基于pytorch的RNNCell的简单文本分类(更新GPU使用方法)
import torch
import torchtext
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torchtext.vocab import GloVe
import time
start=time.time()
#每篇提取200个单词
TEXT = torchtext.data.Field(lower=True, fix_length=200, batch_first=False)
LABEL = torchtext.data.Field(sequential=False)
train, test = torchtext.datasets.IMDB.splits(TEXT, LABEL)
TEXT.build_vocab(train, max_size=10000, min_freq=10, vectors=None)
LABEL.build_vocab(train)
BATCHSIZE = 256
train_iter, test_iter = torchtext.data.BucketIterator.splits((train, test), batch_size=BATCHSIZE)
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#将每个单词映射到长100维度的张量上
embeding_dim = 100
#隐藏单元数量 是超参数
hidden_size = 300
#此模型对评论依次读入,并输出最后状态
class RNN_Encoder(nn.Module):
#input_seq_length为输入序列长度
#hidden_size为输出隐藏单元数
def __init__(self, input_dim, hidden_size):
super(RNN_Encoder, self).__init__()
self.rnn = nn.RNNCell(input_dim, hidden_size)
#inputs是输入序列 inputs的shape: seq, batch, embeding
def forward(self, inputs):
# 获取batch
bz = inputs.shape[1]
# 第一时刻输入的上一刻的状态输出为0
# 也可写ht = torch.zeros((bz, hidden_size)).to(device)
ht = torch.zeros((bz, hidden_size)).cuda()
# 将序列沿着单词进行展开
for word in inputs:
#word是这一时刻输入的单词
#ht是上一时刻的状态输出
ht = self.rnn(word, ht)
return ht
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi), embeding_dim)
self.rnn = RNN_Encoder(embeding_dim, hidden_size)
self.fc1 = nn.Linear(hidden_size, 256)
self.fc2 = nn.Linear(256, 3)
def forward(self, x):
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
model = Net()
if torch.cuda.is_available():
model.to('cuda')
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train()
for b in trainloader:
x, y = b.text, b.label
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
# exp_lr_scheduler.step()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for b in testloader:
x, y = b.text, b.label
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,
model,
train_iter,
test_iter)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
end = time.time()
print(end-start)
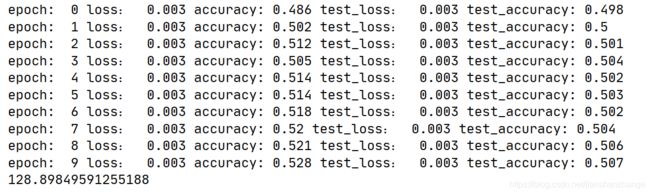
效果并不是很好 因为RNNCell并没有起到保留文本含义的作用
RNNCell只能保留近几次循环的内容