使用Python爬取百度热搜榜
1. 简介
去年用C#给自己博客写的每日新闻爬虫突然就不能用了,最近闲下来看了一下,原来是百度热搜榜的前端页面改版了,那难怪。这次索性人生苦短,我选Python吧。
2. 百度热搜榜源码观察
百度热搜榜的网址如下:
百度热搜榜
去了点开源码一看,我乐了。
百度很贴心的在最前面用注释写好了热搜榜内容的数据字典,也不知道是后端程序员生成出来忘记删了,还是真就方便大家爬呢。
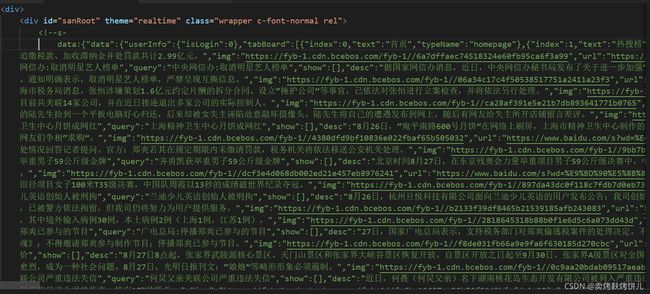
那么接下来就好办了。
3. 获取网页html源码
使用python的urllib.request包,我就直接上代码了,大家看吧
#获取网页源码
def askURL():
print('#>>>获取网页HTML源码中...>>>')
# 模拟浏览器头部信息,向服务器发送消息
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request=urllib.request.Request(newsUrl,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print("#SUCCESS>HTML源码爬取完毕!\n")
except urllib.error.URLError as e:
print("#ERROR>HTML源码爬取失败!\n")
if hasattr(e, "code"):
print("#" + str(e.code))
if hasattr(e, "reason"):
print("#" + str(e.reason))
return html
4. 整理源码中的数据
打算将html中的字符串直接转换为dict,然后再将原本的dict简化成我们需要的dict(只留新闻标题,新闻详情,新闻图片与新闻链接)
代码如下:
#解析数据
def getData(html):
print('#>>>解析数据中...>>>')
newsDictListStr = None
try:
findNewsDictList = re.compile(r',"content":\[\{([\s\S]*)\}\],"moreUrl":')
newsDictListStr = re.findall(findNewsDictList,html)[0]
print("#SUCCESS>字典串截取成功")
except IndexError:
print("#ERROR>字典串截取失败,目标网站源码可能发生改变!")
return newsDictListStr
dataStrList = newsDictListStr.split('},{')
print('#SUCCESS>原始数据字典分析完毕')
newsList = []
try:
for dataStr in dataStrList:
Str ='{' + dataStr + '}'
oldDict = ast.literal_eval(Str)
newDict = dict()
newDict["index"] = oldDict["index"] + 1
newDict["article"] = oldDict["word"]
newDict["info"] = oldDict["desc"]
newDict["link"] = oldDict["url"]
newDict["img"] = oldDict["img"]
newsList.append(newDict)
except KeyError:
print("#ERROR>未找到数据字典中的键,原网站数据字典可能已经改变")
return None
print("#SUCCESS>新数据字典已提取")
return newsList
5. 输出保存整理好的新闻
我打算将得到的数据整理成markdown的格式保存下来,方便导出成图片。
代码如下:
# 生成MD文件字符串
def getMD(newsList):
print('#>>>MD文件生成中...>>>')
nowTime = datetime.datetime.now()
nowTimeStr1 = nowTime.strftime('%Y/%m/%d %H:%M:%S')
nowTimeStr2 = nowTime.strftime('%Y年%m月%d日 %H:%M:%S')
colorList = ["red", "green", "blue"]
newsMDStr = "---\ntitle: 每日新闻\ndate: {}\n---\n".format(nowTimeStr1)
newsMDStr += '\n# ' + nowTimeStr2 + '\n'
for i in range(len(newsList)):
if i < 3:
newsMDStr += "\n ## [{} .{}]({})
".format(colorList[i], str(newsList[i]["index"]), newsList[i]["article"], newsList[i]["link"])
else:
newsMDStr += "\n ### {} .[{}]({})
".format(str(newsList[i]["index"]), newsList[i]["article"], newsList[i]["link"])
newsMDStr += r'
'.format(newsList[i]["img"])
if newsList[i]["info"] == "":
newsMDStr += "> 暂无详细消息
"
else:
newsMDStr += "> {}
".format(newsList[i]["info"])
newsMDStr += '**信息来源来自百度热榜,本网站不对真实性负责**\n'
return newsMDStr
# 保存MD文件
def writeMD(newsMDStr):
f = open(savePath,"w",encoding="utf-8")
f.write(newsMDStr)
print("#SUCCESS>MD文件已生成")
这样以来,就大功告成了,可以每天轻松看新闻啦!
6. 结果与全部代码
整体代码如下:
import re
import ast
import datetime
import urllib.request,urllib.error
newsUrl = "https://top.baidu.com/board?tab=realtime"
savePath = "news.md"
# 主逻辑
def runNewsSpider():
print('#>>>每日新闻爬取中...>>>')
print("#目标网站:" + newsUrl)
print("#存储路径:" + savePath)
htmlCode = askURL()
if htmlCode is None:
print("#ERROR>数据字典爬取失败")
return False
newsList = getData(htmlCode)
if newsList is None:
print("#ERROR>数据字典生成失败")
return False
newsMDStr = getMD(newsList)
writeMD(newsMDStr)
print('#SUCCESS>新闻爬取完毕')
return True
#获取网页源码
def askURL():
print('#>>>获取网页HTML源码中...>>>')
# 模拟浏览器头部信息,向服务器发送消息
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request=urllib.request.Request(newsUrl,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print("#SUCCESS>HTML源码爬取完毕!\n")
except urllib.error.URLError as e:
print("#ERROR>HTML源码爬取失败!\n")
if hasattr(e, "code"):
print("#" + str(e.code))
if hasattr(e, "reason"):
print("#" + str(e.reason))
return html
#解析数据
def getData(html):
print('#>>>解析数据中...>>>')
newsDictListStr = None
try:
findNewsDictList = re.compile(r',"content":\[\{([\s\S]*)\}\],"moreUrl":')
newsDictListStr = re.findall(findNewsDictList,html)[0]
print("#SUCCESS>字典串截取成功")
except IndexError:
print("#ERROR>字典串截取失败,目标网站源码可能发生改变!")
return newsDictListStr
dataStrList = newsDictListStr.split('},{')
print('#SUCCESS>原始数据字典分析完毕')
newsList = []
try:
for dataStr in dataStrList:
Str ='{' + dataStr + '}'
oldDict = ast.literal_eval(Str)
newDict = dict()
newDict["index"] = oldDict["index"] + 1
newDict["article"] = oldDict["word"]
newDict["info"] = oldDict["desc"]
newDict["link"] = oldDict["url"]
newDict["img"] = oldDict["img"]
newsList.append(newDict)
except KeyError:
print("#ERROR>未找到数据字典中的键,原网站数据字典可能已经改变")
return None
print("#SUCCESS>新数据字典已提取")
return newsList
# 生成MD文件字符串
def getMD(newsList):
print('#>>>MD文件生成中...>>>')
nowTime = datetime.datetime.now()
nowTimeStr1 = nowTime.strftime('%Y/%m/%d %H:%M:%S')
nowTimeStr2 = nowTime.strftime('%Y年%m月%d日 %H:%M:%S')
colorList = ["red", "green", "blue"]
newsMDStr = "---\ntitle: 每日新闻\ndate: {}\n---\n".format(nowTimeStr1)
newsMDStr += '\n# ' + nowTimeStr2 + '\n'
for i in range(len(newsList)):
if i < 3:
newsMDStr += "\n ## [{} .{}]({})
".format(colorList[i], str(newsList[i]["index"]), newsList[i]["article"], newsList[i]["link"])
else:
newsMDStr += "\n ### {} .[{}]({})
".format(str(newsList[i]["index"]), newsList[i]["article"], newsList[i]["link"])
newsMDStr += r'
'.format(newsList[i]["img"])
if newsList[i]["info"] == "":
newsMDStr += "> 暂无详细消息
"
else:
newsMDStr += "> {}
".format(newsList[i]["info"])
newsMDStr += '**信息来源来自百度热榜,本网站不对真实性负责**\n'
return newsMDStr
# 保存MD文件
def writeMD(newsMDStr):
f = open(savePath,"w",encoding="utf-8")
f.write(newsMDStr)
print("#SUCCESS>MD文件已生成")
导出md再导出图片如下:

好兄弟萌,关注我,下次一起爬爬天气预报~!