这就是神经网络 4:ResNet-V1、ResNet-V2、ReNeXt、SENet
ResNet-V1(2015)
ResNet在ILSVRC 2015分类任务上赢得了第一名。
ResNet在主要是为了解决深度网络的退化问题。退化问题是指,随着网络深度的增加,准确率达到饱和(这可能并不奇怪)然后迅速下降。这并不是由过拟合引起的,因为训练准确率也下降了。
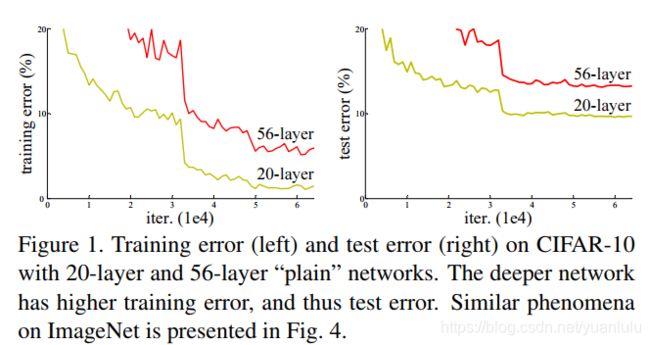
考虑在一个浅层网络上增加恒等映射成为一个更深版本的网络,更深的模型不应当产生比它的浅层版本更高的训练错误率。作者的思路就是产生近似的恒等映射。
作者通过引入深度残差学习框架解决了退化问题。作者推断训练残差比训练原始函数更容易。
如果网络不出现退化,则网络越深,表现越好,至少也应该不比浅层网络差。
假设F(x)是残差函数,H(x)是恒等映射原始函数。则F(x)=H(x)-x,所以H(x)=F(x)+x。
因为H(X)不容易直接训练,咱们转而训练F(x)+x。
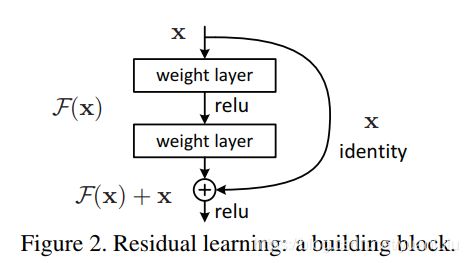
这个模块就相当于一个恒等映射函数H(x)。
下图三个模型分别是VGG、34层原始网络和ResNet34:
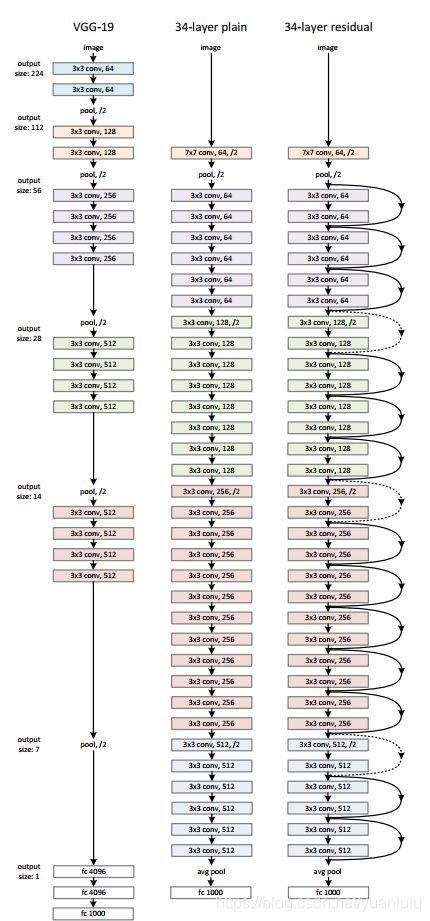
上图: 左:VGG-19模型 (196亿个FLOPs)作为参考。中:plain网络,含有34个参数层(36 亿个FLOPs)。右:残差网络,含有34个参数层(36亿个FLOPs)。
对于维度不变的地方,都是恒等shortcuts,对应实线的,对于尺寸降低、维度提升的地方对应虚线。虚线处无论conv还是shortcuts都是stride为2(降采样)。
要注意到虚线对应的shortcuts前后通道数是不相等的,那怎么做相加的计算呢?
作者列举了A、B、C三种方案:
- (A) 通道变化的时候使用0填充多余的通道,所有的shortcuts是无参数的
- (B) 通道变化的时候使用映射shortcuts(使用1x1卷积调整通道数),其它使用恒等shortcuts;
- © 所有的都是映射shortcuts。
作者做了测试,C方案比B好一点,但是为了减少复杂度和模型尺寸,并不使用选项C的方案。
ResNet还有一系列的变体:

考虑到训练时间的限制,作者在ResNet50和后面的网络中将构建模块改为‘瓶颈’结构,也就是先使用1x1降维,做完3x3卷积,再使用1x1升维,这种两头粗中间细的结构很像‘瓶颈’,故而得名。
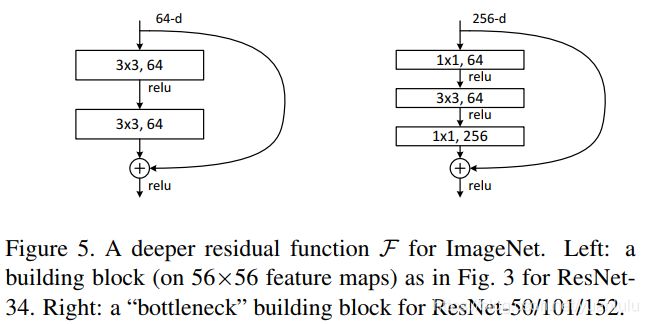
经过测试,ResNet确实解决了退化问题:
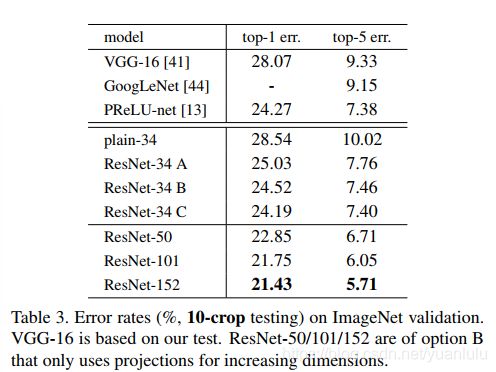
虽然层的深度明显增加了,但是152层ResNet的计算复杂度(113亿个FLOPs)仍然比VGG-16(153 亿个FLOPs)和VGG-19(196亿个FLOPs)的小很多。
ResNet-V2(2016)
在本文中,作者分析了残差块(residual building blocks)背后的计算传播方式,并设计了一个新的残差块结构。原始的RestNet网络在200层左右就会发生过拟合现象,而新的网络在1000层上没有出现过拟合,这说明与原始的ResNet相比,新网络泛化能力更强。
作者认为捷径连接是信息传递最直接的路径。 捷径连接中的操作 (缩放、门控、1××1 的卷积以及 dropout) 会阻碍信息的传递,以致于对优化造成困难。
新老残差块对比及测试如下图:
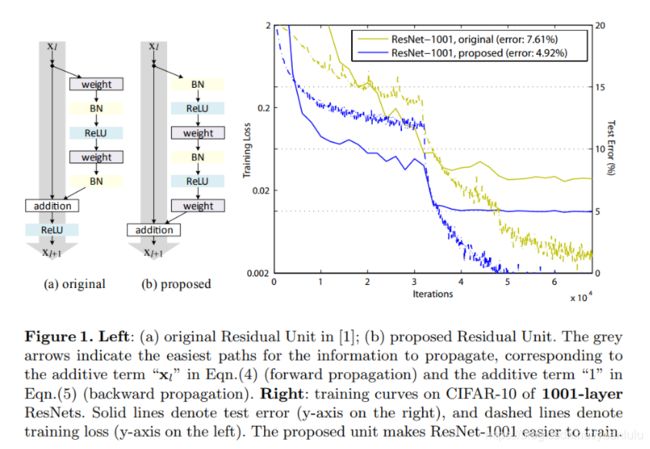
上图a是老的残差块,b是新的残差块。可以看到b的捷径后连没有relu了,反而在权重前面有bn和relu组成的‘预激活’。
从数学角度理解
每个残差单元的正向结果,是之前所有残差函数的输出总和(加上 x_0 ),这表明了任意单元L和l_1之间都具有残差特性。

反向传播时梯度被分解成两个部分:不涉及任何权重层的部分和通过权重层传递的部分。其中第一部分保证了信息能够直接传回任意浅层,不可能出现梯度消失的情况。
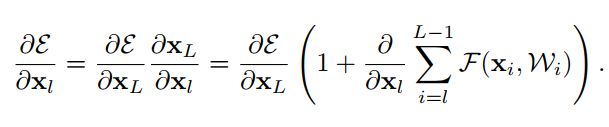
作者用理论和实验证明,在捷径上任何的操作都是多余的,预激活是有效的。
测试结果
单次裁剪的结果对比:

可以可到作者的改进是有明显效果的。
ReNeXt (2016)
ReNeXt是ILSVRC2016分类比赛的亚军。
视觉识别领域的研究正在经历从“特征工程”到“网络工程”的转变。现在研究人员的主要精力转向于设计可以学习到更好的表示的网络架构。
VGG网络的成功说明使用简单但有效的策略(堆叠相同结构的基本构件)也可以构建比较深层的网络,这个策略在ResNet中也得以沿用,ResNet中堆叠的block也都是相同的拓扑结构。简单的设计规则可以减少对超参数的选取。
Inception模型通过精心设计网络的拓扑结构,在保持模型复杂度较低的前提下也取得了很高的准确率。
但是,Inception模型实现起来很麻烦,它包含一系列复杂的超参——每个变换的滤波器的尺寸和数量都需要指定,不同阶段的模块也需要定制。太多的超参数大多的影响因素,如何将Inception模型调整到适合不同的数据集/任务变得很不明晰。
本文同时借鉴VGG/ResNet网络中重复使用同结构模块以及Inception模型的拆分-变换-合并(split-transform-merge)的策略来简明的构建深层网络,具体见图1-right。这样的设计可以随意调整变换的规模。
作者生成了一个新的基础构建模块,和经典残差模块的对比如下:

可以看到在上图右侧,每个ReNeXt模块有两个参数:
- 基数(cardinality),也就是一个ReNeXt模块的通道数,这是本文的重点。
- 每个通道的宽度,上图宽度为4
用作者的表示方法,上图就是一个32x4d的ReNeXt模块,其中32为基数,4为宽度。
下图是ResNet50和ReNeXt50的结构对比,两个网络的参数量及计算量基本一致。

作者探讨了增加深度、宽度和基数的提升表现:
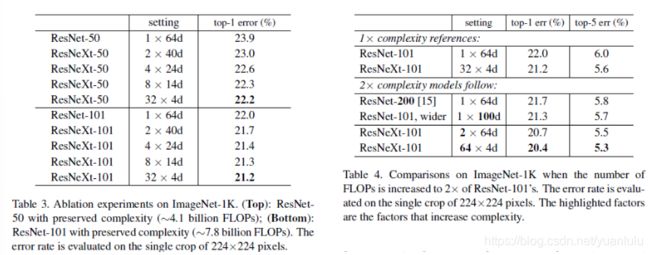
结果显示, 通过增大基数来提升网络能力比深度、宽度更有效。
从表3中可以看出,当bottleneck的宽度很小时,增加基数对模型性能的提升趋于饱和,所以bottleneck宽度的选取一般不小于4d。
和其它优秀网络比较起来,进步很大。
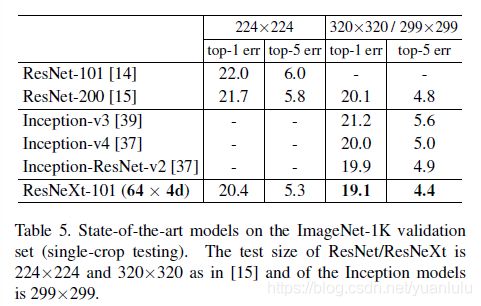
下图可以看到,ReNeXt50基本实现了比ResNet101还好的效果,意味着可以用更少的计算代价实现相同的效果。
SENet (2017)
(本节主要摘抄自《Momenta详解ImageNet 2017夺冠架构SENet》)
SENet以极大的优势获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军。
已经有很多工作在空间维度上来提升网络的性能。那么很自然想到,网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系?我们的工作就是基于这一点并提出了 Squeeze-and-Excitation Networks(简称 SENet)。
那么这个Squeeze-and-Excitation是怎么实现的呢?具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
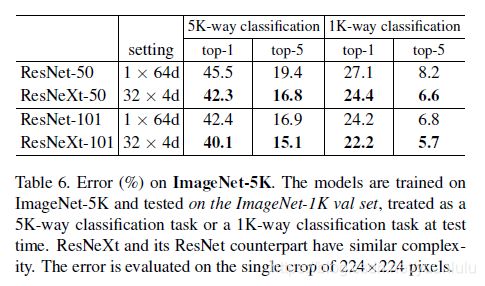
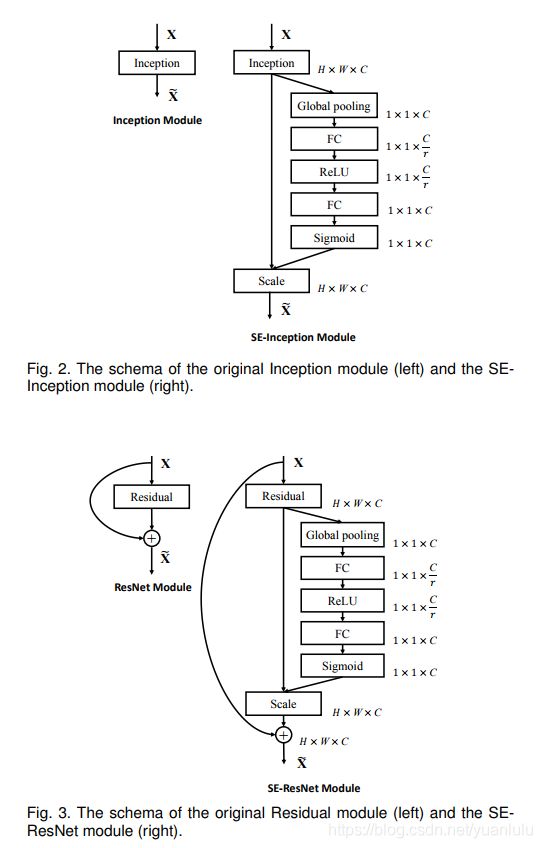
下图就是把SE 嵌入到 ResNet和Inception模块中的例子:
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等。
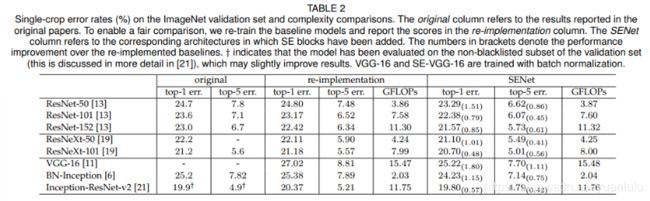
上表表明无论网络的深度如何,SE 模块都能够给网络带来性能上的增益。值得一提的是,SE-ResNet-50 可以达到和 ResNet-101 一样的精度;更甚,SE-ResNet-101 远远地超过了更深的 ResNet-152。
参考资料
精读深度学习论文(5) ResNet V1
Deep Residual Learning for Image Recognition(译)
论文原文:Deep Residual Learning for Image Recognition
精读深度学习论文(6) ResNet V2
ResNet V2原文:Identity Mappings in Deep Residual Networks
Identity Mappings in Deep Residual Networks(译)
精读深度学习论文(7) DenseNet
Densely Connected Convolutional Networks翻译
[DL-架构-ResNet系] 003 ResNeXt
ResNeXt算法详解
ResNeXt论文:Aggregated Residual Transformations for Deep Neural Networks
SENe 论文:Squeeze-and-Excitation Networks
Github:https://github.com/hujie-frank/SENet
Momenta详解ImageNet 2017夺冠架构SENet
SE-Net: 2017 ImageNet 冠军