拿爱奇艺练手Python爬虫,是在法律边缘试探吗?爬虫技巧学习
本案例进行一下中场休息,给大家带来一篇如何通过开发者工具定位接口的案例。
目标站点分析
本次要采集的是爱奇艺的 《理想之城》,采集该电视剧的评论内容。
首先通过下拉发现评论的加载为异步加载,即通过服务器调用接口进行返回,顾查找到对应接口是核心突破点。
但是当启用开发者工具之后,发现页面存在太多的请求,视频加载,广告加载,图片加载非常多,导致评论的接口很难被检测出。

这里首先用到的第一个技巧是,通过某一评论内容,检索接口可能出现的位置。
在开发者工具标题栏按下 Ctrl+F 键,唤醒搜索窗口,如下图所示:
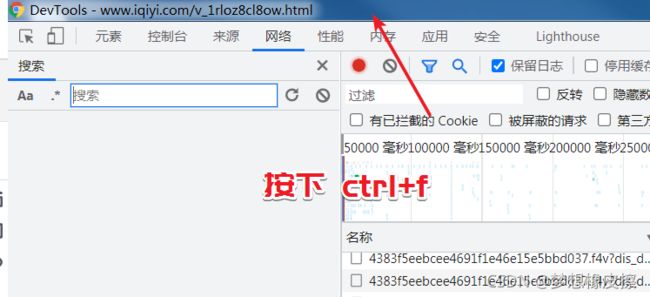
然后输入任意评论内容,按下回车键,即可查找该数据存在的接口,如下图所示:
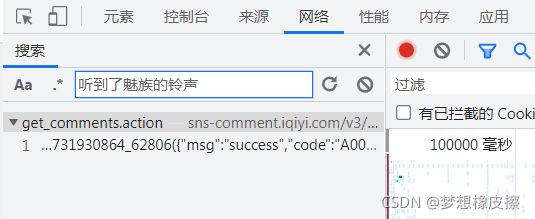
双击目标接口,得到请求相关数据,然后切换到标头,即 headers 部分,此时就得到了数据返回接口。
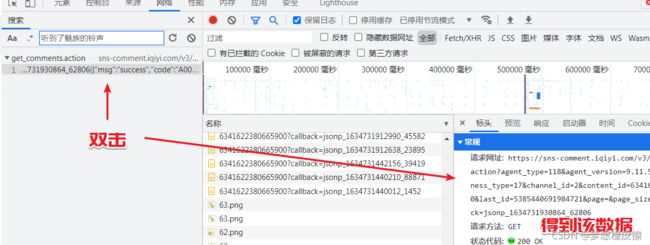
将得到的请求网址相关信息,放置到请求过滤输入框,然后页面就可以对评论接口进行过滤了。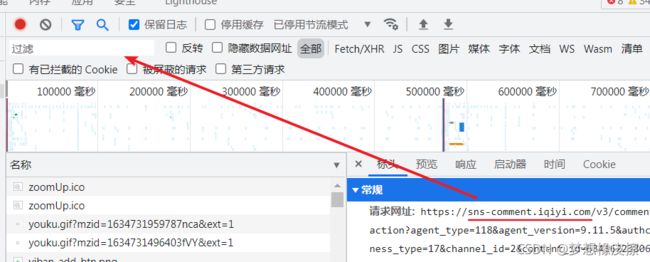
在接下来的动作是拆解接口参数,此处用到的基本技巧是猜+试(有一部分是经常编写爬虫的经验)
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=8268424748618621&page=&page_size=20&types=time&callback=jsonp_1634731681416_32977
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=5385440691984721&page=&page_size=20&types=time&callback=jsonp_1634731930864_62806
复制 2 个进行比对就可以,对比完成,在将得到的结论应用到第 3 个地址。
接口地址:https://sns-comment.iqiyi.com/v3/comment/get_comments.action
agent_type:未知,保持默认 118 ;agent_version:未知,保持默认 9.11.5 ;authcookie:未知,保持 null;business_type:未知,保持 17;channel_id:未知,保持 2;content_id:未知,保持 6341622380665900;hot_size:未知,保持 0;last_id:有变化,猜测与评论的 ID 有关;page:页码,没有变化;page_size:每页数据量,默认 20;types:未知,保持默认;callback:回到函数,用于 JS。(基于经验的结论)
然后复制第 3 个请求地址,验证结论。
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=2&content_id=6341622380665900&hot_size=0&last_id=5385440691984721&page=&page_size=20&types=time&callback=jsonp_1634731705450_53631
接下来的一步是尝试去除部分参数,查看返回数据是否有变化。
最后得到的精简接口地址为:
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&business_type=17&content_id=6341622380665900&last_id=5385440691984721
这里如果你有编写爬虫的经验,可以知道
last_id参数是上一接口返回的最后一条数据 ID
如果没有相关经验,依然使用开发者工具的检索功能,查询last_id值即可。
当 last_id 为空时数据返回第一页数据。
scrapy 采集爱奇艺评论
找到接口之后,使用 scrapy 采集就变得非常简单了,代码如下:
import json
import scrapy
class IqySpider(scrapy.Spider):
name = 'iqy'
allowed_domains = ['sns-comment.iqiyi.com']
start_urls = [
'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&business_type=17&content_id=6341622380665900&last_id=']
def parse(self, response):
html = response.body
json_data = json.loads(html)
yield json_data
if json_data is not None:
ret = json_data['data']
comments = ret['comments']
_id = comments[-1]['id']
next = self.start_urls[0] + str(_id)
# 下一接口
yield scrapy.Request(url=next)
else:
return None
请重点查看 parse 方法,首先返回的是 json_data,即接口返回数据的 JSON 对象,然后直接获取最后一条数据的 ID,拼接成下一页请求地址,从而实现循环采集。
使用下述命令运行爬虫程序:
scrapy crawl iqy -o comments.json -s CLOSESPIDER_ITEMCOUNT=10
-o comments.json:保存为 JSON 格式文件;-s CLOSESPIDER_ITEMCOUNT=10:设置爬取多少个item之后关闭。
本次案例直接将接口请求返回的原数据进行了保存。

如果希望保存为 UTF-8 编码,使用如下命令即可。
scrapy crawl iqy -o comments.json -s CLOSESPIDER_ITEMCOUNT=10 -s FEED_EXPORT_ENCODING=UTF-8
 如果不想在命令行编写,可以直接在
如果不想在命令行编写,可以直接在 settings.py 文件中进行设置。

以上代码就是本篇博客的全部内容啦。
写在后面
今天是持续写作的第 250 / 365 天。
期待 关注,点赞、评论、收藏。
更多精彩
《爬虫 100 例,专栏销售中,买完就能学会系列专栏》
