热榜标题词云实时更新词云上线,给标题起名提供参观建议
大家好,我是小小明。
想上热榜的童鞋注意了,10分钟更新一次的热榜标题词云出炉,标注当前标题热门,给您的标题起名提供参观建议。链接地址:
http://xxmdmst.top:8000/hotrank/all/
例如当前热门标题为:

没错,就是Java,出现了8次比原本最热的python多出现了3次,说明在官方调整各领域的权重之后,python的热度已经被限制到低于Java。
近期官方给热榜换了新算法,算法规则已经变换莫测扑所迷离,0阅读或者发一堆哈哈哈也能上热榜。导致了如今的热榜已经彻底废掉,希望热榜有修护的一天,而不是变成从此没人愿意再去看的冷榜。
现在新热榜算法不稳定,研究其他指标已经没有啥意义,但新热榜算法对标题的分值权重给的较高,所以研究标题起名,写一个符合算法规则的标题显得至关重要。咱们现在统计好实时的标题词云分布,就能清楚当前算法对标题的价值倾向,就可以针对性起名,从而有更高的概率上热榜。虽然现在上热榜没啥用,但未来热榜如果能够稳定的话还是有用的。
其他功能介绍
本网站不仅能查看标题词云,还能查看热榜和周榜详情:
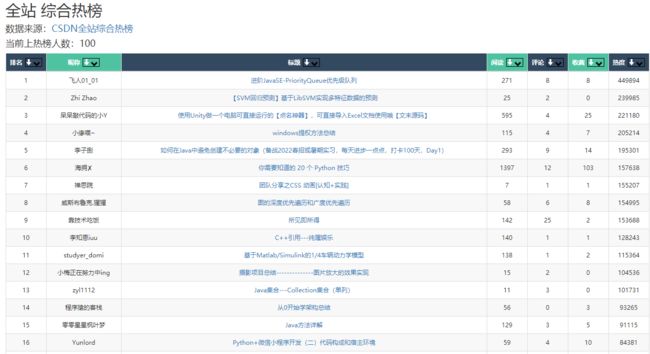
当前表格组件支持搜索和排序,例如,我在昵称搜索组件中输入了一个小字:

就筛选出了昵称中包含小的上热榜的用户,显然当前热榜没有我。
假如我们需要查看出现Java关键字的文章具体是哪几篇,就可以直接在标题搜索框搜索Java:
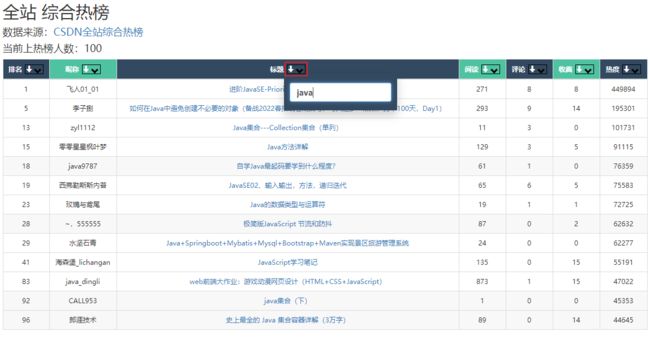
就找出了所以标题含有java的文章。
还可以按阅读量进行降序排列:

可以看到当前热榜阅读量最高的是海拥✘的文章,阅读量为1千多。
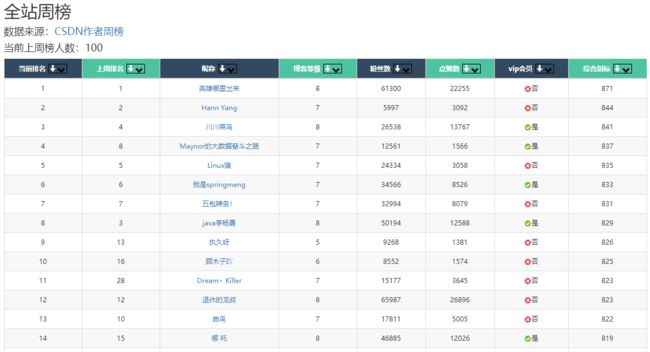
对于周榜,该表格组件也支持同样的操作。
快去http://xxmdmst.top:8000/hotrank/all/体验把。
开发思路
鉴于部分童鞋可能对如何开发的感兴趣,下面公布部分代码。
首先,我们需要一个定时任务去读取当前的热榜,再进行中文切词统计词频后存入数据库,核心代码如下:
for word in words:
jieba.add_word(word)
stopwords = [" ", "的", "和", "是"]
word_count = hot_rank["标题"].str.lower().str.replace("[-—,,、&.()()【】^#::。0-9]", "", regex=True).apply(
lambda s: [word for word in jieba.cut(s) if word not in stopwords]).explode()
word_count = word_count[(word_count.apply(len) > 1) | (word_count == "c")].value_counts().reset_index()
word_count.columns = ["word", "count"]
word_count.index.name = "id"
word_count.to_sql(name='word_count', con=engine, if_exists="replace", index=True, dtype={
"word": VARCHAR(30)})
为了使用django的orm框架读取词频数据,定义一个模型类:
class WordCount(models.Model):
word = models.CharField(max_length=20, blank=True, null=True)
count = models.BigIntegerField(blank=True, null=True)
class Meta:
managed = False
db_table = 'word_count'
django视图渲染页:
context["word_count"] = [{
"name": wc.word, "value": wc.count} for wc in WordCount.objects.all()]
前端页面则使用了echarts渲染图表,大家都能直接查到渲染后的前端源码,针对性修改一下即可得到自己想要的页面。
这就是在线实时词云图开发的完整思路。