【NLP基础技术】浅谈词法分析之短文本语义相似度
目录
一、短文本语义相似度匹配的应用场景
1、背景介绍(举例说明)
2、文本相似度的应用
二、文本语义相似度技术拆解:语义表示和训练模式
1、语义表示
2、SimNet框架
3、两个训练模式:pointwise 和 pairwise
三、使用EasyDL通过BOW算法网络训练模型
一、短文本语义相似度匹配的应用场景
1、背景介绍(举例说明)
2、文本相似度的应用
二、文本语义相似度技术拆解:语义表示和训练模式
1、语义表示
2、SimNet框架
3、两个训练模式:pointwise 和 pairwise
一、短文本语义相似度匹配的应用场景
1、背景介绍(举例说明)
问题:在百度知道场景下,如何根据用户搜索语句推荐相似问题及其答案?
问题描述:用户在百度知道中,搜索一个问题:什么是省内流量?接着我们会把词问题与库中的问题进行匹配,计算相似度并且进行排序。假设库中有三个问题可以进行匹配,分别是:请问省内流量咋回事?省内流量在天津市里能用吗?天津省内流量在河北唐山能用吗?这三个句子会分别和“什么是省内流量?”进行相似度的计算并得到分数,并且从高到低进行排序。最后会筛选出相似度分数最高的语句,这里以“请问下省内流量咋回事?”为例,假设此句与用户搜索的问题句子的相似度是最高的,我们就会把这个问题句子以及这个问题句子的答案推荐给用户,让用户参考其回答。这其实是一个完整的“问题搜索--匹配排序--推荐答案”的过程。

其中最关键的部分在于匹配排序。那么如何进行排序?这其实是一个短文本语义匹配的任务。我们会把用户输入的问题“什么是省内流量?”依次与库中的三个问题进行相似度分数的计算(0-1)。最后根据相似度由高到低排序。那么如何算出这个文本相似度以及如何把相似度算的更加的准确,这就成为了关键。
2、文本相似度的应用
文本相似度在各种产品应用场景中都有普及,并且都已经取得的很好的效果。
例如入在百度知道的信息检索中,用户每时每刻都会检索各种各样的问题,问题也涉及各种领域,包含生活、娱乐、科技等等。同时问题的表达形式多种多样,不可能完全是库中的问题。这时候就需要语义匹配技术来对用户输入的问题进行匹配,把库中最相似的问题找出并且把答案推荐给用户。
实际应用场景:
比如说:用户检索的问题可能是人来在海洋中到低产生了多少垃圾?海洋中的垃圾有多少是人类产生的?等等。这些都和海洋中有多少人类产生的垃圾相似,找到最相似的进行推荐。

再比如百度浏览器的新闻推荐,这也是相同的逻辑。浏览器会根据用户之前的新闻浏览历史来运用语义匹配技术来推荐相似的新闻给用户。涵盖 体育、财经、娱乐等领域,来达到精准推送目的。

在比如智能客服,许多电商和通信运营商中的智能客服都会用到智能客服。在我们与智能客服聊天或者提问题的时候,智能客服总是可以我们的输入语句与库中的语句进行匹配,把相似度最高的语句呈现给用户。涵盖交通、购物、金融等行业,极大的促进了行业的发展。

二、文本语义相似度技术拆解:语义表示和训练模式
1、语义表示
句子的语义表示,以BOW(词袋)模型为例。首先对文本进行分词操作,对每一个词赋予一个词向量(由浮点数组成的固定维度的向量)来代表当前词的语义,词向量可以随着训练的进行来更新参数,最后使得相似的单词具有较高的余弦相似度。我们把句子中所有的词向量相加得到句子的向量。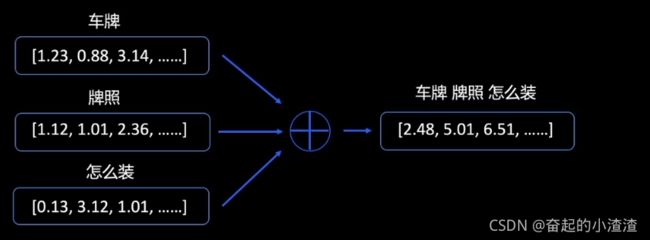
句子语义表示:BOW(词袋)模型
如何计算两个句子的相似分数?这里使用百度语义匹配模型-SimNet框架来进行展示。SimNet是一种有监督的神经网络语义匹配模型,它大幅度提升了语义匹配的效果。
2、SimNet框架
SimNet框架介绍:
SimNet 框架
SimNet 框架如上图所示,主要分为输入层、表示层和匹配层。
1.输入层
该层通过 look up table 将文本词序列转换为 word embedding 序列。
2.表示层
该层主要功能是由词到句的表示构建,或者说将序列的孤立的词语的 embedding 表示,转换为具有全局信息的一个或多个低维稠密的语义向量。最简单的是 Bag of Words(BOW)的累加方法,除此之外,我们还在 SimNet 框架下研发了对应的序列卷积网络(CNN)、循环神经网络(RNN)等多种表示技术。当然,在得到句子的表示向量后,也可以继续累加更多层全连接网络,进一步提升表示效果。
3.匹配层
该层利用文本的表示向量进行交互计算,根据应用的场景不同,我们研发了两种匹配算法。
1)Representation-based Match
该方式下,更侧重对表示层的构建,尽可能充分地将待匹配的两端都转换到等长的语义表示向量里。然后在两端对应的两个语义表示向量基础上,进行匹配度计算,我们设计了两种计算方法:一种是通过固定的度量函数计算,实际中最常用的就是 cosine 函数,这种方式简单高效,并且得分区间可控意义明确;还有就是将两个向量再过一个多层感知器网络(MLP),通过数据训练拟合出一个匹配度得分,这种方式更加灵活拟合能力更强,但对训练的要求也更高。
2)Interaction-based Match
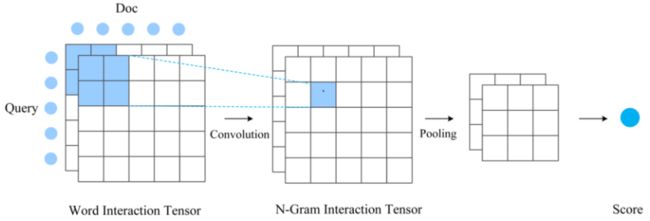
该方式更强调待匹配两端更充分的交互,以及交互基础上的匹配。所以不会在表示层将文本转换成唯一的一个整体表示向量,而一般会保留和词位置相对应的一组表示向量。下面介绍该方式下我们实际应用的一种的 SimNet 模型变体。首先基于表示层采用双向 RNN 得到的文本中间位置表示,和词位置对应的每个向量体现了以本词语为核心的一定的全局信息;然后对两段文本按词对应交互,由此构建两段文本之间的 matching matrix(当然也可以构建多组 matrix,形成 tensor),这里面包括了更细致更局部的文本交互信息;基于该局部匹配特征矩阵,我们进一步使用卷积来提取高级的从单词到 N-Gram 多层次的匹配特征,再经过 pooling 和 MLP 得到最终匹配得分。
Interaction-based match 方法
Interaction-based Match 匹配方法匹配建模更加细致、充分,一般来说效果更好一些,但计算成本会增加非常多,适合一些效果精度要求高但对计算性能要求不高的应用场景。大部分场景下我们都会选择更加简洁高效的 Representation-based 匹配方式。
Pair-wise 的 SimNet 训练框架
采用了pair-wise Ranking Loss 来进行 SimNet 的训练。以网页搜索任务为例,假设搜索查询文本为 Q,相关的一篇文档为 D+,不相关的一篇文档为 D-,二者经过 SimNet 网络得到的和 Q 的匹配度得分分别为 S(Q,D+) 和 S(Q,D-),而训练的优化目标就是使得 S(Q,D+)>S(Q,D-)。实际中,我们一般采用 Max-Margin 的 Hinge Loss:
max{0,margin-(S(Q,D+)-S(Q,D-))}
这种 loss 简洁、高效,还可以通过 margin 的不同设定,来调节模型得分的区分度。
文本任务下的特色改进:
SimNet 的匹配框架非常普适。特别是 Representation-based 模式,其实很早在图像中就有类似应用。九十年代即有利用 Siamese Networks 来进行签名真伪匹配的工作。但对于文本任务来讲,语言的一些特殊性还是需要我们有一些更多针对性的考虑。
针对文本的一维序列的特性,在表示层需要有更针对性的建模。比如我们实现的一维序列卷积网络和长短时记忆网络 LSTM,都充分考虑到了文本的特性。
此外,从输入信号角度我们也充分考虑到文本的特点。SimNet 作为一种 End-to-End 的语义匹配框架,极大地降低了特征设计的代价,直接输入文本的词序列即可。但对中文而言,由于基本语言单位是字,所以仍需要切词这个步骤,但切词本身就是个难题,而且词语的粒度本身也没有严格的定义,所以 SimNet 框架下需要降低对精准切词的依赖,或者说要考虑如何从切词角度来进一步提升匹配效果。另一方面,虽然不再需要进一步的复杂的特征设计,但一些基本的 NLP 技术的产出,如高频共现片段和句法结构信息,能否作为先验知识融入 SimNet 框架发挥作用,也是值得探索的方向。
SimNet模型:实现代码



3、两个训练模式:pointwise 和 pairwise
在这个网络框架下如何学习训练和学习语义匹配呢?这里讲两个训练模式:pointwise 和 pairwise 。
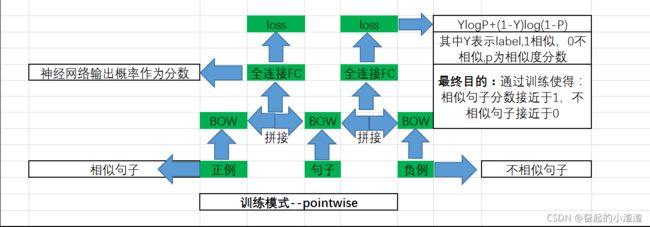
在pointwise模式中,相似的句子叫做正例,不相似的句子叫做负例。句子和正例(或者负例)的训练通过Simnet网络分别通过词向量的表示以及BOW上下的表示得到两个句子的向量后,通过对两个句子向量进行拼接,最后通过全连接FC,把神经网络输出概率作为分数。损失函数为常见的二分函数交叉熵。Y是label,1表示相似,0表示不相似,P表示相似度分数。pointwise模式训练的目的是使得相似句子分数接近于1,不相似句子分数接近于0,更加适合一个分类的场景。

pairwise训练模式和pointwise训练模式的不同是:pairwise需要三段输入的文本,分别是句子、相似的句子--正例,不相似的句子--负例。通过BOW可以得到三个句子的句向量表示。接着我们会先把句子和正例的句向量计算cos余弦相似度得到一个分数是s1,再计算句子和负例的句向量计算cos余弦相似度得到一个分数s2.最后把s1 和 s2 做一个比较,可以查看出损失函数的形式可以通过训练使得相似句子分数 > (不相似句子分数 + 区分度)。pairwise训练模式的目的是使得正例的句子分数尽可能的大于负例的句子分数,更加适合排序的场景。
pointwise和pairwise的总结:
pointwise训练模式 pairwise训练模式 输入样本 query+正例(或负例) query+正例+负例 目的 正例分数接近1,负例分数接近0 正例分数尽可能的高于负例分数 适合场景 分类 排序
训练完毕后,如何进行评估?
对于总体:
- 准确率:预测正确的样本数/总样本数
对于某一类:
- 精确率:该类预测正确的样本数 / 模型预测出该类的数量
- 召回率: 该类预测正确的样本数 / 该类数量
- F1- score : 2 * 精确率 * 召回率 / (精确率 + 召回率)
三、使用EasyDL通过BOW算法网络训练模型
首先准备训练数据,数据分为三部分:训练集、验证集、测试集。

数据集格式:
一条数据集分为三列,分别是句子、正例(或负例)、label.
例如:

其中数据集是不需要分词的,因为 EasyDL 可使用内部分词功能,可以使用权威公开相似度数据集lcqmc数据集(原始lcqmc数据集训练数据量有23万,实践时为了训练效果只截取了2万少量数据量,地址:链接:https://pan.baidu.com/s/1Nfw45I3hL3WjE3EHIMnhzg 提取码:x352)。目前EasyDL(百度官网提供:EasyDL-零门槛AI开发平台)仅支持pointwise训练。
具体的训练方法可以使用下面手册(链接直达)。