新闻个性化推荐系统
新闻个性化推荐系统
- 一、绪论及背景
-
- 1.1、绪论
- 1.2、背景
- 1.3、发展历史
- 二、需求分析
-
- 2.1、功能需求
-
- 2.1.1、用户功能需求
- 2.1.2、运营功能需求
- 2.1.3、算法功能需求
- 2.2、非功能需求
-
- 2.2.1、性能需求
- 2.2.2、准确性需求
- 2.2.3、稳定性需求
- 2.2.4、可靠性需求
- 三、详细设计
-
- 3.1、系统结构设计
- 3.2、模块设计分析
-
- 3.2.1,系统功能
- 3.2.2,系统服务部署架构
- 3.2.3、数据时序图
- 3.3、重要数据结构设计
-
- 3.3.1,新用户注册
- 3.3.2,新的新闻文本发表
- 3.2.3、给用户推荐新闻文本
- 3.2.4、后台数据分析
- 3.4、程序函数清单
-
- 3.4.1 后端部分函数清单
- 3.4.2、算法部分函数分析
- 成果
一、绪论及背景
1.1、绪论
随着互联网与移动互联网迅速普及,网络上的电影娱乐信息相当庞大,人们对感兴趣的新闻信息的需求越来越大,个性化的新闻推荐成为一个热门。基于个性化推荐算法形成的产品成为人们获取信息的主要途径。网络新闻推荐系统旨在解决新闻信息爆炸的问题,为用户提供个性化的推荐服务。一般来说,新闻语言是高度浓缩的,包含了很多知识实体和常识。
个性化推荐一词最早出现在电商行业,是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。
推荐算法在互联网行业的应用非常广泛,今日头条、美团点评等都有个性化推荐,推荐算法抽象来讲,是一种对于内容满意度的拟合函数,涉及到用户特征和内容特征,作为模型训练所需维度的两大来源,而点击率,页面停留时间,评论或下单等都可以作为一个量化的Y值,这样就可以进行特征工程,构建出一个数据集,然后选择一个合适的监督学习算法进行训练,的都模型后,为客户推荐偏好的内容,如头条,就是咨询和文章。
产生于电子商务领域的个性化推荐技术是基于对用户的偏好进行分析对用户推荐商品的一种创新性的方法,这种方法会大大提高商品成交的纪律,如今个性化推荐的算法已经越来越完善,而且效果越来越好,如果我们将其应用到新闻媒体行业,是否会为这个行业注入新鲜的活力呢?文本通过介绍小组设计过程并结合现存的新闻推荐程序,学习实现个性化推荐算法。
1.2、背景
随着万维网的发展,人们的新闻越度习惯逐渐从传统的报纸、电视等媒介转移到互联网上。在线新闻网站,如Google News和Bing News,从各种来源收集新闻,为读者提供新闻的总览。网络新闻平台的一个最大的问题是,文章的数量可能会让用户望而却步。各类新闻平台都存在信息过载的问题,为了减轻信息过载的影响,关键是要帮助用户确定他们的阅读兴趣,并提出个性化推荐。
互联网在最近十年内出现了爆发性增长,伴随着用户数量迅速的增长的背后是用户数据量的指数级增长,面对着海量的信息,用户往往后感到束手无策,这就是互联网中所谓的信息过载问题。如何帮助用户从海量的信息中获取用户最感兴趣的信息逐渐成为一项热门的研究工作。
信息过载问题传统的解决方案是基于被动响应的服务模式,即用户提出有针对性的需求,服务器端则根据每个用户的具体需求,过滤用户不感兴趣的一些信息,然而这种解决方案也存在一些缺陷,因为它只是向用户提供一些共同兴趣点比较高的信息,例如热门的新闻、电影、音乐等,无法满足用户日益增强的个性化需求,用户获取个性化信息的难度仍然很大。
个性化的解决方案是解决上述问题的主要方法,通过分析用户的历史数据对用户的兴趣爱好进行建模,为每个用户创建一个profile文件,其中记录用户的兴趣表示,并能在和用户不断的交互中学习用户的兴趣,即使更新用户的profile,在适当的时候提供给用户其感兴趣的信息。
近年来个性化信息服务逐渐成为Web技术的热点,推荐系统在实时资讯、新闻、微博、电影、音乐、博客、电商等Web站点中都有大量的应用。通过推荐系统,系统可以有效地解决信息过载问题,分析用户的评分与行为等历史数据建立用户兴趣模型,无需用户特意地填写大量的兴趣调查信息,极大的减轻了用户的负担,使用户的认可度大大增加。
另一方面海量数据的运营压力对每个公司也是非常巨大的,每天都可能会有大量的物品上架,下架。常用的推荐算法一般都基于用户评分历史数据,新上架的物品由于没有任何的访问记录,因此很难将其推荐给对其感兴趣的用户,这种物品有可能一上架后就面临这没有机会被访问的问题,这就是推荐系统中常提到的冷启动问题,因此配合推荐系统的物品运营系统也是非常重要的一个部分,运营人员可以通过人工归类、打标签、写商品描述的方式,为新增的物品提供一些初始的信息,这样物品可以迅速被推荐引擎挖掘,并推荐给感兴趣的用户。
1.3、发展历史
1995年3月,卡耐基·梅隆大学的Robert Armstrong等人在美国人工智能协会上提出了个性化导航系统Web Watcher;斯坦福大学的Marko balabanovic等人在同一会议上推出了个性化推荐系统LIRA
1995年8月,麻省理工学院的Henry Lieberman在国际人工智能联合大会(IJCAI)上提出了个性化导航智能体Litizia;
1996年,Yahoo推出了个性化入口My Yahoo;
1997年,AT&T实验室提出了基于协同过滤的个性化推荐系统PHOAKS和Referral Web;
1999年,德国Dresden技术大学的Tanja Joerding实现了个性化电子商务原型系统TELLIM;
2000年,NEC研究院的Kurt等人为搜索引擎CiteSeer增加了个性化推荐功能;
2001年,纽约大学的Gediminas Adoavicius和Alexander Tuzhilin实现了个性化电子商务网站的用户建模系统1:1Pro;
2001年,IBM公司在其电子商务平台Websphere中增加了个性化功能,以便商家开发个性化电子商务网站;
2003年,Google开创了AdWards盈利模型,通过用户搜索的关键词来提供相关的广告。AdWords的点击率很高,是Google广告收入的主要来源。2007年3月开始,Google为AdWords添加了个性化元素。不仅仅关注单词搜素的关键词,而是对用户近期的搜索历史进行记录和分析,据此了解用户的喜好和需求,更为请确地呈现相关的广告内容。
2007年,雅虎推出了SmartAds广告方案。雅虎掌握了海量的用户信息,如用户的性别、年龄、收入水平、地理位置以及生活方式等,再加上对用户搜索、浏览行为的记录,使得雅虎可以为用户呈现个性化的横幅广告。
2009年,Overstock(美国著名的网上零售商)开始运用ChoiceStream公司制作的个性化横幅广告方案,在一些高流量的网站上投放官品广告。Overstock在运行这项个性化横幅广告的夫妻就取得了惊人的成果,公司称:“广告的点击率是以前的两倍,伴随而来的销售增长也高达20%至30%”
2009年7月,国内首个个性化推荐系统科研团队北京百分点信息科技有限公司成立,该团队专注于个性化推荐、推荐引擎技术与解决方案,在其个性化推荐引擎技术与数据平台上汇集了国内外百余家知名电子商务网站与资讯类网站,并通过这些B2C网站每天为数以千万计的额消费者提供实时智能的商品推荐。
2011年8月,纽约大学个性化推荐系统推荐团队在杭州成立载言网络科技有限公司,在传统协同滤波推荐引擎基础上加入用户社交信息和用户的隐性反馈信息,包括网页停留时间、产品页浏览次数,鼠标滑动,链接点击等行为,辅助推荐,提出了迄今为止最为精准的基于社交网络的推荐算法。团队目前专注于电商领域个性化推按服务以及商品推荐服务社区——e推荐。
2011年9月,百度世界大会2011上,李彦宏讲推荐引擎与云计算、搜索引擎并列为未来互联网重要战略规划与发展方向。百度新首页将逐步实现个性化,智能地推荐出用户喜欢的网站和经常使用的APP。
二、需求分析
推荐系统越来越成为互联网中不可或缺的一部分,一个成熟的推荐系统中一般由都会有用户与运营专员两个角色,用户通过在推荐系统中注册账户来在系统中唯一的标识自己,新的用户注册完毕后需要填写一些初始化的兴趣信息,以帮助系统解决用户没有任何历史数据记录而产生的冷启动问题,用户可以通过点击感兴趣的新闻与推荐系统产生交互,推荐系统会储存用户的历史操作数据,并利用数据分析引擎对历史数据分析建模为用户生成推荐列表;另一个比较重要的角色就是运营人员,运营人员负责更新新闻数据集,每天都有大量的新闻发行,运营人员需要收集相关的新闻资料,将其输入进系统中,并填写一定的标签,以方便推荐引擎即时的发掘新的电影并将其推荐给感兴趣的用户。
2.1、功能需求
2.1.1、用户功能需求

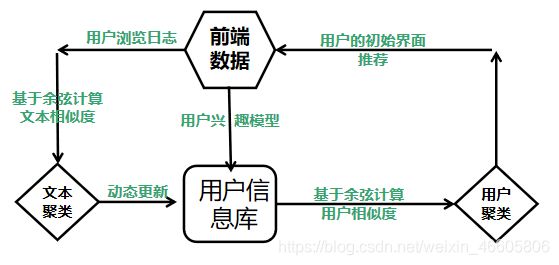
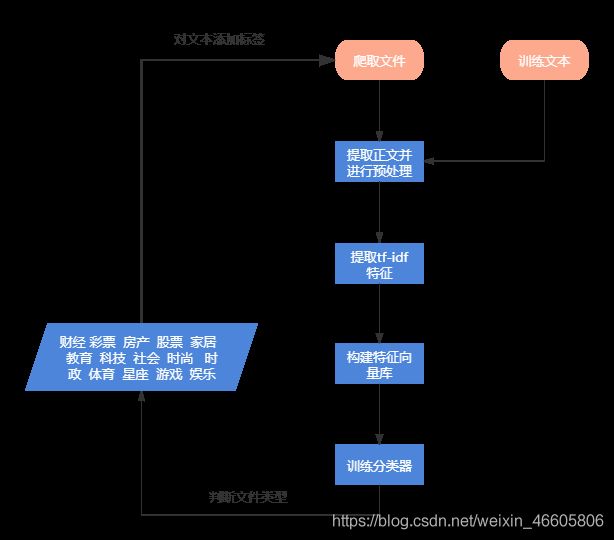
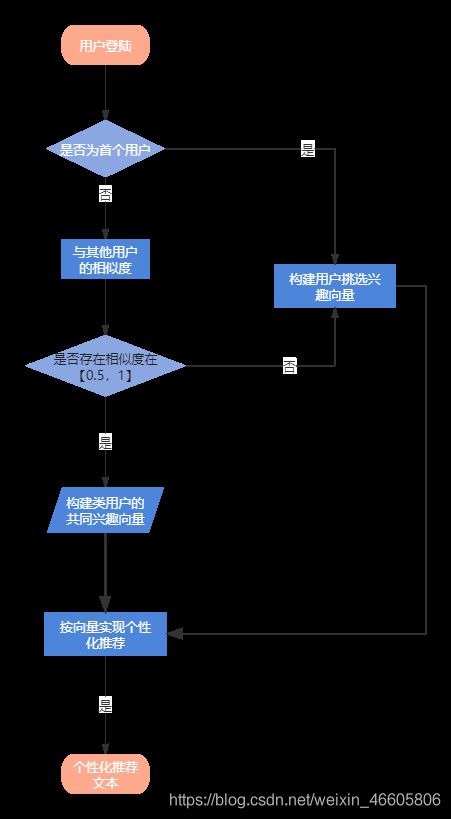
系统提供给用户的初始界面是注册登陆界面,用户按照流程首次注册之后,用户的username和password便会通过与后端相连接的mysql进行存储,登录成功之后,会由用户首先挑选感兴趣的话题,我们小组提供了十四个类型新闻,包括:财经 彩票 房产 股票 家居 教育 科技 社会 时尚 时政 体育 星座 游戏 娱乐。基于用户挑选的类型,计算新用户与已存用户的聚类相似度,基于高相似用户之间的兴趣相同点对新用户推荐首次页面。之后用户对于新闻的浏览记录存储在日志并返回给后端,后端存储与mysql数据库中。算法设计基于mysql存储的浏览记录对用户进行动态建模,并随着用户刷新页面动态返回用户的兴趣最大化。在之后的登陆时,就可以直接基于用户唯一的兴趣模型进行个性化推荐,并且也会动态的记录用户的浏览日志并进行分析,解决用户的兴趣随时间变化而转移的问题。
2.1.2、运营功能需求
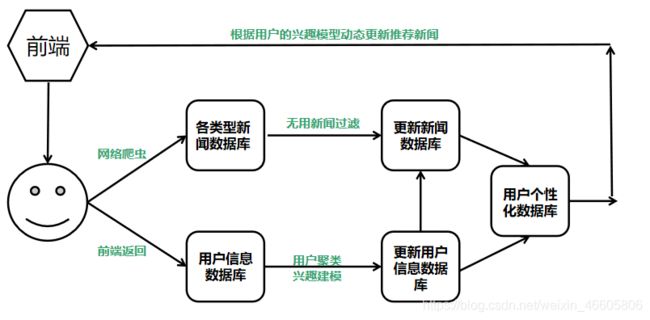
后端运营者首先通过网络爬虫爬取各个类型的新闻数据,然后构建一个新闻数据库。后端接受用户用于注册登陆的信息,构建用户信息库,在用户之后登陆时,便可以直接遍历数据库进行比对,就可以检查用户信息的正确性。在用户浏览一部分日志之后,前端将日志信息返回给后端,后端运营机器学习的算法,重新构建用户的兴趣模型,然后再有过滤性的爬取各个类型的新闻,构建每个用户的个性化新文库。之后返回给前端,用于实时生成个性化推荐页面。
2.1.3、算法功能需求
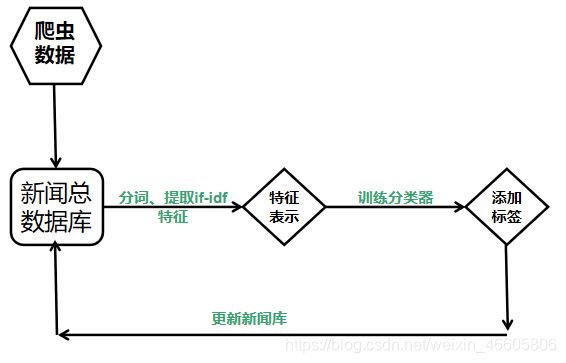
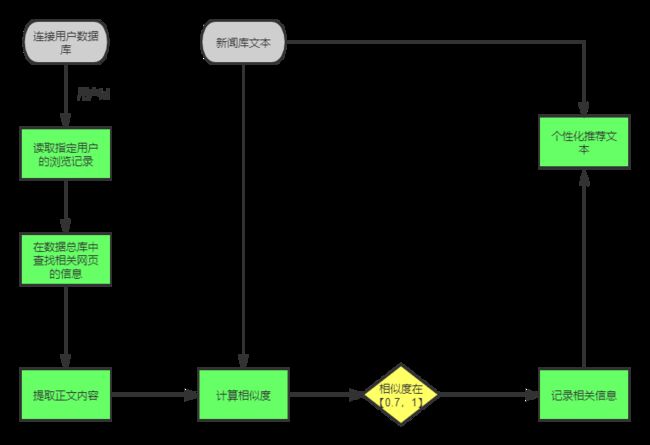
后端首先从网络平台上爬取无标签的各种新闻,之后经过分词、特征提取等使用训练好的分类器对新闻进行分类,并且给每个新闻添加一个类别标签。然后用于重新更新新闻库。由于首次登陆页面的用户没有浏览记录,唯一获取兴趣点的便是首次挑选的兴趣标签,通过余弦计算该用户与已有用户的相似度,相似度大于某一阈值的用户,认为新用户与该类用户属于同一类别,然后基于该团体的兴趣标签生成新用户的首次推荐新闻页面。在用户浏览过一定量的新闻之后,通过前端的日志记录,返回给后端之后,后端给其兴趣重新建模分析,之后基于文本内容计算内容的相似度,给用户推荐的页面就是基于文本内容的相似重新推荐新闻。
2.2、非功能需求
2.2.1、性能需求
1)内存的容量
由于系统中涉及到大量的用户,新闻文本相似度计算,因此系统的内存容量需要尽可能的满足存储系统计算的中间数据,如用户相似度矩阵,文本相似度矩阵,用户的浏览日志列表,等信息。
2)外存的容量
外存的容量也相当重要,大部分的浏览记录与文本信息都需要存在数据库中,系统外存需要有足够的空间满足这些存储要求。
3)查询用户推荐列表速度
用户点击网页,浏览新闻的速度比较快,系统需要在短暂的时间内计算出推荐列表并返回给用户浏览器,让用户及时地看到推荐给其的列表记录,这样用户才会对推荐的列表进行反馈,并进行后续的与推荐系统的交互。
2.2.2、准确性需求
推荐系统推荐给用户的电影列表需要有足够的准确率,这样才能增强用户的认同感,一个好的推荐系统,准确性一定是一个重要的指标。
2.2.3、稳定性需求
推荐系统的各种算法都有其各自的优缺点,例如,过滤算法与基于用户相似度的冷启动问题与数据稀疏性问题,当浏览记录不足给用户准确的推荐,而基于内容过滤的算法则不存在这一问题,另一方面,在相似度计算问题上,有的推荐是有对称性的,例如喜欢《数据挖掘概念与技术》这本书的人可能会喜欢《数据挖掘原理》,而喜欢《数据挖掘原理》也喜欢《数据挖掘概念与技术》,但是在购物篮问题中,买了装修地板的人很有可能也去买装修的电器,而买电器的人不一定会去买装修地板,对于前者使用聚类相似度算法比较合适,因为它是对称的,而后者使用文本相似度算法比较合适。综上所述针对具体情况选择不同的推荐算法很重要,这对大大提高推荐系统的推荐准确度非常有帮助,还能降低系统模块之间的耦合度。
2.2.4、可靠性需求
推荐系统的运营模块是一个非常重要的环节,数据不一致导致的问题很有可能使得用户无法正常地使用推荐系统,另外,大量的数据需要运营,新的新闻都需要运营人员迅速的加入推荐系统中,利用运营专员提供的初始的新闻信息,将这些新闻文本推荐给可能感兴趣的用户,用来提高推荐系统的竞争力,特别是在目前的移动网站的建设中,可靠性的要求非常高,对各种移动平台的支持,需要特定大小的图片,特定布局的网页设计才能使得各种平台上的用户使用起来不出问题。
三、详细设计
3.1、系统结构设计
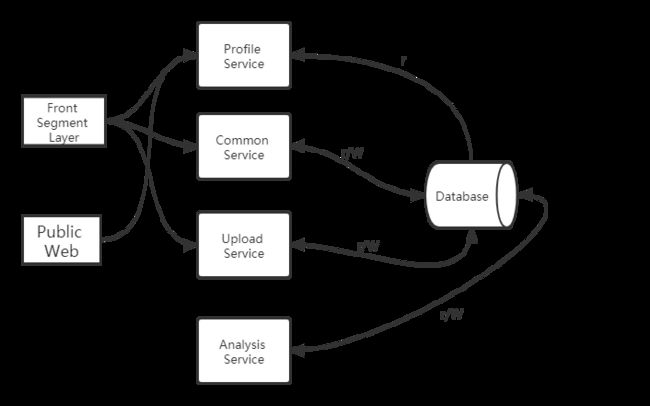
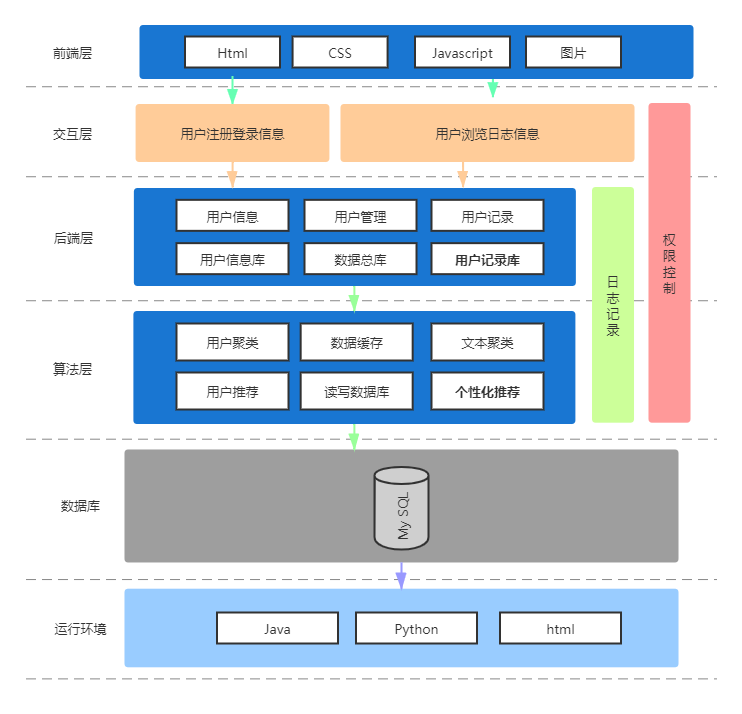
本系统的架构设计如下图3-1所示:
前端层主要是负责前端页面展示,使用Html,CSS,JavaScript等技术实现,用户可以挑选喜欢的新闻类型,也可以随便浏览喜欢的新闻。前端还有相关业务的服务和个性化推荐服务。
交互层主要是负责前端和后端的数据交互,前端传给后端的信息包括用户用于注册登陆的username和password,并实时记录用户的浏览日志,待用户刷新页面时发送给后端相关文件。后端发送给前端的文件主要为根据用户的反馈计算出的相关新闻推荐。
Common Service提供用户获取用户推荐新闻列表,获取根据新闻推荐相关新闻列表的功能。由于Common Service使用频率比较高,因而使用python实现并对外提供python调用接口,供Java调用。Analysis Service是一个定时触发的线程,该线程定期分析用户的日志数据获取用户的浏览记录,更新用户数据库,重新计算用户与用户,新闻文本与文本之间的相似度,更新用户与新闻的profile信息。
3.2、模块设计分析
3.2.1,系统功能
新闻个性化推荐系统模块的功能分为前端层、交互层、后端层、算法层、数据库、运行环境等六个层次。前端层提供展现给用户的页面设计;交互层负责前端和后端的信息传输;后断层实现存储前端返回的信息,并把相关的信息存储于数据库中;算法层包括用户聚类算法和文本聚类算法,并根据具体情况采用不同的推荐算法;数据库存储用户的基本信息以及用户浏览日志数据;运行环境包括python、java、html等。
用户信息管理
推荐系统中新用户注册后会填写注册信息与一些个人兴趣爱好标签信息,随后该用户可以进行正常的浏览等其他的操作,随着系统与用户的交互,系统逐渐获取用户的兴趣的兴趣爱好。用户可以对自己的标签信息进行管理,通过对自己喜爱的新闻类型多次浏览等操作,系统会将用户的浏览行为存入日志,并调用数据分析引擎对用户的行为进行分析,更新用户的profile文件。
新闻信息运营管理
推荐系统日常的运营是由运营人员负责的,运营人员每天会将新的新闻爬取到数据库中,并根据分类器实现贴标签,以方便推荐系统更好的解决冷启动问题,将这些还未被浏览的新闻更够有机会准确的推荐给感兴趣的用户
推荐引擎
推荐引擎时推荐系统中最核心的一部分,通过对用户挑选的兴趣和用户每天的浏览记录,利用余弦聚类算法计算出和用户有较高相似度的其他用户,并结合二者相同的兴趣标签,可以更准确的推荐所喜欢的标签。对于新注册的用户,推荐系统会强制用户选择一些其感兴趣的标签和新闻分类,随后推荐引擎会根据用户提供的这些标签信息,获取属于该标签的一些热点的新闻,作为用户初次浏览的页面。
数据分析引擎
数据分析引擎对用户的操作日志进行分析,获取用户的操作记录并将该信息爬取为推荐引擎的原始数据来源,对数据进行处理之后,存入数据库中。当用户的兴趣发生变化时,这些将会反映在用户的浏览记录中,数据分析引擎会捕捉到,并重新计算用户的profile,并更新用户和相关新闻的profile文件,这样推荐引擎将会根据新的profile文件为用户生成新的推荐列表。
3.2.2,系统服务部署架构
个性化新闻推荐系统的基本架构如下图3-3所示:
用户通过智能手机、移动终端、或者PC登陆系统,Web服务器会将用户的注册信息和用户的操作记录提高给日志服务器,日志服务器中记录的日志主要有用户的浏览信息:用户浏览过的页面、用户浏览页面的时间等。数据分析服务器用于从日志服务器中获取一段时间的日志文件,对这些日志文件进行分析重新计算用户之间的相似度,新闻文本之间的相似度并更新相关用户的profile文件。推荐引擎在用户挑选兴趣标签、浏览页面时触发,Web服务器获取用户浏览页面的信息,将这些信息提交给推荐引擎,推荐引擎根据用户和新闻文本的信息,同时从数据分析服务器中获取相应的相似度信息和用户profile文件,根据相应的推荐算法计算推荐列表给用户推荐。

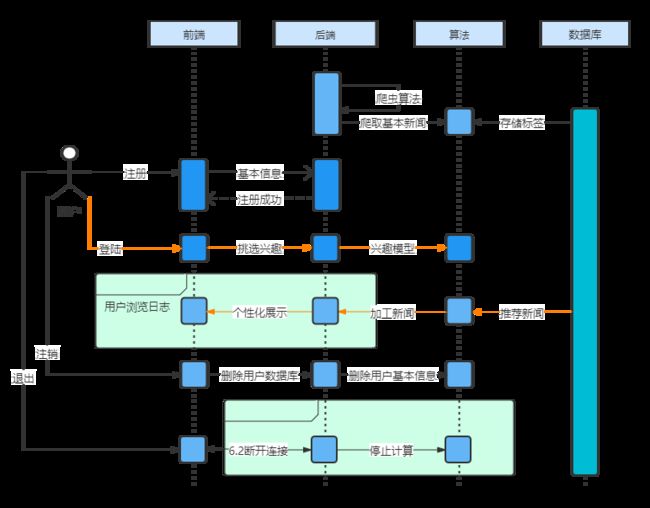
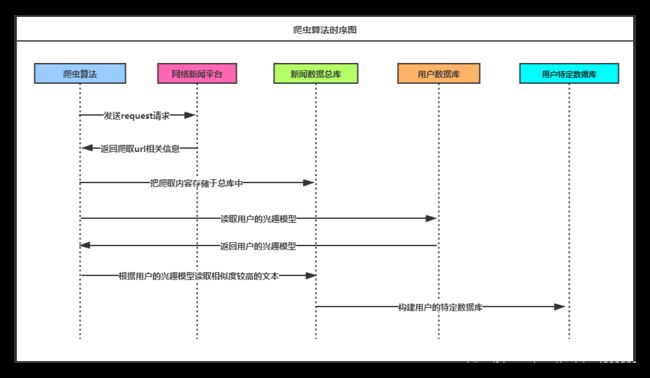
3.2.3、数据时序图
时序图是一种图形化的系统模型,它在一张图中展示信息系统的主要要求,即输入、输出、处理(过程),数据存储,如下图3-4。
1)新用户注册
新用户注册后,会建立新的用户profile文件,根据用户填写的兴趣标签更新用户的相似度列表与用户的推荐列表。
2)新的新闻发表
新闻发表后,推荐系统会添加新的新闻标签,根据运营人员填写的新闻的分类更新相应的新闻文本相似度数据,计算相应的感兴趣的用户类表,更新这些用户的推荐列表信息,并在这些用户登陆系统后给其推荐。
3)用户挑选兴趣
用户在初次登陆时,会强制用户挑选感兴趣的标签,并进行提交之后会实时存储在用户的数据库中,后端算法读取数据库中所选择的兴趣标签会对用户进行建模,方便算法基于用户聚类的特点对新注册用户个性化推荐新闻。
4)用户浏览新闻网页
用户的兴趣兴趣反映在用户对新闻的溃烂行为,当用户从推荐列表中选取了感兴趣的电影后,相关数据就会存储在数据库中,并发送到数据库中,方便后端算法对数据进行计算,对用户的兴趣模型进行重新建模。
5)用户注销帐号
当用户对该网站不再满足时,选择注销帐号时,提交相关请求后,前端会将请求发送给后端,后端会及时从数据库中删除用户的相关信息,数据库中不再存在用户的全部信息,用户之后采用相同的信息进行注册时,在后端数据库中可以及时存储用户的信息,并建立用户的兴趣模型,与之前的数据模型不会有任何的关系,对用户重新建模,重新进行新闻文本推荐。
3.3、重要数据结构设计
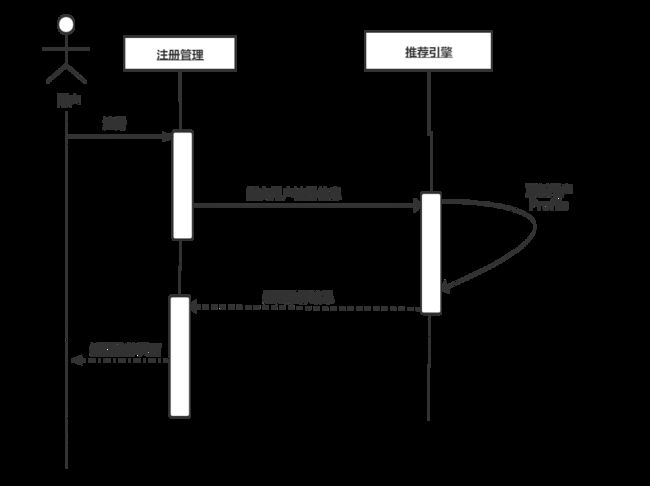
3.3.1,新用户注册
新用户注册时,用户通过Web页面向Web服务器提交用户的注册信息,这其中包括用户的基本信息和用户的初始兴趣标签,Web服务器会将这些信息提交给推荐系统的注册管理模块,注册管理模块提取出用户的基本信息存入数据库中,将标签信息等有助于获得用户兴趣的信息提交给推荐引擎,推荐引擎查询数据库,获取具有相似标签的热门新闻和比较热点的新闻作为推荐列表返回给用户Web页面,这样用户在注册完毕后即可享受到推荐系统给其推荐的电影。用户的初始兴趣模型即为选取的初始标签,后期的兴趣模型与用户浏览的日志文件相关,对用户进行实时的兴趣建模,尽量提高用户兴趣的准确性。
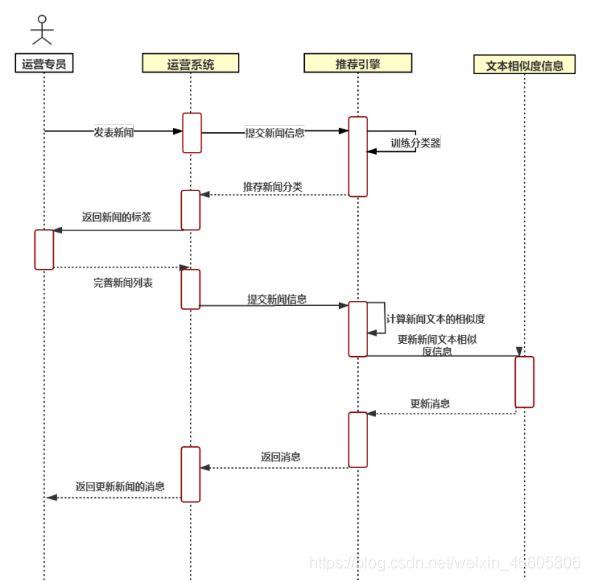
3.3.2,新的新闻文本发表
推荐系统一般都有一个专职的营运专员,负责推荐系统的日常运营工作,包括爬取新的新闻文本,完善爬取文本的信息,因而推荐系统有一个很重要的分支模块就是后台运营系统。当一个新的新闻发表时,运营专员将新闻的基本信息通过后台运营系统提交,这些信息包括新闻的标题、发表日期、出处、连接、作者等。后台运营系统将相应的新闻文本信息存入数据库中,接着会向推荐引擎提交新发表的新闻的基本i西南西,推荐引擎将会按照特定算法给文本进行分类,添加标签信息,运营人员根据分类的标签提交给推荐引擎,推荐引擎根据新的文本标签,重新计算文本的相似度信息和profile信息,更新数据库中的记录。并获取对该文本感兴趣的用户列表,将该新闻文本加入到这些用户的推荐列表中。
3.2.3、给用户推荐新闻文本
推荐系统中使用的最为频繁的功能就是获取用户的推荐列表这一功能,在这个过程中,用户首先会通过浏览器向Web服务器发送一个获取推荐列表的请求,Web服务器会提取出这个请求中的用户新闻信息将其转发给推荐系统的应用服务,应用服务接着调用推荐引擎的获取推荐列表功能,推荐引擎收到调用请求后查询到相应的用户的兴趣模型和电影的标签,利用推荐算法计算推荐列表,当用户量大时,推荐系统会维护一个用户的推荐列表数据库,直接从数据库中读取推荐列表信息将其推荐给用户,以避免耗时的计算过程,将耗时的计算过程定期在用户每次提交个性化申请时。
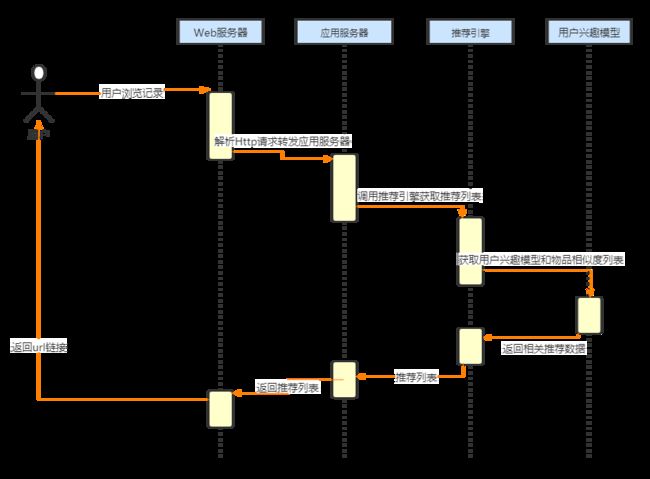
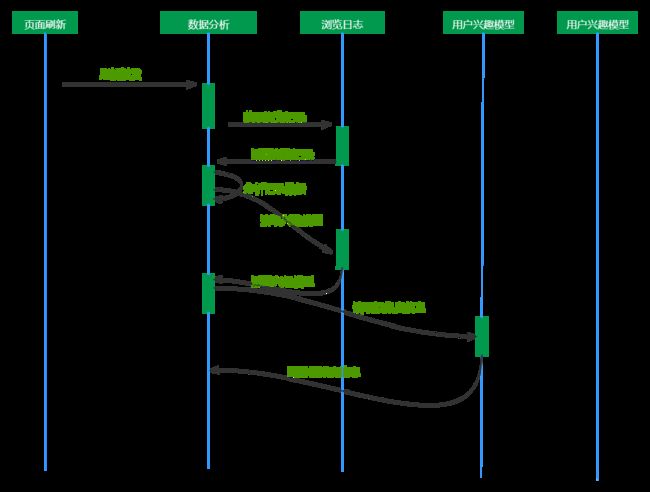
3.2.4、后台数据分析
后台数据分析这个过程主要是用于在用户访问时,对用户的浏览日志数据进行分析整理,调用分类器算法对新的文本进行分类,调用聚类算法,计算用户的兴趣模型,用户刷新页面时,数据提交会被触发,向后端发送浏览日志记录,后端会同步读取浏览的相关的网页内容并找到内容相似度较高的相关文本,并返回给前端相关的推荐数据,用于生成用户的刷新页面。
3.4、程序函数清单
3.4.1 后端部分函数清单
1)函数名——所在文件名 Java类:
Logininervelet
RegisterServelet
ClickServelet
CheckboxServelet
infoServelet
getRequestDispatcher
setCharacterEncoding
getParameters
ifTableNull
2)函数功能
RegisterServelet:注册功能的实现
Logininervelet:登录功能的实现
CheckboxServelet:兴趣爱好多选并返回到后台
InforServelet:将内容展示到前端,即将信息反馈到html页面让用户能够看到
ClickServelet:记录用户是否点击过当前页面
getRequestDispatcher:实现页面的跳转
sendRedirect:实现页面的跳转
setCharacterEncoding:编码格式定义(避免乱码,一般是UTF-8)
WriteSql(我们定义的一个类)类中的函数:
Connection:与数据库的连接
Register:sql语句解决注册过程中在数据库中创建新的元素。
Seek:sql查询登录过程中的ID和密码
Seekuser:注册过程查询数据库中的ID(就是为了确认是否现在输入的ID数据库中已经存在了)
GetPrameters:用于读取提交表单中的值,即获取POST/GET传递的参数值。
ifTableNull:判断表中14个hobby是否全为空(全为0)
3)参数说明
由于参数传递较多,我们主要介绍关键的参数。
RegisterServelet:regid注册名字 regpassword1 regpassword2分别是两次输入的密码,需要两次输入的密码都相同才能注册成功。
Register:id password
Logininervelet:id password 名字和密码
Seek:id password bool型 返回 true 和false
seekuser:id password bool型 返回 true 和false
getPrameter: string name name要获取参数的名称,返回值指定名称的参数
ifTableNull:输入id 返回true 或者 false bool
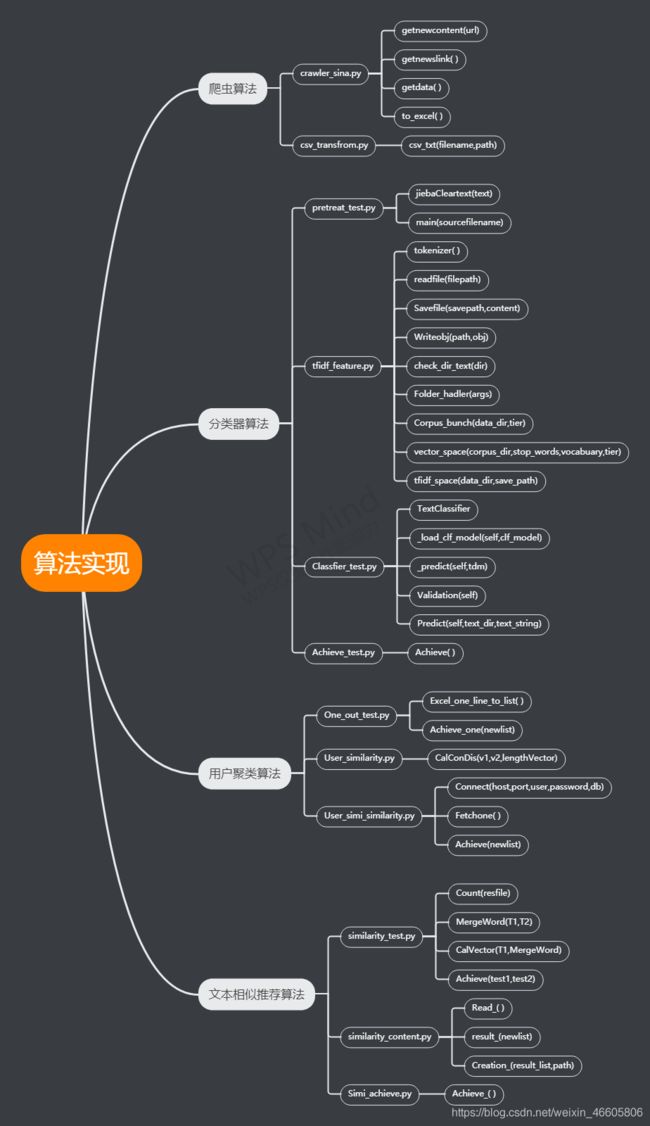
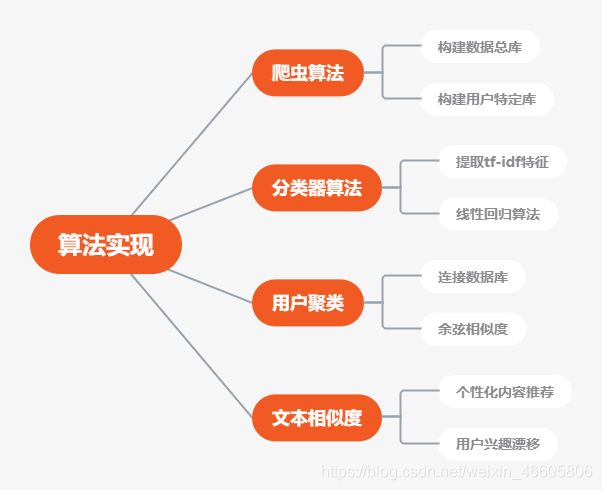
3.4.2、算法部分函数分析
成果
前端工程师:卢潇、范世炜
后端工程师:孙泰成、李兆腾
算法工程师:汤博