网络爬虫-高阶
网络爬虫框架
一.Scrapy框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,利用Twisted异步网络框架来加快下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求。
1. Scrapy原理
-
Scrapy架构图
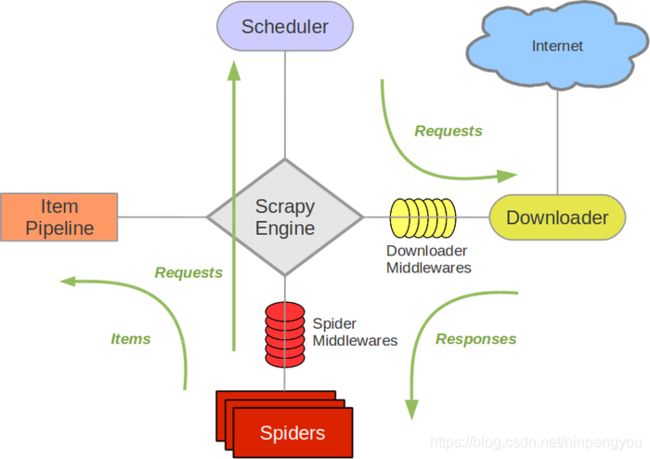
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
-
Scheduler(调度器): 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
-
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
-
Item Pipeline(管道):负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
-
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
-
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
-
-
Scrapy的运作流程
-
当爬虫(Spider)要爬取某URL地址的页面时,使用该URL初始化Request对象提交给引擎(Scrapy Engine),并设置回调函数。
Spider中初始的Request是通过调用start_requests() 来获取的。start_requests() 读取start_urls 中的URL,并以parse为回调函数生成Request 。
-
Request对象进入调度器(Scheduler)按某种算法进行排队,之后的每个时刻调度器将其出列,送往下载器。
-
下载器(Downloader)根据Request对象中的URL地址发送一次HTTP请求到网络服务器把资源下载下来,并封装成应答包(Response)。
-
应答包Response对象最终会被递送给爬虫(Spider)的页面解析函数进行处理。
-
若是解析出实体(Item),则交给实体管道(Item Pipeline)进行进一步的处理。
由Spider返回的Item将被存到数据库(由某些Item Pipeline处理)或存入到文件中。 -
若是解析出的是链接(URL),则把URL交给调度器(Scheduler)等待抓取。
-
-
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
2. Scrapy框架的安装与使用
- Windows 安装方式
Python 2 / 3
升级pip版本:pip install --upgrade pip
通过pip 安装 Scrapy 框架pip install Scrapy - Ubuntu 需要9.10或以上版本安装方式
Python 2 / 3
安装非Python的依赖 sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip 安装 Scrapy 框架 sudo pip install scrapy
二.Scrapy-Redis框架
1. Scrapy与Scrapy-Redis之间的区别
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
Scheduler
Duplication Filter
Item Pipeline
Base Spider
2. scrapy-redis架构

scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(https://github.com/scrapy/queuelib/blob/master/queuelib/queue.py)),但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
Base Spider
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
3.Scrapy-Redis分布式策略:
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master

首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
4. Scrapy-Redis与Redis的安装
-
Scrapy-Redis的安装
pip install scrapy-redis -
Redis的安装与设置
-
安装Redis
安装Redis:http://redis.io/download安装完成后,拷贝一份Redis安装目录下的redis.conf到任意目录,建议保存到:/etc/redis/redis.conf (Windows系统可以无需变动)
-
修改配置文件 redis.conf
打开你的redis.conf配置文件,示例:非Windows系统: sudo vi /etc/redis/redis.conf
Windows系统:C:\Intel\Redis\conf\redis.conf
1.Master端redis.conf里注释bind 127.0.0.1,Slave端才能远程连接到Master端的Redis数据库。
2.daemonize yno表示Redis默认不作为守护进程运行,即在运行redis-server /etc/redis/redis.conf时,将显示Redis启动提示画面;
3.daemonize yes则默认后台运行,不必重新启动新的终端窗口执行其他命令,看个人喜好和实际需要。
-
测试Slave端远程连接Master端
测试中,Master端Windows 10 的IP地址为:192.168.199.108-
Master端按指定配置文件启动 redis-server,示例:
非Windows系统:sudo redis-server /etc/redis/redis/conf
Windows系统:命令提示符(管理员)模式下执行 redis-server C:\Intel\Redis\conf\redis.conf读取默认配置即可。
-
Master端启动本地redis-cli:

-
slave端启动redis-cli -h 192.168.199.108,-h 参数表示连接到指定主机的redis数据库
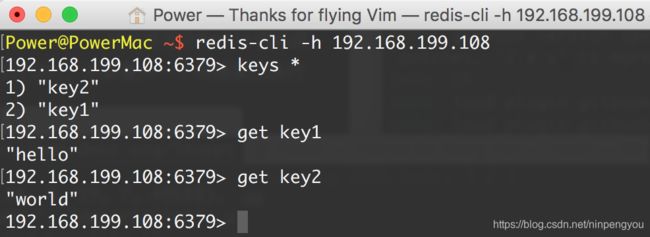
-
-
注意:Slave端无需启动redis-server,Master端启动即可。只要 Slave 端读取到了 Master 端的 Redis 数据库,则表示能够连接成功,可以实施分布式。
5.Redis数据库桌面管理工具
推荐 Redis Desktop Manager,支持 Windows、Mac OS X、Linux 等平台:
下载地址:https://redisdesktop.com/download