ts视频下载 准备下载视频的你确定不进来看看吗
ts视频下载
- 前言
- 开发工具
- 解决思路
- 代码实现
-
- 解析m3u8文件,获取ts下载列表
- 多线程下载ts文件,以及ts文件顺序的存储
-
- 总代码
- ts文件顺序存储到本地文件中
- 多线程下载ts文件
- ts文件合成mp4
- 成果
-
- ts文件
- mp4文件
- 总结
前言
之前一直爬取的内容都是完整的文件,例如一整个mp3或则mp4,但是目前很多视频网站都开始采用ts流媒体视频的方式进行视频的展示,不知道你有没有这样的体验,兴致勃勃的打开一个电影网站,准备开始施展爬虫大法

查看xhr请求之后,本以为可以找到一个返回mp4的接口,没想到返回的是这一堆ts文件
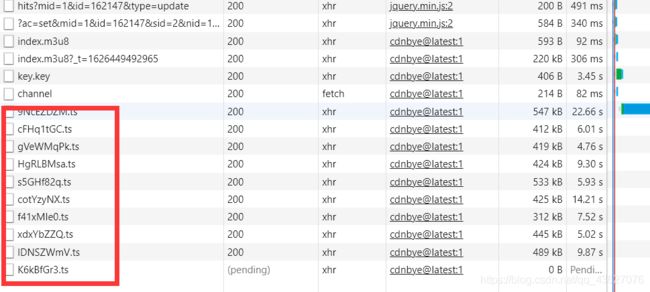
今天我们就来聊一聊怎么下载这些ts文件并将他们拼接为一个mp4
开发工具
ffmpeg,pycharm
解决思路
首先打开谷歌浏览器,F12,查看xhr请求,这一步相信兄弟们已经轻车熟路了。如下图

有两个诡异的m3u8,木错,这就是今天我们的突破口,一般第一个m3u8中存储的都是第二个m3u8文件的url,第二个m3u8文件则是存储的ts文件的urll。因为我们这次主要是讲怎么下载ts文件,所以直接用解析第二个m3u8文件,即可。
双击这个请求,就可以查看详情,其中Request URL就是调用的接口或则远程文件,直接调用则会下载该m3u8文件,然后解析一下,拿到ts的url列表就可以进行下载了。

先看一下这个m3u8文件的内容

很明显文件中存储的不是ts文件的完整地址,需要我们根据实际情况进行拼接就可以,查看的方式就是点击ts文件xhr请求进行查看如下图,很明显,红框圈中的就是我们要拼接在文件名之前的。这就拿到了真实的ts文件地址。
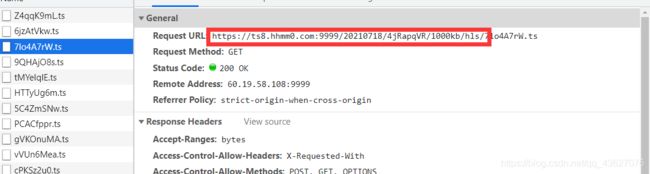
那么开整代码吧
代码实现
解析m3u8文件,获取ts下载列表
要使用到m3u8这个库来解析m3u8文件
import m3u8
tss = []
order = []
#realurl就是存储ts文件地址的m3u8文件的url ,这样返回的数据是json格式的,方便读取数据
data = m3u8.load(realurl).data
# appendurl就是要拼接在前面的那个地址 这样存入tss的ts文件地址都是真实地址
# order的作用是在将多个ts文件合成一个mp4时,由这个order提供各ts文件拼接的顺序
for i in data["segments"]:
tss.append(appendurl + "/" + i["uri"])
order.append(i["uri"])
到现在为止,ts文件拼接的顺序以及ts文件的真实地址就全部拿到了
多线程下载ts文件,以及ts文件顺序的存储
有一说一,这些ts文件不仅多,而且小,如果我们只是一个线程下载文件,未免太浪费时间了,而且效率太低了,这次我们采用多线程的方式进行大量ts文件的下载
总代码
def download(url, name):
#记录创立的线程
task_list = []
# 获取ts的真实地址和顺序
tss, order = getTss(url)
# 这里将ts文件顺序存储在m3u8,至于为啥这么做,因为ts文件数量太多了
file = open("E://file//order.m3u8", 'w')
# 这里将下载ts文件的本地路径输入到order.m3u8之中
for i in order:
file.write(f"file 'E:\\file\\ts\\" + i + "'");
file.write("\n")
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for i in range(0, len(order)):
# 启动多个线程下载文件
task_list.append(pool.submit(FileDownload.downloadFile, 'E://file//ts//' + order[i], tss[i]))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)
# 进行多个ts文件的合并
VideoUtil.mixTss(name)
# 合并结束之后把ts文件都删了,不然太占空间了
for u in order:
turl = f"E:\\file\\ts\\" + u
os.remove(turl)
ts文件顺序存储到本地文件中
主要代码
# 这里将下载ts文件的本地路径输入到order.m3u8之中
for i in order:
file.write(f"file 'E:\\file\\ts\\" + i + "'");
file.write("\n")
最终文件中存储的内容
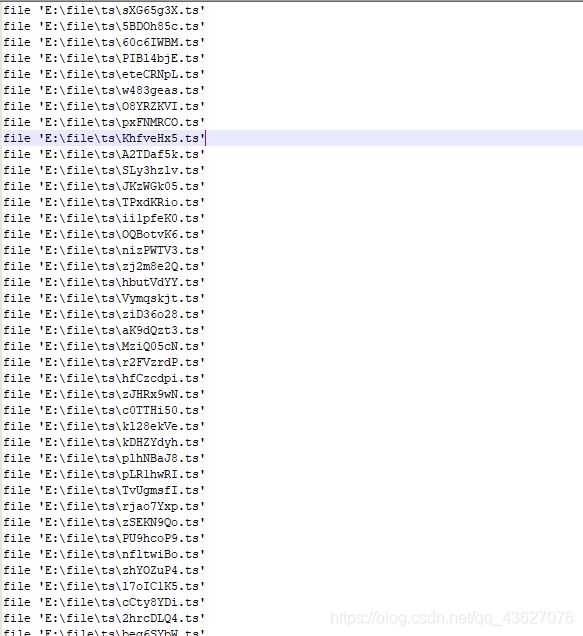
最好按照这种格式存入,之前在网上找的其他格式都会报错,但这个是ok的
多线程下载ts文件
yysy,多线程真的强,尤其是下载这些小文件,多线程真的是绝了
本文采用线程池的方式,为什么采用线程池呢,因为线程池可以帮我们保留一段时间空闲线程,可以减少线程创建和销毁所耗费的时间,大大提高多线程的效率,同时可以帮助我们限制线程的数量
主要代码
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for i in range(0, len(order)):
# 启动多个线程下载文件
task_list.append(pool.submit(FileDownload.downloadFile, 'E://file//ts//' + order[i], tss[i]))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)
ts文件合成mp4
主要思路就是利用刚刚生成的那个ts顺序文件(order.m3u8),按照文件中的顺序进行ts文件的拼接。
这里拼接ts文件时还是要使用ffmpeg,没有的兄弟们可以看下这个安装一下
ffmpeg安装教程
主要代码
def mixTss(name):
com = r'D:\\tool\\ffmpeg\\bin\\ffmpeg.exe -f concat -safe 0 -i E:\\file\\order.m3u8 -c copy E:\\file\\video2\\{}.mp4'.format(
name)
os.system(com)
这里解释一下
D:\tool\ffmpeg\bin\ffmpeg.exe : 本地ffmpeg的位置,设置了环境变量直接ffmpeg即可
E:\file\order.m3u8:刚刚生成的存储ts文件的顺序的文件路径
E:\file\video2\{}.mp4:视频最终合成之后存放的位置
至此,ts视频的下载以及合成一个mp4就实现了
成果
ts文件
这是下载过程中截的图,有一说一,看着这些文件爆炸式增加,还挺爽
mp4文件

具体就不给你们康了,你们猜猜是啥

总结
总之没有想象的这么难,做之前以为很复杂,其实还好,最后欢迎各位大佬指点。
