go高效缓存框架教你实现
Go缓存框架–手把手带你实现
源文章地址
文章目录
- Go缓存框架--手把手带你实现
-
- 引言:
-
- 实现之初
- LFU算法
- LRU
- 大体的思路
-
- 如何解决并发的问题
-
- 串行化一定不会发生并发的问题
- 解决缓存过期时间的问题
- 总结以及优化(重要)
引言:
首先简单的介绍一下这款缓存框架
- 它高效,功能强大,支持多线程
- 它是一个非常好的学习开源项目.这篇文章我将会介绍我开发时候的思路
- 它非常适合学习Go的特性.笔者使用channel 实现同步异步的获取值操作. 在设置和删除的时候是异步的.且不会发生并发问题. 你甚至可以修改源代码 自己写一些缓存算法来自己用.并且你不需要考虑加锁的问题.
- 我实现了LRU(最近最久未使用算法)和LFU(最近最少使用算法)
- 当然它也支持使过期时间.它的开发空间还很大.是一款非常棒非常棒的学习框架. 你甚至可以加入客户端服务端的代码 只要OK你都可以Request 然后也可以分布式 发挥你的想想
- 有一个goroutines 监听管道 cache向管道里写入命令. 执行者依次执行命令就可以了. redis也是一个单线程的执行器.
- 这里也使用了强大的缓存管理者
- 如果你希望提高你的Go编程功底.那么看完这篇文章吧!
- 如果你有好的想法,但是觉得不太会你可以私信我 我们一起探讨
- 项目已经开源放到github上, 并且有很详细的使用说明, 当然它也恨简单
- github源代码地址 <- 戳我
- 注: 再说一便我会把完整的代码思想都写出来 包括写完后测试优化 我将近优化了之前5倍的速度

实现之初
为什么想着实现一个缓存框架呢? 笔者最近也一直在看缓存. 然后也没有去实践.然后想着看看网上的go缓存框架.github上有一款. 我窃喜的阅读了源代码. 它的内容太少了 而且没有太多的学习的地方.所以我就想着自己实现一个. 首先我一开始想先从缓存的策略开始写起. 我的打算是先写两个 一个是LRU和LFU.
LRU算法是比较好实现, 所以我先从难的开始写起
LFU算法
如果这里不想看了 可以跳后面其实没啥关联
当然在LeetCode这个刷题网站就有这道题. 笔者是实现出来以后先去检测通过了再开始往下继续的

下面是笔者的A题记录
基本都在 %95以上

可以大致的讲一下思路: 如果有需要的小伙伴可以私我一下, 我单独写一篇分析LFU算法的也可以.
这里的代码是O(1)的时间复杂度
首先缓存你应该使用Hash表. 这里Hash表存key和 value value是一个结点的地址 结点里有数据的实例封装了一下.
LFU的淘汰策略是使用最少的, 那其实这里思想很简单. 有一个变量去记录了它的访问次数, 一开始是1, get以后直接+1. 然后需要淘汰的时候淘汰最少的.
基于这样的一个涉及思想 笔者一开始最先相先想到的是优先队列 最小堆.但是这样的时间复杂度就是O(logn)
伪O(1)的算法: 这个是再使用一个map 这个map的key是访问次数, 键是一个双向链表. 然后需要淘汰了.从最少的起 开始是1 for循环找到第一个不是空链的尾结点删除(因为先进入的是头结点. 尾结点说明它好久没访问了) 这样其实最好的情况就是O(1)
但是这样的情况其实是有断层的.最坏的情况 访问次数1-n的链表都是空的 这样时间复杂度就上升到了O(n)
O(1)的算法 基于上面的断层问题做处理就行了. 这里换一种数据结构. 用一个双向链表,这个双向链表的结点还是一个双向链表. 链表链.每次只从第一个链表的尾结点删除. 如果链表都是空了 删除这个链表 这样总能保证第一个链表里面是访问最少的.
过多的细节这里不再赘述
源代码如下
type LFUCache struct {
capacity int
size int
elements map[int]*doublyListNode
chain LFUChain
}
type LFUChain struct {
firstLinkedList *DoublyLinkedList
lastLinkedList *DoublyLinkedList
}
func (lc *LFUCache) Size() int {
return lc.size
}
func Constructor(capacity int) LFUCache {
lfuCache := LFUCache{
capacity: capacity,
size: 0,
elements: make(map[int]*doublyListNode, (capacity<<1|capacity)+1),
chain: LFUChain{
firstLinkedList: New(0),
lastLinkedList: New(0),
},
}
lfuCache.chain.firstLinkedList.next = lfuCache.chain.lastLinkedList
lfuCache.chain.lastLinkedList.prev = lfuCache.chain.firstLinkedList
return lfuCache
}
func (lc *LFUCache) Get(key int) int {
node, ok := lc.elements[key]
if !ok {
return -1
}
freqInc(node)
return node.data.(int)
}
func (lc *LFUCache) Put(key int, value int) {
if lc.capacity <= 0 {
return
}
node , ok := lc.elements[key]
if ok {
node.data = value
freqInc(node)
} else {
if lc.Size() >= lc.capacity {
listNodeChain := lc.chain.firstLinkedList.next
delNode, _ := listNodeChain.RemoveTail()
delete(lc.elements, delNode.key.(int))
lc.size--
if listNodeChain.IsEmpty() {
listNodeChain.LeaveForChain()
}
}
lfuNode := &doublyListNode{
key:key,
data:value,
freq:1,
}
lc.elements[key] = lfuNode
if lc.chain.firstLinkedList.next.freq != 1 {
tempList := New(1)
tempList.AddFirst(lfuNode)
insertChain(lc.chain.firstLinkedList, tempList)
} else {
lc.chain.firstLinkedList.next.AddFirst(lfuNode)
}
lc.size++
}
}
func freqInc(node *doublyListNode) {
parentList := node.parent
node.LeaveForList()
nextList := parentList.next
tempParent := parentList.prev
if parentList.IsEmpty() {
parentList.LeaveForChain()
parentList = tempParent
}
node.freq++
if nextList.freq != node.freq {
newChain := New(node.freq)
insertChain(parentList, newChain)
newChain.AddFirst(node)
node.parent = newChain
} else {
nextList.AddFirst(node)
}
}
func insertChain(preChain, newChain *DoublyLinkedList) {
newChain.next = preChain.next
preChain.next.prev = newChain
newChain.prev = preChain
preChain.next = newChain
}
type doublyListNode struct {
prev *doublyListNode
next *doublyListNode
parent *DoublyLinkedList
key interface{
}
data interface{
}
freq int
}
func (dln *doublyListNode) LeaveForList() {
dln.prev.next = dln.next
dln.next.prev = dln.prev
dln.next = nil
dln.prev = nil
dln.parent = nil
}
func (dll *DoublyLinkedList) LeaveForChain() {
dll.prev.next = dll.next
dll.next.prev = dll.prev
dll.prev = nil
dll.next = nil
}
func (dll *DoublyLinkedList) IsEmpty() bool {
return dll.head.next == dll.tail
}
type DoublyLinkedList struct {
prev *DoublyLinkedList
next *DoublyLinkedList
head *doublyListNode
tail *doublyListNode
freq int
}
func New(freq int) *DoublyLinkedList {
head := &doublyListNode{
}
tail := &doublyListNode{
}
head.next = tail
tail.prev = head
return &DoublyLinkedList{
head:head,
tail:tail,
freq:freq,
}
}
func (dll *DoublyLinkedList) GetHead() *doublyListNode {
if dll.head.next == dll.tail {
return nil
}
return dll.head.next
}
func (dll *DoublyLinkedList) AddFirst(node *doublyListNode) {
node.next = dll.head.next
node.prev = dll.head
node.parent = dll
dll.head.next.prev = node
dll.head.next = node
node.parent = dll
}
func (dll *DoublyLinkedList) RemoveHead() (*doublyListNode, bool) {
if dll.head.next == dll.tail {
return nil, false
}
node := dll.head.next
node.next.prev = dll.head
dll.head.next = node.next
node.next = nil
node.prev = nil
return node, true
}
func (dll *DoublyLinkedList) AddTail(node *doublyListNode) {
node.next = dll.tail
node.prev = dll.tail.prev
node.parent = dll
dll.tail.prev.next = node
dll.tail.prev = node
node.parent = dll
}
func (dll *DoublyLinkedList) RemoveTail() (*doublyListNode, bool) {
if dll.head.next == dll.tail {
return nil, false
}
node := dll.tail.prev
node.prev.next = dll.tail
dll.tail.prev = node.prev
node.prev = nil
node.next = nil
return node, true
}
LRU
lru在题库里也有 而且比较简单 这里不再赘述
其实只需要一个双向链表就可以
笔者的A题记录

源代码
type LRUCache struct {
capacity int
size int
elements map[int]*lruNode
manager *lruNodeChain
}
func (lc *LRUCache) Size() int {
return lc.size
}
type lruNode struct {
key int
data int
next *lruNode
prev *lruNode
}
type lruNodeChain struct {
head *lruNode
tail *lruNode
}
func Constructor(capacity int) LRUCache {
lruCache := LRUCache{
capacity: capacity,
size: 0,
elements: make(map[int]*lruNode, (capacity<<1|capacity)+1),
manager: newLRUChain(),
}
return lruCache
}
func (this *LRUCache) Get(key int) int {
node, ok := this.elements[key]
if !ok {
return -1
}
lruUp(node, this.manager)
return node.data
}
func lruUp(node *lruNode, chain *lruNodeChain) {
node.LeaveForList()
chain.AddTail(node)
}
func (this *LRUCache) Put(key int, value int) {
if this.capacity <= 0 {
return
}
node , ok := this.elements[key]
if ok {
node.data = value
lruUp(node, this.manager)
} else {
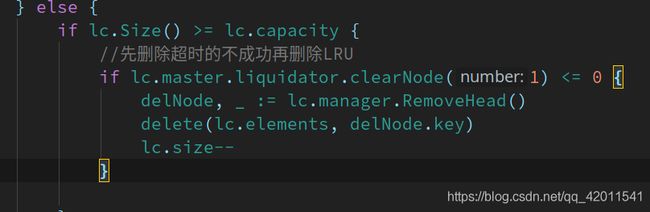
if this.Size() >= this.capacity {
//先删除超时的不成功再删除LRU
delNode, _ := this.manager.RemoveHead()
delete(this.elements, delNode.key)
this.size--
}
lruNode := &lruNode{
key:key,
data:value,
}
this.elements[key] = lruNode
this.manager.AddTail(lruNode)
this.size++
}
}
func newLRUChain() *lruNodeChain {
head := &lruNode{
}
tail := &lruNode{
}
head.next = tail
tail.prev = head
return &lruNodeChain{
head:head,
tail:tail,
}
}
func (ln *lruNode) LeaveForList() {
ln.prev.next = ln.next
ln.next.prev = ln.prev
ln.next = nil
ln.prev = nil
}
func (lc *lruNodeChain) IsEmpty() bool {
return lc.head.next == lc.tail
}
func (lc *lruNodeChain) GetHead() *lruNode {
if lc.head.next == lc.tail {
return nil
}
return lc.head.next
}
func (lc *lruNodeChain) GetTail() *lruNode {
if lc.head.next == lc.tail {
return nil
}
return lc.tail.prev
}
func (lc *lruNodeChain) AddFirst(node *lruNode) {
node.prev = lc.head
node.next = lc.head.next
lc.head.next.prev = node
lc.head.next = node
}
func (lc *lruNodeChain) RemoveHead() (*lruNode, bool) {
if lc.head.next == lc.tail {
return nil, false
}
node := lc.head.next
node.next.prev = lc.head
lc.head.next = node.next
node.next = nil
node.prev = nil
return node, true
}
func (lc *lruNodeChain) AddTail(node *lruNode) {
node.next = lc.tail
node.prev = lc.tail.prev
lc.tail.prev.next = node
lc.tail.prev = node
}
func (lc *lruNodeChain) RemoveTail() (*lruNode, bool) {
if lc.head.next == lc.tail {
return nil, false
}
node := lc.tail.prev
node.prev.next = lc.tail
lc.tail.prev = node.prev
node.prev = nil
node.next = nil
return node, true
}
/**
* Your LRUCache object will be instantiated and called as such:
* obj := Constructor(capacity);
* param_1 := obj.Get(key);
* obj.Put(key,value);
*/
大体的思路
上面的两个缓存算法已经写完了.
因为缓存其实就是一个 写/修改 读 删 所以简单的为这几个方法写一个接口就可以
在源码的dev的cache-goV0-Error/defs.go中
下面定义的缓存的几个方法. 只要实现这个就可以. 所以非常简单
type CacheInter interface {
Get(string) interface{
}
Put(string, interface{
}) interface{
} //返回值是因为可能修改 返回旧值
Delete(string) interface{
} //返回已经被删除的值
}
然后你只需要在你对外暴露的结构体包含有一个CacheInter实例就可以
注意这里其实并不只是这样的 这是笔者在从一开始的思路慢慢写
在源码的dev的cache-goV0-Error/defs.go中
type Cache struct {
cache CacheInter
}
然后为Cache添加你想要方法拿Set举例
在dev的cache-goV0-Error/cache.go中
最核心的是它应该调用cache的Set方法 这里就应该是LRU或者LFU 当然真实的远远没有这么简单
func (c *Cache) Set(key string, val interface{
}) interface{
} {
return c.cache.Set(key, val) // c.cache.Put(key, val) 这里应该是Put 连个名字起的不一样
}
到这里的思路是比较简单的
如何解决并发的问题
那这个缓存肯定是想要给多线程访问的.我觉得单线程的缓存都挺搞笑的. 单线程一个map其实也都能搞定.
最一开始想的是有好多线程同时访问这个缓存. 最简单的方式是读写锁
下面最简单的方式 写一个伪代码
func (c *Cache) Set(key string, val interface{
}) interface{
} {
//加写锁
//defer 释放写锁
return c.cache.Set(key, val)
}
如果对并发有了解的朋友 知道虽然可以解决问题. 但是并不高效.
更好的方式就是对锁进行细粒度. 因为 整个Set的过程 并不是全部都需要加锁的. 有一些不涉及到共享变量的操作 其实完全没有必要去加锁. 比如创建出来一个对象这个其实是栈封闭的. 只有把这个对象加入到缓存的时候才涉及到并发安全的问题.
而且对于LFU或者LRU又对链表有操作. 更好的方式给链表也加锁. 这里读者精力有限就没往下写.
这里就换了一种思路
串行化一定不会发生并发的问题
这里我就在想可不可以使得对缓存的操作串行化.所有指令在一个单线程里面操作.
这里就相当到了redis的执行器也是单线程的.
然后这里我就想到 可以有一个管道 有一端监听这个管道,这个管道里全是指令. 然后来执行这个指令.
然后其他的人可以向这个管道里写入数据
我突然发现这是一个可行的方案, 然后就顺着这个思路走了下去
源码的dev的cache-goV0-Error/defs.go中
这个queue就是这个管道
type dispatcher struct {
queue chan commons
stateCh chan string
}
这个管道里面都是指令
对于指令 它就是一个方法. 传到管道的另外一段有一个单独的执行器来执行就可以
type commons struct {
fn func()
}
然后对于set方法就有了很好的解决方案
Set方法调用set方法就可以
然后创建一个回写管道. 这个管道的作用就是如果你那里函数执行完了
你把你的返回值写到这个管道里面就可以. 然后我在等待管道返回就可以了!
这里面就很巧妙 你品 你细品
然后对于异步也很简单, 直接返回那个回写管道就可以 这里都不需要阻塞
所有的get delete操作都是如此
func (c *Cache) set(key string, val *item) interface{
} {
ch := make(chan interface{
}, 1)
setFunc(key, val, c, ch)
return <- ch
}
func (c *Cache) setAsync(key string, val *item) chan interface{
} {
ch := make(chan interface{
}, 1)
setFunc(key, val, c, ch)
return ch
}
这里创建一个函数 这个函数是写到管道里面的
第一步 调用真正的Put方法得到返回值.
然后再把返回值写入到返回管道
注意 **fn := func()**这里并没有执行.它只是创建了这个函数
然后把这个函数发给了执行者. 执行者接受到了这个函数才会真正的执行.
这里有对象过期的代码 后面再说
当然其实这里是有一个问题的 后面说
func setFunc(key string, val *item ,c *Cache, ch chan interface{
}) {
fn := func() {
obj := c.cache.Put(key, val)
if obj == nil {
ch <- nil
}else {
item := obj.(*item)
//这里其实是解决对象过期的问题
if item.IsExpired() {
ch <- nil
} else {
ch <- item.obj
}
}
}
c.dp.queue <- newCommons(fn)
}
在源代码的dev的cache-goV0-Error/Dispatcher.go里面
这里是V0的那个有问题版本的代码 这里将的都是那里的代码
创建这个也很简单
func newDefaultDispatcher() dispatcher {
return dispatcher{
queue:make(chan commons, DefaultCommonsChannelSize),
stateCh:make(chan string, 1),
}
}
func (d *dispatcher) start() {
go d.run()
}
这里创建了一个单独的goruntines来单独做读取命令 然后执行 然后返回的过程
在源代码的dev的cache-goV0-Error/Dispatcher.go里面
func (d *dispatcher) run(li *Liquidator) {
for {
select {
case commons := <- d.queue: commons.fn()
case state := <- d.stateCh:
if state == CLOSE {
close(d.queue)
}
}
}
}
其实到这里基本也就结束了
并发的处理也就结束了
解决缓存过期时间的问题
其实每一个缓存都应该过期时间, 可能不过期. 可能很快就过期由客户端来指定
源码的dev的cache-goV0-Error/defs.go中
obj 就是你真实的数据
expiration 是到期的时间
type item struct {
obj interface{
}
expiration int64
}
对于Cache的Set方法
在dev的cache-goV0-Error/cache.go中
func (c *Cache) Set(key string, val interface{
}) interface{
} {
if checkCloseGentle(c) {
return nil
}
return c.set(key, newItem(val, NoExpiration))
}
放进去的时候先封装成这个具有过期时间对象
newItem(val, NoExpiration))
拿到对象的时候判断一下是否过期 返回nil 这个时候即使返回nil了 其实还在map中 什么时候删除这个 合适删除.
这里应该开一个定时任务, 每隔5分钟把已经过期的缓存删掉. 这个定时任务和那个执行者放一起就OK了
源码的dev的cache-goV0-Error/defs.go中
垃圾清理者
这个里面是一个优先队列
type Liquidator struct {
elements *alg.PriorityQueue
}
在源代码的algorithm/priority_queue.go里面 实现了这个数据结构感兴趣的可以看一下
然后对于需要清除的结点
源码的dev的cache-goV0-Error/defs.go中
它保存了 需要清除的key 过期时间 还有在哪个缓存中
type needClearNode struct {
masterCache *Cache
key string
expiration int64
}
CompareTo是为了可以加入到优先队列中.
这里使用最小的时间来排序.关于不懂优先队列的
你就可以理解为 类似于一个队列每次出队的都是最小或者最大的 我这里是最小的.
源码的dev的cache-goV0-Error/liquidator.go中
import (
alg "four-seasons/algorithm"
"time"
)
func (node needClearNode) CompareTo(other alg.Comparable) int {
return int(node.expiration - other.(needClearNode).expiration)
}
func (node needClearNode) IsExpired() bool {
if node.expiration <= int64(NoExpiration) {
return false
} else if node.expiration > time.Now().UnixNano() {
return false
}
return true
}
修改源代码的dev的cache-goV0-Error/Dispatcher.go
创建一个定时任务. 时间到了就会执行 clearFunc这个
func (d *dispatcher) run(li *Liquidator) {
ticker := time.NewTicker(DefaultCleatStep)
for {
select {
case commons := <- d.queue: commons.fn()
//fmt.Printf("run %T , %p\n",commons.fn, &commons.fn)
case state := <- d.stateCh:
if state == CLOSE {
close(d.queue)
}
case <- ticker.C:
li.clearFunc()
}
}
}
然后下面这个函数是在计算需要删除的个数.
因为是单线程的 你不能一次性的全部删除.如果过期的对象特别多的话 可能会阻塞这个过程
func (l *Liquidator) clearFunc() {
num := 0
if l.elements.Length() < 50 {
num = l.elements.Length()
} else if l.elements.Length() > 1000 {
num = 100
} else {
num = l.elements.Length() >> 1
}
l.clearNode(num)
}
然后对于真正的清理方法
拿到第一个时间最小的那个结点
判断一下它是不是过期了. 如果过期了 那么就删除.
并且继续.
如果最小的都没过期 其他的肯定没有过期 就直接返回删除的数量
func (l *Liquidator) clearNode(number int) (total int) {
total = 0
if l.elements.Length() == 0 {
return
}
for i := 0; i < number; i++ {
top := l.elements.Top().(*needClearNode)
if top.IsExpired() {
top = l.elements.Pop().(*needClearNode)
_ = top.masterCache.DeleteAsync(top.key)
} else {
break
}
total++
}
return
}
同理如果你缓存的界限已经到了上限.那么应该先删除一个过期的结点
否则再进行LRU
总结以及优化(重要)
先简单的总结一下这个运行的流程
- 通过NewCache初始化所有的数据(创建真正的cache策略实例, 初始化map 启动一个goruntines来监听客户端写入的指令并执行)
- 当一个客户端真正写入一个数据后
- 先封装成一个带有超时时间的对象然后传参进去. 将函数和回写管道写入到执行器管道. 自己在等回写管道有数据
- 管道的接收方收到指令后开始执行这个函数, 执行完毕后 向这个回写管道写入数据 结束!
- 异步的就是 提交完命令 不等带管道的数据到达. 直接返回管道 交由客户端来做
至此大致的流程就完成了. 然后笔者除了在需要测试的时候写完就进行测试
当然还有一个简单的缓存管理没有讲.它很简单没有什么需要讲解的
然后还对性能进行了测试. 这次的测试大跌眼镜, 这个框架的性能居然慢了 github上那个简单为字典加锁解锁的性能的8-9倍左右.
虽然我提供的功能比较强大. 但是也不应该慢这么多呀. 后来慢慢测了一堆东西.修修改改大概性能高了5倍左右.这篇内容太多了优化的部分放到下一篇来讲
大致的流程没怎么改.全都是一些细节的问题
go高效缓存框架性能优化
最后的最后目前这个项目可以发展的空间还很大. 没有加入客户端和服务端又或者持久化对象池…等等一系列. 你们也可以帮笔者加一个客户端服务端 然后自己来用. 然后性能优化 或者代码的健壮型做一些贡献.
源文章地址
未经允许不许转载!