java面试题(十)
1.
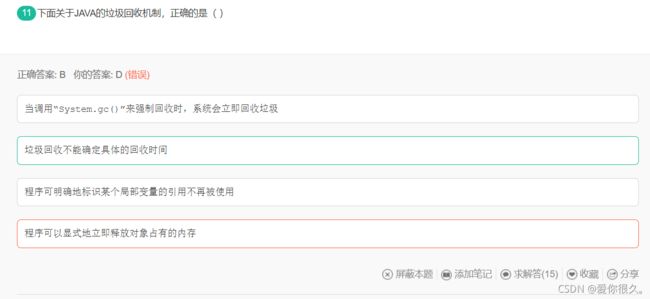
解析:
java提供了一个系统级的线程,即垃圾回收器线程。用来对每一个分配出去的内存空间进行跟踪。当JVM空闲时,自动回收每块可能被回收的内存,GC是完全自动的,不能被强制执行。程序员最多只能用System.gc()来建议执行垃圾回收器回收内存,但是具体的回收时间,是不可知的。当对象的引用变量被赋值为null,可能被当成垃圾。
2.

解析:
通过ServletConfig接口的getInitParameter(java.lang.String name)方法
3.
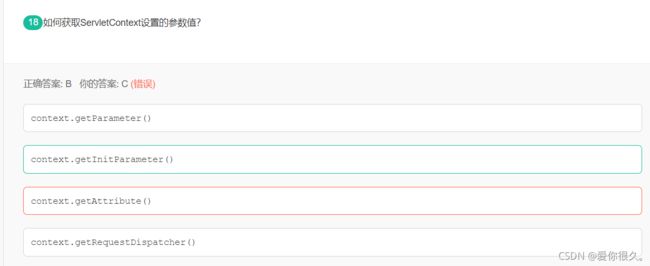
解析:
getParameter()是获取POST/GET传递的参数值;
getInitParameter获取Tomcat的server.xml中设置Context的初始化参数
getAttribute()是获取对象容器中的数据值;
getRequestDispatcher是请求转发。
4.


解析:
Base base=new Son(); 是多态的表示形式。父类对象调用了子类创建了Son对象。
base调用的method()方法就是调用了子类重写的method()方法。
而此时base还是属于Base对象,base调用methodB()时Base对象里没有这个方法,所以编译不通过。
要想调用的话需要先通过SON son=(SON)base;强制转换,然后用son.methodB()调用就可以了。
5.

解析:
在根类Object中包含一下方法:
- clone();
- equals();
- finalize();
- getClass();[align=left][/align]
- notify(),notifyAll();
- hashCode();
- toString();
- wait();
6.
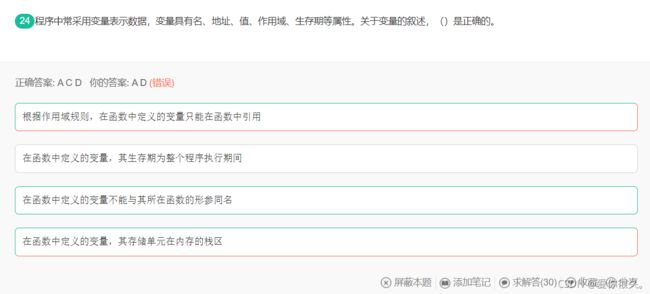
解析:
首先说明栈内存和堆内存里存放的是什么
- 栈内存中存放函数中定义的一些基本类型的变量和对象的引用变量;
- 堆内存中存放new创建的对象和数组。
简单的来说,堆主要是用来存放对象的,栈主要是用来执行程序的
这么做是因为
- 栈的存取速度快,栈数据可以共享,但是栈中的数据大小和生存期必须确定,缺乏灵活性中存放一些基本类型的对象和对象句柄
- 堆是操作系统分配给自己内存,由于从操作系统管理的内存分配,所以再分配和销毁时都需要占用时间,因此用堆的效率非常低,但是优点在于编译器不需要指导从堆里分配多少存储控件,也不需要知道存储的数据要再堆里停留多长事件,因此用堆保存数据时会得到更大的灵活性
7.

解析:
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
8.
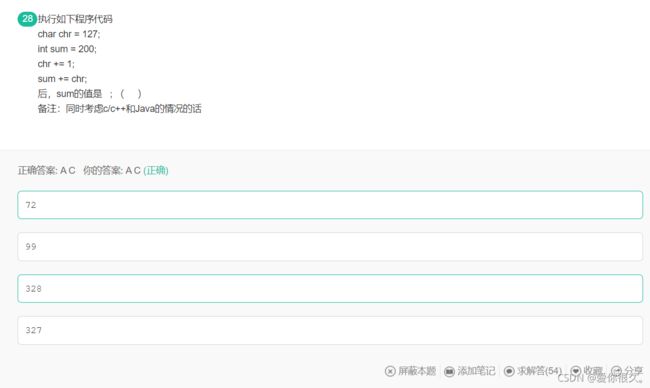
解析:
对于c/c++语言来说:char是一个字节,第一位是符号位,chr在计算机中是补码形式存储,而正数的补码就是原码本身:0111 1111,chr+=1后,chr变为1000 0000,实际上已经溢出了,sum在计算机中存储形式是(假设当前编译器int为16位):0000 0000 1100 1000,接着算sum += chr,sum是16位的而chr是8位的,chr会自动转成16位的,按照按符号位扩展规则,前面补1111 1111,chr变成了1111 1111 1000 0000,于是在计算机内部是0000 0000 1100 1000和1111 1111 1000 0000相加,得到(1)0000 0000 0100 1000 ,第一个1舍去,1001000是72。但是对于我们来说不需要了解那么多,知道补码1000 0000代表-128,200-128=72就完事了。
9.
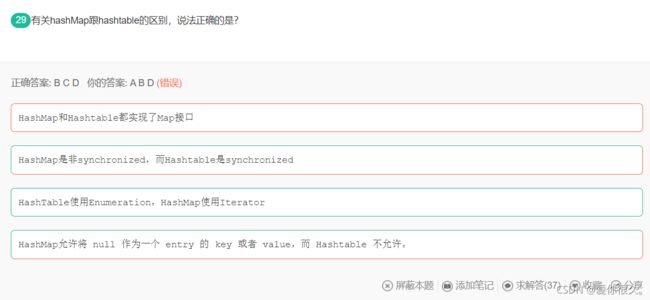
解析:
A正确。Map是一个接口,hashtable,hashmap都是它的实现。
B正确。由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
C正确。 HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
D正确。 哈希值的使用不同,HashTable直接使用对象的hashCode,代码是这样的:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
而HashMap重新计算hash值,而且用与代替求模:
int hash = hash(k);
int i = indexFor(hash, table.length);
10.

解析:
通过阅读源码可以知道,string与stringbuffer都是通过字符数组实现的。
其中string的字符数组是final修饰的,所以字符数组不可以修改。
stringbuffer的字符数组没有final修饰,所以字符数组可以修改。
string与stringbuffer都是final修饰,只是限制他们所存储的引用地址不可修改。
至于地址所指内容能不能修改,则需要看字符数组可不可以修改。