一、数组的基本用法
1.什么是数组
数组本质上就是让我们能 “批量” 创建相同类型的变量。
如果我们需要创建多个同一个类型的变量,则不可能手动一个接一个地创建,如:int n=10; int m =20;int y = 30;等等,因此数组能帮我们批量创建同一个类型的数据。
注意事项: 在 Java 中, 数组中包含的变量必须是相同类型。
2.创建数组
基本语法:
// 动态初始化
数据类型[] 数组名称 = new 数据类型 [] { 初始化数据 };
// 静态初始化
数据类型[] 数组名称 = { 初始化数据 };
//不初始化
数据类型[] 数组名称 = new 数据类型[需要创建的数组长度];
代码示例:
int[] arr = new int[]{1, 2, 3};
int[] arr = {1, 2, 3};
int[] arr = new int[3];
注意事项: 静态初始化的时候, 数组元素个数和初始化数据的格式是一致的。
虽然我们也可以使用:int arr[] = {1, 2, 3}; ,但是还是更推荐写成 int[] arr 的形式,int和 [] 是一个整体。
3.数组的使用
int[] arr = {1, 2, 3};
// 获取数组长度
System.out.println("length: " + arr.length); // 执行结果: 3
// 访问数组中的元素
System.out.println(arr[1]); // 执行结果: 2
System.out.println(arr[0]); // 执行结果: 1
arr[2] = 100;
System.out.println(arr[2]); // 执行结果: 100
1.使用 arr.length 能够获取到数组的长度,. 这个操作为成员访问操作符. 后面在面向对象中会经常用到。
2.使用 [ ] 按下标取数组元素. 需要注意, 下标从 0 开始计数。
3.使用 [ ] 操作既能读取数据, 也能修改数据。
4.下标访问操作不能超出有效范围 [0, length - 1] , 如果超出有效范围, 会出现下标越界异常。
代码示例: 下标越界
int[] arr = {1, 2, 3};
System.out.println(arr[100]);
// 执行结果
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 100 at Test.main(Test.java:4)
抛出了 java.lang.ArrayIndexOutOfBoundsException 异常,使用数组一定要下标谨防越界。
代码示例:遍历数组
所谓 “遍历” 是指将数组中的所有元素都访问一遍, 不重不漏,通常需要搭配循环语句。
int[] arr = {1, 2, 3}; for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]);
}
// 执行结果
1
2
3
代码示例: 使用 for-each 遍历数组
int[] arr = {1, 2, 3};
for (int x : arr) {
System.out.println(x);
}
// 执行结果
1
2
3
for-each 是 for 循环的另外一种使用方式,能够更方便的完成对数组的遍历,可以避免循环条件和更新语句写错。
for-each的另一种使用方式,它只能遍历数组的所有数据,遍历时x能读取数组中的对应下标中的数据。
代码示例:
int[] arr={1,2,3,4,2};
int count = 0 ;
for (int x:arr) {
if(x==2) {
count++;
}
}
System.out.println(count);//结果为2
二、数据作为方法参数
1.基本用法
代码示例: 打印数组内容
public static void main(String[] args) {
int[] arr = {1, 2, 3};
printArray(arr);
}
public static void printArray(int[] a) {
for (int x : a) {
System.out.println(x);
}
}
// 执行结果
1
2
3
注意:
1.int[] a 是函数的形参, int[] arr 是函数实参。
2.如果需要获取到数组长度, 同样可以使用 a.length 。
2.理解引用类型
代码示例1 参数传内置类型
public static void main(String[] args) {
int num = 0;
func(num);
System.out.println("num = " + num);
}
public static void func(int x) {
x = 10;
System.out.println("x = " + x);
}
// 执行结果
x = 10
num = 0
代码示例2 参数传数组类型
public static void main(String[] args) {
int[] arr = {1, 2, 3};
func(arr);
System.out.println("arr[0] = " + arr[0]);
}
public static void func(int[] a) {
a[0] = 10;
System.out.println("a[0] = " + a[0]);
}
// 执行结果
a[0] = 10
arr[0] = 10
我们发现, 在方法内部修改数组内容, 方法外部也发生改变.
此时数组名 arr 是一个 “引用” , 当传参的时候, 是按照引用传参,引用类型类似于C语言中的指针,但却有许多地方不同。
引用可以理解为:创建一个引用只是相当于创建了一个很小的变量, 这个变量保存了一个整数, 这个整数表示内存中的一个地址。
针对 int[] arr = new int[]{1, 2, 3} 这样的代码, 内存布局如图:
当我们创建 new int[]{1, 2, 3} 的时候, 相当于创建了一块内存空间保存三个 int。接下来执行 int[] arr = new int[]{1, 2, 3} 相当于又创建了一个 int[] 变量, 这个变量是一个引用类型, 里面只保存了一个整数(数组的起始内存地址)
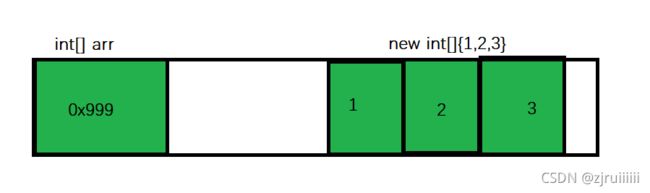
3.接下来传参相当于 int[] a = arr , 内存布局如图:

4. 接下来我们修改 a[0] , 此时是根据 0x100 这样的地址找到对应的内存位置, 将值改成 100 。内存布局如图:

正是因为int[] arr与int[] a指向的内存空间都为在arr创建时的新的对象(三个整型数据),因此虽然其中一个数据改了,但是arr与a指向的空间不变,因此arr与a都会随着对象的改变而改变,这就是引用。
总结: 所谓的 “引用” 本质上只是存了一个地址,Java 将数组设定成引用类型, 这样的话后续进行数组参数传参, 其实只是将数组的地址传入到函数形参中,这样可以避免对整个数组的拷贝(数组可能比较长, 那么拷贝开销就会很大)
3.认识null
null 在 Java 中表示 “空引用” , 也就是一个无效的引用。
代码示例:
int[] arr = null;
System.out.println(arr[0]);
// 执行结果
Exception in thread “main” java.lang.NullPointerException at Test.main(Test.java:6)
null 的作用类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置。 因此不能对这个内存进行任何读写操作, 一旦尝试读写, 就会抛出 NullPointerException.
注:Java 中并没有约定 null 和 0 号地址的内存有任何关联。即使是打印,打印的结果也为null。
4.JVM内存区域划分
在一开始学Java时我们就知道JVM的全称是Java虚拟机,它能够运行Java编译后的字节码文件,实际上运行时它也要开辟栈帧、堆内分配内存等等,因此就有了JVM的内存布局。
JVM内存布局大概可以分为六个区域:程序计数器、JVM虚拟机栈、JVM本地方法栈、方法区、堆区及运行时常量池。它们之间的内存布局:
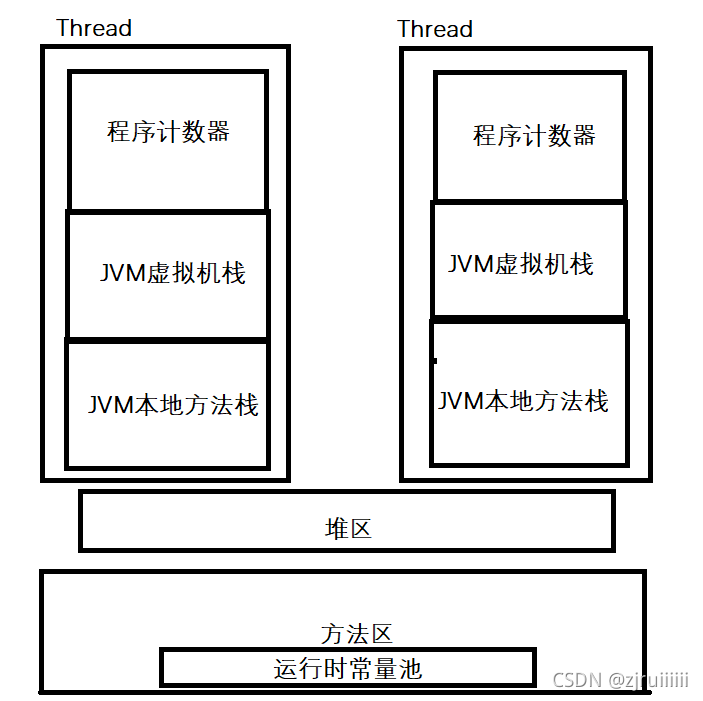
- 程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址
- 虚拟机栈(JVM Stack): 重点是存储局部变量表(当然也有其他信息),我们刚才创建的 int[] arr 这样的存储地址的引用就是在这里保存。
- 本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似,只不过保存的内容是Native方法的局部变量,native方法的运行速度是非常快的,在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的。
- 堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2, 3} )
- 方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,方法编译出的的字节码就是保存在这个区域。
- 运行时常量池(Runtime Constant Pool): 是方法区的一部分, 存放字面量(字符串常量)与符号引用(注意 从 JDK1.7 开始, 运行时常量池在堆上)
Native 方法:
JVM 是一个基于 C++ 实现的程序. 在 Java 程序执行过程中, 本质上也需要调用 C++ 提供的一些函数进行和操作系统底层进行一些交互. 因此在 Java 开发中也会调用到一些 C++ 实现的函数。
这里的 Native 方法就是指这些 C++ 实现的, 再由 Java 来调用的函数。
此处对JVM的内存布局只做了解,重点掌握JVM虚拟机栈中存的是什么,而堆上存的额又是什么即可。
局部变量和引用保存在栈上, new 出的对象保存在堆上.
堆的空间非常大, 栈的空间比较小.
堆是整个 JVM 共享一个, 而栈每个线程具有一份(一个 Java 程序中可能存在多个栈).
5.数组作为方法的返回值
代码示例: 写一个方法, 将数组中的每个元素都 * 2
// 直接修改原数组
class Test {
public static void main(String[] args) {
int[] arr = {1, 2, 3};
transform(arr);
printArray(arr);
}
public static void printArray(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
public static void transform(int[] arr) {
for (int i = 0; i < arr.length; i++) {
arr[i] = arr[i] * 2;
}
}
}
这个代码固然可行, 但是破坏了原有数组. 有时候我们不希望破坏原数组, 就需要在方法内部创建一个新的数组, 并由方法返回出来。在Java中方法可以返回一个数组。
// 返回一个新的数组 class Test {
public static void main(String[] args) {
int[] arr = {1, 2, 3};
int[] output = transform(arr);
printArray(output);
}
public static void printArray(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
public static int[] transform(int[] arr) {
int[] ret = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
ret[i] = arr[i] * 2;
}
return ret;
}
}
这样的话就不会破坏原有数组了。
另外由于数组是引用类型, 返回的时候只是将这个数组的首地址返回给函数调用者, 没有拷贝数组内容, 从而比较高效。
6.关于数组的地址
在Java中,为了维护数据的安全,我们是拿不了数组的地址的(已经被特殊处理过)。若想打印数组的地址,我们会发现结果如下:
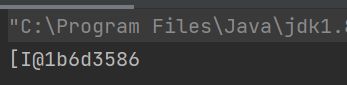
为什么打印结果会如此呢?
我们进入println的源代码中可以看到println中有一个方法是专门对地址进行特殊处理:

它是根据哈希来对数组地址进行处理的,虽然如此,但是数组的地址仍然是只有唯一的一个。
四、数组练习
1.数组转字符串
代码示例:
import java.util.Arrays
int[] arr = {1,2,3,4,5,6};
String newArr = Arrays.toString(arr);
System.out.println(newArr);
// 执行结果
[1, 2, 3, 4, 5, 6]
使用这个方法后续打印数组就更方便一些。
Java 中提供了 java.util.Arrays 包, 其中包含了一些操作数组的常用方法。
2.数组拷贝
代码示例:
import java.util.Arrays
int[] arr = {1,2,3,4,5,6};
int[] newArr = Arrays.copyOf(arr, arr.length);
System.out.println("newArr: " + Arrays.toString(newArr));
arr[0] = 10;
System.out.println("arr: " + Arrays.toString(arr)); System.out.println("newArr: " + Arrays.toString(newArr));
// 拷贝某个范围.
int[] newArr = Arrays.copyOfRange(arr, 2, 4);
System.out.println("newArr2: " + Arrays.toString(newArr2));
注意事项: 相比于 newArr = arr 这样的赋值, copyOf 是将数组进行了 深拷贝, 即又创建了一个数组对象, 拷贝原有数组中的所有元素到新数组中. 因此, 修改原数组, 不会影响到新数组。而浅拷贝则是拷贝时原数组。
其实拷贝数组的方法有4种。
1.for循环进行一个接一个地拷贝
2.Arrays.copyOf ,调用Arrays包中的类来实现
3.System.arraycopy ,能够设置从什么位置处开始拷贝到什么位置结束(拷贝的速度最快)
4.数组名.clone()
虽然这四种拷贝数组的方法都是有了深拷贝具备的特点(拷贝到新数组中,改变新数组内的数据,原数组不会改变)。但是它们处理的都是简单类型,面试时都回答它们是浅拷贝即可。
代码示例:
for循环拷贝:
int[] arr={1,2,3,4};
int[] a=new int[4];
for(int i=0;i
System.arraycopy拷贝:
int[] arr={1,2,3,4};
int[] a=new int[arr.length];
System.arraycopy(arr,0,a,0,arr.length);
System.out.println(Arrays.toString(a));
数组名.clone拷贝:
int[] arr={1,2,3,4};
int[] a=new int[arr.length];
a=arr.clone();
System.out.println(Arrays.toString(a));
五、二维数组
1.二维数组的语法
二维数组本质上也就是一维数组, 只不过每个元素又是一个一维数组。
基本语法:
数据类型[][] 数组名称 = new 数据类型 [行数][列数] { 初始化数据 };
代码示例:
int[][] arr = { {1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12} };
for (int row = 0; row < arr.length; row++) {
for (int col = 0; col < arr[row].length; col++) {
System.out.printf("%d\t", arr[row][col]);
}
System.out.println("");
}
// 执行结果
1 2 3
4 5 6
7 8 9
10 11 12
注意:Java中二维数组只能省略列,不能省略行,否则编译器会报错。
二维数组可以自定义,那么如何自定义呢?
代码示例:
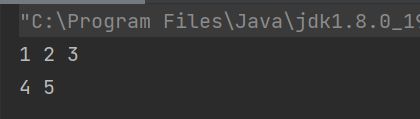
int[][] arr=new int[2][];
arr[0]=new int[]{1,2,3};
arr[1]=new int[]{4,5};
for (int[] a:arr) {
for (int x:a) {
System.out.print(x+" ");
}
System.out.println();
}
运行结果:
2.二维数组的结构
此处我们针对数组int[2][3]进行结构分析,同样,在创建新的二维数组的对象时它们存储在堆区,而数组名(变量)是引用,存放在栈区。
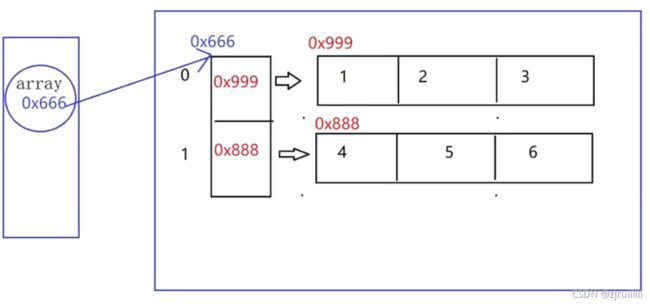
注意:在Java中要取到二维数组的行号,它实际上也是一个一维数组,因此上面的打印二维数组的代码中取行号的方式是arr.length,正是行号是一个一维数组,因此要取二维数组的每一列的方式是arr[row].length。
3.用for-each遍历二维数组
若要用foreach遍历二维数组:
代码示例:
int[][] arr={{1,2,3},{2,3,4}};
for (int[] tmp:arr) {
for (int x:tmp) {
System.out.print(x+" ");
}
System.out.println();
}
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!