本文译者是360奇舞团前端资深开发工程师
原文标题:What makes WebAssembly fast?
原文作者:Lin Clark
原文地址:https://hacks.mozilla.org/2017/02/what-makes-webassembly-fast/
这是 WebAssembly 文章系列的第五部分。如果你还没有读过其他的,我建议你从头开始。
在上一篇文章,我解释过 WebAssembly 和 JavaScript 这两种技术 并非 不可得兼。我们并不期望开发者们都编写纯粹的 WebAssembly 代码库。
也就是说,开发者们在开发应用程序时,不需要在 WebAssembly 和 JavaScript 之间做选择。但我们希望开发者能够将项目中的部分 JavaScript 代码切换成 WebAssembly 的版本。
例如,React 的开发团队可以将他们的 reconciler 代码(即 Virtual DOM)替换成 WebAssembly 版本。使用 React 的人就什么都不用做 … 他们的应用程序会像之前一样正常运行,并因 WebAssembly 收益。
正因为 WebAssembly 执行更加快速,才能说服 React 团队做出这种转换。但是其执行更加快速的原因是什么呢?
JavaScript 目前的性能如何?
在理解 JavaScript 和 WebAssembly 的性能差异之前,我们需要理解 JS 引擎在做什么。
下面我通过图示粗略描述一下现今应用程序的启动。
JS 引擎 花在每一项任务上的时间 取决于 页面上使用的 JavaScript 代码。图示不是在精确表示性能数据。正相反,图示会提供一个 高阶模型 来对比 JS 和 WebAssembly 完成相同功能 的 不同性能表现。
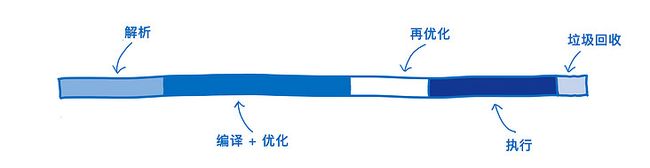
这些横条代表完成特定任务所需的时间。
- 解析 — 源代码被转换成解释器可以运行的东西 花费的时间。
- 编译 + 优化 — 花在 优化编译器 和 基线编译器 上的时间。优化编译器 的某些工作 并不在主线程上做,所以这里没有将这些任务包含进来。
- 再优化(Re-optimizing) — 如果 JIT 发现自己假设(assumption)失败,用于重新调整的时间。这里的调整包括 再优化 和 去优化(将 优化后的代码 回退到 基线代码)。
- 执行 — 用于运行代码的时间。
- 垃圾回收 — 用于清理内存的时间。
这里有一点很重要:这些任务执行并不是完全离散的,也不会遵循特定的顺序。正相反,它们是交错在一起的。做些解析,然后做些编译,接着再解析更多,执行更多,等等。
这样的 工作细分 已经为 JavaScript 带来了巨大的性能提升,早期的 JavaScript 可能类似这样:

早期运行 JavaScript 只依靠 解释器,执行速度是非常慢的。引入 JIT 以后,执行速度得到了非常大的提升。
权衡之后,虽然需要支付监控和编译的开销,但开发者可以在代码不变的情况下,缩短 解析和编译的时间。不过,性能的提升会驱使开发者创建出更大的 JavaScript 应用程序。
这意味着依然有提升的空间。
WebAssembly 对比起来如何?
我估算了一个传统 web 应用程序 使用 WebAssembly 后的对比情况。
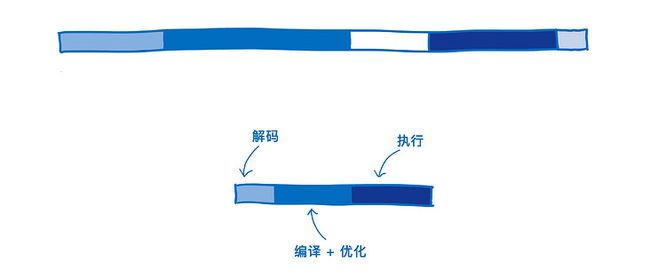
不同的浏览器处理这些阶段可能会有一些轻微的差异。我这里会以 SpiderMonkey 为例。
拉取
这个阶段没有在图示里展示出来,但其实从服务器上拉取文件是很费时间的一件事。
由于 WebAssembly 相比 JavaScript 压缩率更高,拉取就会更快。就算通过压缩算法显著降低 JavaScript 的包大小,也不会比 WebAssembly 压缩后的二进制表示 更小。
这意味着在服务器和客户端之间能够更快的传输。这一点在慢速网络下尤为明显。
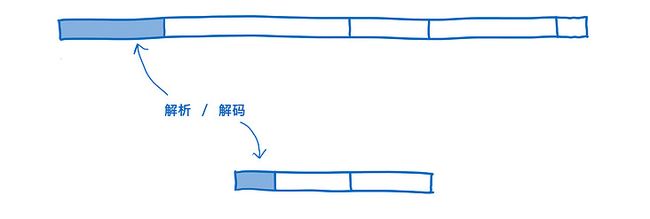
解析
JavaScript 源码被拉取到浏览器后,会被转换成 AST(抽象语法树)。
浏览器总是会惰性执行,只解析那些首要的东西,而对未被调用的函数创建 “桩代码”(stub)。
之后,AST 会被转换成 针对 JS 引擎特化的 IR(被称为 字节码)。
与此相反,WebAssembly 无需这种转换,因为它已经是 IR 了。只需要对它进行 解码 并 校验其中是否存在错误。
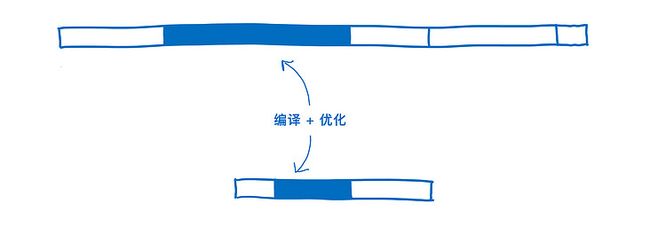
编译 + 优化
我在 JIT 的那篇文章中解释过,JavaScript 会在执行代码的过程中进行编译。依据 运行时 使用的类型,可能需要编译 同一份代码的不同版本。
不同的浏览器在编译 WebAssembly 的方式是不同的。某些浏览器会在开始执行 WebAssembly 之前,先对它做一次 基线编译(baseline compilation),而别的浏览器会使用 JIT。
无论如何,WebAssembly 从一开始就更接近 机器码。以程序中包含的 类型为例。更快的原因是:
- 编译器 在开始编译优化代码之前,无需花费时间执行代码来观测正在使用的类型。
- 编译器 无需基于观测到的不同类型 对同一份代码的不同版本进行编译。
- LLVM 中已经做了另外一些优化。所以减轻了编译和优化代码的工作。
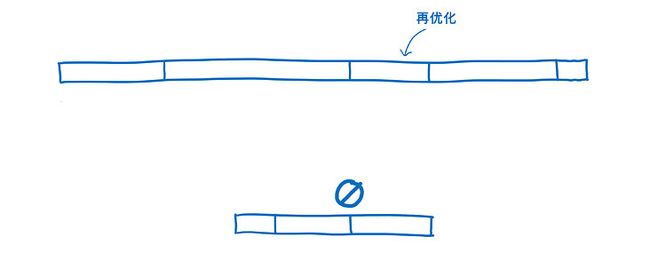
再优化
有时 JIT 不得不丢弃优化版本的代码 并 重新优化。
如果 JIT 基于执行中的代码发现自己的假设是错误的,就会出现这种情况。例如,进入循环的变量在某次迭代中发生改变,或者有函数插入到原型链中时,会发生去优化。
去优化会带来两个代价。第一,放弃优化代码 并 回退到基线版本 需要花费一些时间。第二,如果该函数依然被调用了多次,JIT 可能会选择再次将该函数代码发送到 优化编译器 再次编译,这样的二次编译就是另一个代价。
在 WebAssembly 中,类型这种的东西是很明确的,所以 JIT 不需要基于运行时的数据做出假设。这意味着 WebAssembly 不需要经历 再优化 的循环。
执行
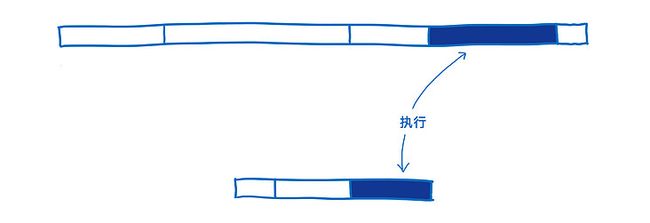
写出高性能的 JavaScript 是可行的。你需要了解 JIT 做出的优化才能做到这一点。例如,你需要了解如何写代码才能让编译器能够特定类型,正如我在 JIT 那篇文章中说的。
然而,大多数开发者不了解 JIT 的内部细节。甚至对于那些了解 JIT 内部细节的开发者,也很难把程序调整到最佳状态。很多帮助代码提升可读性的编程范式(例如,将通用业务抽象成可以跨类型的函数)会阻碍编译器优化代码。
而且,不同浏览器使用 JIT 进行的优化方式是不同的,所以针对一种浏览器的内部细节进行优化可能会让你的代码在另一个浏览器中性能降低。
因此,执行 WebAssembly 代码通常会更快。很多 JIT 对 JavaScript 的优化(就像 类型特定化)对 WebAssembly 不是必要的。
另外,WebAssembly 被设计为一个编译器目标。换句话说,WebAssembly 被设计为了 编译器生成的产物,而不是让人类开发者去编写的。
由于人类程序员不需要直接编写 WebAssembly,WebAssembly 提供了一套对机器更加友好的指令集。基于执行的代码类型,这些指令可以帮助提速 10% 到 800%。
垃圾回收
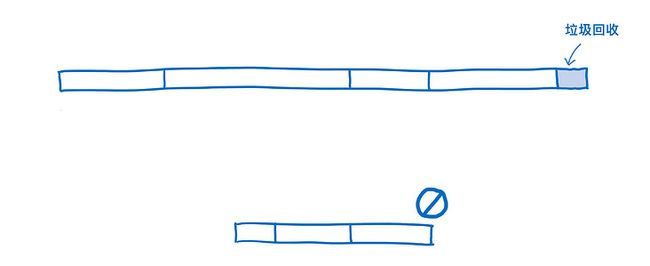
在 JavaScript,开发者不用关心从内存中清理那些不需要的老变量。而 JS 引擎会自动使用 垃圾回收器 处理这件事。
如果你想拥有可预测的性能,那可能会很难。你无法控制垃圾回收器的工作,所以它有可能会在不适合的时候开始工作。大多数浏览器都能很好的安排清理任务,但 垃圾回收 对于代码执行依然是一笔开销。
至少在现在,WebAssembly 还完全不支持垃圾回收。内存是手动管理的(比如 C 和 C++ )。尽管这会使得开发者更难开发,但也让程序的性能变得更加稳定了。
总结
WebAssembly 由于下列因素执行更快:
- 拉取 WebAssembly 更节省时间。因为 WebAssembly 相比于 JavaScript 压缩率更高。
- WebAssembly 解码 相比 解析 JavaScript 耗时更少。
- 编译和优化时间更短。因为 WebAssembly 相比 JavaScript 更贴近 机器码,而且 WebAssembly 在服务端已经做过了优化。
- 再优化 不再会发生。由于 WebAssembly 在编译时就已经内置了 类型等信息,所以 JS 引擎无需像对待 JavaScript 一样,在优化时推测类型。
- 更短的执行时间。因为开发者不需要为了更稳定的性能,去了解使用一些 有关编译器的 奇技淫巧,而且 WebAssembly 的指令集对机器更友好。
- 不依赖垃圾回收。因为内存是手动管理的。
这就是我所认为的,WebAssembly 在做同一任务时 优于 JavaScript 的地方。
在某些情况下,WebAssembly 会无法发挥预期性能。另外,WebAssembly 还有一些即将发生的改动,它会因此变得更快。我会在下篇文章中聊聊这几点。