零基础入门NLP之新闻文本分类挑战赛——数据读取与数据分析
一、数据读取
首先,导入pandas库读取csv数据,并显示前几行看一下~
import pandas as pd
#读取数据
train_df = pd.read_csv('F:/datawhale/NLP_learning/train_set.csv', sep='\t', nrows=100)
train_df.head()
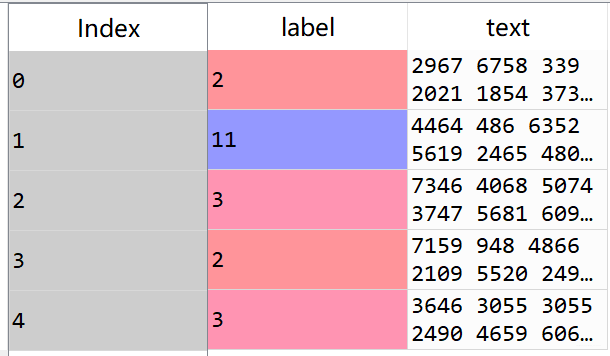 可以看到,第一列为新闻的类别,第二类为新闻的字符。
可以看到,第一列为新闻的类别,第二类为新闻的字符。
二、数据分析
读取数据集后,我们需要对数据进行分析,理解数据的特征,方便后续做相应的数据清洗工作。
1、句子长度分析
因为每个句子的字符使用空格字符隔开,因此我们可以统计单词的个数来得到句子的长度。
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())
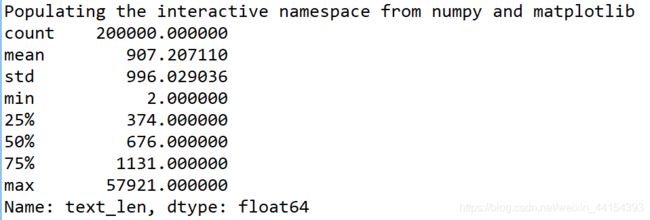
可以看到75%以上的句子长度都在2000以内,接下来,我通过绘制直方图更直接地展示句子长度的分布情况。
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")

2、新闻类别分布
通过对数据集的分布进行统计,统计各个类别数量。
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
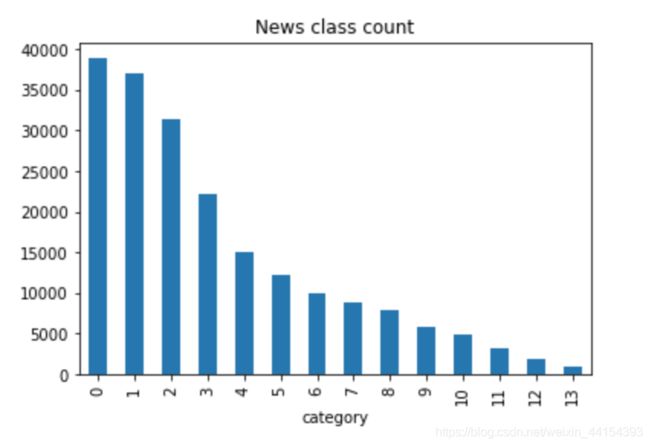
 从直方图可以看出,类别数量分布不均匀,其中科技类新闻最多,星座类新闻最少。
从直方图可以看出,类别数量分布不均匀,其中科技类新闻最多,星座类新闻最少。
3、字符分布统计
接下来分析文本内容中字符的分布特征,尽管加密后我们不能得到字符本身的含义,但还是可以获得字符总数及分布的特点。
all_lines = ' '.join(list(train_df['text'])) # 读取所有文本内容,以空格连接各文本生成一个长字符串
word_count = Counter(all_lines.split(" ")) # 按空格切分字符并存入Counter
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])
'''
Printout:
6869
('3750', 7482224)
('3133', 1)
'''
此外还可以根据字符在不同文本中出现的频率,推断其是否可能为标点符号,如’3750’、'900’及’648’等在几乎所有文本中出现,很可能是标点符号。
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True) # reverse = True 即降序排列
print(word_count[0])
print(word_count[1])
print(word_count[2])
'''
Printout:
('3750', 197997)
('900', 197653)
('648', 191975)
'''
word_keys = [word_count[i][0] for i in range(len(word_count[:10]))]
word_nums = [word_count[i][1] for i in range(len(word_count[:10]))]
plt.bar(word_keys,word_nums)
plt.title('Top 10 Text char')
plt.xlabel("char No.")
plt.ylabel('counts')
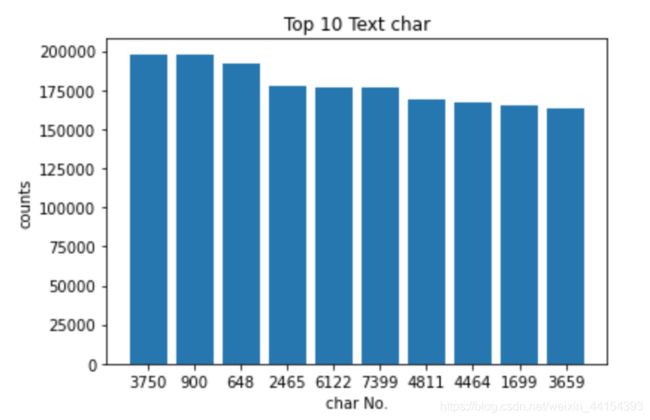 从图中可以看到,出现频率前10的字符均在至少150000个文本中出现,说明这些字符即使不是标点符号,也很可能是无区分度的常用连接词等,我们一般将其称为停用词,而不对其进行分析。
从图中可以看到,出现频率前10的字符均在至少150000个文本中出现,说明这些字符即使不是标点符号,也很可能是无区分度的常用连接词等,我们一般将其称为停用词,而不对其进行分析。