文本分词和文本表示
实验步骤
- 文本自动分词
-
- 基于正向最大匹配算法对文本进行分词
- 基于反向最大匹配算法对文本进行分词
- 对分词效果进行评估
- 文本表示(tf-idf)
- 利用夹角余弦计算文本相似度
文本自动分词
基于正向最大匹配算法对文本进行分词
最大匹配法:最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。例如:词典中最长词为“中华人民共和国”共7个汉字,则最大匹配起始字数为7个汉字。然后逐字递减,在对应的词典中进行查找。
python代码如下:
import time
import datetime
test_file = '词典.txt' # 词典
test_file2 = '分词测试(1).txt' # 测试文件
test_file3 = '正向分词结果.txt'
#def get_dic(test_file):
# with open(test_file,'r',encoding='gb18030',) as f:
# try:
# file_content = f.read().split()
# finally:
# f.close()
# chars = list(set(file_content))
# return chars
with open(test_file,'r',encoding='gb18030',) as f:
dic = f.read()
def readfile(test_file2):
max_length = 5
num = 0
h = open(test_file3, 'w', encoding='gb18030', )
with open(test_file2, 'r', encoding='gb18030', ) as g:
lines = g.readlines()
start = time.time()
print(datetime.datetime.now())
for line in lines:
max_length = 5
my_list = []
len_hang = len(line)
while len_hang > 0:
tryWord = line[0:max_length]
while tryWord not in dic:
if len(tryWord) == 1:
break
tryWord = tryWord[0:len(tryWord) - 1]
my_list.append(tryWord)
line = line[len(tryWord):]
len_hang = len(line)
for t in my_list:
num += 1
if t == '\n':
h.write('\n')
elif t in range(9):
h.write(t)
else:
h.write(t + " ")
end = time.time()
print(datetime.datetime.now())
h.close()
g.close()
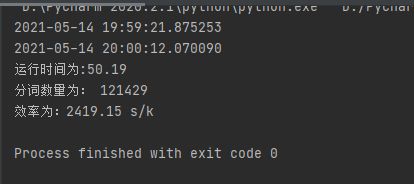
print('运行时间为:%.2f' %(end - start))
print('分词数量为:',num)
p = float(num/(end-start))
print('效率为:%.2f s/k' %(p))
readfile(test_file2)
正向分词结果:

基于反向最大匹配算法对文本进行分词
test_file = '搜狗标准词库.txt' # 词典
test_file2 = '分词测试(1).txt' # 测试文件
test_file3 = '反向分词结果.txt'
def get_dic(test_file):
with open(test_file,'r',encoding='gb18030',) as f:
try:
file_content = f.read().split()
finally:
f.close()
chars = list(set(file_content))
return chars
dic = get_dic(test_file)
def readfile(test_file2):
max_length = 5
h = open(test_file3, 'w', encoding='gb18030', )
with open(test_file2, 'r', encoding='gb18030', ) as g:
lines = g.readlines()
for line in lines:
my_stack = []
len_hang = len(line)
while len_hang > 0 :
tryWord = line[-max_length:]
while tryWord not in dic:
if len(tryWord) == 1:
break
tryWord = tryWord[1:]
my_stack.append(tryWord)
line = line[0:len(line)-len(tryWord)]
len_hang = len(line)
while len(my_stack):
t = my_stack.pop()
if t == '\n':
h.write('\n')
elif t in range(9):
h.write(t)
else:
h.write(t + " ")
h.close()
g.close()
readfile(test_file2)
反向分词结果:

对分词效果进行评估
针对分词结果,对分词效果进行评价,包括分词速度和分词准确率
分词速度:通过分词数量和所消耗的时间的比值给出:
分词准确率,通过与标准分词结果进行对比给出:
test_file1 = '正向分词结果.txt'
test_file2 = '标准结果.txt'
def get_word(fname): #对生成的文本和标准答案文本每行通过切分形成词汇表,然后比较计算
f = open(fname,'r',encoding='gb18030',)
lines = f.readlines()
return lines
def calc():
lines_list_sc = get_word(test_file1)
lines_list_sta = get_word(test_file2)
lines_list_num = len(lines_list_sta)
right_num = 0
m = 0
n = 0
for i in range(lines_list_num):
try:
line_list_sc = list(lines_list_sc[i].split())
line_list_sta = list(lines_list_sta[i].split())
m += len(line_list_sc)
n += len(line_list_sta)
str_sc = ''
str_sta = ''
s = 0
g = 0
while s<len(line_list_sc) and g<len(line_list_sta):
str_word_sc = line_list_sc[s]
str_word_sta = line_list_sta[g]
str_sc += str_word_sc
str_sta += str_word_sta
if str_word_sc == str_word_sta:
s += 1
g += 1
right_num += 1
else:
while len(str_sc) > len(str_sta):
g += 1
str_sta += line_list_sta[g]
while len(str_sc) < len(str_sta):
s += 1
str_sc += line_list_sc[s]
g += 1
s += 1
except:
continue
print('生成结果词的个数:',m)
print('标准文本中词的个数:',n)
print('正确次的个数:',right_num)
p = right_num/m
print('正确率:',p)
calc()
比对结果:

文本表示(tf-idf)
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF。
(1)词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的频率。即词w在文档d中出现的次数count(w, d)和文档d中总词数size(d)的比值。
这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
(2)逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。即文档总数n与词w所出现文件数docs(w, D)比值的对数。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
计算tf-idf:
scikit-learn包进行TF-IDF分词权重计算主要用到了两个类:CountVectorizer和TfidfTransformer。其中
CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在第i个文本下的词频。即各个词语出现的次数,通过get_feature_names()可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果。代码如下:
import os
import time
import numpy as np
import jieba
import jieba.posseg as pseg
import sys
import string
import importlib
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
importlib.reload(sys)
test_file = '词典.txt' # 词典
#sys.setdefaultencoding('gb18030')
#获取文件列表
def getFilelist(path):
filelist = []
files = os.listdir(path)
for f in files:
if f[0] == '.' :
pass
else:
filelist.append(f)
return filelist,path
def divifile(test_file1,test_file2,path,filename):
if not os.path.exists(path):
os.mkdir(path)
with open(test_file1, 'r', encoding='gb18030', ) as f:
dic = f.read()
max_length = 5
test_file3 = path +"/"+filename
h = open(test_file3, 'w+', encoding='gb18030', )
with open(test_file2, 'r', encoding='utf-8', ) as g:
lines = g.readlines()
for line in lines:
max_length = 5
my_list = []
len_hang = len(line)
while len_hang > 0:
tryWord = line[0:max_length]
while tryWord not in dic:
if len(tryWord) == 1:
break
tryWord = tryWord[0:len(tryWord) - 1]
my_list.append(tryWord)
line = line[len(tryWord):]
len_hang = len(line)
test = {
' ','。',',','!','?','=','(',')','1','2','3','4','5','6','7','8','9','0','”','”','-','.','?','"','(',')'}
for t in my_list:
if t not in test:
h.write(t + " ")
h.close()
g.close()
f.close()
#读取已分词好得文档,进行tf_idf计算
def Tfidf(filelist,sFilePath,path):
corpus = [] #存取分词结果
for ff in filelist:
fname = path +"/" +ff
f = open(fname,'r+',encoding='gb18030',)
content = f.read()
corpus.append(content)
f.close()
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
X = vectorizer.fit_transform(corpus) # 将文本转为词频矩阵
tfidf = transformer.fit_transform(X) # 计算tf-idf,
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() ##将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
if not os.path.exists(sFilePath):
os.mkdir(sFilePath)
#将每份文档词语得tf_idf写入tfidffile文件夹中保存
for i in range(len(weight)):
file = (sFilePath+"/"+"%d.txt" %(i))
f = open(file,'w+',)
for j in range(len(word)):
f.write(word[j]+": %.2f\n" %(float(str(weight[i][j]))))
if __name__ == "__main__" :
sFilePath = "D:/PyCharm Community Edition 2020.3/codes/divide_test/tfidffile/体育/test"
segPath = 'D:/PyCharm Community Edition 2020.3/codes/divide_test/segfile/体育/test'
(allfile,path) = getFilelist('分类样本集/体育/test')
for ff in allfile :
test_file2 = path + "/" + ff
divifile(test_file, test_file2, segPath,ff)
Tfidf(allfile,sFilePath,segPath)
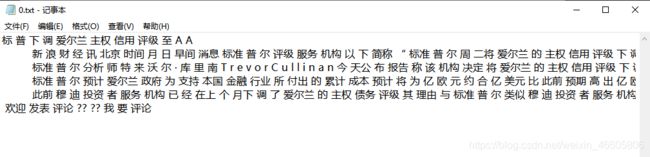
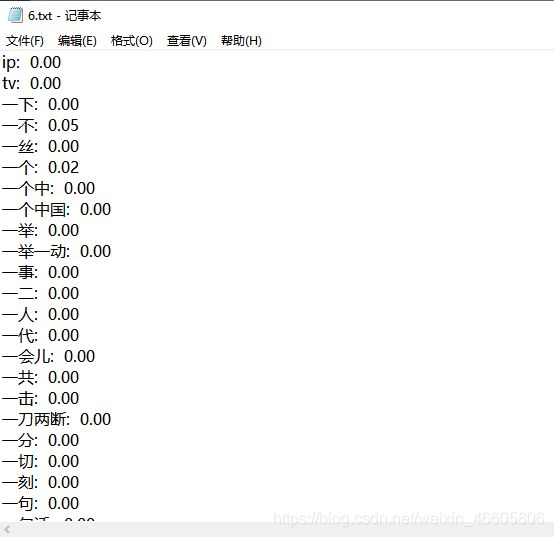
以test文件夹中的100个txt文档为例进行演示,结果如下:
分词的结果保存在segPath路径下,对每次的权值保存在sFilePath路径下
例如:segPath路径下分词的结果:

sFilePath路径下保存的每个词的权重;


利用夹角余弦计算文本相似度
VSM:一个文档可以由文档中的一系列关键词组成,而VSM则是用这些关键词的向量组成一篇文档,其中的每个分量代表词项在文档中的相对重要性。
计算出没偏文章的词的权重向量,然后计算夹角余弦,余弦值越大,代表两篇文章的相似度越高:

import math
import os
#两篇比较文档的路径
test1 = '2020年政府工作报告.txt'
test2 = '2021年政府工作报告.txt'
dict = '词典.txt'
#分词
def divifile(file,dict):
with open(dict, 'r', encoding='gb18030', ) as f:
dic = f.read()
f.close()
max_length = 5
with open(file, 'r+', encoding='utf-8', ) as g:
lines = g.readlines()
g.close()
g = open(file,'w',encoding='utf-8,')
for line in lines:
max_length = 5
my_list = []
len_hang = len(line)
while len_hang > 0:
tryWord = line[0:max_length]
while tryWord not in dic:
if len(tryWord) == 1:
break
tryWord = tryWord[0:len(tryWord) - 1]
my_list.append(tryWord)
line = line[len(tryWord):]
len_hang = len(line)
for t in my_list:
if t == '\n':
g.write('\n')
elif t in range(9):
g.write(t)
else:
g.write(t + " ")
g.close()
#关键词统计和词频统计,以列表形式返回
def Count(resfile):
t = {
}
infile = open(resfile,'r',encoding='utf-8')
f = infile.readlines()
count = len(f)
infile.close()
s = open(resfile,'r',encoding='utf-8')
i = 0
while i < count:
line = s.readline()
#去换行符
line = line.rstrip('\n')
words = line.split(" ")
for word in words:
if word != "" and t.__contains__(word):
num = t[word]
t[word] = num+1
elif word != "":
t[word] = 1
i = i+1
#字典按键值降序
dic = sorted(t.items(),key=lambda t:t[1],reverse=True)
s.close()
return(dic)
#合并文档,得出共同文档
def MergeWord(T1,T2):
MergeWord = []
duplicateWord = 0
for ch in range(len(T1)):
MergeWord.append(T1[ch][0])
for ch in range(len(T2)):
if T2[ch][0] in MergeWord:
duplicateWord = duplicateWord + 1
else:
MergeWord.append(T2[ch][0])
return MergeWord
#得出文档向量
def CalVector(T1,MergeWord):
TF1 = [0]*len(MergeWord)
for ch in range(len(T1)):
TermFrequence = T1[ch][1]
word = T1[ch][0]
i = 0
while i<len(MergeWord):
if word == MergeWord[i]:
TF1[i] =TermFrequence
break
else:
i = i + 1
return(TF1)
def CalConDis(v1,v2,lengthVector):
#计算出两个向量的乘积
B = 0
i = 0
while i < lengthVector:
B = v1[i]*v2[i] + B
i = i + 1
#计算两个向量模的乘积
A = 0
A1 = 0
A2 = 0
i = 0
while i < lengthVector:
A1 = A1 + v1[i]*v1[i]
i = i+1
i = 0
while i < lengthVector:
A2 = A2 + v2[i]*v2[i]
i = i + 1
A = math.sqrt(A1)*math.sqrt(A2)
print(test1+'和'+test2+'两篇文章的相似度 = '+format(float(B)/A,".3f"))
divifile(test1,dict)
T1 = Count(test1)
print('文档1的词频统计如下:')
print(T1)
print()
divifile(test2,dict)
T2 = Count(test2)
print('文档2的词频统计如下:')
print(T2)
print()
#合并两篇文档的关键词
mergeword = MergeWord(T1,T2)
#计算文档向量
v1 = CalVector(T1,mergeword)
print('文档1向量化得到的向量如下:')
print(v1)
print()
v2 = CalVector(T2,mergeword)
print('文档2向量化得到的向量如下:')
print(v2)
print()
#计算余弦距离
CalConDis(v1,v2,len(v1))
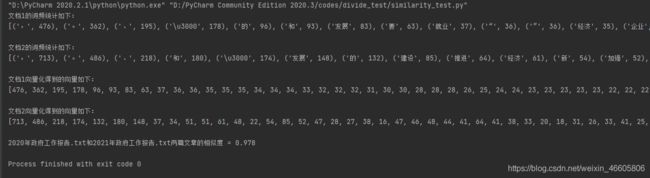
代码效果如下:
2017年和2018年的相似度为99.3%:
2018年和2019年相似度为98.9%:

2019年和2020年相似度为98.3%:
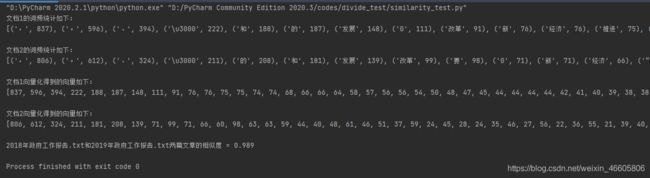
2020年和2021年的相似度为97.8%:

参考链接:
tf-idf:https://www.cnblogs.com/chenbjin/p/3851165.html
相似度:https://www.cnblogs.com/zuixime0515/p/9206861.html