Bytesctf2021 frequently详解
frequently
先看的tcp的流,没发现什么东西,然后开始看UDP,在UDP的第一个流发现
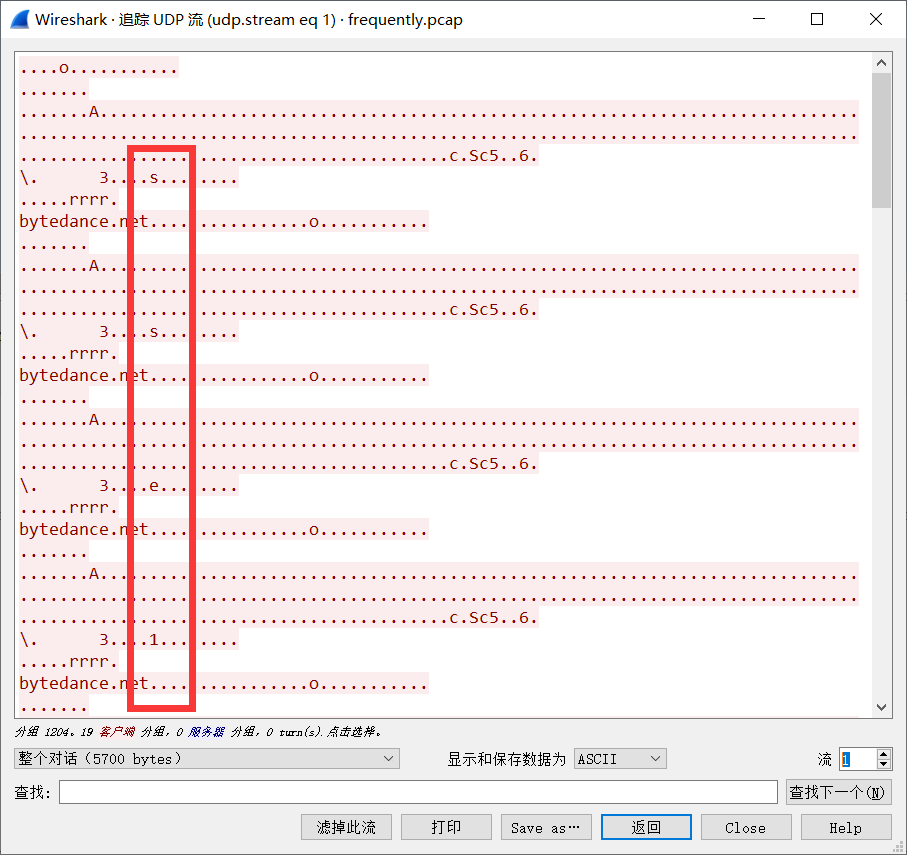
得到
se1f_wIth_m1sc^_^}
然后一直往后看,在第68个流发现png的base64加密后的数据
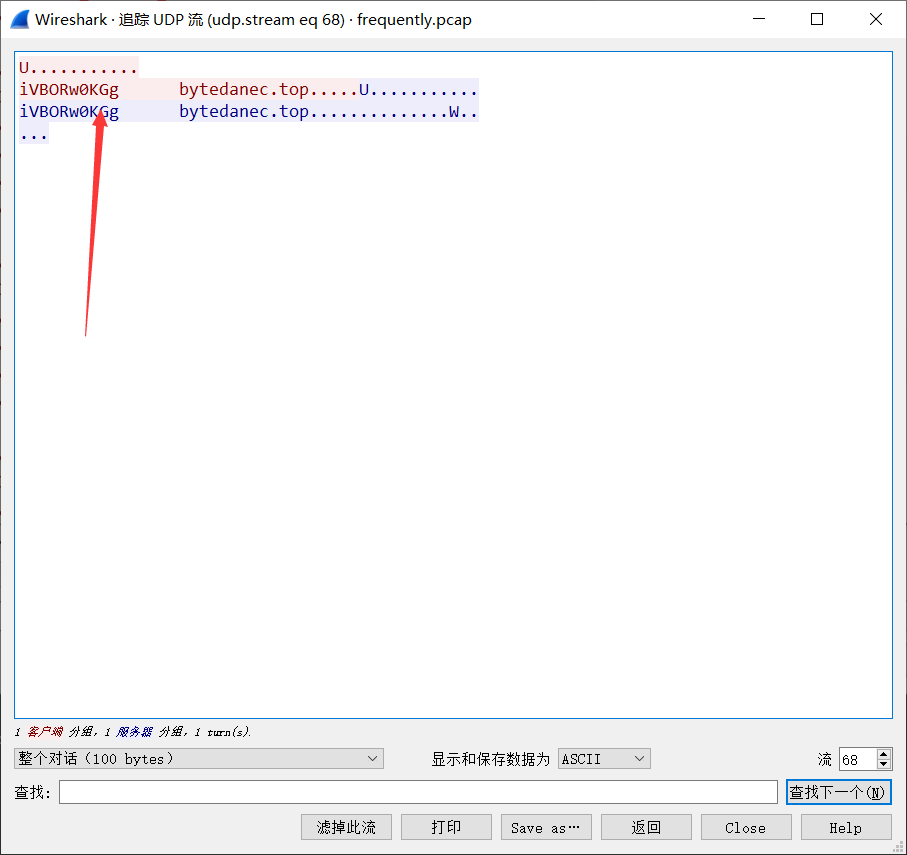
base64解密一下发现
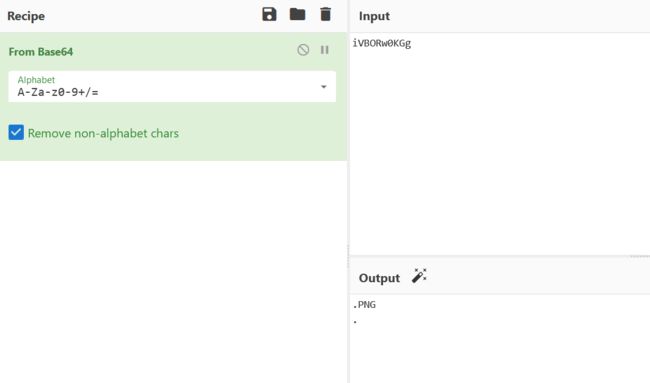
继续往后看发现多个一样的数据,传输图片无疑了。

当时解题时候直接依据这个提取了这部分数据,包括重复的包还有多的包等等(体现了对过滤语句的不熟练)
通过观察可以发现这部分数据的源地址和目的地址都是相同的可以先通过这个过滤
ip.src==10.2.173.238 and ip.dst==8.8.8.8
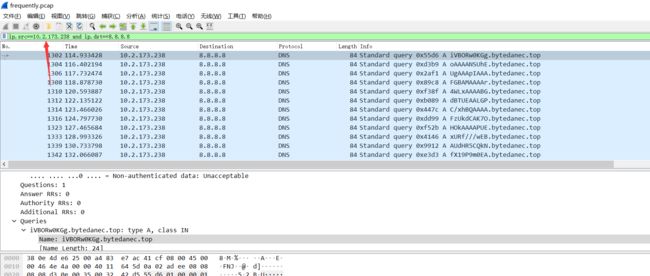
这样其实能提取大部分的数据包了,但是往下翻能发现。
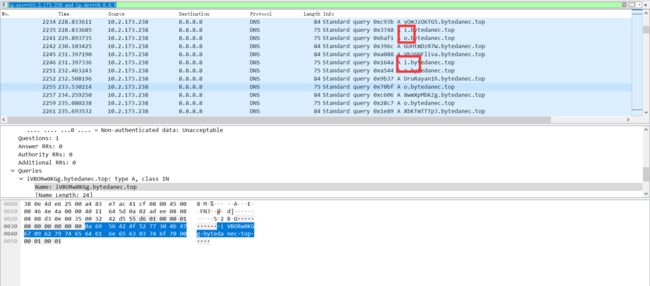
比赛的时候一并提取了这部分数据,最后发现图片不能显示,所以这部分数据显然不属于图片(看了wp之后瞎bb),所以要再通过过滤器过滤这部分数据,通过观察发现原来的属于png图片的包的长度是一定的。它们的dns.qry.name的长度也是一致的。
所以过滤出这部分数据有两种方式
通过观察发现这部分包的长度都为50
udp.length == 50 and ip.src == 10.2.173.238 and ip.dst==8.8.8.8
或者通过包的名字的长度 dns.qry.name.len
ip.src==10.2.173.238 and ip.dst==8.8.8.8 and dns.qry.name.len==24
通过tshark提取数据,-Y指定过滤器内容,-e指定输出内容
tshark -r .\frequently.pcap -T fields -Y "udp.length == 50 and ip.src == 10.2.173.238 and ip.dst==8.8.8.8" -e dns.qry.name
将内容输出到txt里
tshark -r .\frequently.pcap -T fields -Y "udp.length == 50 and ip.src == 10.2.173.238 and ip.dst==8.8.8.8" -e dns.qry.name > fre.txt
用winodws终端这样输出的话内容为gbk的方式,用python读取的时候会出现编码问题(可以直接粘贴),所以可以用linux终端输出到txt。
这样提取出来的数据转图片还是有问题的,仔细看过滤出来的包
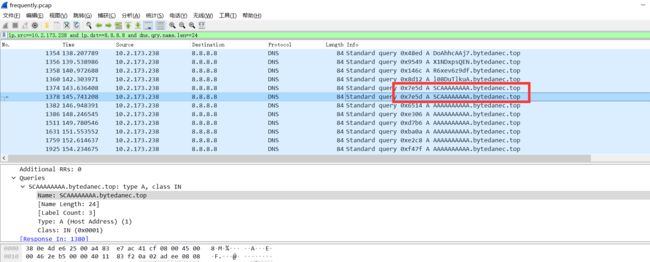
这两个包的dns.id的值相同,所以是同一个包,要对这些包的重复数据再进行一次过滤,参考mochu师傅的脚本
from base64 import *
with open('dns.txt', 'r') as f:
lines = f.readlines()
# print(lines)
sorted_lines = sorted(set(lines), key=lines.index)
# print(sorted_lines)
base64_data = ''
for line in sorted_lines:
base64_data += line[:10]
with open('flag.png', 'wb') as f1:
f1.write(b64decode(base64_data))
print(base64_data)
这里使用了set来删除重复的数据。得到

但是这张图片没有给我们任何信息,想到过滤的时候还漏掉了一部分数据

类似这个包的名字长度为15的数据,用包的名字长度再过滤下
dns.qry.name.len==15 and ip.src == 10.2.173.238 and ip.dst==8.8.8.8

然后我们需要做的就是提取这部分数据,里面还是有重复的数据,需要python去重
import re
with open('bin_data.txt','r') as f:
strings = f.readlines()
sorted_list = sorted(set(strings), key=strings.index)
flagstr = ''
for i in sorted_list:
# print(type(i[0]))
if i[0] == 'o':
flagstr += '0'
else:
flagstr += '1'
# print(flagstr)
print(len(flagstr)/8)
dd = re.findall(r'.{8}',flagstr)
print(dd)
flag = ''
for i in dd:
flag += chr(int(i,2))
print(flag)
The first part of flag: ByteCTF{^_^enJ0y&y0ur
合起来得到
ByteCTF{^_^enJ0y&y0urse1f_wIth_m1sc^_^}
参考链接:https://mochu.blog.csdn.net/article/details/120813077