数据分析:numpy和pandas基础操作详解
数据处理基础
- numpy基础
-
- 1.numpy创建数组及基础属性
- 2.数组的特点
- 3.创建常见数组
- 4.数组数据类型
- 5.生成随机数
- 6.一维数组索引
- 7.布尔索引
- 8. 多维数组的索引
- 9.实际问题
- 10.数组的转置和换轴
- 11.Numpy矩阵介绍
- 12.通用函数介绍
- 13数组广播机制
- 14Numpy读写二进制文件
- 15Numpy读写文本文件
- pandas基础
-
- 1Pandas简介
- 2.pandas读取文本文件
- 3存储数据框
- 4.pandas读取excel文件
- 5将数据框存储为excel文件
- 6.构建数据框
- 7.查看数据框的常用属性
- 8. 按行列顺序访问数据框中的元素
- 9.按行列名称访问数据框中的元素
- 10.修改数据框中的元素
- 11.删除数据框的元素
- 12.描述分析数据框中的元素
- 13.转换成时间类型数据
- 14.时间类型数据的常用操作
- 15.groupby分组操作
- 16.agg操作
- 透视表
numpy基础
1.numpy创建数组及基础属性
numpy是数据处理的基础,pandas也是基于numpy的,首先是numpy数组的创建。
一般我们默认导入了一下库
import numpy as np
import pandas as pd
1.numpy创建数组及基础属性
arr=np.array([[1,2,3],[4,5,6],[7,8,9]])
本文使用的编译环境是jupyter notebook,python3.7。如果想要安装jupyter可以参考我的另一篇文章点击此处不过只要是python3的版本都可以运行,也可以选择自己喜欢的编译器,不影响程序运行

numpy的核心特征之一就是N-维数组对象----ndarray。一个ndarray的每个元素均为相同类型
numpy的基础属性:shape ,dtype ,ndim, size
每一个数组都有一个shape属性用来表征数组每一维度的数量;每个数组都有一个dtype属性用来描述数组的数据类型。ndim返回数组的维数。size返回数组元素个数。

2.数组的特点
数组可以进行矢量运算,比如如果想把list的每个元素平方,用list ** 2这样的运算会报错,而数组不会

3.创建常见数组
除了np.array还有很多函数可以创建新数组,例如np.zeros可以一次行创建全0数组,ones可以一次性创建全1数组,empty则可以创建没有初始化的数组(np.empty有时会返回未初始化的垃圾值)。
 eye创建对角线全为1的二维数组
eye创建对角线全为1的二维数组
 np.logspace(start=开始值,stop=结束值,num=元素个数,base=指定对数的底, endpoint=是否包含结束值)base默认为10
np.logspace(start=开始值,stop=结束值,num=元素个数,base=指定对数的底, endpoint=是否包含结束值)base默认为10

 np.linspace()创建等差数列 ,(start=开始值,stop=结束值,num=元素个数)
np.linspace()创建等差数列 ,(start=开始值,stop=结束值,num=元素个数)

np.diag() 创建对角数组

arange是Python内建函数range的数组版
 Numpy没有特别指明的话,默认的数据结构是float64
Numpy没有特别指明的话,默认的数据结构是float64
4.数组数据类型
数据类型,即dtype也称元数据,表示数据的数据

数据类型的转化,可以用astype方法显式的转换数组的数据类型,也可以直接用函数转换。

5.生成随机数
生成无约束条件的随机数
 生成指定shape的均匀随机数
生成指定shape的均匀随机数
 生成符合正太分布的随机数
生成符合正太分布的随机数
 random具体函数用法
random具体函数用法

6.一维数组索引
 单个元素索引
单个元素索引

连续元素切片特点是左闭右开
 只取了前两位,因为取不到2
只取了前两位,因为取不到2
 注意[]内都是切片的,返回的维度不会发生改变,如上图,而将索引和切片混合就可以得到低纬度的切片。如
注意[]内都是切片的,返回的维度不会发生改变,如上图,而将索引和切片混合就可以得到低纬度的切片。如
 同时注意切片和索引的区别(切片会保留原数据的结构)
同时注意切片和索引的区别(切片会保留原数据的结构)
 虽然返回的是同一个元素,但是维度不同,切片返回的是一个数组,是一个矢量
虽然返回的是同一个元素,但是维度不同,切片返回的是一个数组,是一个矢量
7.布尔索引
举个例子就非常容易明白了
 只有索引为True的会返回,所以可以根据这一特点筛选想要的数据
只有索引为True的会返回,所以可以根据这一特点筛选想要的数据
 注意Python的关键字and和or对布尔数组并没有用,请使用&(and)和 |(or)来代替。
注意Python的关键字and和or对布尔数组并没有用,请使用&(and)和 |(or)来代替。
8. 多维数组的索引
- 多维数组的索引
首先用reshape函数重构一个多维数组
 这是一个二维数组,假如我们要取12这个元素,那么我们要找出12所在的行列索引,中间用逗号隔开
这是一个二维数组,假如我们要取12这个元素,那么我们要找出12所在的行列索引,中间用逗号隔开

对二维数组的切片与一维数组类似
 也可以逻辑索引和切片混合
也可以逻辑索引和切片混合

9.实际问题
9.实际问题
求解距离距离矩阵
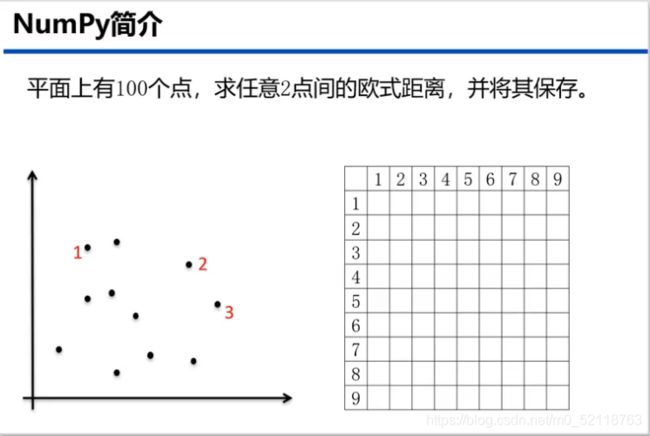 代码
代码

10.数组的转置和换轴
转置是一种特殊的数据重组形式,可以返回底层数据的视图而不需要复制任何内容。
 还有就是数组的展平ravel函数flatten函数等
还有就是数组的展平ravel函数flatten函数等
 还有一些其他的用法
还有一些其他的用法

 这里只介绍部分用法
这里只介绍部分用法
 数组的换轴,transpose方法可以接收包含轴编号的元组,具体用法点击此处
数组的换轴,transpose方法可以接收包含轴编号的元组,具体用法点击此处
11.Numpy矩阵介绍
首先是矩阵的生成

- mat函数mat可以从字符串或者列表中生成,其中字符串的表示中,矩阵的行与行之间用分号隔开,行内的元素之间用空格隔开(也可以用逗号)。
- numpy.matrix(data, dtype=None, copy=True)如果
date是字符串则将其解释为以逗号或空格分隔列的矩阵,以及分隔行的分号。
- numpy.bmat详情点击
矩阵运算

矩阵的属性


12.通用函数介绍
 一元通用函数:
一元通用函数:
| 函数名 | 描述 |
|---|---|
| abs,fabs | 逐元素的计算整数 浮点数或复数的绝对值 |
| sqrt | 计算每个元素的平方根 |
| exp | 计算每个元素的自然指数值 |
二元通用函数
| 函数名 | 描述 |
|---|---|
| multiply | 将数组的对应元素相乘 |
| add | 将数组的对应元素相加 |
| subtract | 在第二个数组中,将第一个数组中的包含的元素去除 |
 这部运算涉及到下面要讲的广播机制
这部运算涉及到下面要讲的广播机制
13数组广播机制
广播描述了算法如何在不同形状的数组之间进行运算,它是一个强大的功能。
广播机制的原则是:如果对于每个结尾维度(及从尾部开始的),轴长度都匹配或者其中一个是1,两个数组就是可以兼容广播的。
下面举一个反例
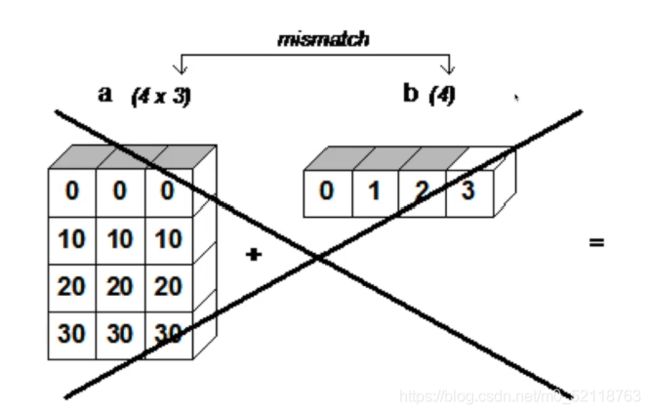
 一维数组【1,2,3】会向下进行广播,变成和二维数组相同的shape,然后对应元素相加
一维数组【1,2,3】会向下进行广播,变成和二维数组相同的shape,然后对应元素相加
 然后是二维数组的广播
然后是二维数组的广播
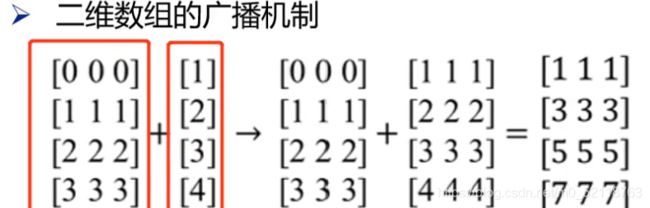 注意这两数组都是二维数组,不过第二个数组只有一列,数组向右进行广播
注意这两数组都是二维数组,不过第二个数组只有一列,数组向右进行广播


14Numpy读写二进制文件
实际情况中使用较少

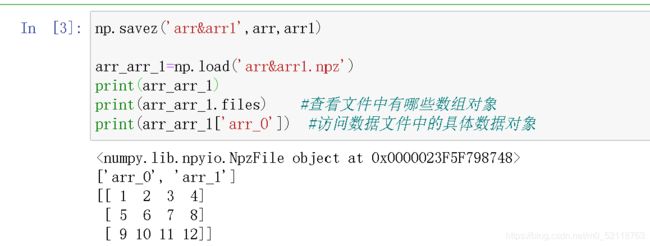
 保存多个数组到一个文件中,注意不能直接print输出文件内容,而要指明查看的文件中的具体数据对象
保存多个数组到一个文件中,注意不能直接print输出文件内容,而要指明查看的文件中的具体数据对象
15Numpy读写文本文件
 delimiter:指定文件分割符
delimiter:指定文件分割符

pandas基础
1Pandas简介
pandas有两个常用的数据结构:Serise和DataFrame。
Serise是一种一维的有数据标签的数组型对象,DataFrame二维数据表,既有行索引也有列索引
pandas在数据分析处理中有非常重要的地位,具有一下特点:

2.pandas读取文本文件
1.文本文件读取
 一般使用pd.read_csv(这个函数不仅仅可以读取csv文件还可以读取txt等其他文件)
一般使用pd.read_csv(这个函数不仅仅可以读取csv文件还可以读取txt等其他文件)
![]()
 注意读取文件的时候一定要清楚文件的分割符是什么,以及文件的编码格式:utf-8,utf-16,gbk,gb2312,gb18030。后三种是多用于中文的解码
注意读取文件的时候一定要清楚文件的分割符是什么,以及文件的编码格式:utf-8,utf-16,gbk,gb2312,gb18030。后三种是多用于中文的解码
如果编码格式不对的话就会出现乱码的情况,如下
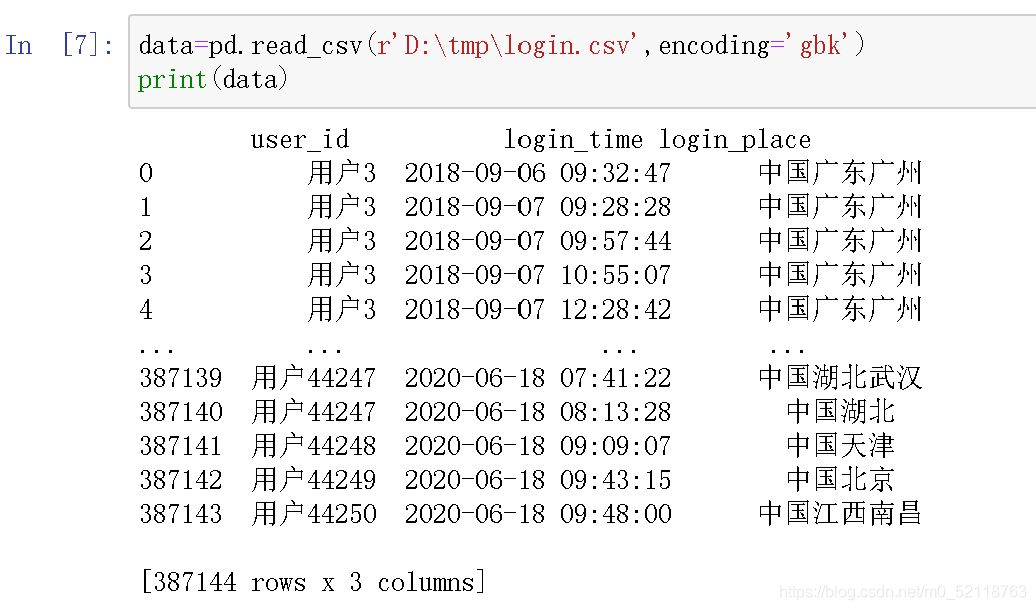
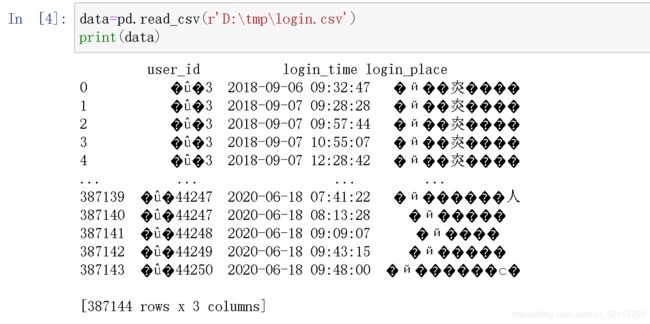 加上编码格式
加上编码格式
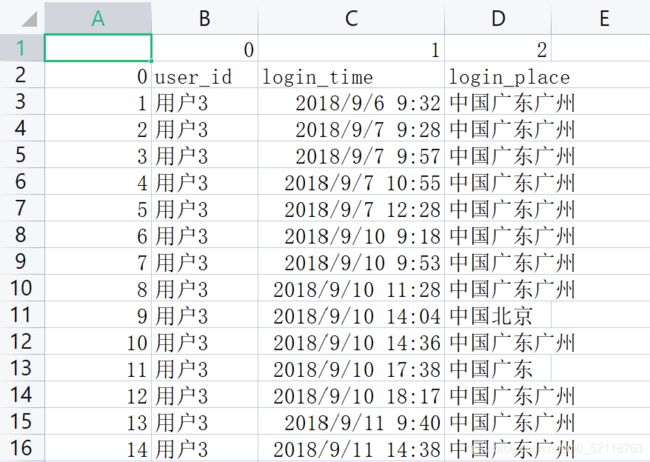
 如果数据中没有列名称读取数据可以设置参数header=None
如果数据中没有列名称读取数据可以设置参数header=None

数据量过大,以下图片均为部分数据展示
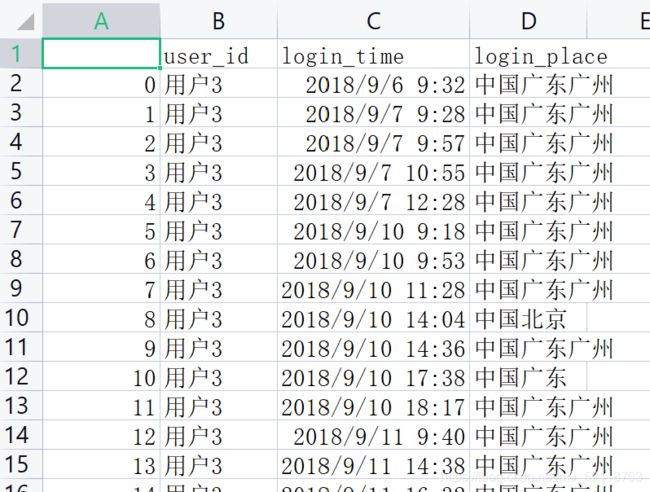
3存储数据框


![]() 数据保存会默认传递index
数据保存会默认传递index
![]() 左边比原数据多了一列从0开始的index
左边比原数据多了一列从0开始的index
如果想保留原数据可以设参数index=None
 不要列名称可以使用
不要列名称可以使用header=None
 读取和存储的时候都有header参数,注意区分
读取和存储的时候都有header参数,注意区分
4.pandas读取excel文件
1.excel文件读取


 想要读取不同的表只需要设置参数
想要读取不同的表只需要设置参数sheet_name

5将数据框存储为excel文件
 这样保存数据左边也会出现一列从0开始的index,可以加参数index
这样保存数据左边也会出现一列从0开始的index,可以加参数index
 s
s
6.构建数据框
一维序列,类比列表,但是每个元素具有名称。如果从DataFrame中取出一列返回的数据结构就是Series。
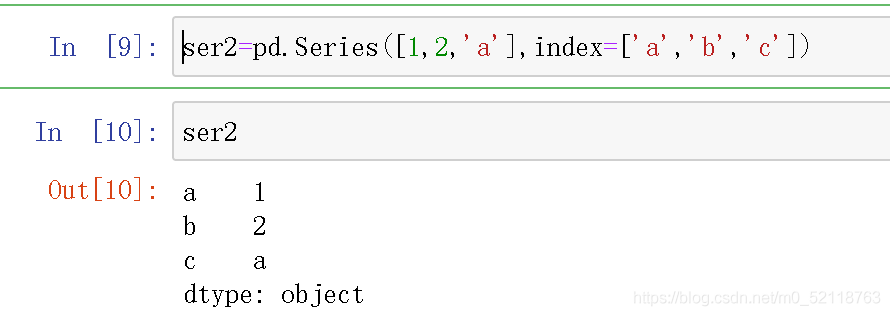 也可以直接用字典构建Series
也可以直接用字典构建Series
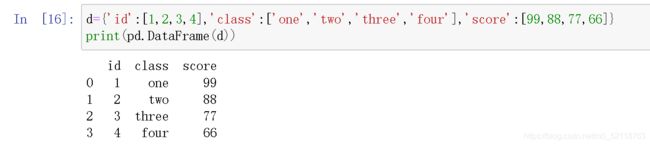
 创建DataFrame,可以用列表充当data
创建DataFrame,可以用列表充当data
 可以指定index和列名称(columns)
可以指定index和列名称(columns)
 也可以用字典创建DataFrame,这样的话字典的键就会充当类名称,值就是数据源
也可以用字典创建DataFrame,这样的话字典的键就会充当类名称,值就是数据源
还可以创建一些特殊的DataFrame,如果不传入data参数,就会创建缺失值型的数据框
 还可以创建全零
还可以创建全零

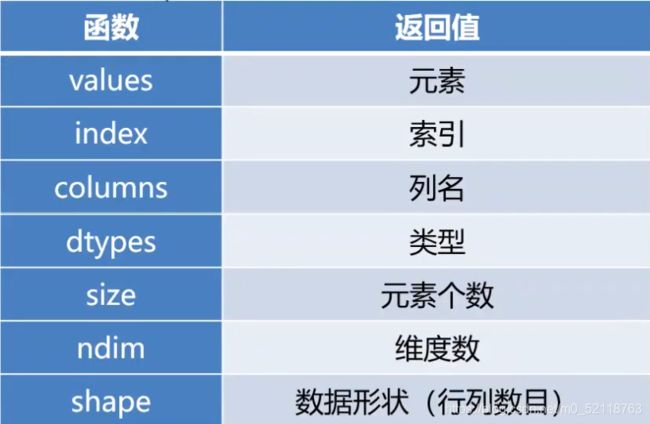
7.查看数据框的常用属性
查看DataFrame的常见属性

8. 按行列顺序访问数据框中的元素
 首先就是单列数据访问
首先就是单列数据访问
 访问任意两列
访问任意两列
 如果你只需要看数据的前几行可以
如果你只需要看数据的前几行可以
 看数据的后几行
看数据的后几行

如果想访问数据框中某个特定的元素,iloc函数指明元素所在的行列
 取某一行或者某一列
取某一行或者某一列
 行列顺序访问也可使用切片的方法
行列顺序访问也可使用切片的方法
注意获取到的数据的数据结构
 因为
因为df.iloc[:,0:1] 左右都是索引,维度不变。
9.按行列名称访问数据框中的元素
当数据框的数量较大的时候,按顺序访问较为麻烦,这时后可以采用按行列名称访问数据框中的元素。
先构建一个新的数据框
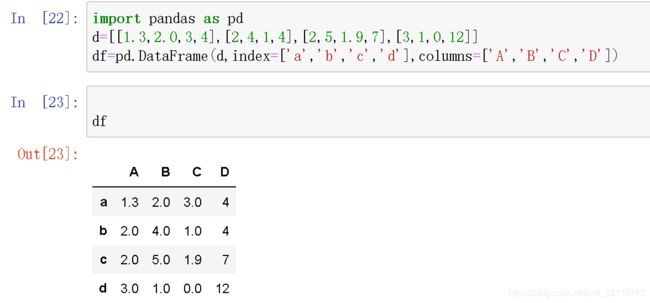 使用loc函数进行名称的访问
使用loc函数进行名称的访问
 注意按照行列名称进行访问的时候,切片
注意按照行列名称进行访问的时候,切片df.loc['a':'c','C']是闭区间,从‘a’到‘c’,因为按位置索引的时候可以判断3前面的数是2,而计算机无法判断‘c’前面的一个数是什么。
10.修改数据框中的元素
 例如
例如
 对整列数据进行修改,有两种方式
对整列数据进行修改,有两种方式

增加数据

11.删除数据框的元素
删除某行或某列需要用到pandas提供的方法drop
 注意默认inplace=False,不对原数据修改
注意默认inplace=False,不对原数据修改
 如果想要修改原数据
如果想要修改原数据
 删除行
删除行

12.描述分析数据框中的元素
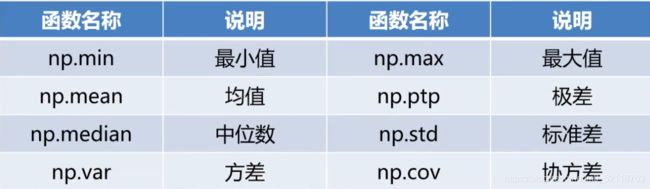
数值型特征的描述性统计-----Numpy中的描述性统计函数。
pandas库基于Numpy,自然也可以用这些函数对数据框进行描述性统计。
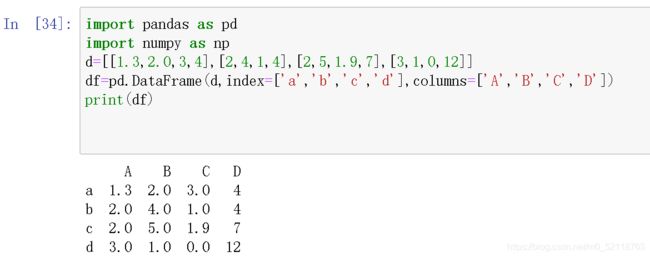
 首先构建数据框
首先构建数据框
 每一行的均值
每一行的均值
 用pandas自带的方法的形式
用pandas自带的方法的形式
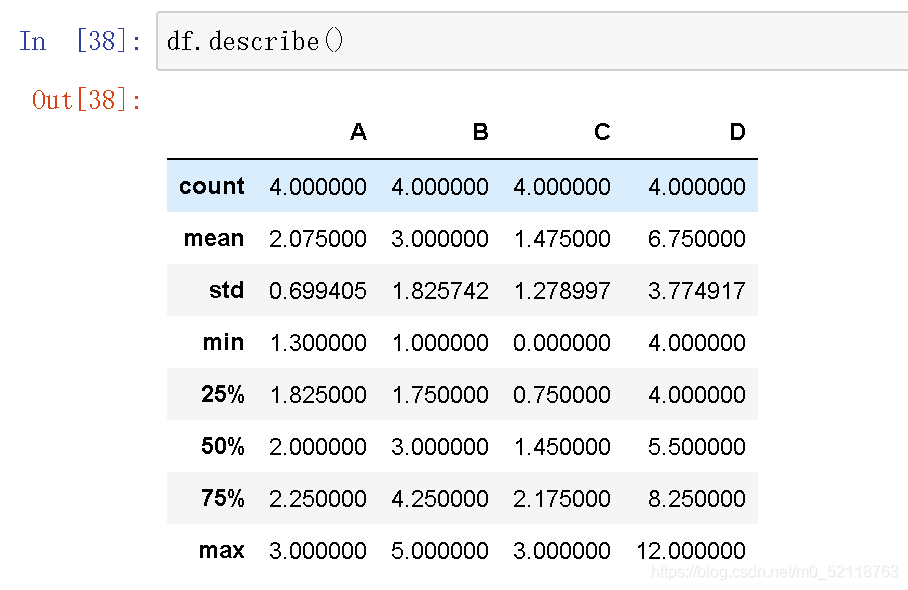
 了解数据的整体分布情况
了解数据的整体分布情况
 还可以统计每一列元素的计数结果,也就是统计这一列每个元素的出现次数
还可以统计每一列元素的计数结果,也就是统计这一列每个元素的出现次数

13.转换成时间类型数据
pands时间相关的类
在多数情况下,对时间类型数据进行分析的前提就是将原本为字符串的时间转换为标准时间类型。pandas继承了NumPy库和datetime库的时间相关模块,提供了6种时间相关的类。
 Timestamp作为时间类中最基础的,也是最为常用的类型,在多数情况下,时间相关的字符串都会转换成为Timestamp。pandas提供了to_datetime函数,能够实现这一目标
Timestamp作为时间类中最基础的,也是最为常用的类型,在多数情况下,时间相关的字符串都会转换成为Timestamp。pandas提供了to_datetime函数,能够实现这一目标
首先我们的数据是点击此处
提取码p53u
 'lock_time’不是我们想要的时间类型
'lock_time’不是我们想要的时间类型

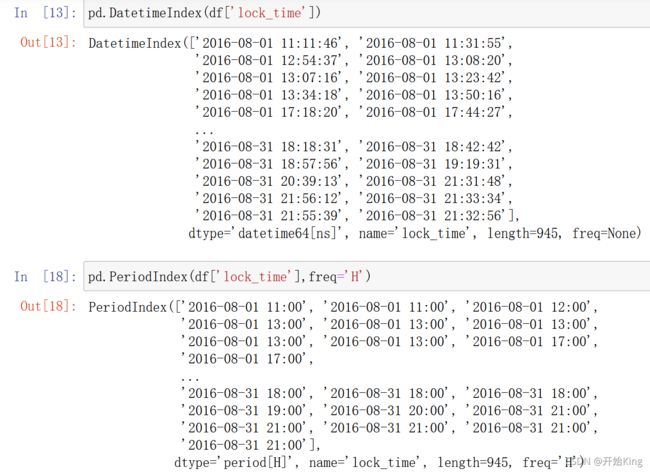
除了将数据字原始DataFrame中直接转换为Timestamp格式外,还可以将数据单独提取出来将其转换
为DatetimeIndex或者PeriodIndex。
转换为PeriodIndex的时候需要注意,需要通过freq参数指定时间间隔,常用的时间间隔有Y为年,M为月,D为日,H为小时,T为分钟,S为秒。两个函数可以用来转换数据还可以用来创建时间序列数据,其参数非常类似。
 参数设置
参数设置

14.时间类型数据的常用操作
Timestamp类常用属性
在多数涉及时间相关的数据处理,统计分析的过程中,需要提取时间中的年份,月份等数据,使用对应的Timestamp类属性就能够实现这一目的。
比如获取当前时间的年份,对单个数据的操作是

如果想要对一列进行操作
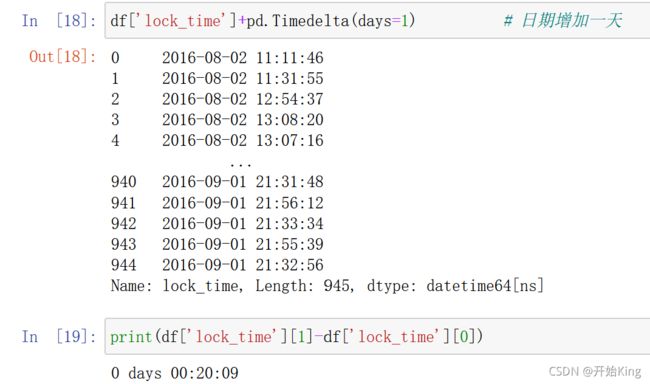
 还可以进行时间的加减
还可以进行时间的加减
15.groupby分组操作
首先读入我们的数据,数据在上面的网盘链接里
 从中提取三列数据,以’order_id’为分组依据
从中提取三列数据,以’order_id’为分组依据
 分组后的结果是不能直接访问的,需要进行agg操作
分组后的结果是不能直接访问的,需要进行agg操作
16.agg操作
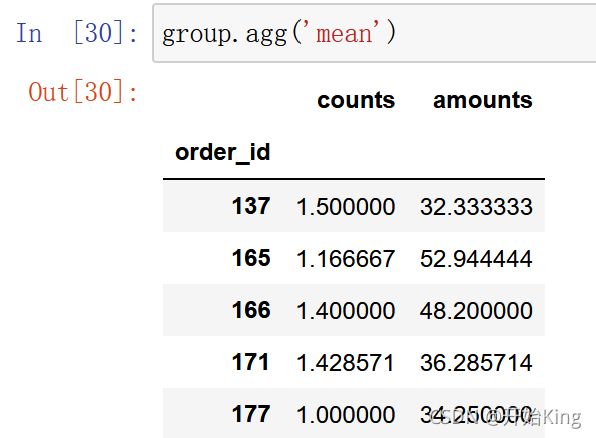
比如对数据进行求均值
还可以同时进行多种操作
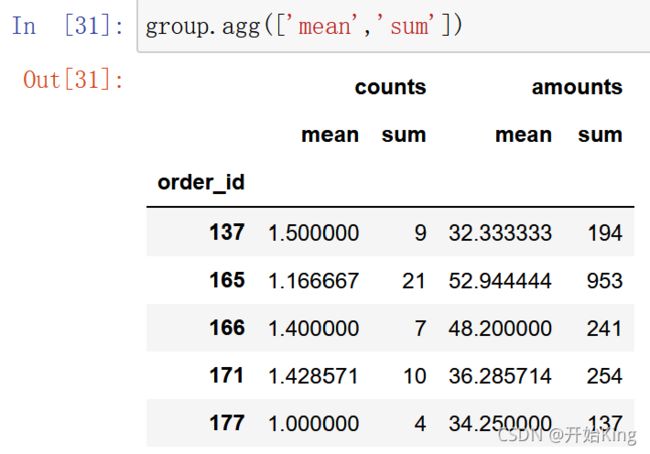 还可以采用字典的形式,对不同列进行不同的函数处理
还可以采用字典的形式,对不同列进行不同的函数处理
 你也可以自定义函数操作
你也可以自定义函数操作
