain提供了两种版本:桌面搜索及服务器搜索。桌面搜索提供了对普通桌面计算机的文档与局域网环境下的网页的快速搜索。服务器版本主要安装在Web服务器上,为网站及局域网环境下的文件服务器进行搜索。
Regain使用Java编写,因此可以实现跨平台安装,能安装于Windows、 Linux、Mac OS及Solaris上。服务器版本需要JSPs环境及标签库(tag library),因此需要安装一个Tomcat容器。而桌面版自带了一个小型的Web服务器,安装非常简单。
2.Zilverline
Zilverline是一款以Lucene为基础的桌面搜索引擎,采用了Spring框架,它主要用于个人本地磁盘及局域网内容的搜索,支持多种语言,并且具有自己的中文名字:银钱查打引擎。Zilverline提供了丰富的文档格式的索引支持,如微软Office文档、RTF、Java、CHM等,甚至能够为归档文件编制索引进行搜索,如zip、rar及其他归档文件,在索引过程中,Zilverline从zip、rar、chm等归档文件中抽取文件来编制索引。Zilverline可以支持增量索引的方式,只对新文件编制索引,同时也支持定期自动索引,其索引库能被存放于Zilverline能够访问到的地方,甚至是DVD中。同时,Zilverline还支持文件路径到URL 的映射,这样可以使用户远程搜索本地文件。
Zilverline提供了个人及研究、商业应用两种许可方式,其发布形式为一个简单的 war包,可以从其官方网站下载(http://www.zilverline.org/)。Zilverline的运行环境需要Java环境及 Servlet容器,一般使用Tomcat即可。在确保正确安装JDK及Tomcat容器后只需将Zilverline的war包(zilverline-1.5.0.war)拷贝到Tomcat的webapps目录后重启Tomcat容器即可开始使用Zilverline搜索引擎了。
爬虫,即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
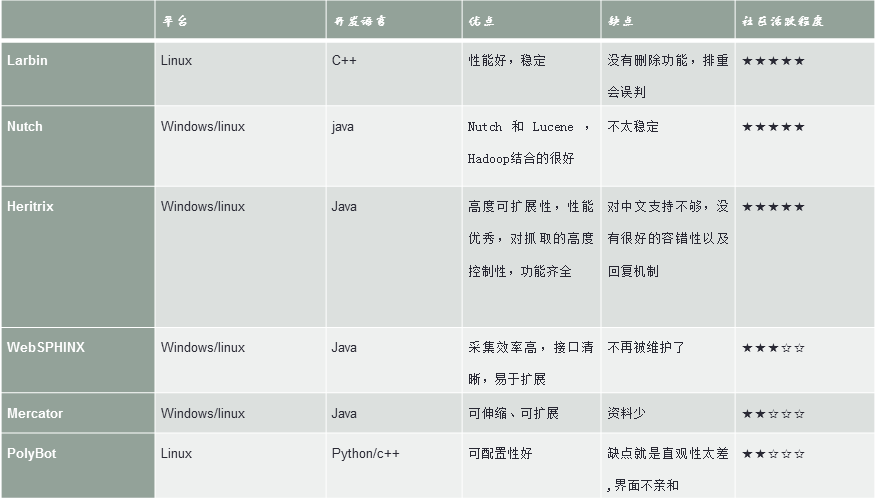
开源爬虫Labin,Nutch,Neritrix介绍和对比
从网上找了一些开源spider的相关资料,整理在下面:
Larbin
开发语言:C++
http://larbin.sourceforge.net/index-eng.html
larbin是个基于C++的web爬虫工具,拥有易于操作的界面,不过只能跑在LINUX下,在一台普通PC下larbin每天可以爬5百万个页面(当然啦,需要拥有良好的网络)
简介
Larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。
Larbin只是一个爬虫,也就是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。
Latbin最初的设计也是依据设计简单但是高度可配置性的原则,因此我们可以看到,一个简单的larbin的爬虫可以每天获取500万的网页,非常高效。
功能
1. larbin 获取单个、确定网站的所有联结,甚至可以镜像一个网站。
2. larbin建立 url 列表群,例如针对所有的网页进行 url retrive后,进行xml的联结的获取。或者是 mp3 。
3. larbin 定制后可以作为搜索引擎的信息的来源(例如可以将抓取下来的网页每2000一组存放在一系列的目录结构里面)。
问题
Labin的主要问题是,:
仅提供保存网页保存功能,没有进行进一步的网页解析;
不支持分布式系统;
功能相对简单,提供的配置项也不够多;
不支持网页自动重访,更新功能;
从2003年底以后,Labin已经放弃更新,目前处于荒芜长草的状态
简介:
Apache的子项目之一,属于Lucene项目下的子项目。
Nutch是一个基于Lucene,类似Google的完整网络搜索引擎解决方案,基于Hadoop的分布式处理模型保证了系统的性能,类似Eclipse的插件机制保证了系统的可客户化,而且很容易集成到自己的应用之中。
总体上Nutch可以分为2个部分:抓取部分和搜索部分。抓取程序抓取页面并把抓取回来的数据做成反向索引,搜索程序则对反向索引搜索回答用户的请求。抓取程序和搜索程序的接口是索引,两者都使用索引中的字段。抓取程序和搜索程序可以分别位于不同的机器上。下面详细介绍一下抓取部分。
抓取部分:
抓取程序是被Nutch的抓取工具驱动的。这是一组工具,用来建立和维护几个不同的数据结构: web database, a set of segments, and the index。下面逐个解释这三个不同的数据结构:
1、The web database, 或者WebDB。这是一个特殊存储数据结构,用来映像被抓取网站数据的结构和属性的集合。WebDB 用来存储从抓取开始(包括重新抓取)的所有网站结构数据和属性。WebDB 只是被 抓取程序使用,搜索程序并不使用它。WebDB 存储2种实体:页面 和 链接。页面 表示 网络上的一个网页,这个网页的Url作为标示被索引,同时建立一个对网页内容的MD5 哈希签名。跟网页相关的其它内容也被存储,包括:页面中的链接数量(外链接),页面抓取信息(在页面被重复抓取的情况下),还有表示页面级别的分数 score。链接 表示从一个网页的链接到其它网页的链接。因此 WebDB 可以说是一个网络图,节点是页面,链接是边。
2、Segment。这是网页的集合,并且它被索引。Segment的Fetchlist 是抓取程序使用的url列表,它是从 WebDB中生成的。Fetcher 的输出数据是从 fetchlist 中抓取的网页。Fetcher的输出数据先被反向索引,然后索引后的结果被存储在segment 中。 Segment的生命周期是有限制的,当下一轮抓取开始后它就没有用了。默认的 重新抓取间隔是30天。因此删除超过这个时间期限的segment是可以的。而且也可以节省不少磁盘空间。Segment 的命名是日期加时间,因此很直观的可以看出他们的存活周期。
3、The index。索引库是反向索引所有系统中被抓取的页面,它并不直接从页面反向索引产生,而是合并很多小的segment的索引产生的。Nutch 使用 Lucene 来建立索引,因此所有Lucene相关的工具 API 都用来建立索引库。需要说明的是Lucene的segment 的概念和Nutch的segment概念是完全不同的,不要混淆。简单来说 Lucene 的 segment 是Lucene 索引库的一部分,而Nutch 的Segment是WebDB中被抓取和索引的一部分。
抓取过程详解:
抓取是一个循环的过程:抓取工具从WebDB中生成了一个 fetchlist 集合;抽取工具根据fetchlist从网络上下载网页内容;工具程序根据抽取工具发现的新链接更新WebDB;然后再生成新的fetchlist;周而复始。这个抓取循环在nutch中经常指: generate/fetch/update 循环。
一般来说同一域名下的 url 链接会被合成到同一个 fetchlist。这样做的考虑是:当同时使用多个工具抓取的时候,不会产生重复抓取的现象。Nutch 遵循 Robots Exclusion Protocol, 可以用robots.txt 定义保护私有网页数据不被抓去。
上面这个抓取工具的组合是Nutch的最外层的,也可以直接使用更底层的工具,自己组合这些底层工具的执行顺序达到同样的结果。这是Nutch吸引人的地方。下面把上述过程分别详述一下,括号内就是底层工具的名字:
1、创建一个新的WebDB (admin db -create)。
2、把开始抓取的跟Url 放入WebDb (inject)。
3、从WebDb的新 segment 中生成 fetchlist (generate)。
4、根据 fetchlist 列表抓取网页的内容 (fetch)。
5、根据抓取回来的网页链接url更新 WebDB (updatedb)。
6、重复上面3-5个步骤直到到达指定的抓取层数。
7、用计算出来的网页url权重 scores 更新 segments (updatesegs)。
8、对抓取回来的网页建立索引(index)。
9、在索引中消除重复的内容和重复的url (dedup)。
10、合并多个索引到一个大索引,为搜索提供索引库(merge)。
*****************
Heritrix
开发语言:Java
http://crawler.archive.org/
Heritrix是一个开源,可扩展的web爬虫项目。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。
简介
Heritrix与Nutch对比
和 Nutch。二者均为Java开源框架,Heritrix 是 SourceForge上的开源产品,Nutch为Apache的一个子项目,它们都称作网络爬虫/蜘蛛( Web Crawler),它们实现的原理基本一致:深度遍历网站的资源,将这些资源抓取到本地,使用的方法都是分析网站每一个有效的URI,并提交Http请求,从而获得相应结果,生成本地文件及相应的日志信息等。
Heritrix 是个 "archival crawler" -- 用来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新爬行对相同的URL不针对先前的进行替换。爬虫通过Web用户界面启动、监控、调整,允许弹性的定义要获取的URL。
Nutch和Heritrix的差异:
Nutch 只获取并保存可索引的内容。Heritrix则是照单全收。力求保存页面原貌
Nutch 可以修剪内容,或者对内容格式进行转换。
Nutch 保存内容为数据库优化格式便于以后索引;刷新替换旧的内容。而Heritrix 是添加(追加)新的内容。
Nutch 从命令行运行、控制。Heritrix 有 Web 控制管理界面。
Nutch 的定制能力不够强,不过现在已经有了一定改进。Heritrix 可控制的参数更多。
Heritrix提供的功能没有nutch多,有点整站下载的味道。既没有索引又没有解析,甚至对于重复爬取URL都处理不是很好。
Heritrix的功能强大 但是配置起来却有点麻烦。
三者的比较
一、从功能方面来说,Heritrix与Larbin的功能类似。都是一个纯粹的网络爬虫,提供网站的镜像下载。而Nutch是一个网络搜索引擎框架,爬取网页只是其功能的一部分。
二、从分布式处理来说,Nutch支持分布式处理,而另外两个好像尚且还没有支持。
三、从爬取的网页存储方式来说,Heritrix和 Larbin都是将爬取下来的内容保存为原始类型的内容。而Nutch是将内容保存到其特定格式的segment中去。
四,对于爬取下来的内容的处理来说,Heritrix和 Larbin都是将爬取下来的内容不经处理直接保存为原始内容。而Nutch对文本进行了包括链接分析、正文提取、建立索引(Lucene索引)等处理。
五,从爬取的效率来说,Larbin效率较高,因为其是使用c++实现的并且功能单一。
crawler
开发
语言
功能
单一
支持分布式
爬取
效率
镜像
保存
Nutch
Java
×
√
低
×
Larbin
C++
√
×
高
√
Heritrix
Java
√
×
中
√
-----------------------------------------------------------
其它一些开源爬虫汇总:
WebSPHINX
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以自动浏览与处理Web页面的程序。WebSPHINX
WebLech
WebLech是一个功能强大的Web站点下载与镜像工具。它支持按功能需求来下载web站点并能够尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
http://weblech.sourceforge.net/
Arale
Arale主要为个人使用而设计,而没有像其它爬虫一样是关注于页面索引。Arale能够下载整个web
J-Spider
J-Spider:是一个完全可配置和定制的Web Spider引擎.你可以利用它来检查网站的错误(内在的服务器错误等),网站内外部链接检查,分析网站的结构(可创建一个网站地图),下载整个Web
spindle
spindle 是一个构建在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spindle项目提供了一组JSP
Arachnid
Arachnid: 是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。Arachnid的下载包中包含两个spider
LARM
LARM能够为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含能够为文件,数据库表格建立索引的方法和为Web
JoBo
JoBo 是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能够自动填充form(如:自动登录)和使用cookies来处理session
snoics-reptile
snoics -reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方式获取到的资源全部抓取到本地,包括网页和各种类型的文件,如:图片、flash、mp3、zip、rar、exe等文件。可以将整个网站完整地下传至硬盘内,并能保持原有的网站结构精确不变。只需要把抓取下来的网站放到web
Web-Harvest
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。Web-Harvest主要是运用了像XSLT,XQuery,
spiderpy
spiderpy是一个基于Python编码的一个开源web
The Spider Web Network Xoops Mod Team
pider Web Network Xoops Mod是一个Xoops
看你需求了。玩python人喜欢用scrapy,heritrix还是比较适合整站直接爬取,不去做二次开发。WebCollector比较适合做有精 准抽取抽取业务的爬虫,很适合做二次开发。Nutch如果你不做搜索引擎,建议不要用,Nutch里面全是是针对搜索引擎优化的。
看需求了,如果你想研究,就去看一些爬虫框架,比如Nutch(分布式的),还有诸如此类的一些。
如果想进行二次开发,处理js页面的话,看看phantomjs这种用浏览器内核的书写。
如果你需求并不是很高,自己动手写一写小的爬虫,在在这些小的爬虫的基础上慢慢的开发出适合自己的一套框架,解析页面用jsoup就好了。
Perl 做爬虫也很爽啊,可以看看mojo框架
前一阵金融系的同学委托我写个Python爬虫从某小额信贷网站爬订单细节(公开的),共20万条,用了多线程还是嫌慢。比较奇怪的是这么频繁的访问它不封我IP…最后一个搞安全的同学帮我直接拖库了。
1024会短时间封IP,用同一个cookie爬就没事了
爬虫下载慢主要原因是阻塞等待发往网站的请求和网站返回
解决的方法是采用非阻塞的epoll模型。
将创建的socket连接句柄和回调函数注册给操作系统,这样在单进程和单线程的情况下可以并发大量对页面的请求。
如果觉得自己写比较麻烦,我用过现成的类库:tornado的异步客户端
http://www.tornadoweb.org/documentation/httpclient.html
如果你打不开增加host或FQ
host地址:
74.125.129.121 http://www.tornadoweb.org
推荐有质量的WebKit相关技术的网站
http://www.fenesky.com
还在持续更新当中。
之前创业公司做过运维总监。爬虫程序可以选择python scrapy架构或者JAVA加多线程中间件用(rabbitmq,activemq等)后端数据(手机号码,物品信息,comments等)直接存储到 mysql或者couchdb,mongodb。图片爬下来之后可存到TFS集群上特别好我一般不告诉别人。
用的语言是python。目前想要爬的同花顺股票行情(http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860),又一次被javascript卡住。因为一页中只显示52条信息,想要看全部的股票数据必须点击下面的页码,是用javascript写的,无法直接用urllib2之类的库处理。试过用webkit(ghost.py)来模拟点击, Headless Webkit,开源的有 PhantomJS 等。能够解析并运行页面上的脚本以索引动态内容是现代爬虫的重要功能之一。Google's Crawler Now Understands JavaScript: What Does This Mean For You?
我手上正好有个比较好的例子。需求:爬取爱漫画上的漫画。问题:图片的名字命名不规则,通过复杂的js代码生成图片的文件名和url,动态加载图片。js代码的模式多样,没有统一的模式。
解决:Py8v库。读取下js代码,加一个全局变量追踪图片的文件名和url,然后Python和这个变量交互,取得某话图片的文件名和url。
全文在此
【原创】最近写的一个比较hack的小爬虫
公司有一套爬虫系统,用特定关键字在搜索引擎上搜索(如Google,百度),流程大致上,从数据库批量取出关键字,然后生成相关搜索引擎的搜索任务,扔到Queue里面,后面一群消费者去爬。多线程的,我想知道如何去设置合理的线程数?
PS:像数据库有最大连接数控制,所以并发数还好控制。没有这种限制,我就不会从IO、CPU方面分析了。
爬虫这种IO密集型,而且是对外网的请求,如果需求的QPS 超过500/s,就用erlang,golang或者其他语言的epoll库。否则就启N个consumer线程处理就好了。爬百度的数据,一个机器的 ip肯定是不够的,先从淘宝上买一堆的http代理肉鸡ip回来再搞。
你这个需求,处理好http代理的问题(设置每个ip的使用间隔放置被ban),
io 方面如果超过500的QPS需求,利用erlang actor 是比较好的选择,如果怕学习成本,可以使用其他语言(java 的nio, c++的libevent的http模块,或者各个语言的epoll封装) 都可以很好的解决。如果QPS比较低,可以开N个线程或者线程池处理,注意线程数不要大于( ulimit -u)
CPU方面,爬虫服务本身,即使是QPS上一千,一个核心基本可以搞定,不需要考虑CPU消耗,如果爬回来的数据需要进行处理,建议使用libxml库,网页解析是CPU密集型的,建议在生产环境测试一下解析性能。
webcollector可定制性强
以前从github上搞到过一个自动爬coursera公开课视频,slides并建好目录的脚本,用它爬了很多很多公开课。。。
然后就束之高阁了。今年再想去用的时候发现网页结构已经变了。。。
这两个我都用过,都是通用搜索引擎爬虫,Heritrix的可定制性强点,有web管理界面使用起来也蛮方便的,可配置的参数很多,但代码复杂度也蛮高 的,二次开发需要读懂他的设计思想。Nutch使用起来就蛮复杂的,一堆的设置,基于命令行的,不利于二次开发。我做的是垂直搜索与数据抓取,这些都不适 合,最终还是选择自己开发了一个爬虫,一般来说,我们最终需要的都不是原始的HTML页面。我们需要对爬到的页面进行分析,将感兴趣的数据转化成结构化的 数据,并存储下来,这才是爬虫的核心价值。
目前来说Java版本的是Lucene,一般可以考虑Solr+Lucene来实现分布式的可容灾的一个索引和检索的平台,如果数据量是海量级别,可参考 Hadoop+Nutch实现,其他的开源技术框架有,Lily(solr+Hbase+hadoop),zoie(实时搜索引擎),Sphider (Sphider是一个轻量级,采用PHP开发的web spider和搜索引擎)。
用过NUTCH,但只用过其中的抓取部分,索引部分没有接触。在垂直抓取方面挺容易上手的,而且基于hadoop,稳定性以及易用性都还可以,基本上大数量抓取无忧。
后面因为考虑到挖掘上的需要,以及抓取目标不特定,改用自己写的了。
现在找到的比较好的框架中有Heritrix和Nutch两个,
从谷歌创始人的论文《The Anatomy of a Large-Scale Hypertextual Web Search Engine
》里可以看到,谷歌一开始的爬虫是用Python写的。
4.3 Crawling the Web
In order to scale to hundreds of millions of web pages, Google has a fast distributed crawling system. A single URLserver serves lists of URLs to a number of crawlers (we typically ran about 3). Both the URLserver and the crawlers are implemented in Python. Each crawler keeps roughly 300 connections open at once. This is necessary to retrieve web pages at a fast enough pace. At peak speeds, the system can crawl over 100 web pages per second using four crawlers. This amounts to roughly 600K per second of data. A major performance stress is DNS lookup. Each crawler maintains a its own DNS cache so it does not need to do a DNS lookup before crawling each document. Each of the hundreds of connections can be in a number of different states: looking up DNS, connecting to host, sending request, and receiving response. These factors make the crawler a complex component of the system. It uses asynchronous IO to manage events, and a number of queues to move page fetches from state to state.
据说现在改成了C++,但是我没有找到明确的材料。
用 Asynccore 之类手写。看看 Twisted 有没有非阻塞、异步的 HTTP client 框架。
用过 multiprocessing 包 + utllib 做 http client 速度相当不理想,线程应该会好但我的直觉是提升有限。
----
推荐 gevent + grequests
很多人提到了grequests(gevent + requests) 但是这东西在2000多个请求之后就崩溃了。(OSerror: Too many open files).推荐用frequests,grequests同样的API,但是更加稳定。
i-trofimtschuk/frequests 路 GitHub
同问,目前在熟悉python的工具,准备系统学习下数据挖掘。用到的软件包包括numpy,nltk,networkx,matplotlib
我还是认真答一下吧,爬虫这种东西在大批量抓去时主要有下面几个量变引发质变的挑战:
1. 出口IP数量,主要是考虑防止被封禁,带宽反而不是大问题,这个问题可以通过搭建NAT出口集群,或者单机多IP的方式实现
2. 本地端口号耗尽,由于爬虫是服务端编程不太常见的主动发起连接的应用,在普通只有一个IP绑定的机器上会受到65535的限制(一般在50000多就会受到限制)
3. 大容量存储的需求,一般都是通过开源或者自己研发的分布式存储系统来实现,像谷歌(GFS)和百度(百灵)都是自研,这里就不展开说了
4. 动态网页的支持,像京东这种网站,内容都是通过类似Facebook的bigpipe一样动态加载的,直接像curl这样抓取看到的页面几乎是空白的,这就要求爬虫能模拟JS的运行,这方面有很多基于v8引擎的开源项目:
CasperJS, a navigation scripting and testing utility for PhantomJS and SlimerJS
PhantomJS | PhantomJS
由于这个需求,爬虫成了CPU密集型的应用了,分布式的需求也就有了
单机爬虫的主要难点在的异步非阻塞网络编程,老生常谈了。先暂时写这么多吧
老老实实的减少请求的频率,慢慢爬
如果你 IP 比较多的话,可以选择做成分布式
如果你有一个访问量还不错的网站,果断写到页面上面让用户帮你爬
小框架有webharvers,大一点的用nutch也行。
数据库比较推荐用nosql,mongodb挺符合需求,建议自己搭框架,比较容易适应各种不同的爬抓方向
抓取用NUTCH,可以脱离hadoop简单用。抽取如果业务不复杂的话,自己做一套就好了,建议尽量采用xpath方案,好配,好测,效率高,避免使用正则;存储的话,千万级内的,用结构化数据库,nosql 的没玩过,不过我想应该没有mysql易用吧?
当爬虫不遵守robots协议时,有没有防止抓取的可能?
一种是分析爬虫特征,尝试过滤爬虫的请求
另外一些可能技巧:
1. 在页面开头放上一些钓鱼的链接(一般人点不到),爬虫会去访问,一访问就把对应的ip封了
2. 页面全是图像
3. 页面内容用javascript来生成
4. 页面上不提供可以供爬虫追踪的链接,跳转都用js触发
但是我觉得方法并不好。假若来的爬虫是googlebot类似的搜索引擎爬虫,你这个站岂不是就不要想出现在搜索引擎上了。
所以我觉得,最最靠谱的方法是在robots.txt里放上钓鱼连接。
正常的搜索引擎不会去访问,不遵守robots规定的也被禁止了。
还有就是限制ip的请求次数把。
但是想完全杜绝爬虫是不可能的。因为完全没有办法确定请求的背后到底是人还是爬虫。
这就是为啥现在大家都拿Webkit改成爬虫啊。去搜crawler based on webkit有一大堆。要对付的问题无非就是这么几种:
1)后期行为生成/消除的内容
2)人机读取页面的行为差异
题主的例子,只要在DOM中找到这个链接元素然后去找它对应渲染的页面上是否存在就行了。这并不是反反爬虫专用的,事实上用来反SEO这也是常用的方法。
Socket error 10054 - connection reset by peer 连接被远端重置。 Server并发的连接数超过其承载量时,就会把一些连接重置掉。如果无法修改Server段,Client这边所能做的只有减少并发量
golang写的爬虫遇到js加载动态内容
自己写了一个golang的爬虫,在抓取网页的时候,发现部分信息是js运行后生成的,有什么办法可以获取这些信息
分析js代码然后用go生成,有时js混淆得好或者算法诡异,分析不是很容易。
或者直接用cgo跑WebkitGTK+,也就是PhantomJS的套路,sourcegraph做了个。
sourcegraph/webloop · GitHub
python下有个ghost.py入门简单,可以试试
你可以试试换一种思路, 去GoDaddy的注册页试试, 不断提交域名到搜索接口, 它会告诉你是否这个域名有没有被注册的~~~
要代码的话万能图片爬虫这里有
如何维护爬虫程序中的代理ip库
代理ip有的变得连接很慢,甚至连不上,有什么样的机制可以让ip列表保持较好的可用性?
第一,从API接口获取100个代理IP,备用。API接口可以百度搜下全网代理IP,他们有提供;
第二,响应速度慢的直接删除;如果列表删除没了,重复执行第一步;
第三,从IP列表中获取一个IP访问目标网址,如果这个IP访问失败,从IP库删除这个IP,重新执行第三部。
把响应时间纪录下来
目前反爬虫机制有哪些手段,使用代理ip来规避的做法用nodejs具体要怎么做?修改
目前我初学爬虫,尽管简单的数据能抓下来,但是看了很多文章,里面有提到一些反爬虫的机制的,比如这两篇:
互联网网站的反爬虫策略浅析
Python简单抓取原理引出分布式爬虫
这里面都提到了用ip来反爬虫,第二篇文章也提到了用代理池来避免,但是还是不大明白,这些代理ip如果用nodejs要怎么弄?修改
对于淘宝(不开放API的) 一般的透明代理一点用都没有
这个并不是乱码,
只是存储时会作为unicode来存,显示的时候会是中文的
print u'\u4e0d\u662f\u4e71\u7801' , 即可显示中文
python 如何抓取动态页面
我找过用webkit pyQt spynner 和 ghost的,具体怎么操作?
我想封装成一个输入url然后得到最后html的功能
页面抓取与动态静态无关,重要的是模拟浏览器、用户行为。
关键点:
1. 伪装浏览器(user agent等)
2. 伪装用户行为(cookie,session维护,验证码等)
能够做到这两点,无论你用什么抓取工具/包,或者urllib2,都没有质的差别。
splinter
用firefox的分析工具,进行抓包分析。
推荐一个很好的blog:在路上
里面有很多python抓取的教程,最关键是,代码都是全的可以跑出来的,我已经试过了
熟悉python、熟悉爬虫框架的话,可以用scrapy,缺点在于它依赖的库特别特别多。
初学爬虫的话,http请求用urllib2、urllib(后者几乎仅用来编码post数据),字符串解析用BeautifulSoup或者其他类似的,BeautifulSoup非常易学,其他的没用过
进阶的话用selenium+phantom(或者Chrome、FireFox等),这就是一个功能完善的浏览器了,既可以用于http请求,也可以解析网页,都非常方便
搜索C++ HTTP,C++ HTML解析不就有答案了
Beautiful Soup。名气大,整合了一些常用爬虫需求。缺点:不能加载JS。
Scrapy。看起来很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如weibo的页面信息,这个框架就满足不了需求了。
mechanize。优点:可以加载JS。缺点:文档严重缺失。不过通过官方的example以及人肉尝试的方法,还是勉强能用的。
selenium。这是一个调用浏览器的driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
cola。一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高,不过值得借鉴。
以下是我的一些实践经验:
对于简单的需求,比如有固定pattern的信息,怎么搞都是可以的。
对于较为复杂的需求,比如爬取动态页面、涉及状态转换、涉及反爬虫机制、涉及高并发,这种情况下是很难找到一个契合需求的库的,很多东西只能自己写。
至于题主提到的:
还有,采用现有的Python爬虫框架,相比与直接使用内置库,优势在哪?因为Python本身写爬虫已经很简单了。
third party library可以做到built-in library做不到或者做起来很困难的事情,仅此而已。还有就是,爬虫简不简单,完全取决于需求,跟Python是没什么关系的。
要处理 js 运行后的结果,可以使用 html5lib。
但我觉得最好的是用 beautifulsoup4 的接口,让它内部用 html5lib。
自己写爬虫的话,用一些异步事件驱动库,如gevent,比单纯多线程要好很多。
然后用beautifsoup解析,挑一些自己感兴趣的数据,比如打分、评论、商家、分类什么的。然后用一些科学库做一些简单的统计和报表,比如 numpy、scipy、matplotlib等。网上也有好多数据生成报表的 js 库,很酷炫,也很不错的 :)
python写爬虫还是不错的,不过用爬虫框架来写,还真没有尝试过,打算尝试下,准备搞个大规模的数据抓取
使用python做网络爬虫,网上的资源很多,我搞不清为什么很多人和机构都热衷于用python做网络爬虫,大概是因为python在这方面提供的支持库比较多也比较容易实现吧。现有的比较典型的开源爬虫架构如scrapy(python实现),其实现的功能已经比较全面了,最早的时候想了解网络爬虫的原理的时候,曾经尝试过使用scrapy定制,scrapy已经实现了比较复杂的爬虫功能,官方文档也介绍的很详细。
爬虫的GUI框架使用Tkinter,Tkinter支持很多语言,比如ruby,perl,python等,是一个比较简单图形界面库,之所以不采用其他第三方GUI框架是因为这些框架很多只支持python2.7.*以前的版本,而我这里用的python3.4.1,无奈选择了最方便的方法。
下面是程序的界面:
下面我们再对Nutch、Larbin、Heritrix这三个爬虫进行更细致的比较:
Nutch
开发语言:Java
http://lucene.apache.org/nutch/
简介:
Apache的子项目之一,属于Lucene项目下的子项目。
Nutch是一个基于Lucene,类似Google的完整网络搜索引擎解决方案,基于Hadoop的分布式处理模型保证了系统的性能,类似Eclipse的插件机制保证了系统的可客户化,而且很容易集成到自己的应用之中。
Larbin
开发语言:C++
简介
larbin是一种开源的网络爬虫,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。
Larbin只是一个爬虫,也就是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。
latbin最初的设计也是依据设计简单但是高度可配置性的原则,因此我们可以看到,一个简单的larbin的爬虫可以每天获取500万的网页,非常高效。
Heritrix
开发语言:Java
简介
与Nutch比较
和 Nutch。二者均为Java开源框架,Heritrix 是 SourceForge上的开源产品,Nutch为Apache的一个子项目,它们都称作网络爬虫它们实现的原理基本一致:深度遍历网站的资源,将这些资 源抓取到本地,使用的方法都是分析网站每一个有效的URI,并提交Http请求,从而获得相应结果,生成本地文件及相应的日志信息等。
Heritrix 是个 "archival crawler" -- 用来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新 爬行对相同的URL不针对先前的进行替换。爬虫通过Web用户界面启动、监控、调整,允许弹性的定义要获取的URL。
二者的差异:
Nutch 只获取并保存可索引的内容。Heritrix则是照单全收。力求保存页面原貌
Nutch 可以修剪内容,或者对内容格式进行转换。
Nutch 保存内容为数据库优化格式便于以后索引;刷新替换旧的内容。而Heritrix 是添加(追加)新的内容。
Nutch 从命令行运行、控制。Heritrix 有 Web 控制管理界面。
Nutch 的定制能力不够强,不过现在已经有了一定改进。Heritrix 可控制的参数更多。
Heritrix提供的功能没有nutch多,有点整站下载的味道。既没有索引又没有解析,甚至对于重复爬取URL都处理不是很好。
Heritrix的功能强大 但是配置起来却有点麻烦。
其中Nutch和Heritrix比较流行
httpclient不错
主要看你定义的“爬虫”干什么用。
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,那么用什么语言差异不大。
当然要是页面结构复杂,正则表达式写得巨复杂,尤其是用过那些支持xpath的类库/爬虫库后,就会发现此种方式虽然入门门槛低,但扩展性、可维护性等都奇差。因此此种情况下还是推荐采用一些现成的爬虫库,诸如xpath、多线程支持还是必须考虑的因素。
2、如果是定向爬取,且主要目标是解析js动态生成的内容
此时候,页面内容是有js/ajax动态生成的,用普通的请求页面->解析的方法就不管用了,需要借助一个类似firefox、chrome浏览器的js引擎来对页面的js代码做动态解析。
此种情况下,推荐考虑casperJS+phantomjs或slimerJS+phantomjs ,当然诸如selenium之类的也可以考虑。
3、如果爬虫是涉及大规模网站爬取,效率、扩展性、可维护性等是必须考虑的因素时候
大规模爬虫爬取涉及诸多问题:多线程并发、I/O机制、分布式爬取、消息通讯、判重机制、任务调度等等,此时候语言和所用框架的选取就具有极大意义了。
PHP对多线程、异步支持较差,不建议采用。
NodeJS:对一些垂直网站爬取倒可以,但由于分布式爬取、消息通讯等支持较弱,根据自己情况判断。
Python:强烈建议,对以上问题都有较好支持。尤其是Scrapy框架值得作为第一选择。优点诸多:支持xpath;基于twisted,性能不错;有较好的调试工具;
此种情况下,如果还需要做js动态内容的解析,casperjs就不适合了,只有基于诸如chrome V8引擎之类自己做js引擎。
至于C、C++虽然性能不错,但不推荐,尤其是考虑到成本等诸多因素;对于大部分公司还是建议基于一些开源的框架来做,不要自己发明轮子,做一个简单的爬虫容易,但要做一个完备的爬虫挺难的。
像我搭建的微信公众号内容聚合的网站http://lewuxian.com就是基于Scrapy做的,当然还涉及消息队列等。可以参考下图:
简单的定向爬取:
Python + urlib2 + RegExp + bs4
或者
Node.js + co,任一一款dom框架或者html parser + Request + RegExp 撸起来也是很顺手。
对我来说上面两个选择差不多是等价的,但主要我JS比较熟,现在选择Node平台会多一些。
上规模的整站爬取:
Python + Scrapy
如 果说上面两个方案里DIY 的 spider是小米加步枪,那Scrapy简直就是重工加农炮,好用到不行,自定义爬取规则,http错误处理,XPath,RPC,Pipeline机 制等等等。而且,由于Scrapy是基于Twisted实现的,所以同时兼顾有非常好的效率,相对来说唯一的缺点就是安装比较麻烦,依赖也比较多,我还算 是比较新的osx,一样没办法直接pip install scrapy
另外如果在spider中引入xpath的话,再在chrome上安装xpath的插件,那么解析路径一目了然,开发效率奇高。
估计和我一样在Windows开发、部署到linux服务器的人不少。nodejs在这时就有个很突出的优点:部署方便、跨平台几乎无障碍,相比之下python……简直让人脱层皮。
解析页面用的是cheerio,全兼容jQuery语法,熟悉前端的话用起来爽快之极,再也不用折腾烦人的正则了;
操作数据库直接用mysql这个module就行,该有的功能全有;
爬 取效率么,其实没有真正做过压力测试,因为我抓的是知乎,线程稍多一点瓶颈就跑到带宽上。而且它也不是真多线程而是异步,最后带宽全满(大约几百线程、 10MB/s左右)时,CPU也不过50%左右,这还只是一个linode最低配主机的CPU。况且平时我限制了线程和抓取间隔,简直不怎么消耗性能;
最后是代码,异步编程最头疼的是掉进callback地狱,根据自己实际情况写个多线队列的话,也不比同步编程麻烦太多就是了。
PHP写爬虫还好,我写过一个,用PHP Command Line下运行。用Curl_multi 50线程并发,一天能抓大概60万页,依网速而定,我是用的校园网所以比较快,数据是用正则提取出来的。
Curl是比较成熟的一个lib,异常处理、http header、POST之类都做得很好,重要的是PHP下操作MySQL进行入库操作比较省心。
不过在多线程Curl(Curl_multi)方面,对于初学者会比较麻烦,特别是PHP官方文档在Curl_multi这方面的介绍也极为模糊。
1.对页面的解析能力基本没区别,大家都支持正则,不过Python有些傻瓜拓展,用起来会方便很多;
2.对数据库的操作能力的话,PHP对MySQL有原生支持,Python需要添加MySQLdb之类的lib,不过也不算麻烦;
3.爬取效率的话,都支持多线程,效率我倒是没感觉有什么区别,基本上瓶颈只在网络上了。不过严谨的测试我没做过,毕竟我没有用多种语言实现同一种功能的习惯,不过我倒是感觉PHP好像还要快一些?
4.代码量的话,爬虫这种简单的东西基本没什么区别,几十行的事,如果加上异常处理也就百来行,或者麻烦点异常的Mark下来,等下重爬等等的处理,也就几百行,大家都没什么区别。
不过Python如果不把lib算进去的话显然是最少的。
Node.js。优点是效率、效率还是效率,由于网络是异步的,所以基本如同几百个进程并发一样强大,内存和CPU占用非常小,如果没有对抓取来的数据进 行复杂的运算加工,那么系统的瓶颈基本就在带宽和写入MySQL等数据库的I/O速度。当然,优点的反面也是缺点,异步网络代表你需要callback, 这时候如果业务需求是线性了,比如必须等待上一个页面抓取完成后,拿到数据,才能进行下一个页面的抓取,甚至多层的依赖关系,那就会出现可怕的多层 callback!基本这时候,代码结构和逻辑就会一团乱麻。当然可以用Step等流程控制工具解决这些问题。
最后说Python。如果你对效率没有极端的要求,那么推荐用Python!首先,Python的语法很简洁,同样的语句,可以少敲很多次键盘。然后,Python非常适合做数据的处理,比如函数参数的打包解包,列表解析,矩阵处理,非常方便。
果断python,c++也ok
也多进程爬取大网站(百万页面以上,大概2-3天)。
Python,多线程的方面会非常爽。
nodejs, 异步多线程

1.webmagic
【猪猪-后端】WebMagic框架搭建的爬虫,根据自定义规则,直接抓取,使用灵活,Demo部署即可查看。
官站:WebMagic
2.jsoup
java网络爬虫jsoup和commons-httpclient使用入门教程实例源码
搜索"jsoup"的分享列表
官站:jsoup Java HTML Parser, with best of DOM, CSS, and jquery
3.apache httpclient
java爬虫实现之httpClient4.2.1 连接池管理客户端请求 抓取页面简单示例
搜索"httpclient"的分享列表
HttpClient - HttpClient Home
4.如果觉得框架用起来复杂,其实完全可以通过java.net.HttpURLConnection来实现。
java通过java.net.HttpURLConnection类抓取网页源码工具类分享
搜索"HttpURLConnection"的分享列表
参考下爬虫相关的源码demo吧:
搜索"爬虫"的分享列表
搜索"抓取"的分享列表
http://www.zhihu.com/question/32676963
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始 网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定 的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询 和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
世界上已经成型的爬虫软件多达上百种,本文对较为知名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非大型、复杂的搜索引擎,因为很多兄弟只是想爬取数据,而非运营一个搜索引擎。
Java爬虫1、Arachnid
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。 Arachnid的下载包中包含两个spider应用程序例子用于演示如何使用该框架。
特点:微型爬虫框架,含有一个小型HTML解析器
许可证:GPL2、crawlzilla
crawlzilla 是一个帮你轻松建立搜索引擎的自由软件,有了它,你就不用依靠商业公司的搜索引擎,也不用再烦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能分析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有中文分词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个方便好用易安裝的搜索平台。
授权协议: Apache License2开发语言: Java JavaScript SHELL
操作系统: Linux
项目主页: https://github.com/shunfa/crawlzilla
下载地址: http://sourceforge.net/projects/crawlzilla/
特点:安装简易,拥有中文分词功能3、Ex-Crawler
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部分,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库存储网页信息。
授权协议: GPLv3
开发语言: Java
操作系统: 跨平台
特点:由守护进程执行,使用数据库存储网页信息4、Heritrix
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:https://github.com/internetarchive/heritrix3
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:严格遵照robots文件的排除指示和META robots标签5、heyDr
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3协议。
用户可以通过heyDr构建自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据准备。
授权协议: GPLv3
开发语言: Java
操作系统: 跨平台
特点:轻量级开源多线程垂直检索爬虫框架6、ItSucks
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面7、jcrawl
jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq.
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:轻量、性能优良,可以从网页抓取各种类型的文件8、JSpider
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL一定要加上协议名称,如:http://,否则会报错。如果省掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用什么插件,结果存储方式等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider非常容易扩展,可以利用它开发强大的网页抓取与数据分析工具。要做到这些,需要对JSpider的原理有深入的了 解,然后根据自己的需求开发插件,撰写配置文件。
授权协议: LGPL
开发语言: Java
操作系统: 跨平台
特点:功能强大,容易扩展9、Leopdo
用JAVA编写的web 搜索和爬虫,包括全文和分类垂直搜索,以及分词系统
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:包括全文和分类垂直搜索,以及分词系统10、MetaSeeker
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方法,如果按照部署在哪里分,可以分成:1,服务器侧:一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前很流行)等做,可以速度做得很快,一般综合搜索引擎的爬虫这样做。但是,如果对方讨厌爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗用的带宽也是挺贵的。建议看一下Beautiful soap。2,客户端:一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或者比价服务或者推荐引擎,相对容易很多,这类爬虫不是什么 页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价格信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以部署很多,而且可以很有侵略性,对方很难封锁。
MetaSeeker中的网络爬虫就属于后者。
MetaSeeker工具包利用Mozilla平台的能力,只要是Firefox看到的东西,它都能提取。特点:网页抓取、信息提取、数据抽取工具包,操作简单11、Playfish
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还很不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各类论坛,贴吧,以及各类CMS 系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方法,1.下载右边的.war包导入到eclipse中, 2.使用WebContent/sql下的wcc.sql文件建立一个范例数据库, 3.修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。 4.然后运行SystemCore,运行时候会在控制台,无参数会执行默认的example.xml的配置文件,带参数时候名称为配置文件名。
系统自带了3个例子,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz论坛的内容。
授权协议: MIT
开发语言: Java
操作系统: 跨平台
特点:通过XML配置文件实现高度可定制性与可扩展性12、Spiderman
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath怎么获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:灵活、扩展性强,微内核+插件式架构,通过简单的配置就可以完成数据抓取,无需编写一句代码13、webmagic
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:http://webmagic.io/docs/
查看源代码:http://git.oschina.net/flashsword20/webmagic
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献14、Web-Harvest
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。Web-Harvest主要是运用了像XSLT,XQuery,正则表达式等这些技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运 用XPath、XQuery、正则表达式等这些技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也 是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑怎么处理数据的Java代码。当然在爬虫开始前,也可 以把Java变量填充到配置文件中,实现动态的配置。
授权协议: BSD
开发语言: Java
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面15、WebSPHINX
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以自动浏览与处理Web页面的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
授权协议:Apache
开发语言:Java
特点:由两部分组成:爬虫工作平台和WebSPHINX类包16、YaCy
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是构建基于p2p Web索引网络的一个新方法.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
授权协议: GPL
开发语言: Java Perl
操作系统: 跨平台
特点:基于P2P的分布式Web搜索引擎
Python爬虫17、QuickRecon
QuickRecon是一个简单的信息收集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats寻找人际关系等。QuickRecon使用python编写,支持linux和 windows操作系统。
授权协议: GPLv3
开发语言: Python
操作系统: Windows Linux
特点:具有查找子域名名称、收集电子邮件地址并寻找人际关系等功能18、PyRailgun
这是一个非常简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
授权协议: MIT
开发语言: Python
操作系统: 跨平台 Windows Linux OS X
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:https://github.com/princehaku/pyrailgun#readme
19、Scrapy
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
授权协议: BSD
开发语言: Python
操作系统: 跨平台
github源代码:https://github.com/scrapy/scrapy
特点:基于Twisted的异步处理框架,文档齐全
C++爬虫20、hispider
HiSpiderisa fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
基于unix/linux系统的开发
异步DNS解析
URL排重
支持HTTP 压缩编码传输 gzip/deflate
字符集判断自动转换成UTF-8编码
文档压缩存储
支持多下载节点分布式下载
支持网站定向下载(需要配置 hispiderd.ini whitelist )
可通过 http://127.0.0.1:3721/ 查看下载情况统计,下载任务控制(可停止和恢复任务)
依赖基本通信库libevbase 和 libsbase (安装的时候需要先安装这个两个库)、
工作流程:
从中心节点取URL(包括URL对应的任务号, IP和port,也可能需要自己解析)
连接服务器发送请求
等待数据头判断是否需要的数据(目前主要取text类型的数据)
等待完成数据(有length头的直接等待说明长度的数据否则等待比较大的数字然后设置超时)
数据完成或者超时, zlib压缩数据返回给中心服务器,数据可能包括自己解析DNS信息, 压缩后数据长度+压缩后数据, 如果出错就直接返回任务号以及相关信息
中心服务器收到带有任务号的数据, 查看是否包括数据, 如果没有数据直接置任务号对应的状态为错误, 如果有数据提取数据种link 然后存储数据到文档文件.
完成后返回一个新的任务.
授权协议: BSD
开发语言: C/C++操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载21、larbin
larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每天获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它建立url 列表群,例如针对所有的网页进行 url retrive后,进行xml的联结的获取。或者是 mp3,或者定制larbin,可以作为搜索引擎的信息的来源。
授权协议: GPL
开发语言: C/C++操作系统: Linux
特点:高性能的爬虫软件,只负责抓取不负责解析22、Methabot
Methabot 是一个经过速度优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
授权协议: 未知
开发语言: C/C++操作系统: Windows Linux
特点:过速度优化、可抓取WEB、FTP及本地文件系统
源代码:http://www.oschina.net/code/tag/methabot
C#爬虫23、NWebCrawler
NWebCrawler是一款开源,C#开发网络爬虫程序。
特性:
可配置:线程数,等待时间,连接超时,允许MIME类型和优先级,下载文件夹。
统计信息:URL数量,总下载文件,总下载字节数,CPU利用率和可用内存。
Preferential crawler:用户可以设置优先级的MIME类型。
Robust:10+URL normalization rules, crawler trap avoiding rules.
授权协议: GPLv2
开发语言: C#
操作系统: Windows
项目主页:http://www.open-open.com/lib/view/home/1350117470448
特点:统计信息、执行过程可视化24、Sinawler
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系搜集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研发等的数据支持,但请勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数量的限制、获取微博数量的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和表演当前作品,制作派生作品。 你不可将当前作品用于商业目的。5.x版本已经发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以 及调节请求频率的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现在测试的结果看,已经能够满足自用。
本程序的特点:1、6个后台工作线程,最大限度挖掘爬虫性能潜力!2、界面上提供参数设置,灵活方便3、抛弃app.config配置文件,自己实现配置信息的加密存储,保护数据库帐号信息4、自动调整请求频率,防止超限,也避免过慢,降低效率5、任意对爬虫控制,可随时暂停、继续、停止爬虫6、良好的用户体验
授权协议: GPLv3
开发语言: C# .NET
操作系统: Windows25、spidernet
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望提交你的代码.
授权协议: MIT
开发语言: C#
操作系统: Windows
github源代码:https://github.com/nsnail/spidernet
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite存储数据26、Web Crawler
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接数组开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回来的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自 Open-Open
开发语言: Java
操作系统: 跨平台
授权协议: LGPL
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源27、网络矿工
网站数据采集软件 网络矿工采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中唯一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
授权协议: BSD
开发语言: C# .NET
操作系统: Windows
特点:功能丰富,毫不逊色于商业软件
PHP爬虫28、OpenWebSpider
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
授权协议: 未知
开发语言: PHP
操作系统: 跨平台
特点:开源多线程网络爬虫,有许多有趣的功能29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引建立一个词汇表。当搜索查询时,它将按一定的排序规则显示 包含关 键字的搜索结果页面。PhpDig包含一个模板系统并能够索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它打造针对某一领域的垂直搜索引擎是最好的选择。
演示:http://www.phpdig.net/navigation.php?action=demo
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
特点:具有采集网页内容、提交表单功能30、ThinkUp
ThinkUp 是一个可以采集推特,facebook等社交网络数据的社会媒体视角引擎。通过采集个人的社交网络账号中的数据,对其存档以及处理的交互分析工具,并将数据图形化以便更直观的查看。
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
github源码:https://github.com/ThinkUpLLC/ThinkUp
特点:采集推特、脸谱等社交网络数据的社会媒体视角引擎,可进行交互分析并将结果以可视化形式展现31、微购
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了淘宝、天 猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML就会做程序模板,免费开放下载,是广大淘客站长的首选。
演示网址:http://tlx.wego360.com
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
ErLang爬虫32、Ebot
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
授权协议: GPLv3
开发语言: ErLang
操作系统: 跨平台
github源代码:https://github.com/matteoredaelli/ebot
项目主页: http://www.redaelli.org/matteo/blog/projects/ebot
特点:可伸缩的分布式网页爬虫
Ruby爬虫33、Spidr
Spidr 是一个Ruby 的网页爬虫库,可以将整个网站、多个网站、某个链接完全抓取到本地。
开发语言: Ruby
授权协议:MIT
特点:可将一个或多个网站、某个链接完全抓取到本地
33款可用来抓数据的开源爬虫软件工具2015/10/10阅读(3573)评论(6)收藏(183)
来人人都是产品经理【起点学院】,BAT实战派产品总监手把手系统带你学产品、学运营。点此查看详情
要玩大数据,没有数据怎么玩?这里推荐一些33款开源爬虫软件给大家。
爬虫,即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
世界上已经成型的爬虫软件多达上百种,本文对较为知名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非大型、复杂的搜索引擎,因为很多兄弟只是想爬取数据,而非运营一个搜索引擎。171Java爬虫1. Arachnid
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。 Arachnid的下载包中包含两个spider应用程序例子用于演示如何使用该框架。
特点:微型爬虫框架,含有一个小型HTML解析器
许可证:GPL2、crawlzilla
crawlzilla 是一个帮你轻松建立搜索引擎的自由软件,有了它,你就不用依靠商业公司的搜索引擎,也不用再烦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能分析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有中文分词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个方便好用易安裝的搜索平台。
授权协议: Apache License2开发语言: Java JavaScript SHELL
操作系统: Linux
项目主页: https://github.com/shunfa/crawlzilla
下载地址: http://sourceforge.net/projects/crawlzilla/
特点:安装简易,拥有中文分词功能3、Ex-Crawler
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部分,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库存储网页信息。
授权协议: GPLv3
开发语言: Java
操作系统: 跨平台
特点:由守护进程执行,使用数据库存储网页信息4、Heritrix
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:https://github.com/internetarchive/heritrix3
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:严格遵照robots文件的排除指示和META robots标签5、heyDr
heyDr
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3协议。
用户可以通过heyDr构建自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据准备。
授权协议: GPLv3
开发语言: Java
操作系统: 跨平台
特点:轻量级开源多线程垂直检索爬虫框架6、ItSucks
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面7、jcrawl
jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq.
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:轻量、性能优良,可以从网页抓取各种类型的文件8、JSpider
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL一定要加上协议名称,如:http://,否则会报错。如果省掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用什么插件,结果存储方式等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider非常容易扩展,可以利用它开发强大的网页抓取与数据分析工具。要做到这些,需要对JSpider的原理有深入的了 解,然后根据自己的需求开发插件,撰写配置文件。
授权协议: LGPL
开发语言: Java
操作系统: 跨平台
特点:功能强大,容易扩展9、Leopdo
用JAVA编写的web 搜索和爬虫,包括全文和分类垂直搜索,以及分词系统
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:包括全文和分类垂直搜索,以及分词系统10、MetaSeeker
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方法,如果按照部署在哪里分,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前很流行)等做,可以速度做得很快,一般综合搜索引擎的爬虫这样做。但是,如果对方讨厌爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗用的带宽也是挺贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或者比价服务或者推荐引擎,相对容易很多,这类爬虫不是什么页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价格信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以部署很多,而且可以很有侵略性,对方很难封锁。
MetaSeeker中的网络爬虫就属于后者。
MetaSeeker工具包利用Mozilla平台的能力,只要是Firefox看到的东西,它都能提取。特点:网页抓取、信息提取、数据抽取工具包,操作简单11、Playfish
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还很不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各类论坛,贴吧,以及各类CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方法:
下载右边的.war包导入到eclipse中,
使用WebContent/sql下的wcc.sql文件建立一个范例数据库,
修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。
然后运行SystemCore,运行时候会在控制台,无参数会执行默认的example.xml的配置文件,带参数时候名称为配置文件名。
系统自带了3个例子,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz论坛的内容。
授权协议: MIT
开发语言: Java
操作系统: 跨平台
特点:通过XML配置文件实现高度可定制性与可扩展性12、Spiderman
Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath怎么获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:灵活、扩展性强,微内核+插件式架构,通过简单的配置就可以完成数据抓取,无需编写一句代码13、webmagic
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:http://webmagic.io/docs/
查看源代码:http://git.oschina.net/flashsword20/webmagic
授权协议: Apache
开发语言: Java
操作系统: 跨平台
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献14、Web-Harvest
Web-Harvest是一个Java开源Web数据抽取工具。它能够收集指定的Web页面并从这些页面中提取有用的数据。Web-Harvest主要是运用了像XSLT,XQuery,正则表达式等这些技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这些技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑怎么处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
授权协议: BSD
开发语言: Java
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面15、WebSPHINX
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以自动浏览与处理Web页面的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
授权协议:Apache
开发语言:Java
特点:由两部分组成:爬虫工作平台和WebSPHINX类包16、YaCy
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是构建基于p2p Web索引网络的一个新方法.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
授权协议: GPL
开发语言: Java Perl
操作系统: 跨平台
特点:基于P2P的分布式Web搜索引擎
Python爬虫17、QuickRecon
QuickRecon是一个简单的信息收集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats寻找人际关系等。QuickRecon使用python编写,支持linux和 windows操作系统。
授权协议: GPLv3
开发语言: Python
操作系统: Windows Linux
特点:具有查找子域名名称、收集电子邮件地址并寻找人际关系等功能18、PyRailgun
这是一个非常简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
授权协议: MIT
开发语言: Python
操作系统: 跨平台 Windows Linux OS X
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:https://github.com/princehaku/pyrailgun#readme
19、Scrapy
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
授权协议: BSD
开发语言: Python
操作系统: 跨平台
github源代码:https://github.com/scrapy/scrapy
特点:基于Twisted的异步处理框架,文档齐全
C++爬虫20、hispider
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
基于unix/linux系统的开发
异步DNS解析
URL排重
支持HTTP 压缩编码传输 gzip/deflate
字符集判断自动转换成UTF-8编码
文档压缩存储
支持多下载节点分布式下载
支持网站定向下载(需要配置 hispiderd.ini whitelist )
可通过 http://127.0.0.1:3721/ 查看下载情况统计,下载任务控制(可停止和恢复任务)
依赖基本通信库libevbase 和 libsbase (安装的时候需要先安装这个两个库)、
工作流程:
从中心节点取URL(包括URL对应的任务号, IP和port,也可能需要自己解析)
连接服务器发送请求
等待数据头判断是否需要的数据(目前主要取text类型的数据)
等待完成数据(有length头的直接等待说明长度的数据否则等待比较大的数字然后设置超时)
数据完成或者超时, zlib压缩数据返回给中心服务器,数据可能包括自己解析DNS信息, 压缩后数据长度+压缩后数据, 如果出错就直接返回任务号以及相关信息
中心服务器收到带有任务号的数据, 查看是否包括数据, 如果没有数据直接置任务号对应的状态为错误, 如果有数据提取数据种link 然后存储数据到文档文件.
完成后返回一个新的任务.
授权协议: BSD
开发语言: C/C++操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载21、larbin
larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于如何parse的事情则由用户自己完成。另外,如何存储到数据库以及建立索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每天获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它建立url 列表群,例如针对所有的网页进行 url retrive后,进行xml的联结的获取。或者是 mp3,或者定制larbin,可以作为搜索引擎的信息的来源。
授权协议: GPL
开发语言: C/C++操作系统: Linux
特点:高性能的爬虫软件,只负责抓取不负责解析22、Methabot
Methabot 是一个经过速度优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
授权协议: 未知
开发语言: C/C++操作系统: Windows Linux
特点:过速度优化、可抓取WEB、FTP及本地文件系统
源代码:http://www.oschina.net/code/tag/methabot
C#爬虫23、NWebCrawler
NWebCrawler是一款开源,C#开发网络爬虫程序。
特性:
可配置:线程数,等待时间,连接超时,允许MIME类型和优先级,下载文件夹。
统计信息:URL数量,总下载文件,总下载字节数,CPU利用率和可用内存。
Preferential crawler:用户可以设置优先级的MIME类型。
Robust:10+URL normalization rules, crawler trap avoiding rules.
授权协议: GPLv2
开发语言: C#
操作系统: Windows
项目主页:http://www.open-open.com/lib/view/home/1350117470448
特点:统计信息、执行过程可视化24、Sinawler
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系搜集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研发等的数据支持,但请勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数量的限制、获取微博数量的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和表演当前作品,制作派生作品。 你不可将当前作品用于商业目的。5.x版本已经发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节请求频率的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现在测试的结果看,已经能够满足自用。
本程序的特点:
6个后台工作线程,最大限度挖掘爬虫性能潜力!
界面上提供参数设置,灵活方便
抛弃app.config配置文件,自己实现配置信息的加密存储,保护数据库帐号信息
自动调整请求频率,防止超限,也避免过慢,降低效率
任意对爬虫控制,可随时暂停、继续、停止爬虫
良好的用户体验
授权协议: GPLv3
开发语言: C# .NET
操作系统: Windows25、spidernet
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望提交你的代码.
授权协议: MIT
开发语言: C#
操作系统: Windows
github源代码:https://github.com/nsnail/spidernet
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite存储数据26、Web Crawler
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接数组开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回来的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
开发语言: Java
操作系统: 跨平台
授权协议: LGPL
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源27、网络矿工
网站数据采集软件 网络矿工采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中唯一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
授权协议: BSD
开发语言: C# .NET
操作系统: Windows
特点:功能丰富,毫不逊色于商业软件
PHP爬虫28、OpenWebSpider
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
授权协议: 未知
开发语言: PHP
操作系统: 跨平台
特点:开源多线程网络爬虫,有许多有趣的功能29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引建立一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并能够索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它打造针对某一领域的垂直搜索引擎是最好的选择。
演示:http://www.phpdig.net/navigation.php?action=demo
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
特点:具有采集网页内容、提交表单功能30、ThinkUp
ThinkUp 是一个可以采集推特,facebook等社交网络数据的社会媒体视角引擎。通过采集个人的社交网络账号中的数据,对其存档以及处理的交互分析工具,并将数据图形化以便更直观的查看。
ThinkUp
ThinkUp
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
github源码:https://github.com/ThinkUpLLC/ThinkUp
特点:采集推特、脸谱等社交网络数据的社会媒体视角引擎,可进行交互分析并将结果以可视化形式展现31、微购
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了淘宝、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML就会做程序模板,免费开放下载,是广大淘客站长的首选。
演示网址:http://tlx.wego360.com
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
ErLang爬虫32、Ebot
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
授权协议: GPLv3
开发语言: ErLang
操作系统: 跨平台
github源代码:https://github.com/matteoredaelli/ebot
项目主页: http://www.redaelli.org/matteo/blog/projects/ebot
特点:可伸缩的分布式网页爬虫
Ruby爬虫33、Spidr
Spidr 是一个Ruby 的网页爬虫库,可以将整个网站、多个网站、某个链接完全抓取到本地。
开发语言: Ruby
授权协议:MIT
特点:可将一个或多个网站、某个链接完全抓取到本地