TCP-重传机制、滑动窗口、流量控制、拥塞控制
本篇文章诶学习 程序员乔戈里 的一篇微信推文的学习笔记,非原创,侵删。
TCP
TCP通过序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。
一、重传机制
当TCP针对数据包丢失的情况,会用重传机制解决。
以下四种是常见的重传机制。
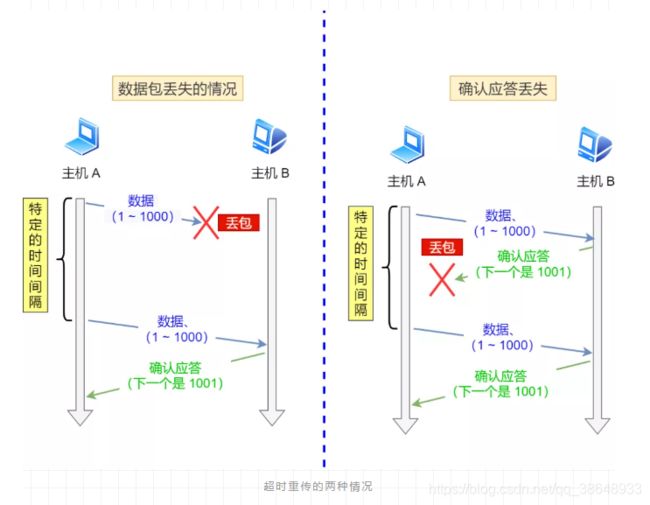
1、 超时重传
发送数据后,设定一个定时器,当超过指定时间后,没有收到对方的 ACK 确认应答报文后,就会重发该数据。
超时重传的原因:
- 数据包丢失
- 确认应答丢失
注:可以这样想,超时重传发生了,那么应该是一段时间内没收到ACK了,这时,丢弃的包一般是大量的;如果只是某个ACK丢了,大有后面的 D-SACK 来解决哦。
超时时间(RTO Retransmission Timeout)应该设置为多少呢?
略大于RTT(Round-Trip Time 往返时延)
- 太大的话,重发就很慢,丢了老半天才重发,没有效率,性能差
- 太小的话,导致没有丢就重发,增加网络拥塞(负担),导致更多的超时,导致更多的重发。
2、 快速重传(Fast Retransmit)
不以时间为驱动,以数据驱动重传。
什么意思呢?
当发送端收到了三个相同的ACK,就说明之前的SEQ还没有收到,就会在定时器过期之前,重传丢失的SEQ。

注:快速重传发生了,一般是某一个包丢失了,导致连续收到的三个 ACK 都是一样的。
3、 SACK
SACK(selective ACknowledge 选择性确认) 。
该方式需要在TCP头部 [选项] 字段里加一个 SACK 的东西。它可以将缓存的地图发给发送方。
发送方收到后就可以知道哪些数据丢失,哪些需要重传。

注:如果要支持 SCAK,必须双方都支持。
在Linux下,可以通过 net.ipv4.tcp_sack 参数打开这个功能。
4、 D-SACK
Duplicate SACk ,对SACK进行重用,除了像SACK中用来记录哪些是已经接收到的,还可以记录哪些是重复接受的。如何判别呢?
下面是个人理解:
- 当 ACK < SACK.LEFT 时:
这时,SACK作为确认已经收到的报文ACK区间,表示区间内的SEQ已经收到了。
此时的ACK指向的是以前没有收到的SEQ序号。
- 当 ACK > SACK.RIGHT 时:
这时,ACK明显已经超过了 SACK ,此时的 SACK 又叫做 Duplicate(重复)SACK,称为 D-SACK。
这时的D-SACK用于告知发送方:(这些SEQ我以前已经收到过了,只是我发出的ACK在网络传输中丢了,你以后不用再发这个SEQ给我拉~)
再从过程的角度看:
SACK用于告知发送方,接收方没有收到的SEQ;
D-SACK用于告知发送方,接收到SEQ但对应的ACK发出去后丢了(丢包)(解决超时重传)。
在Linux下,可以通过 net.ipv4.tcp_dsack 参数打开这个功能。
二、滑动窗口
解决一人一句的低效率问题。
概念:
- 窗口大小:无需等待确认,而可以继续发送数据的最大值。
窗口实际是 OS 开辟出的一个缓存空间。发送方主机在等到确认应答回答之前,必须在缓存区中保存已发送的数据。如果按期收到确认应答,数据可以从缓存区清除。
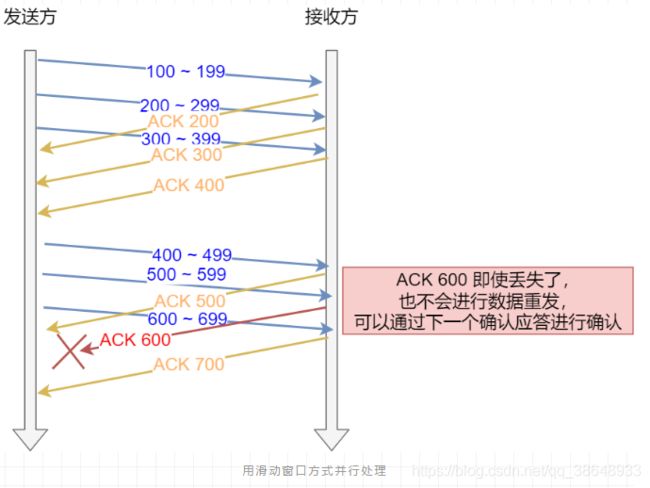
窗口大小由谁来决定呢?
窗口大小一般取决于你能接受多少,所以是由接收方去确定的。
TCP 头里有一个字段叫 window , 也就是窗口大小(可改变)。
1、 发送方窗口
由 窗口大小 + 三个指针 构成
-
SND.WND : 表示发送窗口的大小(大小由接收方决定)
-
SND.UNA : 是一个绝对指针,它指向已发送但没收到确认的第一个字节的序列号
-
SND.NXT:是一个绝对指针,它指向可发送但未发送的第一个字节的序列号。
-
SND.UNA + SND.WND : 通过起始+窗口大小确定的相对指针,指向窗口的最后一个字节。
2、 接受窗口
由两个指针构成:
- RCV.WND : 表示接受窗口的大小,它会告知发送方。
- RCV.NXT : 是一个指针,指向期望发送方发送来的下一个数据字节的序列号。
- RCV.WND + RCV.NXT : 相对指针,指向窗口最后一个字节的。
注:发送窗口约等于接受窗口。
三、流量控制
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。
TCP 提供了一种机制可以让 [发送方] 根据 [接收方] 的实际接收能力控制发送的数据量,这就是所谓的 流量控制。
流量控制是避免 [发送方] 填满 [接收方] 的缓存,但是并不知道网络传输过程发生了啥。
1、 操作系统缓冲区与滑动窗口的关系
我们假定了发送窗口和接收窗口是不变的,但是实际上,发送窗口和接收窗口中所存放的字节数,都是放在操作系统内存缓冲区中的,而操作系统的缓冲区,会被操作系统调整。
当[接收方]的OS没办法及时处理缓存区的报文时,会告诉[发送方]减小窗口的大小,但是缓存区不会同时减小(防止丢包),等到稳定后再减小缓存区。
为了防止这种情况发生,TCP 规定是不允许同时减少缓存又收缩窗口的,而是采用先收缩窗口,过段时间在减少缓存,这样就可以避免了丢包情况。
2、 窗口关闭
TCP 让 [接收方] 通过 ACK 指明 希望从 [发送方] 接收的数据大小(窗口大小)来进行流量控制。
如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。
窗口关闭存在风险
当 [接收方] 处理完缓存区后,会发出 ACK 告诉 [发送方] 窗口大小非0 ,但是假设这个ACK丢失了的话,那么出大问题!
这时,[发送方] 等着 [接收方] 的通知, [接收方] 等着 [发送方] 的数据。如不采取措施,这种相互等待的过程,就造成了死锁。
如何解决/防止 这种死锁现象?
TCP 连接一方收到对方的零窗口通知,就启动持续计数器。
计时器超时就会发起一次 窗口探测(window probe)报文 ,[接收方] 确认这个报文后,给出自己的接受窗口大小。
如果窗口为0,计时器重置。
如果窗口非0,死锁打破。
3、 糊涂窗口综合征
当 [接收方] 来不及处理缓存区的数据,会导致 [发送方] 的发送窗口越来越小。
到最后, 如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症。
为什么不可以这样做
发报文是有成本的,TCP+IP的头就有40字节,而为了几个字节的数据,要搭上这么大的开销,这太不经济了。
怎么让接收方不通知小窗口呢?
当 [窗口大小] 小于 min(MSS,缓存空间/2), 就会告知 [发送方] 窗口大小为0
怎么让发送方避免发送小数据呢?
使用 Nagle 算法,算法思路是延时处理,满足以下两个条件的一条才可以发送数据:
- 窗口大小 >= MSS 或者 数据大小 >= MSS
- 收到之前发送数据的 ack 回包。
只要没满足上面条件的一条,发送方一直在囤数据,知道满足条件为止。
Nagle算法默认打开。对于小数据交互的场景,比如telnet或ssh 这样的交互性比较强的程序,需要关闭Nagle算法。
可以在 Socket 设置 TCP_NODELAY 关闭该算法
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value, sizeof(int));
四、拥塞控制
为什么要有拥塞控制,不是有流量控制了吗
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大….
于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。
为了在 [发送方] 调节所要发送数据的量,定义了一个叫做 [拥塞窗口] 的概念。
什么是拥塞窗口?和发送窗口有什么关系?
拥塞窗口 cwnd(congestion window) 是发送方维护的状态变量,它会根据网络的拥塞程度动态变化。
从上文我们知道,发送窗口 swnd 和接受窗口 rwnd 是约等于的关系;
在引入拥塞窗口的概念后,swnd = min(cwnd,rwnd) 发送窗口等于拥塞窗口和接受窗口的最小值。
cwnd 变化的规则:
- 只要网络中没有出现阻塞,cwnd 就会增大;
- 但网络中出现了阻塞,cwnd就会减小;
如何判定网路阻塞?
发生超时重传时,被认定网络出现了拥塞。
以下为四种拥塞控制算法
慢启动、拥塞避免、拥塞发生、快速恢复
1、 慢启动
慢启动的规则就是:收到一个ACK,拥塞窗口就+1。
可以看到,每一次接收到的 ACK 都能加大 cwnd。((((1+1)+2)+4)+8)
cwnd根据这种特性会呈现出指数型的增长。
增长到哪是个头?
有一个慢启动门限 ssthresh (slow start threshold)状态变量。
- 当 swnd < ssthresh 时,采用 慢启动算法。
- 当 swnd >= ssthresh 时, 采用 拥塞避免算法。
2、 拥塞避免
当 swnd >= ssthresh 时,采用拥塞避免算法:
拥塞避免的规则就是: swnd 每收到一个ACK 增加 1 / cwnd,也就是收到以前发送数据的所有 ACK,swnd 才能增加1。
推理可知,cwnd 根据 拥塞避免 的特性,是呈线性增长的。
这种情况下, cwnd 一直增长,网络就会慢慢进入了拥塞的状况了,也就会出现丢包的现象。此时要重发丢失的包。
当触发重传机制,也就进入了 [拥塞避免] 算法。
3、 拥塞发生
从上面重传机制我们知道,主要重传机制有两种:
- 超时重传
- 快速重传
这两中对应的拥塞发生算法是不同的。
发生超时重传的拥塞发生算法
这个时候,慢启动门阀 ssthresh 和 拥塞窗口cwnd 的值会发生变化:
- ssthresh 设为 cwnd/2
- cwnd 设为1
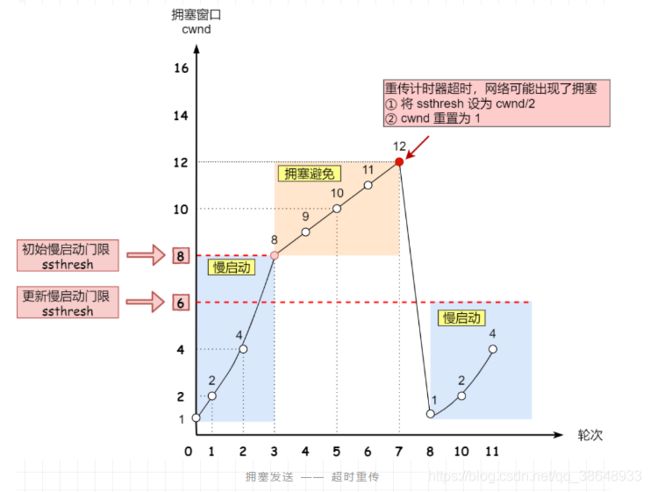
之后,也就是回到了慢启动,慢慢重新开始啦~
发生快速重传的拥塞发生算法
这种情况下:收到了三个连续的 ACK , 一般是某一个包丢了,整体的数据量传输还是没有问题的(SACK解决),但是为了以防万一,还是要将 ssthresh 和 cwnd 降低一点的。
- cwnd = cwnd / 2
- ssthresh = cwnd
注: 此时 cwnd 和 ssthresh 的值是一样的。然后就进入了快速恢复算法。
4、 快速恢复(+3 算法)
顾名思义,在只是丢了某一个包的情况下,我们将 阻塞窗口(cwnd) 降到了一半,那么我们就要快速恢复 cwnd 以便恢复到原来的传输速度。
它不用想 RTO 那么激烈,直接降到1,而是在只降一半的前提下+3然后拥塞避免。
快速恢复算法的规则如下:
- 在cwnd = cwnd/2, ssthresh = cwnd 之后
- cwnd += 3(确认有3个数据包(的ACK)收到了),然后继续拥塞避免算法。
