nltk分词器编写-语言模型-循环神经网络相关理解
今天学习的内容是文本预处理、语言模型、循环神经网了的内容,主要是有以下内容:
1、分词,索引,建立词语到index的映射
2、一种语言模型,两种表示。两种采样方式
3、循环神经网络理解,侧重理解,代码为辅助。
首先来说说分词的事情,分词,顾名思义,就是将句子分成单个词语,另外去掉所有的标点符号。教程中给出的分词函数较为简单,而且分词后的效果也不太好,这里我写了一个简单的分词器可以供大家参考使用。
第一步,移除句子中的特殊字符,当然传入的参数是一个单句。
def remove_symbols(sentence):
import string
del_estr = string.punctuation + string.digits # ASCII 标点符号,数字
replace = " " * len(del_estr)
tran_tab = str.maketrans(del_estr, replace)
sentence = sentence.translate(tran_tab)
return sentence第二步,载入nltk库、停用词、用户自定义词表,分词。
# 对句子进行分词
def segment(text, userdict_filepath="userdict2.txt", stopwords_filepath='stopwords.txt'):
import nltk
# nltk..load_userdict(userdict_filepath)
stopwords = [line.strip().lower() for line in open(stopwords_filepath, 'r', encoding='utf-8').readlines()] # 这里加载停用词的路径
# seg_list = nltk.word_tokenize(text.replace(',',' '))
final_list = []
temp_list = []
with open(userdict_filepath, 'r', encoding='utf-8') as f:
for line in f:
temp_list.append(line.strip(' ').strip('\n'))
f.close()
temp = []
for line in temp_list:
for li in line.lower().split(' '):
if len(li) != 0:
temp.append(li.strip('\t'))
final_list.append(tuple(temp))
temp.clear()
userdict_list = final_list
# print(userdict_list)
tokenizer = MWETokenizer(userdict_list, separator=' ')
seg_list=tokenizer.tokenize(nltk.word_tokenize(remove_symbols(text).lower()))
seg_list_without_stopwords = []
for word in seg_list:
if word not in stopwords:
if word != '\t':
seg_list_without_stopwords.append(word)
return seg_list_without_stopwords第三步,设定几个测试的句子,
text_list=[
'I like swimming.',
'Studying makes me happy.',
'I am a boy',
'I am a student of XXXXX university.'
]第四步,建立分词结果到index映射,并完成text_list中分词后的结果到index的映射。请注意,这里在分词之后,已经去掉了停用词,仅仅保留了部分特征词语,并不是所有的词到index的映射。
totalvocab_tokenized = []
single_sentence=[]
for i in text_list:
allwords_tokenized = segment(i, "userdict2.txt", 'stopwords.txt')
totalvocab_tokenized.extend(allwords_tokenized)
single_sentence.append(allwords_tokenized)
dict={}
index=0
for key in list(set(totalvocab_tokenized)):
dict[key]=index
index=index+1
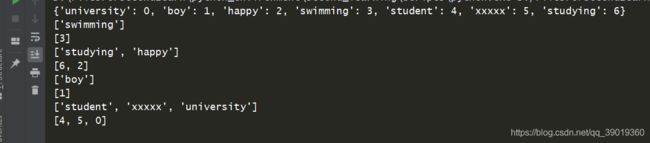
print(dict)
temp=[]
sequential_list=[]
for sentence in single_sentence:
# print(sentence)
# print('indexed:')
for key in sentence:
temp.append(dict[key])
sequential_list.append(temp)
temp=[]
for i,j in zip(single_sentence,sequential_list):
print(i)
print(j)
输出的结果如下图所示:
其次,我来谈谈我对教程中提到的语言模型的理解,主要采用的是文字描述的方式,因为画图并不是我的强项。
对于一门语言,对他进行建模是一件非常痛苦的事情,而将一个语言模型的常用词汇抽取出来,通过大语料库可以给语言建模。
n元语法,简单来说,就是一个概率的情况,比如“你好世界”,在第一个词为“你”的情况下,第二个词为“好”的概率;在前两个词为“你好”情况下,第三个词为“世”的概率。。。。。以此类推。
但是n元语法有一个致命的问题,那就是随着句子序列的增长,它的计算复杂度呈现出指数级增长,计算开销过大。
下面需要用到的知识就是采样问题了,主要是分为相邻采样和随机采样。
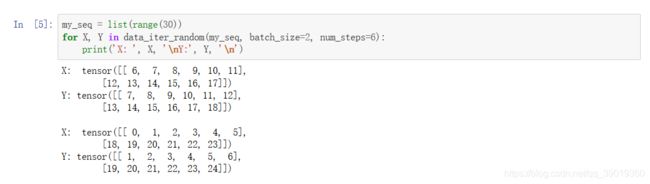
随机采样:在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
举个例子:
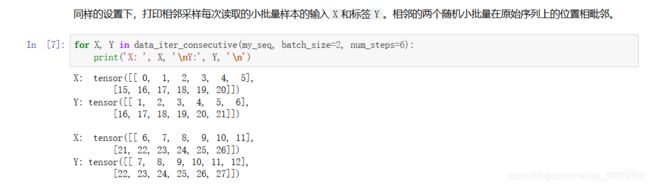
相邻采样:在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
举个例子:
最后是这次学习到的循环神经网络。
给出一个从网上其他博客上面找到的循环神经网络的示意图:
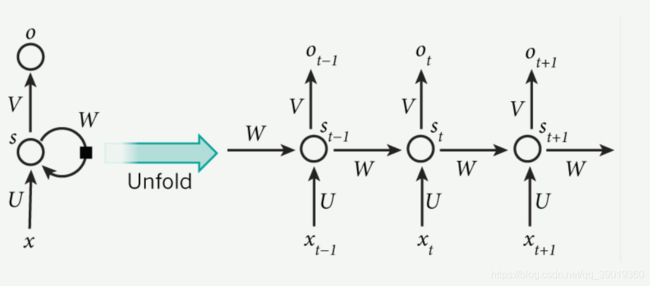
简单说一下自己的理解, 相比较与多层感知机和单层的神经网络,他们都是经过中间的隐藏层和softmax层之后,直接输出结果。循环神经网络中,隐藏层结果被计算出来之后,会同时被传送到该时刻下的输出层并且传送到下一个时序,和下一个时序的输入结果,以此类推。
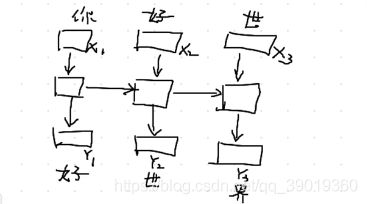
可以这样理解,用“你”来预测“好”,用“你好”来预测“世”,以此类推。
哦,对了,给大家一个可参考的pytorch动手学习深度学习的代码参考动手学习深度学习-PyTorch
下面给一段代码吧,都是从教程中“抄写”下来的,增加一下自己的理解,其实学习到现在,更重要的是要动手去敲代码,理解的基础上去写代码。代码如下:
import torch
import torch.nn as nn
import time
import math
import sys
import d2lzh_pytorch as d2l
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
num_steps, batch_size = 35, 2
X = torch.rand(num_steps, batch_size, vocab_size)
state = None
Y, state_new = rnn_layer(X, state)
print(Y.shape, state_new.shape)
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance(state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
model = RNNModel(rnn_layer, vocab_size).to(device)
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
其实,写这么多东西,都是自己很粗浅的理解,之前学习过这些内容,但是感觉学习效果很不好,这次再学习的时候,我还是要在理解的基础上多看看代码,思路和实现是并重的,这是我第一遍学习的时候惨痛教训。 总之,遇到事情,就想办法解决吧,冲就完事了,如果有问题卡着你很长时间,你还没有思路,没有任何进展的话,别有什么遗憾,放弃吧,放弃之后,你可以用时间来做其他事情,学习一些其他的知识。 不用纠结,一直向前走就好了,加油,FIGHTING!!!