【机器学习】基础之概率论与信息论
该博文的markdown原文链接,猛戳这里!!
文章目录
-
- 引言
- 概率论
-
- 概率
- 概率分布
-
- 离散型随机变量和概率质量函数
- 连续型随机变量和概率密度函数
- 边缘概率分布
- 条件概率分布
-
- 条件概率的链式法则
- 独立性和条件独立性
- 期望、方差和协方差
-
- 期望
- 方差
- 协方差
- 常用概率分布
-
- 伯努利分布
- 高斯分布
- 指数分布
- L a p l a c e \rm Laplace Laplace分布
- 常用函数
-
- s i g m o i d \rm sigmoid sigmoid函数
- s o f t p l u s \rm softplus softplus函数
- 贝叶斯规则
- 信息论
- 参考资料
引言
概率论是用于表示不确定性声明的框架。它不仅提供了量化不确定性的方法,还提供了用于导出新不确定性声明的公理。
人工智能领域,概率论的用途有两种,首先,概率法则告诉我们AI系统如何推理,据此设计一些算法来计算或者估算由概率论导出的表达式。其次,可以用概率与统计来分析和评价AI系统的行为。
概率论使我们能够提出不确定的声明以及在不确定性存在的情况下进行推理,而信息论则能够使我们量化概率分布中的不确定性总量。
机器学习通常必须处理不确定量,有时可能也要处理随机量。不确定性来自三个方面:被建模系统内在的随机性、不完全观测以及不完全建模。
概率论
概率
-
贝叶斯流派概率:认为概率是对某件事情发生的确定程度,也就是确信的程度;
-
频率流派概率:认为概率就是事情发生的频率。
-
随机变量:随机取不同值的变量,一般用无格式小写字母来表示随机变量,用斜体小写字母表示随机变量能够取到的值。如随机变量 x \mathrm x x能取到的值有 x 1 , x 2 x_1, x_2 x1,x2。
如果随机变量是向量形式,则使用粗体 x \mathbf x x表示,它的可能取值为 x \boldsymbol x x。就其本身而言,一个随机变量只是对可能状态的描述,它必须通过概率分布来指定每个状态的可能性。
随机变量可能是离散的,也可能是连续的。离散随机变量拥有有限或者可数无限多的状态。状态不一定非要是整数,也可能是一些被命名的状态而没有数值,连续随机变量则是实数值。
概率分布
离散型随机变量和概率质量函数
对于离散型随机变量,其概率分布可用概率质量函数 ( p r o b a b i l i t y m a s s f u n c t i o n , P M F ) (\rm probability \ mass \ function, PMF) (probability mass function,PMF)来描述,通常用大写字母 P P P表示,概率质量函数将每个随机变量能够取得的每个状态映射到随机变量取得该状态时的概率。如随机变量 x \rm x x取 x x x时的概率表示为 P ( x = x ) P(\text{x} = \it x) P(x=x)。
一般情况下,随机变量 x \rm x x遵循的概率分布 P ( x ) P(\rm x) P(x)用: x ∼ P ( x ) \text x \sim \mathit{P}(\text x) x∼P(x)来表示。概率质量函数 P ( x ) P(\rm x) P(x)必须满足以下条件:
⧫ \blacklozenge \, ⧫ P P P的定义域必须是 x \text{x} x所有状态的集合;
⧫ \blacklozenge \, ⧫ ∀ x ∈ x , 0 ≤ P ( x ) ≤ 1 \forall x \in \text{x}, 0 \leq P(\text{x}) \leq 1 ∀x∈x,0≤P(x)≤1;
⧫ \blacklozenge \, ⧫ ∑ x ∈ x P ( x ) = 1 \sum_{x \in \text{x}} P(x) = 1 ∑x∈xP(x)=1.
假设一个随机变量 x \text{x} x有 k k k个状态,并且遵循均匀分布 ( u n i f o r m d i s t r i b u t i o n ) (\rm uniform \ distribution) (uniform distribution),通过将它的 P M F \rm PMF PMF设为
P ( x = x i ) = 1 k P(\text{x} = x_i) = \frac1k P(x=xi)=k1
对所有的 i i i均成立。
-
联合概率分布
将概率质量函数同时作用于多个随机变量,如 P ( x = x , y = y ) \mathit{P}(\text{x} = x, \text{y} = y) P(x=x,y=y),表示 x = x , y = y \mathrm{x} = x, \mathrm{y} = y x=x,y=y同时发生的概率。
连续型随机变量和概率密度函数
对于连续型随机变量,其概率分布可用概率密度函数 ( p r o b a b i l i t y d e n s i t y f u n c t i o n , P D F ) (\rm probability \ density \ function, PDF) (probability density function,PDF)描述,通常用小写字母 p p p来表示,其必须满足:
⧫ \blacklozenge \, ⧫ P P P的定义域必须是 x \text{x} x所有状态的集合;
⧫ \blacklozenge \, ⧫ ∀ x ∈ x , 0 ≤ P ( x ) \forall x \in \text{x}, 0 \leq P(\text{x}) ∀x∈x,0≤P(x);
⧫ \blacklozenge \, ⧫ ∫ − ∞ ∞ p ( x ) d x = 1 \displaystyle \int _{-\infty}^{\infty} p(x)\mathrm{d}x = 1 ∫−∞∞p(x)dx=1.
因此可以利用 P D F \rm PDF PDF求积分来求得点集的真实概率质量。
比如,在 ( a , b ) (a,b) (a,b)上的均匀分布,
U ( x ; a , b ) = 1 b − a U(x;a,b) = \frac{1}{b - a} U(x;a,b)=b−a1
边缘概率分布
定义:一组变量的联合概率分布中一个子集的概率分布。定义在子集上的概率分布称为边缘概率分布。
假设有离散型随机变量 x, y \text {x, y} x, y且已知 P ( x,y ) P(\text{x,y}) P(x,y)。那么
∀ x ∈ x , P ( x = x ) = ∑ y P ( x = x , y = y ) \forall x \in \text{x}, P(\text{x} = x) = \sum_{y} P(\text{x} = x, \text{y} = y) ∀x∈x,P(x=x)=y∑P(x=x,y=y)
对连续型变量,则利用积分
p ( x ) = ∫ p ( x , y ) d y p(x) = \int p(x, y) dy p(x)=∫p(x,y)dy
条件概率分布
定义:某个事件在给定其他事件发生时出现的概率。
比如,在给定 x = x , \text{x} = x, x=x,事件 y = y \text y = y y=y发生的概率为
P ( y = y ∣ x = x ) = P ( y = y , x = x ) P ( x = x ) P(\text y = y \mid \text x = x) = \frac{P(\text y = y, \text x = x)}{P(\text x = x)} P(y=y∣x=x)=P(x=x)P(y=y,x=x)
条件概率的链式法则
任何多维随机变量的联合概率分布都可以分解为只有一个变量的条件概率相乘的形式:
P ( x ( 1 ) , ⋯ , x ( n ) ) = P ( x ( 1 ) ) ∏ i = 2 n P ( x ( i ) ∣ x ( 1 ) , ⋯ , x ( i − 1 ) ) P(\text x^{(1)}, \cdots, \text x^{(n)}) = P(\text x^{(1)}) \prod_{i = 2}^n P(\text x^{(i)} \mid \text x^{(1)}, \cdots, \text x^{(i - 1)}) P(x(1),⋯,x(n))=P(x(1))i=2∏nP(x(i)∣x(1),⋯,x(i−1))
比如,
P ( a , b , c ) = P ( a ) P ( b ∣ a ) P ( c ∣ a , b ) P(a, b, c) = P(a) P(b \mid a)P(c \mid a,b) P(a,b,c)=P(a)P(b∣a)P(c∣a,b)
或者
P ( a , b , c ) = P ( a ∣ b , c ) P ( b , c ) P ( b , c ) = P ( b ∣ c ) P ( c ) P ( a , b , c ) = P ( a ∣ b , c ) P ( b ∣ c ) P ( c ) \begin{aligned} P(a, b,c) &= P(a \mid b,c)P(b,c) \\ P(b,c) &= P(b \mid c) P(c) \\ P(a,b,c) &= P(a \mid b,c)P(b \mid c)P(c) \end{aligned} P(a,b,c)P(b,c)P(a,b,c)=P(a∣b,c)P(b,c)=P(b∣c)P(c)=P(a∣b,c)P(b∣c)P(c)
独立性和条件独立性
两个随机变量 x \text x x和 y \text y y,若它们的联合概率分布可以表示为单独概率分布的乘积的形式,则称这两个随机变量相互独立,即
∀ x ∈ x , y ∈ y , P ( x = x , y = y ) = P ( x = x ) P ( y = y ) \forall x \in \text x,y\in \text y,P(\text x = x, \text y = y) = P(\text x = x)P(\text y = y) ∀x∈x,y∈y,P(x=x,y=y)=P(x=x)P(y=y)
如果随机变量 x \text x x和 y \text y y的条件概率分布对于随机变量 z \text z z的每个取值都能写成乘积的形式,那么随机变量 x \text x x和 y \text y y在给定随机变量 z \text z z时是条件独立的,即
∀ x ∈ x , y ∈ y , z ∈ z , P ( x = x , y = y ∣ z = z ) = P ( x = x ∣ z = z ) P ( y = y ∣ z = z ) \forall x \in \text x,y\in \text y,z \in \text z,P(\text x = x, \text y = y \mid \text z = z) = P(\text x = x \mid \text z = z)P(\text y = y \mid \text z = z) ∀x∈x,y∈y,z∈z,P(x=x,y=y∣z=z)=P(x=x∣z=z)P(y=y∣z=z)
期望、方差和协方差
期望
期望 ( E x p e c t a t i o n ) (\rm Expectation) (Expectation):函数 f f f关于概率分布 P ( x ) P(\text x) P(x)或 P ( x ) P(\text x) P(x)的期望表示为,由概率分布产生 x x x,再将 f f f作用在 x x x上之后 f ( x ) f(x) f(x)的平均值。即
E x ∼ P [ f ( x ) ] = ∑ x P ( x ) f ( x ) \mathrm{E}_{x \sim P}[f(x)] = \sum_x P(x)f(x) Ex∼P[f(x)]=x∑P(x)f(x)
连续型变量则通过积分求得。
方差
方差 ( V a r i a n c e ) (\rm Variance) (Variance):当对 x x x依据其概率分布进行采样时,随机变量 x x x的函数值 f ( x ) f(x) f(x)会呈现多大的差异。即
V a r ( f ( x ) ) = [ ( f ( x ) − E [ f ( x ) ] ) 2 ] \mathrm{Var}(f(x)) = [(f(x) - \mathrm{E}[f(x)])^2] Var(f(x))=[(f(x)−E[f(x)])2]
平方根称为标准差。
协方差
协方差 ( C o v a r i a n c e ) (\rm Covariance) (Covariance):在某种意义上给出了变量之间的线性相关强度以及各个变量的尺度。即
C o v ( f ( x ) , g ( y ) ) = E { ( f ( x ) − E [ f ( x ) ] ) ( g ( y ) − E [ g ( y ) ] ) } \mathrm{Cov}(f(x), g(y)) = \mathbb{E} \{ (f(x) - \mathbb{E}[f(x)]) (g(y) - \mathbb{E}[g(y)]) \} Cov(f(x),g(y))=E{ (f(x)−E[f(x)])(g(y)−E[g(y)])}
协方差的绝对值很大则意味着变量值的变化很大,并且它们距离各自的均值很远。如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值,反之亦然。
相关系数 ( c o r r e l a t i o n ) (\rm correlation) (correlation)将每个变量的贡献归一化,为了只衡量变量的相关性而不受各个变量尺度大小的影响。
-
协方差矩阵
随机向量 x ∈ R n \boldsymbol x \in \mathbb{R}^n x∈Rn的协方差矩阵是一个 n × n n \times n n×n的矩阵,并且满足
C o v ( x ) i , j = C o v ( x i , x j ) \mathrm{Cov}(\mathbf{x})_{i,j} = \mathrm{Cov}(\text{x}_i, \text{x}_j) Cov(x)i,j=Cov(xi,xj)
其中,对角元素是方差。
import numpy as np
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([8, 7, 6, 5, 4, 3, 2, 1])
Mean = np.mean(x)
Var = np.var(x)
Var_unbias = np.var(x, ddof=1) # N - ddof
Cov = np.cov(x, y)
print(Mean) # 4.5
print(Var) # 5.25
print(Var_unbias) # 6.0
print(Cov)
# [[ 6. -6.]
# [-6. 6.]]
常用概率分布
伯努利分布
单个二值随机变量的分布,也叫两点分布。 ϕ \phi ϕ给出了随机变量等于 1 1 1的概率。
P ( x = 1 ) = ϕ P ( x = 0 ) = 1 − ϕ P ( x = x ) = ϕ x ( 1 − ϕ ) ( 1 − x ) E x [ x ] = ϕ V a r x ( x ) = ϕ ( 1 − ϕ ) P(\text x = 1) = \phi \\ P(\text x = 0) = 1 - \phi \\ P(\text x = x) = \phi^x(1 - \phi)^{(1-x)} \\ \mathbb{E}_{\text x}[\text x] = \phi \\ \mathrm{Var}_{\text x}(\text x) = \phi (1- \phi) P(x=1)=ϕP(x=0)=1−ϕP(x=x)=ϕx(1−ϕ)(1−x)Ex[x]=ϕVarx(x)=ϕ(1−ϕ)
高斯分布
也叫正态分布 ( n o r m a l d i s t r i b u t i o n ) (\rm normal \ distribution) (normal distribution)。
N ( x ; μ , σ 2 ) = 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 \mathcal{N}(x;\mu, \sigma^2) = \sqrt{\frac{1}{2\pi \sigma^2}} e^{-\frac{(x - \mu)^2}{2 \sigma^2}} N(x;μ,σ2)=2πσ21e−2σ2(x−μ)2
有时也会用 β = 1 σ 2 \beta = \frac{1}{\sigma^2} β=σ21 表示分布的精度。中心极限定理认为,大量独立的随机变量的和近似于一个正态分布,因此可认为噪声呈正态分布的。

指数分布
f ( x ) = { λ e − λ x , x > 0 0 , other. f(x) = \begin{cases} \lambda e^{-\lambda x}, & x \gt 0 \\ 0, &\text{other.} \end{cases} f(x)={ λe−λx,0,x>0other.
或这样表示
p ( x ; λ ) = λ 1 x ≥ 0 e − λ x p(x;\lambda) = \lambda \boldsymbol 1_{x \geq 0} e^{-\lambda x} p(x;λ)=λ1x≥0e−λx
指数分布使用指示函数 1 x ≥ 0 \boldsymbol 1_{x \geq 0} 1x≥0来使得当 x x x取负值的时候概率为 0 0 0。
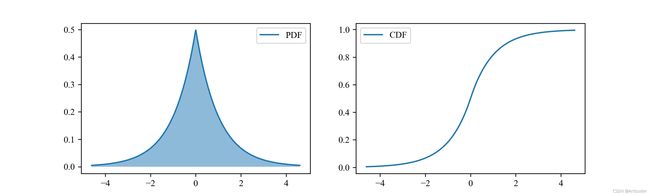
L a p l a c e \rm Laplace Laplace分布
允许在任意一点 μ \mu μ处取得峰值。
p ( x ; γ , μ ) = 1 2 γ e − ∣ x − μ ∣ γ p(x;\gamma, \mu) = \frac{1}{2 \gamma} e ^{-\frac{\left | x - \mu \right |}{\gamma}} p(x;γ,μ)=2γ1e−γ∣x−μ∣
常用函数
s i g m o i d \rm sigmoid sigmoid函数
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1

该函数通常用于产生伯努利分布中的参数 ϕ \phi ϕ,因为其范围是 ( 0 , 1 ) (0,1) (0,1)。当函数的自变量变得很大或者很小的时候,会出现饱和的情况,也就意味着它对输入的微小改变变得不敏感。
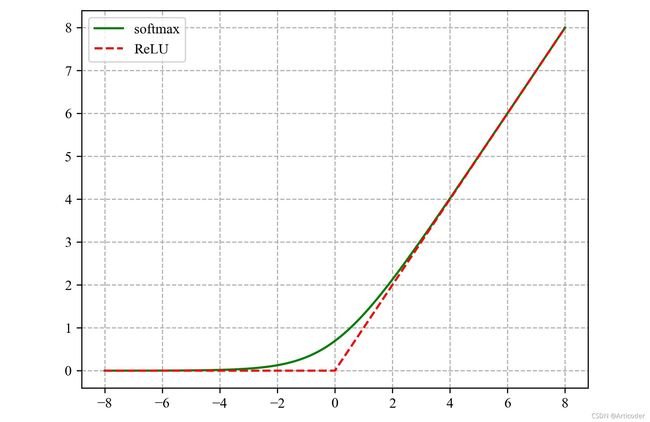
s o f t p l u s \rm softplus softplus函数
ζ ( x ) = log ( 1 + e x ) \zeta(x) = \log (1 + e^x) ζ(x)=log(1+ex)
该函数名来源于另一个函数 R e L U \rm ReLU ReLU
x + = max { 0 , x } x^+ = \max\{0, x\} x+=max{ 0,x}
该函数可用于产生正态分布的参数 μ , σ \mu, \sigma μ,σ,其范围是 ( 0 , ∞ ) (0, \infty) (0,∞)。
贝叶斯规则
已知 P ( y ∣ x ) P(\text y \mid \text x) P(y∣x)计算 P ( x ∣ y ) P(\text x \mid \text y) P(x∣y).
P ( x ∣ y ) = P ( y ∣ x ) P ( x ) P ( y ) = P ( y ∣ x ) P ( x ) ∑ x P ( y ∣ x = x ) P ( x = x ) P(\text x \mid \text y) = \frac{P(\text y \mid \text x)P(\text x)}{P(\text y)} = \frac{P(\text y \mid \text x)P(\text x)}{\sum_x P(\text y \mid \text x = x) P(\text x = x)} P(x∣y)=P(y)P(y∣x)P(x)=∑xP(y∣x=x)P(x=x)P(y∣x)P(x)
无需知道 P ( y ) P(\text y) P(y)的值。
信息论
思想:一件较不可能发生的事比一件较可能发生的事所包含的信息量大。
信息需要满足三个条件:
- 非常可能发生的事件信息量要比较少,并且极端情况下,确保能够发生的事件应该没有信息量。
- 较不可能发生的事件具有更高的信息量;
- 独立事件应具有增量信息。例如,投掷的硬币两次正面朝上传递的信息量,应该是投掷一次硬币正面朝上的信息量的两倍。
自信息:一个事件 x = x \text x = x x=x的自信息为
I ( x ) = − log P ( x ) I(x) = - \log P(x) I(x)=−logP(x)
用 log \log log 来表示自然对数,其底数为 e e e。信息量的单位是奈特 ( n a t s ) (\rm nats) (nats)。若以 2 2 2为底,则单位是比特 ( b i t s ) (\rm bits) (bits)。
香农熵:用于对整个概率分布中的不确定性总量进行量化。也就是编码理论中的最优编码长度。
H ( x ) = − E x ∼ P ( x ) [ log P ( x ) ] = − ∑ x P ( x ) log P ( x ) H(\text x) = -\mathbb{E}_{x \sim P(x)}[\log P(x)] = -\sum_{x}P(x)\log P(x) H(x)=−Ex∼P(x)[logP(x)]=−x∑P(x)logP(x)

# 香农熵 plot
p = np.linspace(1e-6, 1 - 1e-6, 100)
entropy = - p * np.log(p)
plt.figure(figsize=(6, 4))
plt.plot(p, entropy)
plt.xlabel('p')
plt.ylabel('entropy(nats)')
plt.savefig('entropy.jpg', dpi=300)
plt.show()
def Shannon_Entropy(string):
"""
计算最优编码长度
:param string:
:return:
"""
entropy = 0
for ch in range(0, 256):
Px = string.count(chr(ch)) / len(string)
if Px > 0:
entropy += -Px * math.log(Px, 2)
return entropy
message = "".join([chr(random.randint(0, 64)) for i in range(100)])
print(message)
# .1??@41-'7;<;!
# / +
# =;9!<"6#0%3
print(Shannon_Entropy(message))
# 5.419819909835648
联合熵:同时考虑多个事件的熵,多个随机变量
H ( X , Y ) = − ∑ x , y P ( x , y ) log P ( x , y ) H(X, Y) = -\sum_{x,y} P(x, y) \log P(x,y) H(X,Y)=−x,y∑P(x,y)logP(x,y)
条件熵:一件事情发生的情况下,另一个事件的熵,
H ( X ∣ Y ) = − ∑ y P ( y ) ∑ x P ( x ∣ y ) log P ( x ∣ y ) H(X \mid Y) = - \sum_y P(y) \sum_x P(x \mid y) \log P(x \mid y) H(X∣Y)=−y∑P(y)x∑P(x∣y)logP(x∣y)
互信息:表示两件事情信息相交的部分。
I ( X , Y ) = H ( X ) + H ( Y ) − H ( X , Y ) I(X,Y) = H(X) +H(Y) - H(X,Y) I(X,Y)=H(X)+H(Y)−H(X,Y)
信息变差:表示两件事情信息不相交的部分。
V ( X , Y ) = H ( X , Y ) − I ( X , Y ) V(X,Y) = H(X, Y) - I(X,Y) V(X,Y)=H(X,Y)−I(X,Y)
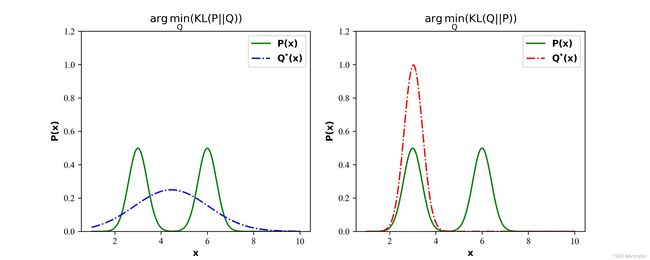
K L \rm KL KL散度:用于衡量两个分布 P ( x ) P(\text x) P(x)和 Q ( x ) Q(\text x) Q(x)之间差距,
D K L ( P ∣ ∣ Q ) = E x ∼ P [ log P ( x ) Q ( x ) ] = ∑ P ( x ) log P ( x ) Q ( x ) D_{\rm KL}(P \mid \mid Q) = \mathbb{E} _{\text x \sim P}\left[\log \frac{P(x)}{Q(x)} \right] = \sum P(x) \log \frac{P(x)}{Q(x)} DKL(P∣∣Q)=Ex∼P[logQ(x)P(x)]=∑P(x)logQ(x)P(x)
D K L ( Q ∣ ∣ P ) = E x ∼ Q [ log Q ( x ) P ( x ) ] = ∑ Q ( x ) log Q ( x ) P ( x ) D_{\rm KL}(Q \mid \mid P) = \mathbb{E} _{\text x \sim Q}\left[\log \frac{Q(x)}{P(x)} \right] = \sum Q(x) \log \frac{Q(x)}{P(x)} DKL(Q∣∣P)=Ex∼Q[logP(x)Q(x)]=∑Q(x)logP(x)Q(x)
显然, D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{\rm KL}(P \mid \mid Q) \neq D_{\rm KL}(Q \mid \mid P) DKL(P∣∣Q)=DKL(Q∣∣P)。
★ \bigstar ★注意:在离散型随机变量下, K L \rm KL KL散度衡量的是当我们使用一种被设计成能够使得概率分布 Q Q Q产生的消息的长度的最小编码,发送包含由概率分布 P P P产生的符号的消息时,所需要的额外信息量。
from scipy.stats import entropy # 内置KL散度
import numpy as np
def KL_Divergence(p, q):
"""D(P || Q)"""
return np.sum(np.where(p != 0, p * np.log(p / q), 0))
p = np.array([0.1, 0.9])
q = np.array([0.1, 0.9])
print(KL_Divergence(p, q)) # 0.0
print(entropy(p, q)) # 0.0
# 两个分布一样
from scipy.stats import norm, entropy
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(1, 10, 1000)
y1 = norm.pdf(x, 3, 0.4)
y2 = norm.pdf(x, 6, 0.4)
P = y1 + y2 # 构造p(x)
KL_PQ = []
KL_QP = []
Q_list = []
for mu in np.linspace(0, 10, 100):
for sigma in np.linspace(0.1, 5, 50):
Q = norm.pdf(x, mu, sigma)
Q_list.append(Q)
KL_PQ.append(entropy(P, Q))
KL_QP.append(entropy(Q, P))
# 寻找Q使得KL_PQ最小
KL_PQ_min = np.argmin(KL_PQ)
# 寻找Q使得KL_QP最小
KL_QP_min = np.argmin(KL_QP)
plt.rcParams['font.family'] = ["Times New Roman"]
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].plot(x, P / 2, 'g-', label="$\\bf P(x)$")
axes[0].plot(x, Q_list[KL_PQ_min], 'b-.', label="$\\bf {Q^{*}(x)}$")
axes[0].set_ylim(0, 1.2)
axes[0].set_xlabel("$\\bf x$")
axes[0].set_ylabel("$\\bf P(x)$")
axes[0].set_title("$\\bf \\rm \\arg\\min_{Q}(KL(P||Q))$")
axes[0].legend()
axes[1].plot(x, P / 2, 'g-', label="$\\bf P(x)$")
axes[1].plot(x, Q_list[KL_QP_min], 'r-.', label="$\\bf {Q^{*}(x)}$")
axes[1].set_ylim(0, 1.2)
axes[1].set_xlabel("$\\bf x$")
axes[1].set_ylabel("$\\bf P(x)$")
axes[1].set_title("$\\bf \\rm \\arg\\min_{Q}(KL(Q||P))$")
axes[1].legend()
plt.savefig("./images/KL.jpg", dpi=300)
plt.show()
交叉熵:一个和 K L \rm KL KL散度联系紧密的量是交叉熵。含义就是实际输出概率 Q Q Q和期望输出概率 P P P之间的距离。
H ( P , Q ) = H ( P ) + D K L ( P ∣ ∣ Q ) = − E x ∼ P [ log Q ( x ) ] = − ∑ x P ( x ) log Q ( x ) \begin{aligned} H(P,Q) &= H(P) + D_{\rm KL}(P \mid \mid Q) = - \mathbb{E}_{x \sim P} [\log Q(x)] \\ & =-\sum_{x}P(x)\log Q(x) \end{aligned} H(P,Q)=H(P)+DKL(P∣∣Q)=−Ex∼P[logQ(x)]=−x∑P(x)logQ(x)
对于二分类来说,其交叉熵计算方式如下
H ( P , Q ) = − 1 N ∑ x P ( x ) log Q ( x ) + ( 1 − P ( x ) ) log ( 1 − Q ( x ) ) H(P,Q) =- \frac1N\sum_x P(x) \log Q(x) + (1- P(x))\log (1-Q(x)) H(P,Q)=−N1x∑P(x)logQ(x)+(1−P(x))log(1−Q(x))
其中, P ( x ) P(x) P(x)表示样本 x x x的期望(真实)标签,正类为1,负类为0; Q ( x ) Q(x) Q(x)表示模型实际预测该样本 x x x类别为正的概率。 N N N表示样本个数。
假设有 3 3 3个样本,其真实类别标签是 P = ( 1 , 0 , 1 ) P = (1, 0, 1) P=(1,0,1) ,实际预测样本为正的概率为 Q = ( 0.8 , 0.1 , 0.7 ) Q=(0.8, 0.1, 0.7) Q=(0.8,0.1,0.7)。计算期望输出和实际输出之间的交叉熵,如下
from sklearn.metrics import log_loss import numpy as np P = np.array([1, 0, 1]) Q1 = np.array([0.8, 0.1, 0.7]) Q2 = np.array([0.1, 0.7, 0.3]) # binary_ent = 0.0 # for i in range(P.size): # binary_ent += P[i] * np.log(Q1[i]) + (1 - P[i]) * np.log(1 - Q1[i]) # print(-binary_ent) # 0.6851790109107685 binary_ent1 = - P * np.log(Q1) - (1 - P) * np.log(1 - Q1) binary_ent2 = - P * np.log(Q2) - (1 - P) * np.log(1 - Q2) print(binary_ent1.sum() / P.size) # 0.22839300363692283 print(binary_ent2.sum() / P.size) # 1.5701769005486392 # np.log 为自然对数 print(log_loss(P, Q1)) print(log_loss(P, Q2)) # 0.22839300363692283 # 1.5701769005486392从上述结果中可以看出预测值 Q 1 Q1 Q1的交叉熵明显比 Q 2 Q2 Q2的小,说明 Q 1 Q1 Q1的预测更接近期望值。
对于多分类来说,其交叉熵计算方式如下
H ( P , Q ) = − 1 N ∑ i = 1 N ∑ j = 1 M P ( x i , j ) log ( Q ( x i , j ) ) H(P,Q) = -\frac1N\sum_{i=1}^N \sum_{j=1}^M P(x_{i,j})\log(Q(x_{i,j})) H(P,Q)=−N1i=1∑Nj=1∑MP(xi,j)log(Q(xi,j))
其中, P ( x i , j ) P(x_{i,j}) P(xi,j)表示样本 x i x_i xi真实类别标签为 j j j则为 1 1 1,否则为 0 0 0; Q ( x i , j ) Q(x_{i,j}) Q(xi,j)表示样本 x i x_i xi预测为第 j j j类的概率, N N N为样本数量, M M M为类别标签数量。
假设有 3 3 3个样本,总共有 0 ∼ 9 0\sim9 0∼9共 10 10 10个类别标签, P P P表示样本真实标签,是一个向量; Q Q Q表示模型对每个样本进行类别预测的值,是一个 3 3 3行 10 10 10列的矩阵,每行表示对样本 i i i的类别预测概率值组成的向量,计算交叉熵。
import numpy as np from sklearn.metrics import log_loss from sklearn.preprocessing import LabelBinarizer P = np.array(['1', '5', '9']) # 样本的真实标签 Q = np.array([ [0.1, 0.7, 0, 0, 0.01, 0.19, 0, 0, 0, 0], [0, 0.1, 0, 0.1, 0, 0.8, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0.1, 0, 0.9] ]) # Q[i]是一个向量 Q[i][j]表示P[i]被预测为j类的概率 labels = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] # 标签集合 sklearn_multi_ent = log_loss(P, Q, labels=labels) print(sklearn_multi_ent) # 0.22839300363693002 # 根据公式计算 # 先对类别标签进行二值化为0&1 数字标签和非数字标签都需要 LB = LabelBinarizer() LB.fit(labels) bin_P = LB.transform(P) # 真实标签进行转换 print(bin_P) # [[0 1 0 0 0 0 0 0 0 0] # [0 0 0 0 0 1 0 0 0 0] # [0 0 0 0 0 0 0 0 0 1]] N = P.size M = len(labels) eps = 1e-15 # 预测概率的控制值 multi_ent = 0.0 for i in range(N): for j in range(M): if Q[i, j] > 1 - eps: Q[i, j] = 1 - eps if Q[i, j] < eps: Q[i, j] = eps multi_ent += -bin_P[i, j] * np.log(Q[i, j]) print(multi_ent / N) # 0.22839300363692283
假设 P P P是期望(真实)分布, Q Q Q是模型(实际)分布,最小化交叉熵 H ( P , Q ) H(P,Q) H(P,Q)就能让模型分布逼近真实分布。
参考资料
[1] 《深度学习》花书
[2] 相关github