Python之数据清洗
Python之数据清洗
注:使用数据源—口袋妖怪数据集提取码s30w
一、检查数据
1、不清楚的数据
- 列名不一致(大小字母或单次之间的空格)
- 数据缺失
- 语言不同
通常使用head,tail,columns,shape和info等函数来检查数据
# 数据清洗
import pandas as pd
# import numpy as np
data=pd.read_csv('..\data\pokemon\Pokemon.csv')
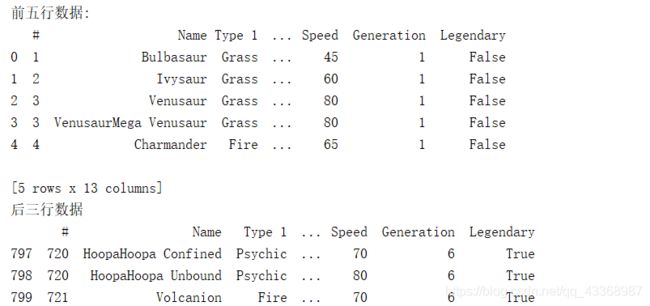
# 输出前五行数据
print('前五行数据:')
print(data.head(5))
# 输出最后三行数据
print('后三行数据')
print(data.tail(3))
# 查看列名
print('列名:',data.columns)
# 查看行数与列数
print('行数与列数:',data.shape)
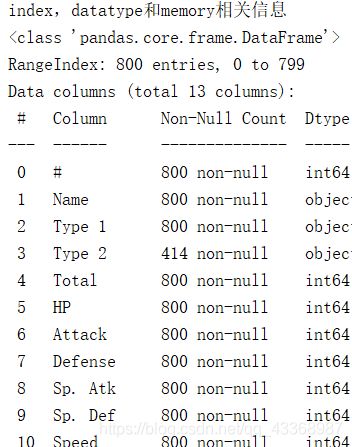
# 展示index,datatype和memory相关信息
print('index,datatype和memory相关信息')
print(data.info())
运行结果


二、EDA(探索性数据分析)
1.value_counts()与离群值
pandas中的一个函数,可以对series里面的每个值进行技术并且排序
离群值(outliers):也称溢出值,是指在数据中有一个或者几个其他数据相比差异较大
- 小于 Q1 - 1.5(Q3-Q1) ,或大于 Q3 + 1.5(Q3-Q1)的值称为outliers。(Q1表示第一四分位数)
- TQR代表四分位数间距,IQR=(Q3-Q1)
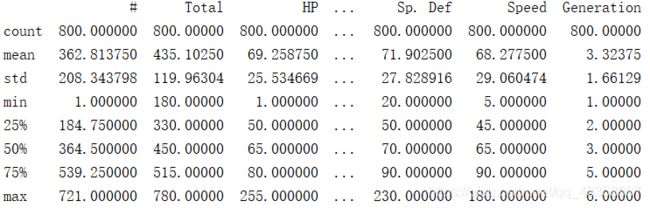
我们使用describe()函数总结数据集分布的中心趋势,常用的算术运算指标如下:
- count: 计算每个条目出现的次数
- mean: 平均值
- std: 标准差
- min: 最小值
- 25%: 第一四分位数
- 50%: 中位数
- 75%: 第三四分位数
- max: 最大值
注:什么是四分位数??
四分位数也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。多应用于统计学中的箱线图绘制。它是一组数据排序后处于25%和75%位置上的值。
四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。很显然,中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为第一四分位数)和处在75%位置上的数值(称为第三四分位数)。
举例:1,4,5,6,8,9,11,12,13,14,15,16,17
第二四分位数(中位数)Q2是序列中间的数字,即11;
第一四分位数Q1,是最小数字和中位数之间的中位数,也就是1到11之间的中位数,即6;
第三分位数Q3,是中位数和最大数之间的中位数,也就是11和17之间的中位数,即14。
看看不同类型口袋妖怪出现的频率
# EDA
import pandas as pd
data=pd.read_csv('..\data\pokemon\Pokemon.csv')
#dropna表示升序,为false表示降序,true为升序
print(data['Type 1'].value_counts(dropna=False))
运行结果
从运行结果可以看出水精灵的个数最多,有112个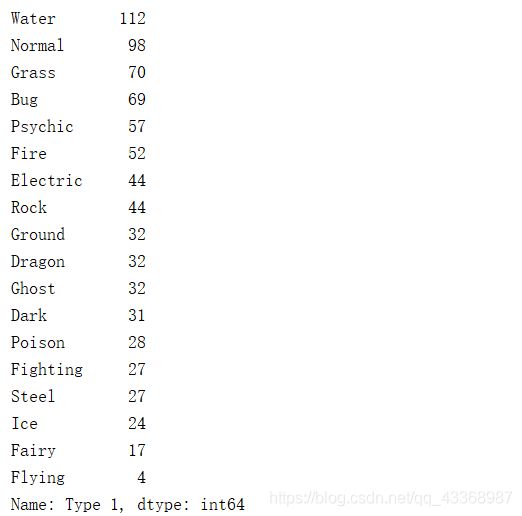
可以通过describe()函数看出其他信息
print(data.describe())
2.箱线图(box plot)
箱线图:可视化基本的统计数据,如离群值,最大、最小值,四分位值等
# 箱线图:可视化基本的统计数据:如离群值,最大最小值,四分位值
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv('..\data\pokemon\Pokemon.csv')
data.boxplot(column=['Attack','Defense'])
plt.show()
运行结果

加入分类数据列‘Legendary’
data.boxplot(column='Attack',by='Legendary')
运行结果

三、重塑数据
使用melt()函数来转换数据的行列。
语法:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name=‘value’, col_level=None)
参数:
- frame:要处理的数据集
- id_vars:不需要被转换的列名
- value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了
- var_name和value_name是自定义设置对应的列名。
# 数据重塑
import pandas as pd
data=pd.read_csv('..\data\pokemon\Pokemon.csv')
data_new=data[10:15]#取10-14行数据来构建新的数据表
# print(data_new)
# 使用melt()函数
#frame:需要处理的数据集,id_vars:不需要转换的列名,value_vars:需要转换的列名
melted=pd.melt(frame=data_new,id_vars='Name',value_vars=['Attack','Defense'])
print(melted)
运行结果

四、数据透视表
pivot()函数根据列值重塑数据,生成“数据透视表”
语法:
DataFrame.pivot_table(index=None, columns=None, values=None)
参数:
- index: 重塑的新表的索引名称是什么
- columns:重塑的新表的列名称是什么
- values: 生成的新列中的值是什么
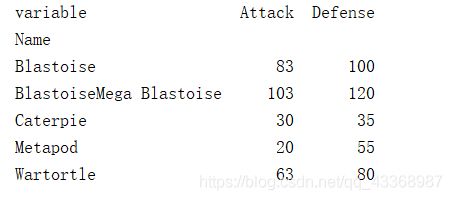
# 需求:根据上面的melted数据表生成一张新表,新表可以显示口袋妖怪的名字以及对应的防御值和攻击值
# index:重塑的新表的索引名称,columns:重塑的新标的列名称,values:生成的新列中的值是什么
melted_pivot=melted.pivot(index='Name',columns='variable',values='value')
print(melted_pivot)
运行结果
五、数据连接
将两个dataframe连接在一起
# 数据连接:将两个dataframe连接在一起
import pandas as pd
data=pd.read_csv('..\data\pokemon\Pokemon.csv')
# 首先生成两个新的dataframe
# 分别取data的前三行和后三行数据
data1=data.head(3)
data2=data.tail(3)
# 使用comcat将两个dataframe连接在一起,axis=0表示行拼接,即纵向拼接
con_data_row=pd.concat([data1,data2],axis=0,ignore_index=True)
print(con_data_row)
运行结果

data1=data['Attack'].head(3)
data2=data['Defense'].head(3)
#axis=1:列拼接,即横向拼接
conc_data_col=pd.concat([data1,data2],axis=1)
print(conc_data_col)

六、数据类型转换
1.Python的基础数据类型
- Number(数字):int、float、bool、complex
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
不同的数据类型之间可以转换,例如将字符串转换为categorical数据(分类数据),或者将整数转换为浮点数
2.统计数据类型:Numerical 与 Categorical
Numerical data:这种数据类型具有实际测量的物理意义(例如一个人的身高、体重、血压等);或者是一个计量数字(比如一个人拥有多少股票,一只猫有多少颗牙齿等),统计学上也称其为定量数据(quantitative data)。
Numerical data可分为两类:离散型数据(discrete data)和连续型数据(continuous data)。
- 离散型:离散数据无法测量但可以计数,具有可以列出的可能值。其可能值的列表可以是有限的,也可以是可数无穷的。例如,100次抛掷中正面的次数取值范围从0到100(有限情况),但得到100次正面所需的抛掷次数取值范围从100(最快的情况)到无穷大(如果永远不能得到第100次正面)。它的可能值被列出为100、101、102、103、……(表示可数无穷情况)
- 连续型:连续数据表示测量值,它们的可能值不能计算,只能用实数轴上的间隔来描述。例如,一个油箱容量60L的汽车,在加油站购买的确切汽油量将是0L到60L之间的连续数据,用区间[0,60]表示。连续数据可以被认为是不可数的无限的。为了便于记录,统计人员通常会在数字中选取一个点进行四舍五入。
Categorical data:分类数据表示特征,如一个人的性别,婚姻状况,家乡,或他们喜欢的电影类型。分类数据也可以是数值(例如“1”表示男性,“2”表示女性),但这些数字没有数学意义,比如你不能把它们加在一起。
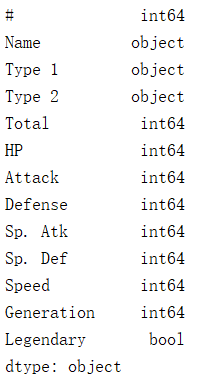
# 查看数据类型
print(data.dtypes)
运行结果
# 将str转换为categorical(分类数据),将int转换为float
data['Type 1']=data['Type 1'].astype('category')
data['Speed']=data['Speed'].astype('float')
print(data.dtypes)
运行结果

七、数据缺失及断言
1.如果遇到缺失的数据(NaN)我们能做的事情有:
- 放着不管
- 使用dropna()函数删除他们
- 用fillna()函数填充缺失值
- 用平均值之类的统计数据填充缺失值
assert: Python中assert用来判断语句的真假,如果为假的话将触发AssertionError错误
# 查看pokemon数据集是否存在NAN值
print(data.info())

800个条目中,type2 只有414个非空对象,有386个空
# 单独将type2提出来验证上述
print(data['Type 2'].value_counts(dropna=False))
运行结果

#使用dropna()删除nan值
data1=data#后面使用数据来填充缺失值
# #inplace=True表示我们不将其赋值给新变量,自动分配填充缺失值
data1['Type 2'].dropna(inplace=True)
data1=data1.dropna().head(6)
print(data1['Type 2'].head(6))
运行结果

2.assert的用法
# assert语法的用法
assert 2==2
# 语句为真,没有返回值
运行结果

assert 1==2
#错误,会返回asserterror错误
运行结果

# 使用notnull()函数判断数据是否缺失,返回boll型数据,这里返回的是Ture
# 使用all()函数判断notnull()返回的值是否都为True,是则返回Ture
# 使用assert断言,语句为真
assert data1['Type 2'].notnull().all() # 因为已经删除了nan值,所以什么也不返回
# 使用fillna()可以填充缺失值
print(data['Type 2'].head(6))
data["Type 2"].fillna('empty',inplace=True)
print(data['Type 2'].head(6))
运行结果

自学自用,希望可以和大家积极沟通交流,小伙伴们加油鸭,如有错误还请指正,不喜勿喷