GAN模型计算量减少至1/9!MIT韩松团队提出GAN压缩法,已开源
点上方蓝字计算机视觉联盟获取更多干货
在右上方 ··· 设为星标 ★,与你不见不散
编辑:Sophia
计算机视觉联盟 报道 | 公众号 CVLianMeng
转载于 :机器之心
AI博士笔记系列推荐:
博士笔记 | 周志华《机器学习》手推笔记“神经网络”

生成模型 GAN 是机器学习领域里最为重要的发展方向之一。但这类算法需要消耗巨量算力,大多数研究者已经很难得出新成果。近年来,这一方向颇有被大型机构垄断的趋势。
但近日,来自麻省理工学院(MIT)、Adobe、上海交通大学的研究者提出了一种用于压缩条件 GAN 的通用方法。这一新技术在保持视觉保真度的同时,将 pix2pix,CycleGAN 和 GauGAN 等广泛使用的条件 GAN 模型的计算量减少到 1/9~1/21。该方法适用于多种生成器架构、学习目标,配对或非配对设置。
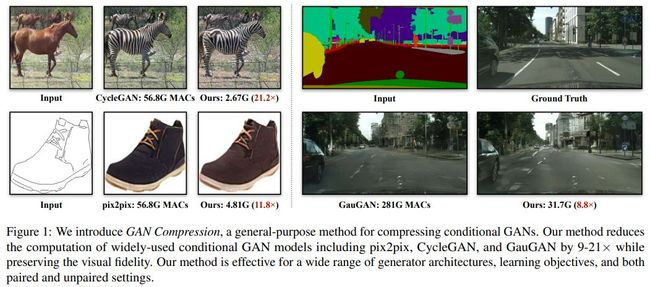
目前该研究的论文已被 CVPR 2020 大会收录,有关 GAN 压缩框架的 PyTorch 版实现也已开源。
项目链接:https://github.com/mit-han-lab/gan-compression
GAN 压缩后的具体性能如何?在研究者们展示的 Demo 中,使用 CycleGAN 为视频中的马添加斑马条纹所需的算力不到 1/16,帧数提高了三倍,而且效果还有所提升:
值得一提的是,该研究所使用的硬件平台是英伟达的边缘 AI 计算芯片 Jetson Xavier GPU。根据官方公布的数据,Jetson Xavier 的 INT8 算力为 22+10TOPS,骁龙 865 则是 15TOPS。压缩后的 GAN 现在看来已经可以跑在机器人、无人机等小型设备上了,未来塞进手机指日可待。

论文链接:https://arxiv.org/pdf/2003.08936v1.pdf
总体介绍
生产对抗网络(GANS)擅长合成十分逼真的图像。GAN 的一种变体——条件式生成对抗网络(conditional generative adversarial network,cGAN)在很多计算机视觉和图像学应用中都能够实现可控制的图像合成。但这些应用大都需要模型与人互动,因此需要低延迟的设备上才能获得更好的用户体验。
然而,近来推出的一些 cGAN 在计算强度上比当前识别卷积神经网络(CNN)大 1 至 2 个量级。举例而言,GanGAN 每张图像消耗 281G Macs,而 MobileNet-v3 仅需 0.44G Macs,这就导致前者很难用于交互式部署。
而且,就目前来看,边缘设备又多数受到内容以及电池之类硬件层面上的限制,也阻碍了 GAN 在边缘设备上的部署。
因此,基于 GAN 和 cGAN 在图像合成领域存在的这些问题,韩松团队提出了 GAN 压缩,这是一种通用压缩方法,用于减少 GAN 的推理时间以及计算成本。同时,压缩生成模型面临两个基本困难:GAN 训练不稳定,尤其是在未配对的情况下;生成器与 CNN 不同,因此很难使用现有的 CNN 设计。为了解决此问题,团队将知识从原始的教师生成器中间表示层传递到其相应的学生生成器层中。
为了降低训练成本,团队还通过训练包含所有可能通道数的「once- for-all network」,将模型训练与架构搜索分离。这个「once-for-all network」可以通过权重共享产生许多子网络,无需训练就可以评估每个子网络的性能。该模型可应用至各种条件下的 GAN 模型,不管其属于哪种模型架构、学习算法或监督设置(配对或未配对)。
通过大量的实验,团队已证明了此方法可以将 pix2pix,CycleGAN 以及 GauGAN 三种广泛使用的 GAN 模型计算量减少至 1/9 到 1/21,同时还不会损失生成图像的保真度。
具体方法
我们都知道,对用于交互式应用的条件式生成模型进行压缩具有挑战性,这主要是由以下两方面原因造成的。其一,从本质上讲,GAN 的动态训练非常不稳定;其二,识别和生成模型之间存在的巨大架构差异导致很难直接使用现有的 CNN 压缩算法。
基于这些原因,研究者提出了专门针对高效生成模型的训练方案,并利用神经架构搜索(NAS)进一步增加压缩比。GAN 压缩框架整体架构如下图 3 所示,其中他们利用 ResNet 生成器作为示例。需要强调的是,同一框架可以应用于不同的生成器架构和学习目标。
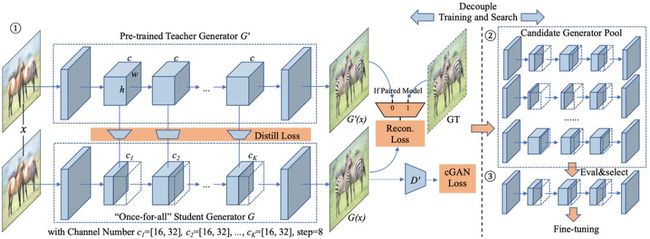
图 3:文中 GAN 压缩框架的整体架构图。
目标函数
1. 统一配对学习和非配对学习
广泛的训练目标使得构建通用压缩框架非常困难。为了解决这一问题,研究者在模型压缩设置中统一了配对和非配对学习,不管教师模型最初是如何训练的。给定原始教师生成器 G′,研究者将非配对训练设置转换为配对设置。对于非配对设置,可以将原始生成器输出视为真值并使用配对训练目标训练压缩后的生成器 G。
学习目标总结如下:

基于这些修改,现在可以将同一个压缩框架应用于不同类型的 cGAN。而且,与原始的非配对训练设置相比,使用上述伪对(pseudo pair)进行学习可以使训练更加稳定,并产生更好的结果。
2. 从教师判别器中学习
尽管此研究致力于压缩生成器,但判别器 D 中储存着 GAN 的有用信息。因此,研究者利用了同一个判别器架构,使用来自教师判别器的预训练权重,与压缩生成器一起微调判别器。
在实验中,研究者观察到,预训练判别器可以指导学生生成器的训练。使用一个随机初始化的判别器通常会导致训练不稳定及图像质量下降。这个 GAN 的目标可以写成以下形式:

在上式中,研究者使用来自教师判别器 D′的权重来初始化学生判别器 D。他们使用一个标准的极小化极大优化器训练 G 和 D。
3. 中间特征蒸馏
知识蒸馏是 CNN 模型压缩用到的一种普遍方法。通过匹配输出层 logit 的分布,可以将来自教师模型的暗知识(dark knowledge)迁移到学生模型中,提高学生模型的性能。然而,条件 GAN 通常会输出一个确定的图像,而不是概率分布。
为了解决上述问题,研究者匹配了教师生成器的中间表示。中间层包含的通道越多,它们所能提供的信息越丰富,学生模型所获取的输出之外的信息也越多。蒸馏目标如下:

其中,G_t(x) 和 G′_t(x) 是学生和教师模型中第 t 个被选层的中间特征激活,T 表示层数。
4. 完整优化目标
最终目标可以写成如下形式:

其中,超参数λ_recon 和 λ_distill 控制每个项的重要性。
高效生成器设计空间
选择一个设计良好的学生架构对最终知识蒸馏的效果是至关重要的,研究者发现,光是缩减教师模型的通道数量并不能使学生模型更紧凑:当计算缩减量超过 4 倍时,性能就会显著下降。
1. 卷积分解和层灵敏度
现有的生成器通常采用传统卷积来匹配 CNN 分类和分段设计。近来一些高效的 CNN 设计广泛采用卷积的分解形式(depthwise + pointwise),在性能和计算二者之间的均衡性更好。研究者发现,分解的卷积也可以用在 cGAN 的生成器设计上。
2. 使用 NAS 实现自动裁剪通道
现有的生成器在所有层上使用手动设计(并且几乎统一)的通道数,如此一来就会产生冗余,远非最优方法。为了进一步提升压缩效率,研究者使用通道剪枝(channel pruning)来自动选择生成器中的通道宽度,从而减少冗余,二次减少计算量。这一方法支持有关通道数的细粒度选择,针对每个卷积层,可以从 8 的倍数中选择卷积层,从而平衡 MAC 和硬件并行性。
解耦训练与结构搜索
研究者依照最近 one-shot 的 NAS 方法的研究,将模型训练与架构搜索脱钩。首先,训练一个支持不同通道数量的「once-for-all」网络,其中的每个子网络都经过了同等训练。图 3 阐释了整个框架。研究者假设原始的教师生成器有 个通道,对于给定的通道数
个通道,对于给定的通道数 ,从「once-for-all」的权重张量提取第一个
,从「once-for-all」的权重张量提取第一个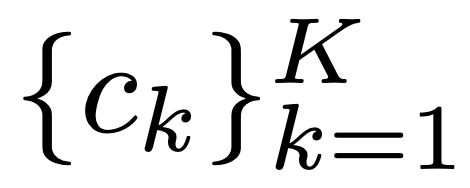 通道,获得子网络的权重网络。
通道,获得子网络的权重网络。
在每一个训练步骤中,使用学习目标对具备某一通道数的子网络进行随机取样,计算输出和梯度,更新提取的权重(公式 4)。由于最先被抽取的几个通道更新频率更高,它们在所有权重之中扮演着更为关键的角色。
这个「once-for-all」网络训练好之后,研究者直接在验证集上评估了每个子网络的性能,找出了最佳的子网络。「once-for-all」网络已经经过了权值共享的彻底训练,无需再进行微调(fine-tuning)。这个结果近似于从头开始训练模型的性能。
通过这种方式,只需要训练一次,且无需再进一步训练,就能评估所有评估所有通道的配置,并依据搜索结果找到其中最佳。当然,也可以对选中的架构进行微调来进一步提升其性能。
实验结果
研究者在以下三种条件式 GAN 模型上进行实验以验证文中 GAN 压缩框架的泛化性,它们分别是 CycleGAN、Pix2Pix 和 GauGAN。所使用的四个数据集为 Horse↔zebra、Edges→shoes、Cityscapes 和 Map↔aerial photo。
下表 1 展示了在上述四个数据集上压缩 CycleGAN、Pix2Pix 和 GauGAN 模型的量化结果。
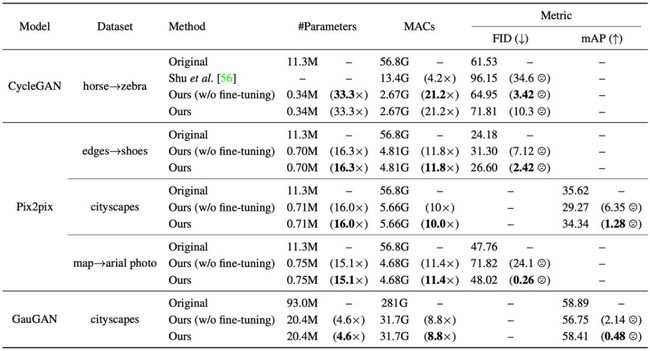
表 1:三种条件式 GAN 模型压缩的量化评估,其中 Cityscapes 数据集上使用 mAP 度量(越高越好),其他数据集上使用 FID 度量。结果显示,在性能轻微下降的情况下,文中 GAN 压缩方法可以在 MACs 上将当前 SOTA 条件式 GAN 压缩 7 至 21 倍,在模型大小上压缩 5 至 33 倍。对于 CycleGAN 模型压缩,文中 GAN 压缩方法远优于以往的 CycleGAN-specific Co-evolution 方法。
性能与计算之间的权衡
该方法除了能够实现较大的压缩率以外,同时其也可以提升不同模型大小的性能。下图 6 显示了在 pix2pix 模型中,在不同数据集上的性能与计算的权衡。

图 6:在 Cityscapes 与 Edges→Shoes 数据集上 pix2pix 的权衡曲线。剪枝与蒸馏方法在大型模型中超出了从头开始训练,然而在模型被急剧压缩时表现较差。
效果展示
下图 4 为使用该方法得到的效果展示。图中分别给出了输入数据、标准输出、原始模型输出以及压缩后模型的输出。从图中可以看出,即使在较大的压缩率下,研究者所提方法仍然能保持输出图像的视觉可信度。

图 4:Cityscapes、Edges→Shoes 以及 Horse→Zebra 数据集上效果比较。
硬件推理加速
对于真实场景交互应用而言,在硬件设备上推理加速的重要性要远大于减少计算消耗。如下表 2 所示,为验证所提方法在实际应用中的有效性,研究者在具有不同运算性能的设备上面测试了压缩模型的推理速度。
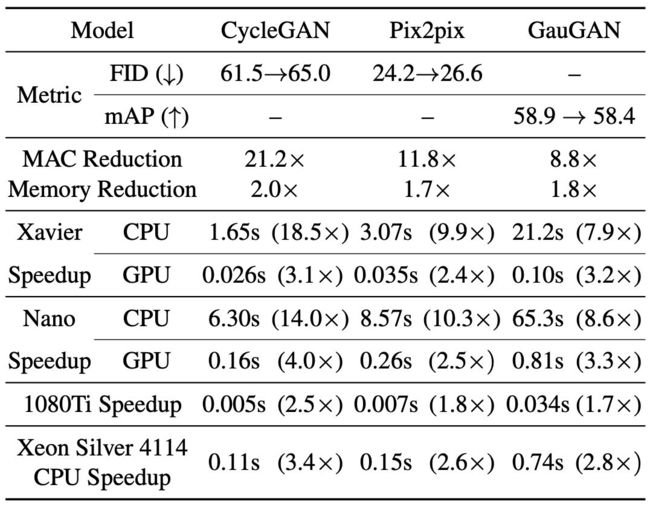
表 2:在 NVIDIA Jetson AGX Xavier、NVIDIA Jetson Nano、1080Ti GPU 和 Xeon CPU 上测到的内存和延迟下降。
结论
在本文中,韩松团队提出的通用压缩框架能够显著降低条件式 GAN 中生成器的计算花销和模型大小,并且通过知识蒸馏和自然架构搜索来提升训练稳定性以及模型效率。实验表明,文中提出的 GAN 压缩方法能够在保持视觉质量的同时压缩数种条件式 GAN 模型。他们表示,未来的研究工作将侧重于降低模型延迟以及构建生成视频模型的高效框架。
END
声明:本文来源于网络
如有侵权,联系删除
联盟学术交流群
扫码添加联盟小编,可与相关学者研究人员共同交流学习:目前开设有人工智能、机器学习、计算机视觉、自动驾驶(含SLAM)、Python、求职面经、综合交流群扫描添加CV联盟微信拉你进群,备注:CV联盟

最新热文荐读
GitHub | 计算机视觉最全资料集锦
Github | 标星1W+清华大学计算机系课程攻略!
Github | 吴恩达新书《Machine Learning Yearning》
收藏 | 2020年AI、CV、NLP顶会最全时间表!
收藏 | 博士大佬总结的Pycharm 常用快捷键思维导图!
收藏 | 深度学习专项课程精炼图笔记!
笔记 | 手把手教你使用PyTorch从零实现YOLOv3
笔记 | 如何深入理解计算机视觉?(附思维导图)
笔记 | 深度学习综述思维导图(可下载)
笔记 | 深度神经网络综述思维导图(可下载)
总结 | 2019年人工智能+深度学习笔记思维导图汇总

点个在看支持一下吧