容器化之路Docker网络核心知识小结,理清楚了吗?
Docker网络是容器化中最难理解的一点也是整个容器化中最容易出问题又难以排查的地方,加上使用Kubernets后大部分人即使是专业运维如果没有扎实的网络知识也很难定位容器网络问题,因此这里就容器网络单独拿出来理一理。
先了解一下Docker的一点基础架构知识,Docker 技术架构图:
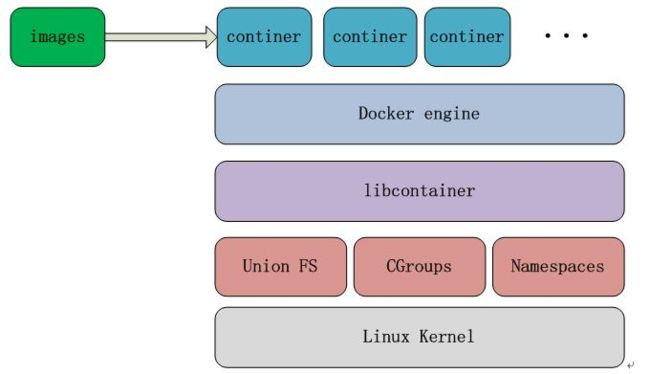
Docker是不能直接在 Windows 平台上运行的,只支持 linux 系统,因为Docker 依赖 linux kernel 三项最基本的技术。
- Namespaces 充当隔离的第一级,是对 Docker 容器进行隔离,让容器拥有独立的 hostname,ip,pid,同时确保一个容器中运行一个进程而且不能看到或影响容器外的其它进程 。
- Cgroups 是容器对使用的宿主机资源进行核算并限制的关键功能,比如 CPU, 内存, 磁盘等。
- Union FS 主要是对镜像也就是 image 这一块作支持,采用 copy-on-write 技术,让大家可以共用某一层,对于某些差异层的话就可以在差异的内存存储,
- Libcontainer 是一个库,是对上面这三项技术做一个封装。
- Docker engine 用来控制容器 container 的运行,以及镜像文件的拉取。
Docker的工作原理:每个容器都在自己的命名空间中运行,但使用与所有其他容器完全相同的内核。发生隔离是因为内核知道分配给进程的命名空间,并且在API调用期间确保进程只能访问其自己的命名空间中的资源。
Docker部署关键配置
daemon.json文件
指定私有仓库地址insecure-registries,否则拉取镜像出现问题:

1 {
2 "data-root": "/docker/data",
3 "exec-opts": ["native.cgroupdriver=cgroupfs"],
4 "registry-mirrors": [
5 "https://docker.mirrors.ustc.edu.cn",
6 "http://hub-mirror.c.163.com"
7 ],
8 "hosts": ["tcp://0.0.0.0:2375", "unix:///var/run/docker.sock"],
9 "insecure-registries": ["192.168.0.23:5000"],
10 "max-concurrent-downloads": 10,
11 "live-restore": false,
12 "log-driver": "json-file",
13 "log-level": "warn",
14 "log-opts": {
15 "max-size": "50m",
16 "max-file": "1"
17 },
18 "storage-driver": "overlay2"
19 }
1.指定data-root 配置容器数据地址,在服务器中单独规划磁盘空间,避免占用系统空间
2.指定hosts,放开2375对外接口
3.Docker使用storage driver(存储驱动程序)来管理image和container的数据,要使用overlayfs,要确保系统的内核版本大于等于3.18,overlay要比aufs和device mapper快一点,OverlayFS仅有两层,镜像中的每一层对应/var/lib/docker/overlay中的一个文件夹,文件夹以该层的UUID命名。然后使用硬连接将下面层的文件引用到上层。这在一定程度上节省了磁盘空间。
4.指定文件驱动native.cgroupdriver=cgroupfs控制的资源主要包括CPU、内存、block I/O、网络带宽等,也可以指定为systemd,这里要注意的是后续布署k8s时要与k8s设置的文件驱动操持一致,否时会报错:
failed to create kubelet: misconfiguration: kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
需要修改kubelet.service Environment中添加--cgroup-driver=cgroupfs或systemd
docker.service文件
[Unit] Description=Docker Application Container Engine Documentation=http://docs.docker.io [Service] Environment="PATH=/docker/bin:/bin:/sbin:/usr/bin:/usr/sbin" ExecStart=/docker/bin/dockerd ExecStartPost=/sbin/iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT ExecReload=/bin/kill -s HUP $MAINPID Restart=always RestartSec=5 LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity TimeoutStartSec=0 Delegate=yes KillMode=process [Install] WantedBy=multi-user.target
docker 从 1.13 版本开始,将`iptables` 的`filter` 表的`FORWARD` 链的默认策略设置为`DROP`,从而导致 ping 其它 Node 上的 Pod IP 失败,因此必须在 `filter` 表的`FORWARD` 链增加一条默认允许规则 `iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT`
通过了解以上docker基础框架后排查网络问题思路会更清晰。
Docker容器的网络模型
Docker容器网络的原始模型主要有三种:Bridge(桥接)、Host(主机)及Container(容器)
Docker默认使用Bridge+NAT的通讯模型,Bridge模型借助于虚拟网桥设备为容器建立网络连接,Docker守护进程首次启动时,它会在当前节点上创建一个名为docker0的桥设备,并默认配置其使用172.17.0.0/16网络,此主机上启动的Docker容器会连接到这个虚拟网桥上。
当容器启动时在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中,从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关,这样同一个host的容器之间就可以通过docker0通信了,可以通过brctl show命令查看。
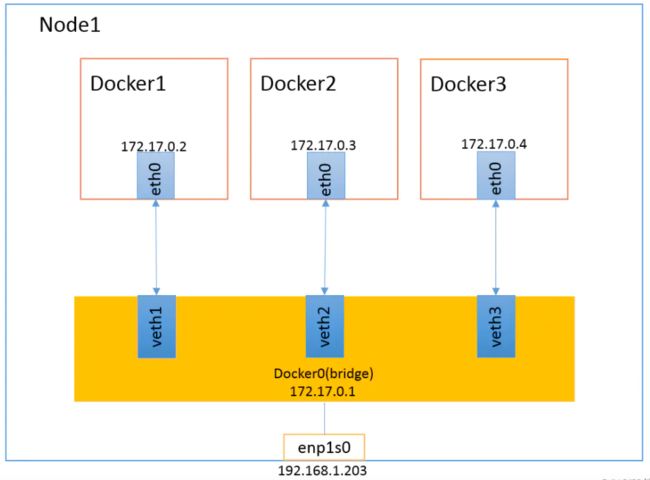
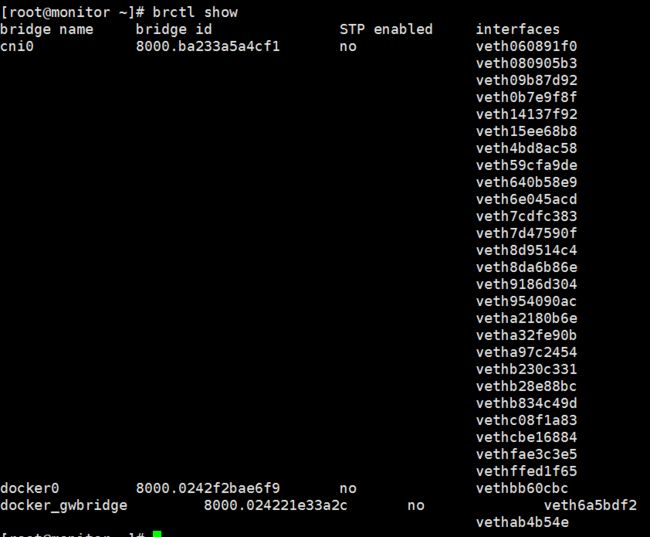
容器与外部网络间的通信
为了解决容器访问外部网络,docker引入NAT,通过iptables规则控制,网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。创建MASQUERADE规则:
查看nat表
# iptables -t nat -S
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
数据包流程
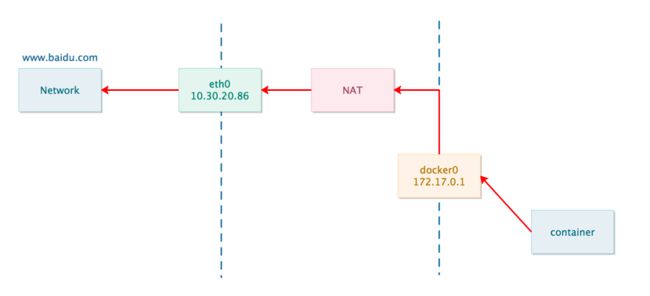
这条规则将所有从容器发出的、目的地址为Host外部网络的包的IP都修改成Host的IP,并由Host发送出去。
外部网络访问容器
Docker容器是通过dnat映射或docker-proxy服务对外提供访问,如指定端口映射:docker run -p 9001:9000。
使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能,为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
可以使用iptables -t nat -vnL查看。
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 9001 -j DNAT --to-destination 172.17.0.2:9000
外部访问外部服务器访问10.3.20.87:9001
匹配到DNAT规则,访问到容器-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 9001 -j DNAT --to-destination 172.17.0.2:9000
本机访问127.0.0.1:9001 没有匹配到任何iptable,走docker-proxy
另外容器要访问外部网络需要宿主机进行转发,要在宿主机中打开转发设置:
#sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
为0说明没有开启,需要手动打开。
安装Docker时,它会自动创建三个网络。
#docker network ls
NETWORK ID NAME DRIVER
7fca4eb8c647 bridge bridge
9f904ee27bf5 none null
cf03ee007fb4 host host
bridge网络代表docker0所有Docker安装中存在的网络,默认将容器连接到此网络。可以使用该--network标志来指定容器应连接到哪些网络。
使用host模式,这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
创建自定义网桥时可指定网段圈定容器ip范围避免冲突,如:
docker network create -d macvlan \
--subnet=172.16.86.0/24 \
--gateway=172.16.86.1 \
-o parent=eth0 pub_net
Docker跨主机容器间网络通信
Docker默认的网络环境下,单台主机上的Docker容器可以通过docker0网桥直接通信,而不同主机上的Docker容器之间只能通过在主机上做端口映射进行通信,
如果能让Docker容器之间直接使用自己的IP地址进行通信,会解决很多问题。按实现原理可分别直接路由方式、桥接方式(如pipework)、Overlay隧道方式(如flannel、ovs+gre)等。
一般选用Overlay隧道方式,核心是通过Linux网桥与vxlan隧道实现跨主机划分子网。
K8S网络模型CNI插件主流使用Flannel ,功能是让集群中的不同节点主机重新规划IP地址的使用规则,使得不同节点上的容器能够获得"同属一个内网"且"不重复的"IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。flannel提供hostgw实现,避免vxlan实现的udp封装开销,估计是目前最高效的;
Flannel实质上是运行在一个网上的网(应用层网络),并不依靠ip地址来传递消息,而是采用一种映射机制,把ip地址和identifiers做映射来资源定位。也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式。
原理是每个主机配置一个ip段和子网个数。例如,可以配置一个覆盖网络使用 10.100.0.0/16段,每个主机/24个子网。因此主机a可以接受10.100.5.0/24,主机B可以接受10.100.18.0/24的包。
Flannel使用etcd来维护分配的子网到实际的ip地址之间的映射。对于数据路径,flannel 使用udp来封装ip数据报,转发到远程主机。选择UDP作为转发协议是因为他能穿透防火墙。例如,AWS Classic无法转发IPoIP or GRE 网络包,是因为它的安全组仅仅支持TCP/UDP/ICMP。
Flannel使用etcd存储配置数据和子网分配信息。Flannel启动之后,后台进程首先检索配置和正在使用的子网列表,然后选择一个可用的子网,然后尝试去注册它。
etcd也存储这个每个主机对应的ip。Flannel使用etcd的watch机制监视/coreos.com/network/subnets下面所有元素的变化信息,并且根据它来维护一个路由表。为了提高性能,Flannel优化了Universal TAP/TUN设备,对TUN和UDP之间的ip分片做了代理。
默认的节点间数据通信方式是UDP转发.在Flannel的GitHub页面有如下的一张原理图:
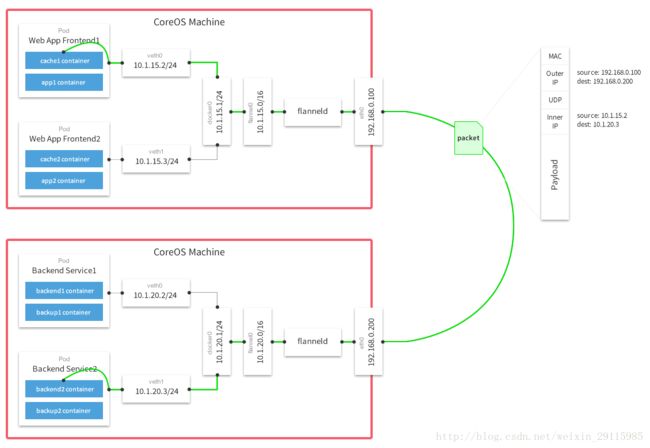
具体的介绍可参考 之前的文章 Kubernetes集群部署关键知识总结 地址 https://www.cnblogs.com/zhangs1986/p/10749721.html
注意:flannel 使用 vxlan 技术为各节点创建一个可以互通的 Pod 网络,使用的端口为 UDP 8472,需要开放该端口。
本文所用到Docker版本为19.03.15
Kubernetes 1.20 版本开始将弃用 Docker
kubelet目前推荐方式是直连containerd。

被去掉的部分是删除 dockershim(Dockershim 作用:把外部收到的请求转化成 Docker Daemon 能听懂的请求,让 Docker Daemon 执行创建、删除等容器操作。)
可以用Containerd 或 Podman 替换。