卷积神经网络算法_FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法

其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
- 书的购买链接
- 书的勘误,优化,源代码资源
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。
导言
光流预测一直都是计算机视觉中的经典问题,同时又是解决很多其他问题的基础而备受关注,例如,运动估计、运动分割和行为识别。随着深度神经网络技术在计算机视觉领域中引发的技术变革,基于深度神经网络的光流预测算法应运而生。本文中,SIGAI将以FlowNet到FlowNet2.0的演变,来和大家一起领略基于CNN(卷积神经网络)的光流算法的诞生与发展。
光流(optical flow)是指平面上,光照模式的变化情况。在计算机视觉领域,是指视频图像中各点像素随时间的运动情况。光流具有丰富的运动信息,因而在运动估计、自动驾驶和行为识别方面都有广泛应用。光流预测通常是从一对时间相关的图像对中,估计出第一张图像中各个像素点在相邻图像中的位置。
光流问题长久以来,主要被基于变分能量模型的优化算法和基于块匹配的启发式算法统治着。随着深度神经网络技术在计算机视觉领域取得的成功,科学家们开始尝试利用深度学习技术的优势去解决光流问题。
FlowNet:新技术的诞生
随着CNN在图像分割、深度预测和边缘预测方面的成功,研究人员思考,同样是每个像素点都要给出预测结果的光流预测问题能否也利用CNN进行预测呢?
FlowNet[1]是第一个尝试利用CNN去直接预测光流的工作,它将光流预测问题建模为一个有监督的深度学习问题。模型框架如下:
如图1输入端为待求光流的图像对I_1,I_2,输出端为预测的光流W。
W=CNN(θ,I_1,I_2)
其中 W,I_1,I_2均为x,y的函数,x,y为图像中像素的位置坐标。θ为CNN中待学习的参数。通过调节θ,来使网络具有光流预测的能力。
那么问题来了,什么样的网络结构具有光流预测能力呢?
FlowNet[1]中提出了两种可行的网络结构。
网络整体上为编码模块接解码模块结构,编码模块均为9层卷积加ReLU激活函数层,解码模块均为4层反卷积加ReLU激活函数层,在文中解码模块又被称为细化模块。整个网络结构类似于FCN(全卷机网络),由卷积和反卷积层构成,没有全连接层,因此理论上对输入图像的大小没有要求。
根据输入方式的不同,FlowNet又分为FlowNetSimple和FlowNetCorr。
编码模块(如图2):
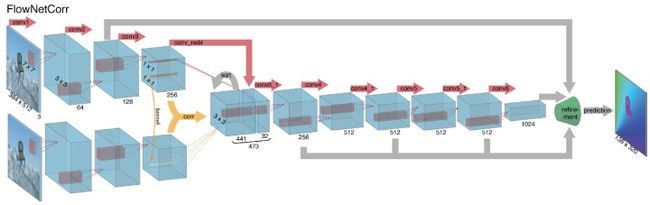
FlowNetS(FlowNetSimple) 直接将两张图像按通道维重叠后输入。
FlowNetC (FlowNetCorr)为了提升网络的匹配性能,人为模仿标准的匹配过程,设计出“互相关层”,即先提取特征,再计算特征的相关性。相关性的计算实际上可以看做是两张图像的特征在空间维做卷积运算。
解码模块(如图3):在解码细化的过程中,对每层的反卷积ReLU层,不仅输入前一层的输出,同时还输入前一层预测的低尺度的光流和对应编码模块中的特征层。这样使得每一层反卷积层在细化时,不仅可以获得深层的抽象信息,同时还可以获得浅层的具象信息,以弥补因特征空间尺度的缩小而损失的信息。

现在另一个问题来了,是否有足够的数据去训练网络呢?
为了训练网络,我们需要大量的具有光流真值的数据。而目前已知的具有光流真值的数据库规模都太小,即使利用数据增加的技术也相差甚远。另外,要获得真实世界中,自然图片的准确光流往往更是难以获得。
[1]中为解决这个问题,研究员们以牺牲图片真实性为代价,转而人为去合成大量的虚拟图像对。通过将一些3D椅子模型[3]随机的覆盖在一些从Flickr上检索的图片上合成图像,再对椅子和背景分别做随机的仿射变化。图像虽然看上去不是很自然,但是却很容易的获得了约22k带有光流真值的图像对。如图4,其中光流以颜色编码的形式展示,色调代表方向,强度代表大小。


充足的数据加上设计好的网络结构,剩下就是训练测试了。下面我们来定性的看下FlowNet的结果图。


最后的结果表明设计出的网络具有学习和预测光流的能力,证明CNN可以用来解决光流预测问题。并且实验表明,即使是人工合成的非自然图像,依然可以用来训练深度神经网络来预测光流。
精度方面,FlowNetC结果出现了过拟合,与FlowNetS相比也是难分伯仲,然而在FlowNet2.0中,研究者又更新了结论。速度方面,在NVIDIA GTX Titan上运行时,FlowNetS的运行时间为0.08s,FlowNetC因为加入了互相关层的计算,因此运行时间增加到0.15s。
比较其他算法和FlowNet的性能。在精度方面,虽然在公共数据库上离最好的传统算法还有差距,但是在合成的FlyingChair数据库上,FlowNet的结果精度是最好的。这使我们看到只要拥有合适充足的数据,基于CNN的算法还是非常有前景的。另外,由于FlowNet只需要简单的卷积运算,加上GPU的加速,在算法速度方面,FlowNet具有很大优势,远远快于目前其他领先的传统算法,可以实现实时的光流计算系统。以下是一个demo,大家可以欣赏一下:
https://lmb.informatik.uni-freiburg.de/Publications/2015/DFIB15/video-with-authors.mp4

FlowNet2.0:从追赶到持平
FlowNet提出了第一个基于CNN的光流预测算法,虽然具有快速的计算速度,但是精度依然不及目前最好的传统方法。这在很大程度上限制了FlowNet的应用。
FlowNet2.0是FlowNet的增强版,在FlowNet的基础上进行提升,在速度上只付出了很小的代价,使性能大幅度提升,追平了目前领先的传统方法。
主要有以下改进:
增加了训练数据,改进了训练策略
深度学习算法的一大优势即是具有学习能力,算法的性能会随着不断学习而提升。FlowNet2.0在FlowNet的基础上,额外增加了具有3维运动的数据库FlyingThings3D[4]和更加复杂的训练策略。


S_short即为FlowNet中的训练策略,FlowNet2中增加S_long策略和S_fine策略。
相比于FlyingChair中的图像只具有平面变换,FlyingThings3D中的图像具有真实的3D运动和亮度变化,按理说应该包含着更丰富的运动变换信息,利用它训练出的网络模型应该更具鲁棒性。然而实验发现,训练结果不仅与数据种类有关,还与数据训练的顺序有关。

实验表明,先在FlyingChair上按S_long策略,再在FlyingThings3D上按S_fine策略后,所得结果最好。单独在FlyingThing3D上训练的结果反而下降。文中给出了解释是尽管FlyingThings3D比较真实,包含更丰富的运动信息,但是过早的学习复杂的运动信息反而不易收敛到更好的结果,而先从简单的运动信息学起,由易到难反得到了更好的结果。
同时,结果发现FlowNetC的性能要高于FlowNetS。
利用堆叠的结构对预测结果进行多级提升
[2]文中发现所有最好的光流预测算法都利用了循环优化的方法。而基于CNN的像素级预测算法结果往往都含有很多噪声和模糊。通常的做法都是利用一些后处理方法对结果进行优化,如FlowNet中,利用传统变分优化方法对FlowNet输出结果进行再优化。那么是否也能够利用CNN来代替后处理方法对结果进行再优化呢?文中对这一问题进行了探究。
实验结果证明在FlowNetC的基础上堆叠FlowNetS,当以每个FlowNet为单位逐个进行训练时,得到的结果最优。也就是说在训练当前FlowNet模块时,前面的FlowNet模块参数均为固定状态。
此外,发现后续的堆叠FlowNet模块,除了输入I_1、I_2外,再输入前一模块的预测光流W_i,图像I_2经预测W_i的变换图像I_2(w_i)以及误差图像|I_1-I_2(W_i)|后,可以使新堆叠的FlowNet模块专注去学习I_1与I_2(W_i)之间剩下的运动变换,从而有效的防止堆叠后的网络过拟合。

实验表明,当以FlowNetC为基础网络,额外堆叠两个FlowNetS模块后,所得结果最好,[2]中用FlowNet2-CSS表示。
同时指出,随着优化模块的堆叠,FlowNet2的计算速度会有所下降,因此可以通过按比例消减FlowNet各层的特征通道数来减少计算量。[2]推荐保留每层3/8的通道数是一个不错的选择。文中将消减后的网络用FlowNet2-c和FlowNet2-s表示。最快的FlowNet2-s精度与FlowNetS的精度近似,而运算速率可以达到140fps(在Nvidia GTX 1080上测试)。
针对小位移的情况引入特定的子网络进行处理
最后,由于FlowNet在真实图片的小位移情况下,结果往往不够理想。因此[2]中,针对小位移情况改进了FlowNet模块的结构,首先将编码模块部分中大小为7x7和5x5的卷积核均换为多层3x3卷积核以增加对小位移的分辨率。其次,在解码模块的反卷积层之间,均增加一层卷积层以便对小位移输出更加平滑的光流预测。文中将针对小位移改进后的网络结构命名为FlowNet2-SD。在训练数据的选择上,针对小位移,又重新合成了以小位移为主的新的数据库ChairsSDHom,并将此前的堆叠网络FlowNet2-CSS在ChairsSDHom和FlyingThings3D的混合数据上继续微调训练,将结果网络表示为FlowNet2-CSS-ft-sd。
最后,再利用一个新的小网络对FlowNet2-CSS-ft-sd的结果和FlowNet2-SD的结果进行融合,并将整个网络体系命名为FlowNet2。结构如下:

从实验结果来看,FlowNet2在各个公共数据库上,在精度方面已经追平了目前最好的一些传统算法。同时,在速度上依然保持着高效快速的优势。下面我们看一下各种情况下FlowNet2的输出结果:

小位移情况下,FlowNet2-CSS的光流预测噪声非常大,而FlowNet2-SD的输出非常光滑,最后融合结果充分利用了FlowNet2-SD的结果。

大位移情况下,FlowNet2-CSS预测出了大部分运动,而FlowNet2-SD则丢失了大部分运动信息,最后融合结果又很好的利用了FlowNet2-CSS的结果。
综上,FlowNet2-CSS与FlowNet2-SD做到了很好地互补,共同保证了FlowNet2在各种情况下的预测质量。
文中还通过将FlowNet2的预测结果直接用于运动分割和动作识别的任务中,证明FlowNet2的精度已完全可以和其他传统算法媲美的程度,已达到可以实际应用的阶段。
最后我们再来欣赏一下FlowNet2.0的实时demo:
https://v.qq.com/x/page/c0503q9j8hf.html?
小结
相对于传统方法来看,基于CNN的光流算法沿袭了CNN算法的优势,即具有由数据驱动的学习能力,也就是说,它的预测能力是可以随着不断学习而不断提升的。从FlowNet2.0的提升中我们可以看到,改变训练策略和增加数据种类就使结果得到了提升。这也反过来说明了,数据对于深度学习算法的重要性。
另外,基于CNN算法由于主要需要的是简单的卷积运算,加上GPU的并行加速,往往可以获得很快运行速度,使得实时的光流预测系统成为可能,促进了光流预测系统的广泛应用。
因此,目前来看,基于CNN的光流预测算法具有很好的发展前景,超越传统算法也是指日可待。
参考文献
[1] A. Dosovitskiy et al., "FlowNet: Learning Optical Flow with Convolutional Networks," 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2016, pp. 2758-2766.
doi:10.1109/ICCV.2015.316
[2] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy and T. Brox, "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, USA, 2017, pp. 1647-1655.
doi:10.1109/CVPR.2017.179
[3] M. Aubry, D. Maturana, A. Efros, B. Russell, and J. Sivic.
Seeing 3d chairs: exemplar part-based 2d-3d alignment using a large dataset of cad models. In CVPR, 2014
[4] N.Mayer, E.Ilg, P.Häusser, P.Fischer, D.Cremers, A.Dosovitskiy, and T.Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。
推荐阅读
[1] 机器学习-波澜壮阔40年 SIGAI 2018.4.13.
[2] 学好机器学习需要哪些数学知识?SIGAI 2018.4.17.
[3] 人脸识别算法演化史 SIGAI 2018.4.20.
[4] 基于深度学习的目标检测算法综述 SIGAI 2018.4.24.
[5] 卷积神经网络为什么能够称霸计算机视觉领域? SIGAI 2018.4.26.
[6] 用一张图理解SVM的脉络 SIGAI 2018.4.28.
[7] 人脸检测算法综述 SIGAI 2018.5.3.
[8] 理解神经网络的激活函数 SIGAI 2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 SIGAI 2018.5.8.
[10] 理解梯度下降法 SIGAI 2018.5.11
[11] 循环神经网络综述—语音识别与自然语言处理的利器 SIGAI 2018.5.15
[12] 理解凸优化 SIGAI 2018.5.18
[13]【实验】理解SVM的核函数和参数 SIGAI 2018.5.22
[14]【SIGAI综述】 行人检测算法 SIGAI 2018.5.25
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上) SIGAI 2018.5.29
[16] 理解牛顿法 SIGAI 2018.5.31
[17]【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题 SIGAI 2018.6.1
[18] 大话Adaboost算法 SIGAI 2018.6.1
原创声明
本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。

更多干货请关注V X公众号:SIGAI