深度学习(一)Keras环境搭建与mnist
本文代码仓库https://github.com/MachinePlay/Keras-toturial 包含.py 代码和Jupyter Notebook的.ipynb文件
Keras
Keras是一个高度封装的python深度学习库,以TensorFlow或Thano为后端
最近打算重新系统的学习深度学习,于是就从使用Keras开始从零撸神经网络
Keras 具有以下重要特性。
- 相同的代码可以在 CPU 或 GPU 上无缝切换运行。
- 具有用户友好的 API,便于快速开发深度学习模型的原型。
- 内置支持卷积网络(用于计算机视觉)、循环网络(用于序列处理)以及二者的任意
组合。 - 支持任意网络架构:多输入或多输出模型、层共享、模型共享等。这也就是说,Keras
- 能够构建任意深度学习模型,无论是生成式对抗网络还是神经图灵机。
Keras 已有 200 000 多个用户,既包括创业公司和大公司的学术研究人员和工程师,也包括 研究生和业余爱好者。Google、Netflix、Uber、CERN、Yelp、Square 以及上百家创业公司都在 用 Keras 解决各种各样的问题。Keras 还是机器学习竞赛网站 Kaggle 上的热门框架,最新的深度学习竞赛中,几乎所有的优胜者用的都是 Keras 模型
Keras、TensorFlow、Theano 和 CNTK
Keras 是一个模型级(model-level)的库,为开发深度学习模型提供了高层次的构建模块。 它不处理张量操作、求微分等低层次的运算。相反,它依赖于一个专门的、高度优化的张量库 来完成这些运算,这个张量库就是 Keras 的后端引擎(backend engine)。Keras 没有选择单个张 量库并将 Keras 实现与这个库绑定,而是以模块化的方式处理这个问题
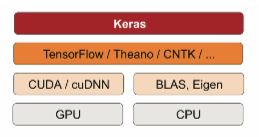
因此,几 个不同的后端引擎都可以无缝嵌入到 Keras 中。目前,Keras 有三个后端实现:TensorFlow 后端、 Theano 后端和微软认知工具包(CNTK,Microsoft cognitive toolkit)后端。
配置要求
本文使用Ubuntu18.04 搭载Nvidia GTX 1080Ti显卡,windows+cpu也行。
在开始开发深度学习应用之前,你需要建立自己的深度学习工作站。虽然并非绝对必要,但强烈推荐你在现代 NVIDIA GPU 上运行深度学习实验。某些应用,特别是卷积神经网络的图 像处理和循环神经网络的序列处理,在 CPU 上的速度非常之慢,即使是高速多核 CPU 也是如此。 即使是可以在 CPU 上运行的深度学习应用,使用现代 GPU 通常也可以将速度提高 5 倍或 10 倍。 如果你不想在计算机上安装 GPU,也可以考虑在 AWS EC2 GPU 实例或 Google 云平台上运行深 度学习实验。但请注意,时间一长,云端 GPU 实例可能会变得非常昂贵。
无论在本地还是在云端运行,最好都使用 UNIX 工作站。虽然从技术上来说可以在 Windows 上 使 用 K e r a s ( K e r a s 的 三 个 后 端 都 支 持 W i n d o w s ), 但 我 们 不 建 议 这 么 做 。
环境搭建
python环境建议使用anaconda安装,anaconda安装教程可以参考我的Anaconda简单入门
Keras以TensorFlow为后端,所以要先安装Tensorflow
1.安装显卡驱动 (安装cpu版本跳至步骤2)
可以先安装显卡驱动(只安驱动就可以,不用像其他教程那样再安装cuda和cudnn)windows显卡驱动安装还请自行解决 本文主要以ubuntu 18.04讲解
- .首先卸载旧版本显卡驱动:
$sudo apt-get purge --remove nvidia* 命令卸载旧版本
- 添加驱动源
$sudo add-apt-repository ppa:graphics-drivers/ppa
$sudo apt update
- 安装驱动
首先,检测你的NVIDIA图形卡和推荐的驱动程序的模型。执行命令:
ubuntu-drivers devices
输出结果为:
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
modalias : pci:v000010DEd00001B81sv000019DAsd00001434bc03sc00i00
vendor : NVIDIA Corporation
model : GP102 [GeForce GTX 1080 Ti]
driver : nvidia-driver-396 - third-party free
driver : nvidia-driver-390 - third-party free
driver : nvidia-driver-415 - third-party free recommended
driver : nvidia-driver-410 - third-party free
driver : xserver-xorg-video-nouveau - distro free builtin
从中可以看到,这里有一个设备是GTX 1080 Ti ,对应的驱动是nvidia-driver-396,415,410 ,而推荐是安装415版本的驱动
$sudo apt install nvidia-driver-415 安最新的就行
2安装TensorFlow
anaconda创建一个新环境(或者用旧环境 例如我的环境叫tf3.6)
conda create -n tf3.6(名字随便起) python =3.6# 指定使用python3.6版本
- 如果有Nvidia显卡并装好驱动,可安装GPU版TensorFlow
在新环境(tf3.6)中
conda install tensorflow-gpu=1.12 #不指定版本号可以安装最新的 目前最新的是1.12
conda会自动把需要的numpy、scikit、cuda、cudnn装在新环境里
- 没有Nvidia显卡 安装cpu版TensorFlow
conda install tensorflow
在Terminal输入
python
>>> import tensorflow as tf
如下图不报错就是Tensorflow安装成功了
3 安装Keras和Jupyter notebook
conda install keras
conda install jupyter notebook
jupyter notebook是可以通过浏览器写python代码的一个小工具,非常好用
在终端输入
jupyter notebook
即可开启notebook服务,复制滚出的地址在浏览器打开,点击左上角New一个python3 notebook就可以在网页写代码和运行啦

编辑界面
还可以开启远程访问、终端访问等功能可以参考我的 Jupyter Notebook 远程访问配置一文
Keras MNIST启动~

我们这里要解决的问题是,将手写数字的灰度图像(28 像素×28 像素)划分到 10 个类别 中(0~9)。我们将使用 MNIST 数据集,它是机器学习领域的一个经典数据集,其历史几乎和这 个领域一样长,而且已被人们深入研究。
这个数据集包含 60 000 张训练图像和 10 000 张测试图 像,由美国国家标准与技术研究院(National Institute of Standards and Technology,即 MNIST 中 的 NIST)在 20 世纪 80 年代收集得到。你可以将“解决”MNIST 问题看作深度学习的“Hello World”,正是用它来验证你的算法是否按预期运行。当你成为机器学习从业者后,会发现 MNIST 一次又一次地出现在科学论文、博客文章等中。
首先加载keras自带的mnist数据集
from keras.datasets import mnist
- 自带的mnist第一次需要下载,返回两个元组对象,每个元组里是两个numpy数组,我们把它拆分成四个numpy数组数据集
(train_images,train_labels),(test_images,test_labels)=mnist.load_data()
- 我们可以看看他们的形状
print(train_images.shape,train_labels.shape,test_images.shape,test_labels.shape)

接下来的工作流程
- 首先将训练数据 train_images、train_labels、测试数据test_images,test_labels转化成网络要求的数据格式(由灰度(0,255)转换为[0,1]之间的数据
- 其次设计网络模型 选择优化器、损失函数和监控指标
- 最后使用我们训练好的模型对test_image进行预测
神经网络的核心组件是层(layer),它是一种数据处理模块,你可以将它看成数据过滤器。 进去一些数据,出来的数据变得更加有用。具体来说,层从输入数据中提取表示——我们期望 这种表示有助于解决手头的问题。大多数深度学习都是将简单的层链接起来,从而实现渐进式 的数据蒸馏(data distillation)。深度学习模型就像是数据处理的筛子,包含一系列越来越精细的 数据过滤器(即层)。
定义网络
本例中的网络包含 2 个 Dense 层,它们是密集连接(也叫全连接)的神经层。第二层(也 是最后一层)是一个 10 路 softmax 层,它将返回一个由 10 个概率值(总和为 1)组成的数组。 每个概率值表示当前数字图像属于 10 个数字类别中某一个的概率
#首先我们导入keras的神经网络模型包models和层包layer
from keras import models
from keras import layers
#定义一个网络的模型对象firstnet
firstnet=models.Sequential()
#Sequential模型代表我们的模型网络是按层顺序叠加的
#为网络添加第一层
#创建一个Dense(全联接层) 使用激活函数为relu函数,输入n个28*28维的向量(1个2D张量),激活后输出n个512维的向量
firstnet.add(layers.Dense(512,activation='relu',input_shape=(28*28,)))
#第二层 softmax层
firstnet.add(layers.Dense(10,activation='softmax'))
要想训练网络,我们还需要选择编译(compile)步骤的三个参数。
- 损失函数(loss function):网络如何衡量在训练数据上的性能,即网络如何朝着正确的
方向前进。 - 优化器(optimizer):基于训练数据和损失函数来更新网络的机制。
- 在训练和测试过程中需要监控的指标(metric):本例只关心精度,即正确分类的图像所占的比例。
#编译阶段 使用rmsprop优化器,交叉熵作为损失函数,监控指标为准确度accuracy
firstnet.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
数据处理
我们的数据格式与编写的网络不同,网络要求为n个2828维的向量(2D张量),我们的是3D张量(60000,28,28)需要修改成(60000,2828)
并且将[0,255]的灰度范围映射到[0,1],并把数据类型由uint更改为float32
在开始训练之前,我们将对数据进行预处理,将其变换为网络要求的形状,并缩放到所 有值都在 [0, 1] 区间。比如,之前训练图像保存在一个 uint8 类型的数组中,其形状为 (60000, 28, 28),取值区间为[0, 255]。我们需要将其变换为一个float32数组,其形 状为 (60000, 28 * 28),取值范围为 0~1。
train_images=train_images.reshape(60000,28*28)
train_images=train_images.astype('float32')/255
test_images=test_images.reshape(10000,28*28)
test_images=test_images.astype('float32')/255
#我们还需要对标签进行分类编码,未来将会对这一步骤进行解释。
from keras.utils import to_categorical
train_labels=to_categorical(train_labels)
test_labels=to_categorical(test_labels)
训练网络
现在我们准备开始训练网络,在 Keras 中这一步是通过调用网络的 fit 方法来完成的—— 我们在训练数据上拟合(fit)模型。
我们规定Batch_size=128 即每次迭代训练读取128个样本
5个epochs,指把整个数据集训练五遍
firstnet.fit(train_images,train_labels,epochs=5,batch_size=128)
可以看到由于数据集、网络规模较小,设备性能较强,训练很快
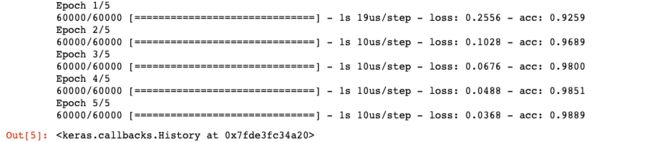
训练过程中显示了两个数字:一个是网络在训练数据上的损失(loss),另一个是网络在 训练数据上的精度(acc)。
我们很快就在训练数据上达到了 0.989(98.9%)的精度。现在我们来检查一下模型在测试 集上的性能。
test_loss,test_acc=firstnet.evaluate(test_images,test_labels)
print('test_loss: ',test_loss,'test_acc: ',test_acc)

- 测试集精度为 97.8%,比训练集精度低不少。训练精度和测试精度之间的这种差距是过拟 合(overfit)造成的。过拟合是指机器学习模型在新数据上的性能往往比在训练数据上要差,它 是第 3 章的核心主题。
- 第一个例子到这里就结束了。你刚刚看到了如何构建和训练一个神经网络,用不到 20 行的 Python 代码对手写数字进行分类
- 接下来详细介绍这个例子中的每一个步骤,并讲解其背后 的原理。接下来你将要学到张量(输入网络的数据存储对象)、张量运算(层的组成要素)和梯 6 度下降(可以让网络从训练样本中进行学习)。
参考文献
[1] Python深度学习,(美)弗朗索瓦·肖莱,人民邮电出版社,2018,8