原文链接:http://tecdat.cn/?p=18860
原文出处:拓端数据部落公众号
简介
时间序列分析是统计学中的一个主要分支,主要侧重于分析数据集以研究数据的特征并提取有意义的统计信息来预测序列的未来值。时序分析有两种方法,即频域和时域。前者主要基于傅立叶变换,而后者则研究序列的自相关,并且使用Box-Jenkins和ARCH / GARCH方法进行序列的预测。
本文将提供使用时域方法对R环境中的金融时间序列进行分析和建模的过程。第一部分涵盖了平稳的时间序列。第二部分为ARIMA和ARCH / GARCH建模提供了指南。接下来,它将研究组合模型及其在建模和预测时间序列方面的性能和有效性。最后,将对时间序列分析方法进行总结。
时间序列数据集的平稳性和差异:
1.平稳性:
对时间序列数据建模的第一步是将非平稳时间序列转换为平稳时间序列。这是很重要的,因为许多统计和计量经济学方法都基于此假设,并且只能应用于平稳时间序列。非平稳时间序列是不稳定且不可预测的,而平稳过程是均值回复的,即它围绕具有恒定方差的恒定均值波动。此外,随机变量的平稳性和独立性密切相关,因为许多适用于独立随机变量的理论也适用于需要独立性的平稳时间序列。这些方法大多数都假设随机变量是独立的(或不相关的)。噪声是独立的(或不相关的);变量和噪声彼此独立(或不相关)。那么什么是平稳时间序列?
粗略地说,平稳时间序列没有长期趋势,均值和方差不变。更具体地说,平稳性有两种定义:弱平稳性和严格平稳性。
a.平稳性弱:如果满足以下条件,则称时间序列{Xt,t∈Z}(其中Z是整数集)是平稳的

b.严格平稳:如果(Xt1,Xt2,...,Xtk)的联合分布与(Xt1 + h,Xt2 + h)的联合分布相同,则时间序列{Xt. ……Xtk + h),t∈Z}被认为是严格平稳的。
通常在统计文献中,平稳性是指平稳时间序列满足三个条件的弱平稳性:恒定均值,恒定方差和自协方差函数仅取决于(ts)(不取决于t或s)。另一方面,严格平稳性意味着时间序列的概率分布不会随时间变化。
例如,白噪声是平稳的,意味着随机变量是不相关的,不一定是独立的。但是,严格的白噪声表示变量之间的独立性。另外,由于高斯分布的特征是前两个时刻,所以高斯白噪声是严格平稳的,因此,不相关也意味着随机变量的独立性。
在严格的白噪声中,噪声项{et}不能线性或非线性地预测。在一般的白噪声中,可能无法线性预测,但可由稍后讨论的ARCH / GARCH模型非线性预测。有三点需要注意:
•严格的平稳性并不意味着平稳性弱,因为它不需要有限的方差
•平稳性并不意味着严格的平稳性,因为严格的平稳性要求概率分布不会随时间变化
•严格平稳序列的非线性函数也严格平稳,不适用于弱平稳
2.区别:
为了将非平稳序列转换为平稳序列,可以使用差分方法,从原始序列中减去该序列滞后1期:例如:
![]()
在金融时间序列中,通常会对序列进行转换,然后执行差分。这是因为金融时间序列通常会经历指数增长,因此对数转换可以使时间序列平滑(线性化),而差分将有助于稳定时间序列的方差。以下是苹果股票价格的示例:
•左上方的图表是苹果股票价格从2007年1月1日到2012年7月24日的原始时间序列,显示出指数级增长。
•左下方的图表显示了苹果股票价格的差分。可以看出,该系列是价格相关的。换句话说,序列的方差随着原始序列的级别增加而增加,因此不是平稳的
•右上角显示Apple的log价格图。与原始序列相比,该序列更线性。
•右下方显示了苹果log价格的差分。该系列似乎更具有均值回复性,并且方差是恒定的,并且不会随着原始系列级别的变化而显着变化。


要执行R中的差分,请执行以下步骤:
•读取R中的数据文件并将其存储在变量中
appl.close=appl$Adjclose #在原始文件中读取并存储收盘价•绘制原始股票价格
plot(ap.close,type='l')•与原始序列不同
diff.appl=diff(ap.close)•原始序列的差分序列图
plot(diff.appl,type='l')•获取原始序列的对数并绘制对数价格
log.appl=log(appl.close)•不同的log价格和图
difflog.appl=diff(log.appl)log价格的差分代表收益,与股票价格的百分比变化相似。
ARIMA模型:
模型识别:
通过观察时间序列的自相关建立并实现时域方法。因此,自相关和偏自相关是ARIMA模型的核心。BoxJenkins方法提供了一种根据序列的自相关和偏自相关图来识别ARIMA模型的方法。ARIMA的参数由三部分组成:p(自回归参数),d(差分数)和q(移动平均参数)。
识别ARIMA模型有以下三个规则:
•如果滞后n后ACF(自相关图)被切断,则PACF(偏自相关图)消失:ARIMA(0,d,n)确定MA(q)
•如果ACF下降,则滞后n阶后PACF切断:ARIMA(n,d,0),识别AR(p)
•如果ACF和PACF失效:混合ARIMA模型,需要区别
注意,即使引用相同的模型,ARIMA中的差异数也用不同的方式书写。例如,原始序列的ARIMA(1,1,0)可以写为差分序列的ARIMA(1,0,0)。同样,有必要检查滞后1阶自相关为负(通常小于-0.5)的过差分。差分过大会导致标准偏差增加。
以下是Apple时间序列中的一个示例:
•左上方以对数苹果股票价格的ACF表示,显示ACF缓慢下降(而不是下降)。该模型可能需要差分。
•左下角是Log Apple的PACF,表示滞后1处的有效值,然后PACF截止。因此,Log Apple股票价格的模型可能是ARIMA(1,0,0)
•右上方显示对数Apple的差分的ACF,无明显滞后(不考虑滞后0)
•右下角是对数Apple差分的PACF,无明显滞后。因此,差分对数Apple序列的模型是白噪声,原始模型类似于随机游走模型ARIMA(0,1,0)


在拟合ARIMA模型中,简约的思想很重要,在该模型中,模型应具有尽可能小的参数,但仍然能够解释级数(p和q应该小于或等于2,或者参数总数应小于等于鉴于Box-Jenkins方法3)。参数越多,可引入模型的噪声越大,因此标准差也越大。
因此,当检查模型的AICc时,可以检查p和q为2或更小的模型。要在R中执行ACF和PACF,以下代码:
•对数的ACF和PACF
acf.appl=acf(log.appl)
pacf.appl=pacf(log.appl,main='PACF Apple',lag.max=100•差分对数的ACF和PACF
acf.appl=acf(difflog.appl,main='ACF Diffe
pacf.appl=pacf(difflog.appl,main='PACF D除了Box-Jenkins方法外,AICc还提供了另一种检查和识别模型的方法。AICc为赤池信息准则,可以通过以下公式计算:
AICC = N log(SS / N)+ 2(p + q + 1) N /(N – p – q – 2),如果模型中没有常数项
AICC = N log(SS / N)+ 2(p + q + 2) N /(N – p – q – 3),如果模型中为常数项
N:求异后的项目数(N = n – d)
SS:差平方和
p&q:自回归模型和移动平均模型的顺序
根据这种方法,将选择具有最低AICc的模型。在R中执行时间序列分析时,程序将提供AICc作为结果的一部分。但是,在其他软件中,可能需要通过计算平方和并遵循上述公式来手动计算数字。当使用不同的软件时,数字可能会略有不同。
Model AICc
0 1 0 -6493
1 1 0 -6491.02
0 1 1 -6493.02
1 1 1 -6489.01
0 1 2 -6492.84
1 1 2 -6488.89
2 1 0 -6491.1
2 1 1 -6489.14
2 1 2 -6501.86基于AICc,我们应该选择ARIMA(2,1,2)。这两种方法有时可能会得出不同的结果,因此,一旦获得所有估计,就必须检查和测试模型。以下是在R中执行ARIMA的代码:
summary(arima212)参数估计
要估算参数,请执行与先前所示相同的代码。结果将提供模型每个元素的估计。使用ARIMA(2,1,2)作为选定模型,结果如下:
Series: log.appl
ARIMA(2,1,2)
Coefficients:
ar1 ar2 ma1 ma2
-0.0015 -0.9231 0.0032 0.8803
s.e. 0.0532 0.0400 0.0661 0.0488
sigma^2 estimated as 0.000559: log likelihood=3255.95
AIC=-6501.9 AICc=-6501.86 BIC=-6475.68完整模型:
(Yt –Yt-1)= -0.0015(Yt-1 – Yt-2)-0.9231(Yt-2 – Yt-3)+0.0032εt-1+0.8803εt-2+εt
注意,当执行带差分的ARIMA模型时,R将忽略均值。以下是Minitab的输出:
Final Estimates of Parameters
Type Coef SE Coef T P
AR 1 0.0007 0.0430 0.02 0.988
AR 2 -0.9259 0.0640 -14.47 0.000
MA 1 0.0002 0.0534 0.00 0.998
MA 2 -0.8829 0.0768 -11.50 0.000
Constant 0.002721 0.001189 2.29 0.022
Differencing: 1 regular difference
Number of observations: Original series 1401, after differencing 1400
Residuals: SS = 0.779616 (backforecasts excluded)
MS = 0.000559 DF = 1395
Modified Box-Pierce (Ljung-Box) Chi-Square statistic
Lag 12 24 36 48
Chi-Square 6.8 21.2 31.9 42.0
DF 7 19 31 43
P-Value 0.452 0.328 0.419 0.516请注意,根据我们编写代码的方式,R将对同一模型给出不同的估计。例如:arima(log.appl,order = c(2,1,2))
arima(difflog.appl,order = c(2,0,2))从这两条代码行得出的ARIMA(2,1,2)的参数估计值在R中将有所不同,即使它引用的是同一模型。但是,在Minitab中,结果是相似的,因此对用户的混淆较少。
诊断检查
该过程包括观察残差图及其ACF和PACF图,并检查Ljung-Box结果。
如果模型残差的ACF和PACF没有显着滞后,则选择合适的模型。


残差图ACF和PACF没有任何明显的滞后,表明ARIMA(2,1,2)是表示该序列的良好模型。
此外,Ljung-Box测试还提供了另一种方法来仔细检查模型。基本上,Ljung-Box是一种自相关检验,其中它检验时间序列的自相关是否不同于0。换句话说,如果结果拒绝了假设,则意味着数据是独立且不相关的;否则,序列中仍然存在序列相关性,需要修改模型。
Modified Box-Pierce (Ljung-Box) Chi-Square statistic
Lag 12 24 36 48
Chi-Square 6.8 21.2 31.9 42.0
DF 7 19 31 43
P-Value 0.452 0.328 0.419 0.516Minitab的输出显示p值均大于0.05,因此我们不能拒绝自相关性不同于0的假设。因此,所选模型是Apple股票价格的合适模型之一。
ARCH / GARCH模型
尽管残差的ACF和PACF没有明显的滞后,但是残差的时间序列图显示出一些波动性。重要的是要记住,ARIMA是一种对数据进行线性建模且预测保持不变的方法,因为该模型无法反映最近的变化或合并新信息。换句话说,它为序列提供了最佳的线性预测,因此在非线性模型预测中几乎没有作用。为了建模波动,需要用到ARCH / GARCH方法。我们如何知道所关注的时间序列是否需要ARCH / GARCH?
首先,检查残差图是否显示任何波动性。接下来,观察残差平方。如果存在波动性,则应使用ARCH / GARCH对系列的波动性建模,以反映该系列中更多的近期变化和波动。最后,平方残差的ACF和PACF将有助于确认残差(噪声项)是否独立且可以预测。如前所述,严格的白噪声不能线性或非线性地预测,而普通的白噪声可能不能线性地预测但仍不能非线性地预测。如果残差是严格的白噪声,则它们与零均值,正态分布无关,并且平方残差的ACF和PACF没有明显的滞后。
以下是平方残差的图:
•残差平方图显示了某些时间点的波动性
•滞后10时,PACF仍会截断,即使有些滞后仍然很大


因此,残差显示了一些可以建模的模式。ARCH / GARCH对模型波动率建模很有必要。顾名思义,此方法与序列的条件方差有关。ARCH(q)的一般形式:

res.arima212=arima212$res
squared.res.arima212=res.arima212^2根据AICc选择ARCH / GARCH阶数和参数,如下所示:
AICC = -2 log+ 2( q + 1) N /(N – q – 2),如果模型中没有常数项
AICC = -2 log+ 2( q + 2) N /(N – q – 3),如果模型中为常数项
要计算AICc,我们需要将ARCH / GARCH模型拟合到残差,然后使用R中的logLik函数计算对数似然。请注意,由于我们只希望对ARIMA模型的噪声建模,因此我们将ARCH拟合到先前选择的ARIMA模型的残差,而不拟合原始序列或对数或差分对数序列。
Model N q Log&likelihood AICc&no&const AICc&const
ARCH(0) 1400 0 3256.488 ,6510.973139 ,6508.96741
ARCH(1) 1400 1 3314.55 ,6625.09141 ,6623.082808
ARCH(2) 1400 2 3331.168 ,6656.318808 ,6654.307326
ARCH(3) 1400 3 3355.06 ,6702.091326 ,6700.076958
ARCH(4) 1400 4 3370.881 ,6731.718958 ,6729.701698
ARCH(5) 1400 5 3394.885 ,6777.709698 ,6775.68954
ARCH(6) 1400 6 3396.683 ,6779.28554 ,6777.262477
ARCH(7) 1400 7 3403.227 ,6790.350477 ,6788.324504
ARCH(8) 1400 8 3410.242 =6802.354504 =6800.325613
ARCH(9) 1400 9 3405.803 ,6791.447613 ,6789.415798
ARCH(10) 1400 10 3409.187 ,6796.183798 ,6794.149054
GARCH(1,"1) 1400 2 3425.365 ,6844.712808 ,6842.701326上面提供了恒定和非恒定情况的AICc表。请注意,从ARCH 1到ARCH 8 的AICc减少,然后在ARCH 9和ARCH 10中AICc增加。为什么会发生?表示我们需要检查模型的收敛性,在前7种情况下,R中的输出给出“相对函数收敛”,而ARCH 9和ARCH 10具有“假收敛”。当输出包含False收敛时,该模型的预测能力值得怀疑,我们应该从选择中排除这些模型;尽管GARCH 1,1的AICc也最低,但是该模型被错误地收敛,因此被排除在外。 ARCH 8是所选模型。
此外,我们在分析中还包括ARCH 0 ,因为它可以用作检查是否存在任何ARCH效应或残差是否独立。
执行ARCH / GARCH模型的R代码:
loglik08=logLik(arch08)
summary(arch08)注意,R不允许q = 0的阶数,因此我们无法从R 获得ARCH 0的对数似然 ;但是我们需要通过公式进行计算:−.5 N 1 + log 2 pi mean(x) ˆ2
N:相差后的观测次数N = n – d
X:在此考虑的数据集情况,残差
ARCH 8的输出:
Call:
Model:
GARCH(0,8)
Residuals:
Min 1Q Median 3Q Max
-4.40329 -0.48569 0.08897 0.69723 4.07181
Coefficient(s):
Estimate Std. Error t value Pr(>|t|)
a0 1.472e-04 1.432e-05 10.282 < 2e-16 ***
a1 1.284e-01 3.532e-02 3.636 0.000277 ***
a2 1.335e-01 2.839e-02 4.701 2.59e-06 ***
a3 9.388e-02 3.688e-02 2.545 0.010917 *
a4 8.678e-02 2.824e-02 3.073 0.002116 **
a5 5.667e-02 2.431e-02 2.331 0.019732 *
a6 3.972e-02 2.383e-02 1.667 0.095550 .
a7 9.034e-02 2.907e-02 3.108 0.001885 **
a8 1.126e-01 2.072e-02 5.437 5.41e-08 ***
\-\-\-
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Diagnostic Tests:
Jarque Bera Test
data: Residuals
X-squared = 75.0928, df = 2, p-value < 2.2e-16
Box-Ljung test
data: Squared.Residuals
X-squared = 0.1124, df = 1, p-value = 0.7374除第六个参数外,所有参数的p“值均小于0.05,表明 它们具有统计学意义。此外,Box” Ljung检验的p“值大于0.05, 因此我们不能拒绝自相关的假设残差的值不同于0。因此该模型足以表示残差。
完整的ARCH 8模型:
ht = 1.472e-04 +1.284e-01ε2t“ 1 +1.335e-01ε2t” 2 +9.388e-02ε2t“ 3 + 8.678 e-02ε2t“ 4 +
5.667e-02ε2t” 5 +3.972e-02ε2t“ 6 +9.034e-02ε2t” 7 +1.126e-01ε2t“ 8
ARIMA-ARCH / GARCH
在本节中,我们将比较ARIMA模型和组合的ARIMAARCH / GARCH模型的结果。如前所述,Apple Log价格序列的ARIMA和ARCH模型分别为ARIMA 2,1,2)和ARCH 8)。此外,我们还将查看Minitab的结果,并将其与R 的结果进行比较。请记住,在将ARIMA拟合所需的差分序列时,R将排除常数。因此,我们先前从R生成的结果是ARIMA 2,1,2),没有常数。使用预测函数,根据ARIMA 2,1,2)对系列进行1步预测
Point Forecast Lo 95 Hi 95
1402 6.399541 6.353201 6.445882ARIMA(2,1,2)– ARCH(8)的完整模型:

下表总结了所有模型,并在Excel中编辑和计算了点预测和预测区间:
95% Confident interval
Model Forecast Lower Upper Actual
ARIMA(2,1,2) in R 6.399541 6.353201 6.445882 6.354317866
ARIMA(2,1,2) in Minitab (constant) 6.40099 6.35465 6.44734
ARIMA(2,1,2) in Minitab (no constant) 6.39956 6.35314 6.44597
ARIMA(2,1,2) + ARCH(8) in R 6.39974330 6.35340330 6.44608430
ARIMA(2,1,2) in Minitab (constant) +ARCH(8) 6.40119230 6.35485230 6.44754230
ARIMA(2,1,2) in Minitab (no constant)
+ARCH(8) 6.39976230 6.35334230 6.44617230 将对数价格转换为价格,我们获得原始序列的预测:
95% Confident interval
Model Forecast Lower Upper Actual
ARIMA(2,1,2) in R 601.5688544 574.3281943 630.1021821 574.9700003
ARIMA(2,1,2) in Minitab (constant) 602.4411595 575.1609991 631.0215411
ARIMA(2,1,2) in Minitab (no constant) 601.5802843 574.2931614 630.1576335
ARIMA(2,1,2) + ARCH(8) in R 601.6905666 574.4443951 630.2296673
ARIMA(2,1,2) in Minitab (constant) +ARCH(8) 602.5630482 575.2773683 631.1492123
ARIMA(2,1,2) in Minitab (no constant)
+ARCH(8) 601.7019989 574.409355 630.285132012年7月25日苹果发布了低于预期的收益报告,此公告影响了公司股价,导致该股票从2012年7月24日的600.92美元跌至2012年7月24日的574.97美元。公司发布正面或负面新闻时,这是经常发生的意外风险。但是,由于实际价格在我们95%的置信区间内并且非常接近下限,因此我们的模型似乎可以成功预测该风险。
需要注意的是,ARIMA(2,1,2)的95%置信区间比ARIMA(2,1,2)– ARCH(8)组合模型的置信区间宽。这是因为后者通过分析残差及其条件方差(随着新信息的出现而受到影响的方差)来反映并纳入股价的近期变化和波动。
那么如何计算ARCH(8)的条件方差ht?
•生成1步预测,100步预测,预测图:
forecast212step1=forecast(arima212,1,level=95)•计算ht,条件方差:
ht.arch08=arch08$fit\[,1\]^2 #使用拟合的第一栏•生成对数价格,上限和下限95%的图
plot(log.appl,type='l',main='Log Apple,Low,High')
lines(low,col='red')
lines(high,col='blue')为了计算ht,我们首先在一列中列出模型的所有参数,然后查找与这些系数关联的残差,将这些残差平方,将ht系数乘以残差平方,然后对这些数字求和以得出ht。例如,要估计点1402(我们的数据集有1401个观测值),我们需要最后8天的残差,因为我们的模型是ARCH(8)。以下是生成的表:
ht coeff res squared res ht components
const 1.47E-04 1.47E,04
a1 1.28E-01 ,5.18E,03 2.69E,05 3.45E,06
a2 1.34E-01 4.21E,04 1.77E,07 2.37E,08
a3 9.39E-02 ,1.68E,02 2.84E,04 2.66E,05
a4 8.68E-02 1.25E,02 1.57E,04 1.36E,05
a5 5.67E-02 ,7.41E,04 5.49E,07 3.11E,08
a6 3.97E-02 8.33E,04 6.93E,07 2.75E,08
a7 9.03E-02 2.92E,03 8.54E,06 7.72E,07
a8 1.13E-01 9.68E,03 9.37E,05 1.05E,05
ht 2.02E,04为了如上所述估计混合模型的1步预测和95%置信区间,我们使用从R或Minitab获得的ARIMA预测,然后将ht添加到ARIMA预测中。记录对数价格和条件方差:
•条件方差图成功反映了整个时间序列的波动性•高波动性与股价暴跌的时期密切相关 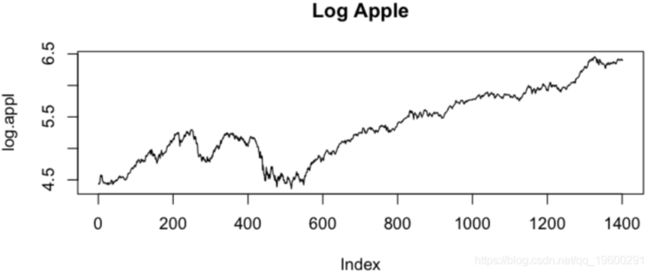

价格的95%预测间隔: 
对模型的最终检查是查看ARIMA-ARCH模型的残差的QQ图,即et =εt/ sqrt(ht)=残差/ sqrt(条件方差)。我们可以直接从R计算出来,然后绘制QQ图以检查残差的正态性。以下是代码和QQ图:
qqline(archres)
该图表明,残差似乎大致呈正态分布,尽管有些点不在直线上。但是,与ARIMA模型的残差相比,混合模型的残差更接近正态分布。

结论
时域方法是分析金融时间序列的有用方法。基于ARIM-ARCH / GARCH模型的预测中有一些需要考虑的方面:
首先,ARIMA模型专注于线性分析时间序列,并且由于新信息的存在,它无法反映最近的变化。因此,为了更新模型,用户需要合并新数据并再次估计参数。ARIMA模型中的方差是无条件方差,并且保持恒定。ARIMA适用于平稳序列,因此,应变换非平稳序列(例如对数变换)。
此外,ARIMA通常与ARCH / GARCH模型一起使用。ARCH / GARCH是一种测量序列波动性的方法,或更具体地说,是对ARIMA模型的噪声项建模的方法。ARCH / GARCH结合了新信息,并根据条件方差分析了序列,用户可以使用最新信息来预测未来价值。混合模型的预测区间比纯ARIMA模型的预测区间短。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析