深度学习网络结构大全
1 Lenet
7层:卷积+下采样+卷积+下采样+全连接+全连接+全连接
可以很好的进行数字识别
第一次运用卷积神经网络
参考:(39条消息) 详解深度学习之经典网络架构(一):LeNet_chenyuping333的博客-CSDN博客_lenet网络结构详解
https://blog.csdn.net/chenyuping333/article/details/82177677
1 Alexnet
5层卷积+3层全连接


参考:
(39条消息) 图像识别-AlexNet网络结构详解_算法之美-CSDN博客_alexnet网络结构详解
https://blog.csdn.net/weixin_44222014/article/details/106250687
3 VGG16
13个卷积层+3个全连接层
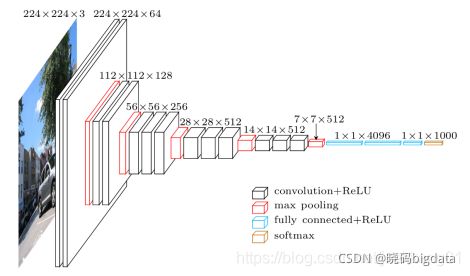

4 GoogleNet模块化的开端
(1) 最终的架构包含了这些叠在一起的初始模块的多个。甚至在GoogleNet中,训练也略有不同,因为大多数最顶层都有自己的输出层。这种细微差别有助于模型更快地收敛,因为对于层本身有联合训练和并行训练。
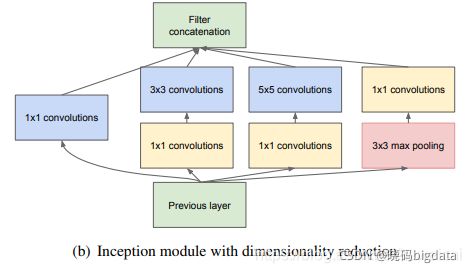
(2) 在 GoogLeNet 上开始出现了分支,而不是一条线连到底,这是最直观的差异,也被称作 Inception module,如下图所示。从图中可以看到, 每个 module 中采用了不同 size 的 kernel,然后在将特征图叠加(用的是通道维度的结合,不是相加),实际上起到了一个图像金字塔的作用,即 所谓的 multiple resolution。
(3) 有很多 1x1 的卷积核,这里的1x1的卷积操作与之前讲到是不一样的,这里利用它来改变 output 的 channel, 具体说这里是减少 channel 数,从而达到减少计算的目的。
(4) 用 Global Ave Pool 取代 FC。下图可以看到,对于 FC ,超参数的个数为 7x7x1024x1024=51.3M,但是换成 Ave Pool之后,超参数变为0,所以这里可以起到防止过拟合的作用,另外作者发现采用 Ave Pool 之后,top-1的精度提高了大概0.6%。但是需要注意的是,在 GoogLeNet 中并没有完全取代 FC。
(5) 采用了辅助分类器。整个模型有三个 output(之前的网络都只有一个 output),这里的多个 output 仅仅在训练的时候用,也就是说测试或者部署的时候仅仅用最后一个输出。在训练的时候,将三个输出的loss进行加权平均,weight=0.3, 通过这种方式可以缓解梯度消失,同时作者也表示有正则化的作用。其实这个思想有点类似于传统机器学习中的投票机制,最终的结果由多个决策器共同投票决定,这个在传统机器学习中往往能提升大概2%的精度。
[1] (39条消息) 深度学习中的经典基础网络结构(backbone)总结_生命在于折腾!-CSDN博客_backbone网络
https://blog.csdn.net/kuweicai/article/details/102789420?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_v2~rank_aggregation-4-102789420.pc_agg_rank_aggregation&utm_term=%E7%BB%8F%E5%85%B8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93&spm=1000.2123.3001.4430
5 Resnet
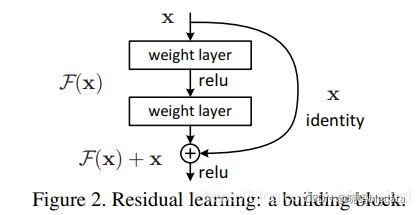
(1) 我们之前提 ResNet 将深度学习推到了新的高度,因为它首次将错误率降到比人类还低的水平,网络深度甚至达到1202层,所以它具有里程碑式的意义。文章中作者提出了多种不同深度的结构,其中50,101和152层的网络后来用的比较多。
(2) ResNet 的核心思想是采用了 identity shortcut connection。前面我们提到,已经得出了结论,加深网络深度有助于提高模型精度,那什么不直接干到几千几万层?这里的原因很多,抛开计算资源和数据集的原因,还有一个很重要的原因是梯度消失。在最开始,比如在 LeNet 那个年代,也就几层网络,当网络更深的时候便会出现精度不升反降的现象,后来我们知道是因为梯度下降导致学习率下降甚至停滞,而到了 VGG 和 GoogLeNet 的年代,我们有了 ReLU,有了更好的初始化方法,有了 BN,但是如下面第一幅图所示,当深度达到50多层时,问题又出现了了,所以激活函数或者初始化方法仅仅是缓解了梯度消失,让网络的深度从几层推移到了二十多层,而如何让网络更深,正是 ResNet 被提出的原因。GoogLeNet 中我们提到采用辅助分类器的方式来解决梯度消失的问题,而 ResNet 是另一种思路,虽然这个思路并非由凯明首创,但是确实取得了很好的效果。
(3) 下图对比了 VGG-19 和 34层的 ResNet,可以看到 ResNet 的 kernel channel 比 VGG-19 少很多,另一个就是 ResNet 中已经没有 FC 了, 而是用的 Ave Pool,这点在 GoogLeNet 中已经提到过。下面的 VGG-19 的 FLOPs 是 19.6 biliion, 而下面的 34 层的 ResNet 仅仅只有3.6 billion,即使是152层的 ResNet152 也才 11.6 billion。另外还可以发现在 ResNet 中只有开头和结尾的位置有 pooling 层,中间是没有的,这是因为 ResNet 中间采用了 stride 为2的卷积操作,取代了 pooling 层的作用
(4)另外上图中需要注意的是,shortcut 有虚线和实线之分,实际上虚线的地方是因为用了 stride 为2的conv,因此虚线连接的 input 和 output 的 size 是不一样大的,因此没法直接进行 element wise addition,所以虚线表示并非是直接相连,而是通过了一个 conv 去完成了 resize 的操作,是相加的两个输入有相同的 size。
还一点是,之前在 VGG 和 GoogLeNet 中都采用3x3的conv,但是我们看到在 ResNet 中又用回了7x7的 conv。上图中 VGG-19用的4个 3x3, 而 ResNet 用的一个 7x7, 我觉得主要还是因为 ResNet 的 channel 数比较小,因此大的 kernel size 也不会使计算量变的很大(和 VGG-19 的4个 conv 比,计算量更小),而且可以获得较大的感受野。
(5)两个特征图用的是相加,GoogleNet用的是拼接
[1] (39条消息) 深度学习中的经典基础网络结构(backbone)总结_生命在于折腾!-CSDN博客_backbone网络
https://blog.csdn.net/kuweicai/article/details/102789420?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_v2~rank_aggregation-4-102789420.pc_agg_rank_aggregation&utm_term=%E7%BB%8F%E5%85%B8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E7%BB%93%E6%9E%84%E6%80%BB%E7%BB%93&spm=1000.2123.3001.4430
6 轻量化网络实现

7 Squeezenet
通过改变卷积核大小,来降低参数量,实际上计算量没有改变


SqueezeNet 的主要思想如下:
(1)多用 1x1 的卷积核,而少用 3x3 的卷积核。因为 1x1 的好处是可以在保持 feature map size 的同时减少 channel。
(2)在用 3x3 卷积的时候尽量减少 channel 的数量,从而减少参数量。
(3)延后用 pooling,因为 pooling 会减小 feature map size,延后用 pooling, 这样可以使 size 到后面才减小,而前面的层可以保持一个较大的 size,从而起到提高精度的作用。
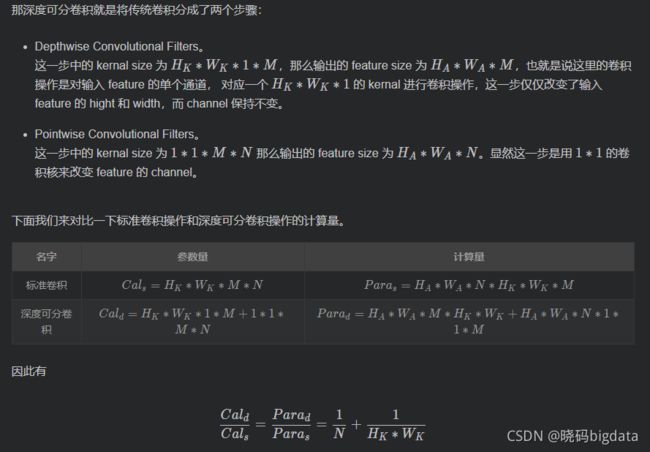
8 Mobilenet(深度可分离卷积)
用了两步,进下了卷积方面的优化
第一步33进行分组卷积,不改变通道数,参数量331输入channel
第二步11 进行卷积,改变通道数参数量11输入channel输出channel
传统的参数量 33输入channel*输出channel
(1)MobileNet 是通过优化卷积操作来达到轻量化的目的的,具体来说,文中通过 Deepwise Conv(其实是Deepwise Conv + Pointwise Conv)代替原始的卷积操作实现,从而达到减少计算的目的(通常所使用的是 3×3 的卷积核,计算量会下降到原来的九分之一到八分之一)。如下图所示。
(2)这一变换来达到减少参数量和计算量的目的。


9 ShuffleNet(分组卷积)
ShuffleNet 是 Xiangyu Zhang(旷视)等人于2017年在 ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 中提出来的。ShuffleNet 的核心思想是对卷积进行分组,从而减少计算量,但是由于分组相当于将卷积操作局限在某些固定的输入上,为了解决这个问题采用 shuffle 操作将输入打乱,从而解决这个问题。
12 注意力机制模型Residual Attention Network
注意力就是为正常的CNN前馈过程加一层权重(可以是对应每层CNN),但是没想到本文还融入了残差设计,并解释了为什么只添加mask在深层之后会导致性能下降。
[1] [论文笔记] Residual Attention Network - 知乎
https://zhuanlan.zhihu.com/p/128977244
二 目标识别
1 Faster-RCNN