第一章 kafka-初识(基础)
目录
1、概述
1.1、异步通信、系统解耦
1.2、削峰填谷
1.3、Kafka重点研究的内容
1.4、常见的消息队列工作模式
1.5、Kafka集群
2、分区&日志
3、消费者&生产者
4、高性能之道 - 顺序写入&mmap
零拷贝(zeroCopy)
下一章我们讲一下Kafka的环境搭建(单机和集群)以及Topic的管理
1、概述
kafka是一个流处理平台,该平台提供了消息的订阅与发布的消息队列,一般作用于系统间的解耦、异步通信、削峰填谷等作用。同时kafka又提供了kafka streaming插件包实现了实时在线流处理。相比较一些专业的流处理框架不同,kafka Streaming计算是运行在应用端,具有简单、入门简单、入门要求低、部署方便等优点。
1.1、异步通信、系统解耦

1.2、削峰填谷

1.3、Kafka重点研究的内容
-
消息队列Message Queue(重点)
-
Kafka Streaming流处理
1.4、常见的消息队列工作模式
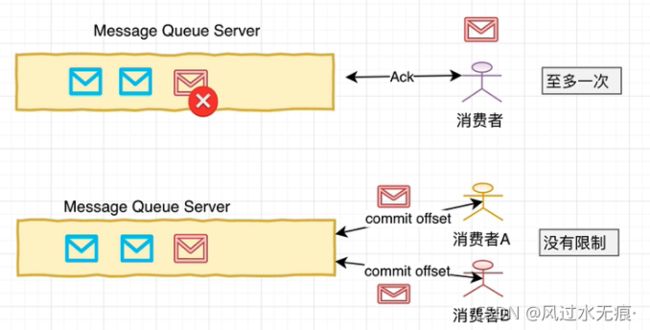
- 至多一次:消息生产者将数据写入消息系统,然后由消费者负责去拉取消息服务器中的消息,一个旦消息被确认消费之后,由消息服务器主动删除队列中的数据,这种消费方式一般只允许被一个消费者消费一次,并且消息队列中的数据不允许被重复消费。
- 没有限制:同上诉消费形式不同,生产者发布完数据以后,该消息可以被多个消费者同时消费,并且同一个消费者可以多次消费消息服务器中的同一个记录。主要是因为消息服务器一般可以长时间存储海量信息。
1.5、Kafka集群
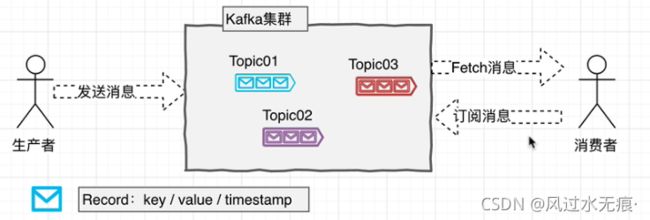
以Topic形式负责分类集群中的Record,每一个Record属于一个Topic。每一个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有一个Broker担当该分区的Leader,其他的Broker担当该分区的follower,Leader负责分区数据的读写操作,follower负责同步该分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群中的Leader监控和Topic的部分元数据是存储在zookeeper中。
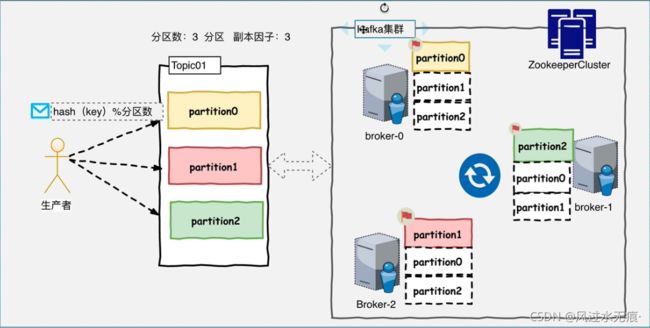
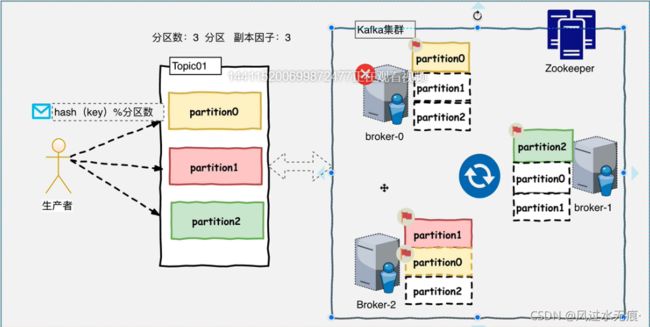
broker-0宕机的情况:
Record:一则消息。
Topic:消息队列中对Record的分类机制(逻辑概念)。
partition(分区): 将Topic中的数据分散的存储在几个独立的文件中。
副本因子:当前分区文件在集群中有多少个本分数据(分区因子不应大于broker的数量),且副本因子数包含leader的部分。
broker:集群中的每一个Kafka节点
2、分区&日志
Kafka中所有的消息都是通过Topic为单位进行管理,每个Kafka中的Topic通常都会有多个订阅者,负责订阅发送到该Topic中的数据。
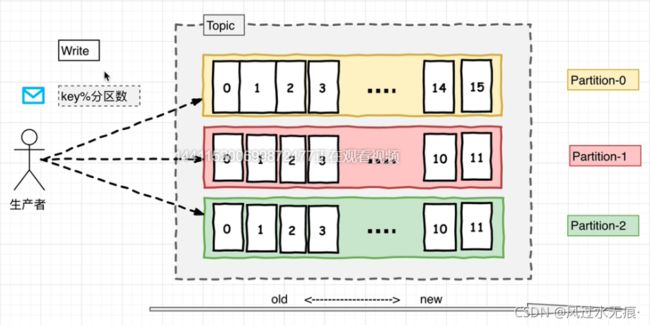
生产者将数据发布到相应的Topic。负责选择将哪个记录分发到Topic中的哪个Partition。例如可以round-robin方式完成此操作,然而这种仅仅是为了平衡负载。也可以根据某些语义分区功能(例如基于记录中Key)进行此操作。
每组日志分区是一个有序的不可变的日志序列,分区中的每一个Record都被分配了唯一的序列编号称为offset,kafka集群会持久化所有发布到Topic中的Record信息,该Record的持久化时间是通过配置文件指定,默认是168小时。
log.retention.hours=168
Kafka底层会定期检查日志 文件,然后将过期的数据从log中移除,由于Kafka使用硬盘存储日志文件,因此Kafka长时间缓存一些日志文件是不存在问题的。
Kafka的分区越多,Kafka的吞吐能力越强。
3、消费者&生产者
在消费者消费Topic中数据的时候,每个消费者会维护本次消费对应分区的偏移量,消费者会在消费完一个批次的数据之后,会将本次消费的偏移量提交给Kafka集群,因此对于每个消费者而言,可以随意控制修改消费的偏移量。因此,在Kafka中,消费者可以从一个Topic分区中的任意位置读取队列数据,由于每个消费者控制了自己消费的偏移量,因此多个消费者之间彼此相互独立。
kafka中对Topic实现日志分区有以下目的:
- 首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区都必须适合托管它的服务器,但一个Topic可能有很多分区,因此它可以处理任意数量的数据。
- 其次,每个服务器充当其某些分区的leader,也可以充当其他分区的follower,因此集群中的负载得到了很好的平衡
消费者:
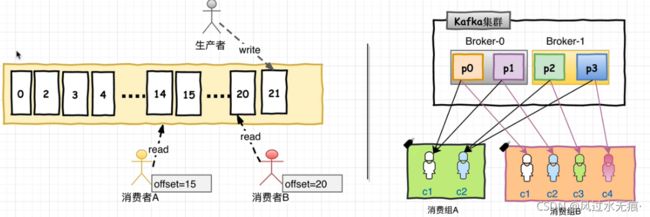
消费者使用Consumer Group名称标记自己,并且发布到Topic的每条记录都会传递到每个订阅Consumer Group中的一个消费者实例。如果所有Consumer实例都具有相同的Consumer Group,那么Topic中的记录会在该Consumer Group中的Consumer实例进行均分消费。如果Consumer实例具有不同的Consumer Group,则每条记录将广播到所有Consumer Group进程。
更常见的是,我们发现Topic具有少量的Consumer Group,每个Consumer Group可以理解为一个“逻辑订阅者”。每个Consumer Group均由许多Consumer实例组成,以实现可伸缩性和容错能力。这无非就是发布-订阅模型,其中订阅者是消费者的集群而不是单个进程。这种消费方式Kafka会将Topic按照分区的方式均分给一个Consumer Group下的实例。如果Consumer Group下有新的成员介入,则新介入的Consumer实例回去接管Consumer Group其他消费者负责的某些分区,同样如果同一Consumer Group下有其他Consumer实例宕机,则有该Consumer Group其他实例接管。
由于Kafka的Topic的分区策略,因此Kafka仅提供分区中记录的有序性,也就意味着相同的Topic的不同分区记录之间是无顺序的。因为针对于绝大多数的大数据应用和使用场景,使用分区内部有序或使用key进行分区策略已经足够满足大多数应用场景。但是,如果需要记录全局有序性,则可以通过只有一个分区Topic来实现,这样意味着每个Consumer Group只有一个Consumer进程(防止重复消费)。
4、高性能之道 - 顺序写入&mmap
Kafka的特性之一就是高吞吐率,但是Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上的读写数据是会降低性能的,但是Kafka即使是普通服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也是的Kafka在日志处理等海量数据场景广泛应用。Kafka会把收到的消息都写入到磁盘中,防止丢失数据。为了优化写入速度,Kafka采用了两个技术:顺序写入和MMFile(内存映射文件)。
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。这样省去了大量的内存开销以及节省了IO寻址的时间。但是单纯的使用顺序写入,Kafka的写入性能也不可能和内存进行对比,因此Kafka的数据并不是实时写入硬盘中。
Kafka充分利用了现代操作系统分页存储来利用内存提高I/O效率。Memory Mapped Files(mmap)也称为内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接用操作系统的Page实现文件到物理内存的直接映射。完成mmap映射后,用户对内存的所有操作会被操作系统自动的刷新到磁盘上,极大地降低了IO使用率。
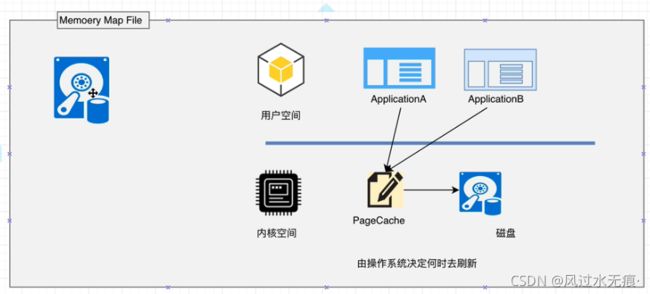
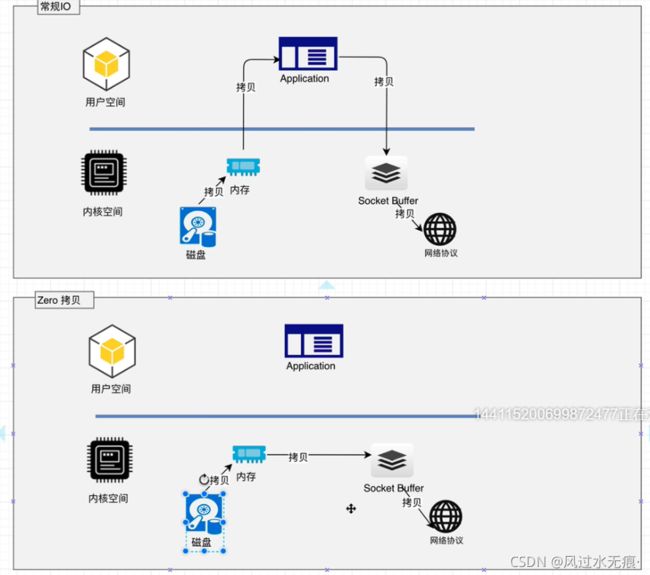
Kafka服务器在响应客户端读取的时候,底层使用ZeroCopy技术,直接将磁盘无需拷贝到用户空间,而是直接将数据通过内核空间传递输出,数据并没有抵达用户空间。(传统用户读取步骤:硬件 ——> 到内核空间处理完 ——> 到用户空间处理完成 ——> 再到内核空间出去) --- 零拷贝的意思是:从硬盘读取直接走内核空间出去,不进行用户空间的处理,叫做ZeroCopy技术。
零拷贝(zeroCopy)
常规读取:
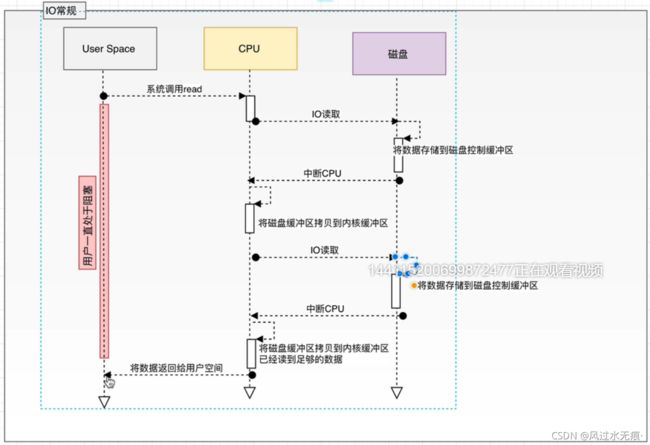
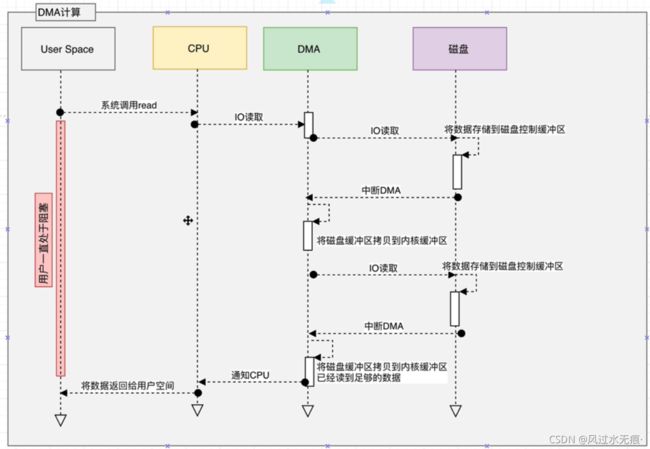
DMA:协处理器(可以防止 CPU多次中断,释放CPU的计算能力)